







一:Principal Component Analysis(PCA)
1:Maximum variance formulation:
1):Maximum variance formulation的依据如下:数据正交投影到一个低维的线性空间,该低维线性空间的选择要使得投影数据的方差最大化,同时该低维线性空间也被称之为principal subspace;
2):依据上述原理,我们能够获得如下的步骤去决定该低维(假设是M维)的线性空间:
(1):计算数据集的协方差矩阵:
(2):计算其正交归一的本征矢量和对应的本征值,前M个最大的本征值所对应的本征矢量即为M维线性空间的基矢。并且投影到M维线性空间基矢的投影数据方差即为该基矢所对应的本征值;
(3):假设M维线性空间的基矢分别为 u1→,...,uM→ ,则我们可以用 xn→˜=∑Mm=1(u⃗ Tixn→) u⃗ i 去近似原先的数据点 x⃗
2:Minimum-error formulation:
1):Minimum-error formulation的依据如下:数据线性投影到低维的线性空间,该低维线性空间的选择要使得数据点与其投影的距离平方最小;
2):依据此方法得出来的关于低维M维线性空间的选择与Maximum variance formulation的一样,都是选择协方差矩阵前M个最大本征值所对应的本征矢量;
3):但有一点不同的是,当近似原先的数据点 x⃗ 时,我们依据的是下式:
3:Applications of PCA
1):我们能够使用PCA对数据集进行转变,使得转变后的数据集平均值为0,协方差矩阵为单位协方差矩阵。步骤如下:
(1):SU=UL,U是D*D正交矩阵,它的列由S的本征值 u⃗ i 组成,L是一个由本征值 λi 组成的D行D列的对角矩阵;
(2):对原先数据集 x⃗ n 使用下式转变成 y⃗ n :
可以证明,由 y⃗ n 组成的数据集其均值为0,协方差为单位矩阵
2):PCA和Fisher linear discriminant 都是用来维度缩减的,但要注意的是PCA属于未监督学习,其仅仅依赖于 x⃗ n ,而Fisher linear discriminat需要利用类标号信息。
3):PCA能够被用来数据的可视化(data visualization):每个数据点投影到两维的principal subspace,以至于每个数据点 x⃗ n 能够在两维坐标下显示,对应的坐标值为( x⃗ Tnu⃗ 1 , x⃗ Tnu⃗ 2 ), u⃗ 1 和 u⃗ 2 对应着第一大和第二大本征值的本征矢量。
4:PCA for high-dimensional data
1):对于高维数据来说,假设是D维,计算其协方差矩阵的本征矢量所需要的计算量为O( D3 ),计算量为很大;
2):为了简化计算同时又能够计算出协方差矩阵所对应的本征矢量和本征值,我们能够按照如下步骤进行:
I:首先计算 XXT ,X是N*D维矢量,其第n行为 (x⃗ n−x⃗ ¯)T ;
II:利用下式计算 XXT 本征矢量和对应的本征值:
III:利用下式计算协方差矩阵的本征矢量:
因为 XXT 是N*N维,所以计算其本征值和对应的本征矢量所需要的计算为O( N3 ),而不是刚开始的 O(D3)
二:Probabilistic PCA
1:Probabilistic PCA的表达形式
1):概率PCA属于线性高斯模型,其有一个对应着principal-component子空间的M维latent variable z⃗ ,满足的分布为 p(z⃗ )=N(z⃗ |0,I) ,条件在 z⃗ 的D维observed variable x⃗ 所满足的分布为 p(x⃗ |z⃗ )=N(x⃗ |Wz⃗ +u⃗ ,σ2I) ,W是D*M矩阵并且可以证明W的列矢量对应着principal subspace;
2):observed variable x⃗ 的边际分布 p(x⃗ ) 为 p(x⃗ )=N(x⃗ |u⃗ ,C),C=WWT+σ2I ;
3):latent variable z⃗ 所满足的后验分布 p(z⃗ |x⃗ ) 为 p(z⃗ |x⃗ )=N(z⃗ |M−1WT(x⃗ −u⃗ ),σ−2M),M=WTW+σ2I
2:Maximum likelihood PCA
1):可以用极大似然法求解上述概率分布所含有的参数值 W,u⃗ ,σ ,得出来的结果如下:
2):传统PCA方法构造的思路是D维数据空间中数据点向M维线性空间的投影;然而概率PCA则要反过来,其被认为是M维latent space向数据空间的映射,映射的关系式是 x⃗ =Wz⃗ +u⃗ +ϵ⃗ ,其中 ϵ⃗ 是D维的均值为0,协方差矩阵为 σ2I 的高斯分布噪音;
3):当我们在应用概率PCA时,如果我们想要获得数据点在M维空间的投影,我们能够利用latent variable z⃗ 的后验分布,均值为 E[z⃗ |x⃗ ]=M−1WTML(x⃗ −x⃗ ¯) ,方差为不依赖于 x⃗ 的 σ2M−1 。特别要注意的是如果我们采取极限 σ2 趋于0,则后验平均值为 (WTMLWML)−1WTML(x⃗ −x⃗ ¯) ,这个代表了数据点在latent space的正交投影,因此此时我们恢复到了标准PCA模型;
4):概率PCA模型不仅能够应用于维度缩减,同时它也定义了一个多变量的高斯分布 p(x⃗ ) ,此高斯分布不仅将独立参数的数目限定于与维度D呈线性关系的 DM+1−M(M−1)/2 ,同时还能俘获变量成分与成分之间M个最显著的关联。
3:EM algorithm for PCA
1):因为概率PCA包含latent variable z⃗ ,因此在求取概率PCA参数值时,我们可以用EM algorithm;
2):我们首先初始化参数值,然后在E步与M步中迭代直至收敛标准被满足,在E步中所需要进行的计算为
3):如果我们采取 σ2 趋于0的极限,则E step的计算可以简化为:
4:Bayesian PCA
1):如果我们只把参数当做点来处理的话,在应用概率PCA时我们必须要指定principal subspace的维度M,然而如果我们把M当做变量的话,并且归给予它一个合适先验,这样我们就能够让数据集自动的选择合适的维度M;
2):W的先验被定为如下形式
这种先验的设定形式也是ARD(automatic relevance determination)的一种应用;
3):由于最优化的结果,一些 αi 值会趋于无穷,这样就导致了其对应的 w⃗ i 值趋于0,因此principal subspace的有效维度由有限 αi 值的个数决定的。
5:Factor analysis
1:类似于概率PCA,Factor analysis也是一个线性高斯隐变量模型,但是条件在 z⃗ 的 x⃗ 高斯分布其方差不是各向同性的协方差 σ2I ,而是对角化的协方差,表达形式如下:
2:矩阵W被用来俘获观察变量之间的关联,其列矢量被称之为factor loadings;矩阵 Ψ 被用来代表每个变量本身拥有的与其它变量无关的噪音方差,其对角线元素被称之为uniquenesses;
3:观察变量 x⃗ 的边际概率 p(x⃗ ) 为 p(x⃗ )=N(x⃗ |u⃗ ,C),C=WWT+Ψ
三:Kernel PCA
1:在 x⃗ 空间中,有很大可能其principal subspace是非线性的,因此我们能够用函数 ϕ⃗ (x⃗ ) 将最初的 x⃗ 转化到特征空间中,然后在特征空间中principal subspace是线性的。然而我们并不想去确定函数 ϕ⃗ 的具体形式,在这时候我们可以利用kernel method;
2:kernel PCA的计算方法步骤如下:
I:利用下式计算矩阵 K˜ :
II:利用 K˜a⃗ i=λiNa⃗ i 以及 λiNa⃗ Tia⃗ i=1 这两个条件计算其本征值 λi 和 a⃗ i ;
III:数据点 x⃗ 在用函数 ϕ⃗ 转换后数据集协方差矩阵的第i个本征矢量的投影为 yi(x⃗ )=∑Nn=1aink(x⃗ ,x⃗ n)
3:在标准线性PCA中,我们会用 x⃗ n˜=∑Mi=1(x⃗ Tnu⃗ i)u⃗ i 来近似原先的数据点 x⃗ n ,但是在kernel PCA中这是不可能的。
四:Nonlinear Latent Variable Models
1:Independent component analysis
1):observed variables与latent variables是线性相关的,例如 x⃗ =Az⃗ ,然而latent variables是非高斯分布,其各个成分之间的概率分布是相互独立的,具有如下的因式分解形式:
2):假设观察变量 x⃗ 与隐变量 z⃗ 满足关系式 x⃗ =Az⃗ ,现在我们有了观察的数据集 {x⃗ i} 以及概率分布 p(z⃗ ) 的具体形式(也就是有了观察变量 p(x⃗ ) 的具体形式),则我们可以通过极大似然法获得矩阵A的值,因此我们也就有了 z⃗ 的值,在这种情况下,我们能够应用ICA。如果我们应用PCA,也就是说假定 z⃗ 满足的是高斯分布,正如我们之前看到的,矩阵A和矩阵AR( RRT=1 )所导致的 x⃗ 的概率分布是一样的,因此我们无法知道矩阵A的恰好形式,因此也就无法得知 z⃗ 的值。
2:Autoassociative neural networks
1):Autoassociative neural networks有相同的D个输入和D个输出,有M个hidden units( M<D ),用来训练网络的目标矢量就是输入变量自身,以便于神经网络尝试把每个输入矢量映射到它本身以此减小reconstruction error,最小化的目标函数如下:
2):如果说只有一个hidden layer(如下图),那么autoassociative neural networks相当于linear dimensionality reduction,从输入层连接hidden units的权重矢量就形成了扩展linear principal subspace的一组基集,hidden layer各units的值就相当于数据点在此principal subspace的投影值;
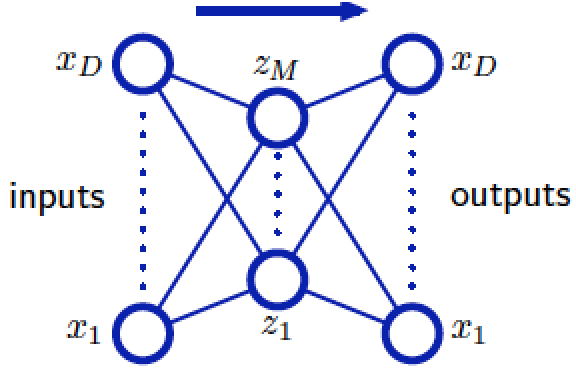
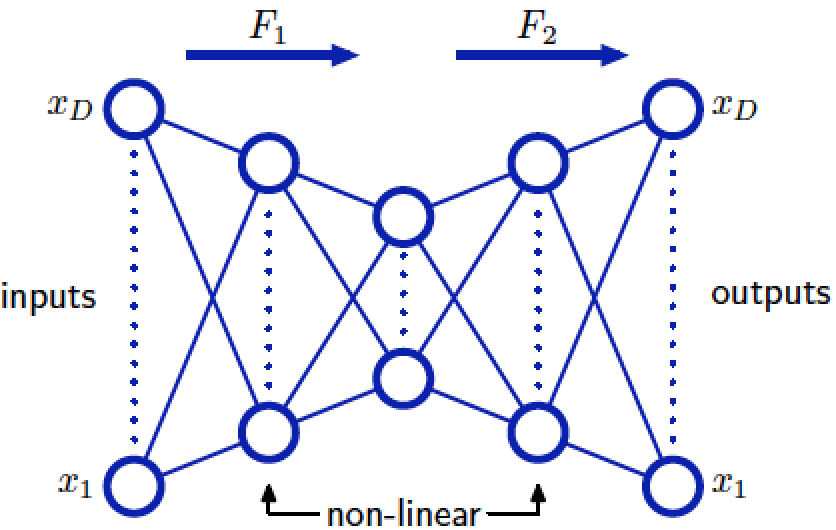
3):如果说在上述的神经网络基础上再添加两个hidden layer(如下图),并且第一个和第三个hidden layer units的activation functions是sigmoidal非线性的,那么这就相当于nonlinear dimensionality reduction。















 1253
1253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









