





机器学习中常见的损失函数
现实世界中的DS (DS IN THE REAL WORLD)
In mathematical optimization and decision theory, a loss function or cost function is a function that maps an event or values of one or more variables onto a real number intuitively representing some “cost” associated with the event. — Wikipedia
在数学优化和决策理论中 ,损失函数或成本函数是将一个事件或一个或多个变量的值映射到实数上的函数,该实数直观地表示与该事件相关的某些“成本”。 — 维基百科
As a core element, the Loss function is a method of evaluating your Machine Learning algorithm that how well it models your featured dataset. It is defined as a measurement of how good your model is in terms of predicting the expected outcome.
作为核心要素,损失函数是一种评估您的机器学习算法的方法,该算法可以很好地模拟您的特征数据集。 它的定义是衡量模型在预测预期结果方面的良好程度。
The Cost function and Loss function refer to the same context. The cost function is a function that is calculated as the average of all loss function values. Whereas, the loss function is calculated for each sample output compared to its actual value.
成本函数和损失函数引用相同的上下文。 成本函数是计算为所有损失函数值的平均值的函数。 而损失函数是针对每个样本输出及其实际值进行计算的。
The Loss function is directly related to the predictions of your model that you have built. So if your loss function value is less, your model will be providing good results. Loss function or I should rather say, the Cost function that is used to evaluate the model performance, needs to be minimized in order to improve its performance.
损失函数与您所建立的模型的预测直接相关。 因此,如果损失函数值较小,则模型将提供良好的结果。 损失函数,或者我应该说,用于评估模型性能的Cost函数需要最小化以改善其性能。
Lets now dive into the Loss functions.
现在让我们进入“损失”功能。
Widely speaking, the Loss functions can be grouped into two major categories concerning the types of problems that we come across in the real world — Classification and Regression. In Classification, the task is to predict the respective probabilities of all classes that the problem is dealing with. In Regression, oppositely, the task is to predict the continuous value concerning a given set of independent features to the learning algorithm.
广义上讲,损失函数可以分为两大类,分别是关于我们在现实世界中遇到的问题的类型- 分类和回归 。 在分类中,任务是预测问题正在处理的所有类别的各自概率。 相反,在回归中,任务是预测与学习算法给定的一组独立特征有关的连续值。
Assumptions:
n/m — Number of training samples.
i — ith training sample in a dataset.
y(i) — Actual value for the ith training sample.
y_hat(i) — Predicted value for the ith training sample.分类损失 (Classification Losses)
1.二进制互熵损失/对数损失 (1. Binary Cross-Entropy Loss / Log Loss)
This is the most common Loss function used in Classification problems. The cross-entropy loss decreases as the predicted probability converges to the actual label. It measures the performance of a classification model whose predicted output is a probability value between 0 and 1.
这是分类问题中最常用的损失函数。 交叉熵损失随着预测概率收敛到实际标记而减少。 它测量分类模型的性能,该分类模型的预测输出为0到1之间的概率值。
When the number of classes is 2, Binary Classification
当类别数为2时,二进制分类
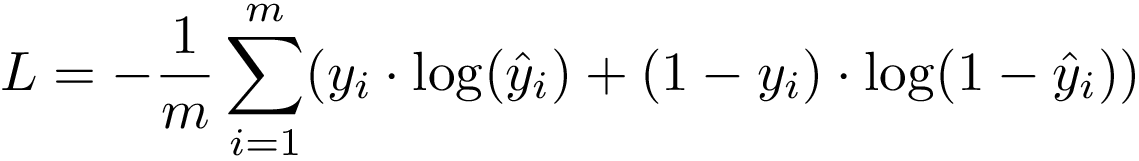
When the number of classes is more than 2, Multi-class Classification
当类别数大于2时,多重类别分类
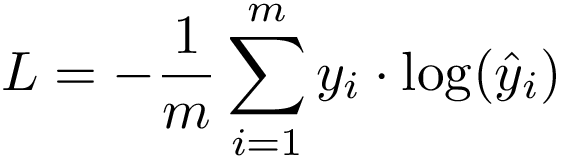
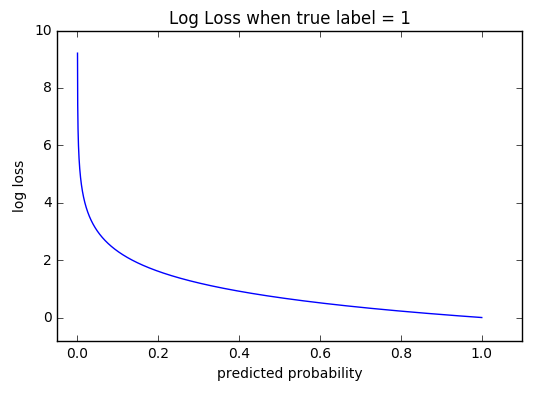
The Cross-Entropy Loss formula is derived from the regular likelihood function, but with logarithms added in.
交叉熵损失公式是从规则似然函数中导出的,但是增加了对数。
2.铰链损失 (2. Hinge Loss)
The second most common loss function used for Classification problems and an alternative to Cross-Entropy loss function is Hinge Loss, primarily developed for Support Vector Machine (SVM) model evaluation.
用于分类问题的第二种最常见的损失函数是“交叉损失”,它是“交叉损失”的另一种选择,主要是为支持向量机(SVM)模型评估而开发的。
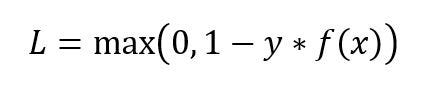

Hinge Loss not only penalizes the wrong predictions but also the right predictions that are not confident. It is primarily used with SVM Classifiers with class labels as -1 and 1. Make sure you change your malignant class labels from 0 to -1.
Hinge Loss不仅会惩罚错误的预测,还会惩罚不确定的正确预测。 它主要与具有类别标签-1和1的SVM分类器一起使用。请确保将恶性类别标签从0更改为-1。
回归损失 (Regression Losses)
1.均方误差/二次损失/ L2损失 (1. Mean Square Error / Quadratic Loss / L2 Loss)
MSE loss function is defined as the average of squared differences between the actual and the predicted value. It is the most commonly used Regression loss function.
MSE损失函数定义为实际值和预测值之间的平方差的平均值。 它是最常用的回归损失函数。
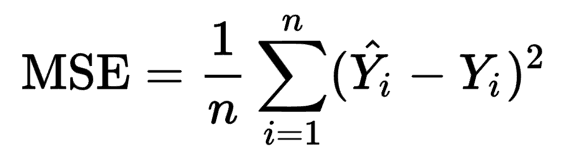
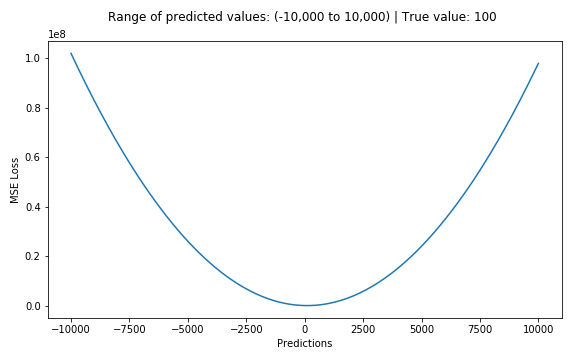
The corresponding cost function is the Mean of these Squared Errors (MSE). The MSE Loss function penalizes the model for making large errors by squaring them and this property makes the MSE cost function less robust to outliers. Therefore, it should not be used if the data is prone to many outliers.
相应的成本函数是这些平方误差的均值 (MSE) 。 MSE损失函数通过对错误进行平方来惩罚模型,以免产生大错误,并且此属性会使MSE成本函数对异常值的鲁棒性降低。 因此, 如果数据容易出现很多异常值 , 则不应使用此方法。
2.平均绝对误差/ L1损失 (2. Mean Absolute Error / L1 Loss)
MSE loss function is defined as the average of absolute differences between the actual and the predicted value. It is the second most commonly used Regression loss function. It measures the average magnitude of errors in a set of predictions, without considering their directions.
MSE损失函数定义为实际值与预测值之间的绝对差的平均值。 它是第二个最常用的回归损失函数。 它测量一组预测中的平均误差幅度,而不考虑其方向。
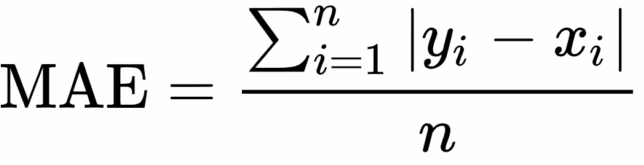
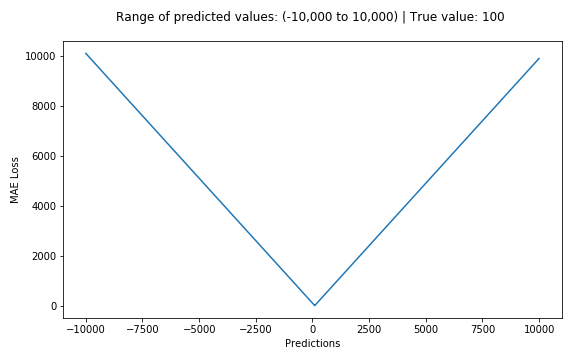
The corresponding cost function is the Mean of these Absolute Errors (MAE). The MAE Loss function is more robust to outliers compared to MSE Loss function. Therefore, it should be used if the data is prone to many outliers.
相应的成本函数是这些绝对误差的平均值 (MAE) 。 与MSE损失函数相比,MAE损失函数对异常值更健壮。 因此, 如果数据容易出现异常值 , 则应使用此方法。
3.胡贝尔损耗/平滑平均绝对误差 (3. Huber Loss / Smooth Mean Absolute Error)
Huber loss function is defined as the combination of MSE and MAE Loss function as it approaches MSE when 𝛿 ~ 0 and MAE when 𝛿 ~ ∞ (large numbers). It’s Mean Absolute Error, that becomes quadratic when the error is small. And to make the error quadratic depends on how small that error could be which is controlled by a hyperparameter, 𝛿 (delta), which can be tuned.
Huber损失函数定义为MSE和MAE的组合, 当𝛿〜0时接近MSE,当𝛿〜∞时接近MAE(大数),损失函数。 它是平均绝对误差,当误差很小时,它变成平方。 而使误差呈二次方取决于取决于可以调整的超参数𝛿(delta)控制的误差有多小。
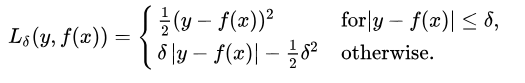
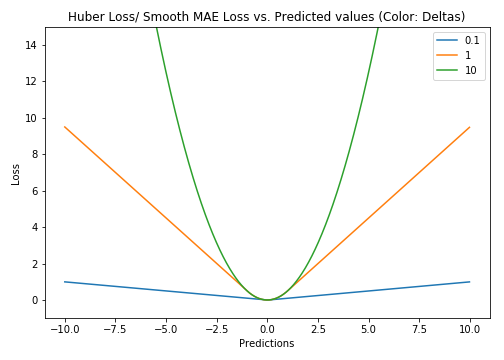
The choice of the delta value is critical because it determines what you’re willing to consider as an outlier. Hence, the Huber Loss function could be less sensitive to outliers compared to MSE Loss function depending upon the hyperparameter value. Therefore, it can be used if the data is prone to outliers and we might need to train hyperparameter delta which is an iterative process.
增量值的选择至关重要,因为它决定了您愿意考虑的异常值。 因此,取决于超参数值,与MSE损失函数相比,Huber损失函数对异常值的敏感性可能较低。 因此, 如果数据容易出现异常值,并且我们可能需要训练超参数增量(这是一个迭代过程) , 则可以使用它。
4.对数共损失 (4. Log-Cosh Loss)
The Log-Cosh loss function is defined as the logarithm of the hyperbolic cosine of the prediction error. It is another function used in regression tasks which is much smoother than MSE Loss. It has all the advantages of Huber loss, and it’s twice differentiable everywhere, unlike Huber loss as some Learning algorithms like XGBoost use Newton’s method to find the optimum, and hence the second derivative (Hessian) is needed.
Log-Cosh损失函数定义为预测误差的双曲余弦的对数。 它是用于回归任务的另一个函数,它比MSE损失要平滑得多。 它具有Huber损失的所有优点,并且在任何地方都可微分两次,这与Huber损失不同,因为像XGBoost之类的某些学习算法使用牛顿法来找到最优值,因此需要二阶导数( Hessian )。
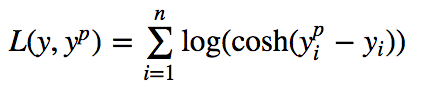
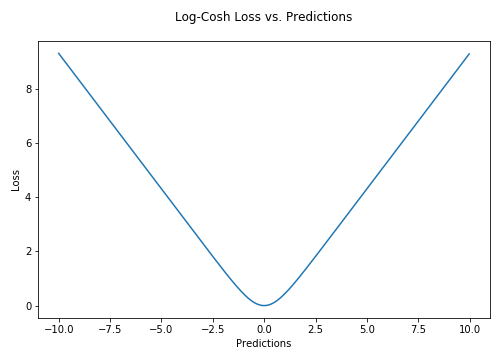
log(cosh(x))is approximately equal to(x ** 2) / 2for smallxand toabs(x) - log(2)for largex. This means that ‘logcosh’ works mostly like the mean squared error, but will not be so strongly affected by the occasional wildly incorrect prediction. — Tensorflow Docs
log(cosh(x))近似等于(x ** 2) / 2为小型x和abs(x) - log(2)对大x。 这意味着“ logcosh”的工作原理与均方误差类似,但不会受到偶然的不正确预测的强烈影响。 — Tensorflow文档
5.分位数损失 (5. Quantile Loss)
A quantile is a value below which a fraction of samples in a group falls. Machine learning models work by minimizing (or maximizing) an objective function. As the name suggests, the quantile regression loss function is applied to predict quantiles. For a set of predictions, the loss will be its average.
分位数是一个值,低于该值的组中的样本比例将下降。 机器学习模型通过最小化(或最大化)目标函数来工作。 顾名思义,分位数回归损失函数用于预测分位数。 对于一组预测,损失将是其平均值。
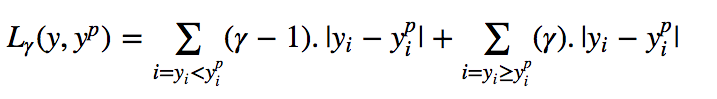
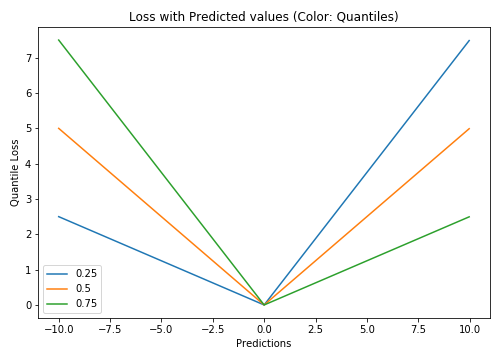
Quantile loss function turns out to be useful when we are interested in predicting an interval instead of only point predictions.
当我们对预测间隔而不是仅对点进行预测感兴趣时, 分位数损失函数将非常有用。
Thank you for reading! I hope this post has been useful. I appreciate feedback and constructive criticism. If you want to talk about this article or other related topics, you can drop me a text here or on my LinkedIn account.
感谢您的阅读! 希望这篇文章对您有所帮助。 我感谢反馈和建设性的批评。 如果您想谈论本文或其他相关主题,可以在此处或在我的LinkedIn帐户上给我留言 。

翻译自: https://towardsdatascience.com/most-common-loss-functions-in-machine-learning-c7212a99dae0
机器学习中常见的损失函数















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









