







该论文发表在ECCV2020。
论文地址:https://arxiv.org/pdf/2007.06227.pdf
项目地址:https://github.com/lartpang/HDFNet
简介
这是一篇关于RGB-D显著性目标检测的工作,该研究课题的关键点在于如何充分融合和利用跨模态的信息(深度图的结构信息)来有助于目标检测的任务。
本文的贡献主要在于两点:第一点是利用动态滤波的方法并设计出一个新颖的动态空洞金字塔模块,该模块能够更好地融合不同尺度的跨模态信息;第二点设计出一个混合增强损失函数,使得预测结果能够产生更加清晰的边缘和具有一致性的显著区域。
动机
- 现有的基于FCN的显著性目标检测(不涉及深度图)的工作,在处理复杂或者低对比度的场景时没有优势。为了克服这个问题,引入深度图可以进一步提升目标检测的表现。
- 在RGB-D目标检测的任务中,其一大挑战是如何利用这样的深度信息。
- 在RGB-D的任务中,RGB图像包含风度的细节信息而深度图则包含更多的空间结构信息,因此两者可以相互补充。
- 现有的显著性目标检测的算法在测试时,针对不同的样本使用的是固定的参数,这就使得模型的泛化能力大大地降低。此外,对于该任务每一个位置的预测结果的损失是不用的,所以,在不同位置上的梯度优化的方向应该是不同的。为了解决这一问题,本文提出动态空洞金字塔模块,使用RGB-D的混合特征来自适应的调整卷积核,处理不同的输入样本和位置。
- 早期的基于学习的SOD方法是简单使用全连接层,但是却破坏了数据的空间结构信息。后来,使用FCN缓解了这一问题。但是其本质上的gridding operation和down-sampling 操作使得很多细节信息都丢失。在本文中,作者提出混合增强损失函数,分别来对显著物体的主体区域和边缘部分进行约束,最终得到更好的预测结果。
方法
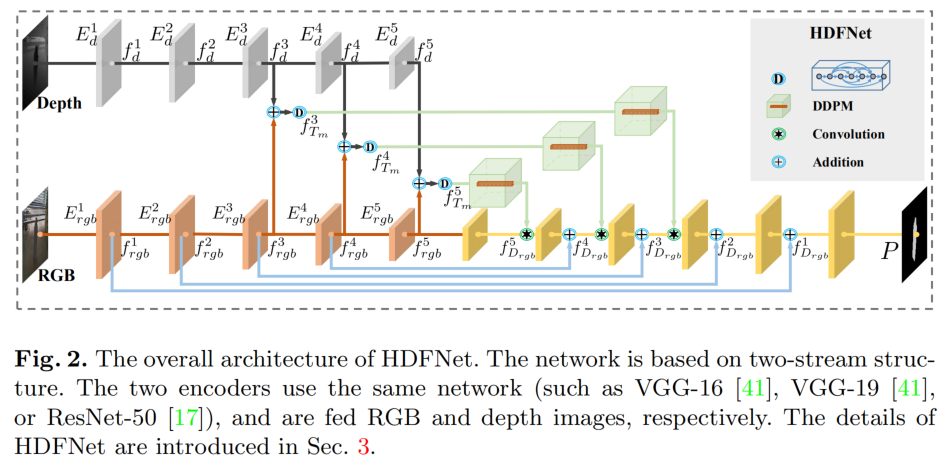
Two Stream Structure
如图2所示,它是一个two-stream网络结构,其输入是深度图和RGB图像。
首先,两者分别经过一个具有相同网络结构的编码网络(这里可以使用VGG-16,VGG-19,ResNet-50)得到不同尺寸的中间特征。考虑到计算代价和噪声,作者这里处理后三个尺度的特征: f d 3 , f d 4 , f d 5 ; f r g b 3 , f r g b 4 , f r g b 5 f_d^3,f_d^4,f_d^5;f_{rgb}^3,f_{rgb}^4,f_{rgb}^5 f
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3094
3094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









