





 本文探讨了图像数据增强在图像分类任务中的重要性。通过使用Python库进行数据扩充,可以有效地扩大数据库,提高模型的泛化能力。通过对不同增强技术的分析,揭示了如何利用旋转、缩放、裁剪等操作来改善模型的性能,并结合机器学习和大数据处理,优化了图像识别的准确性和效率。
本文探讨了图像数据增强在图像分类任务中的重要性。通过使用Python库进行数据扩充,可以有效地扩大数据库,提高模型的泛化能力。通过对不同增强技术的分析,揭示了如何利用旋转、缩放、裁剪等操作来改善模型的性能,并结合机器学习和大数据处理,优化了图像识别的准确性和效率。
图像数据增强扩充数据库
Image classification is one of the most researched and well-documented task of machine learning. There are lots of benchmarks and large public datasets like ImageNet [1] to compare new models and algorithms to state of the art (SOTA). Every year a couple of new algorithms are published, and the accuracy of SOTA improves rapidly.
图像分类是机器学习中研究最多,记录最充分的任务之一。 有很多基准和大型公共数据集,例如ImageNet [1],用于将新模型和算法与最新技术(SOTA)进行比较。 每年都会发布一些新算法,SOTA的准确性会Swift提高。
In recent years, a key element of improvement was the data augmentation techniques, especially when one tries to improve the rankings without using external data. Data augmentation, small modifications of the training data helps the models to generalize better for unseen examples. An example of data augmentation working with images is mirroring the picture: a cat is a cat in the mirror too.
近年来,改进的关键要素是数据增强技术,尤其是当人们尝试不使用外部数据来提高排名时。 数据扩充 ,对训练数据进行少量修改,有助于模型更好地概括看不见的示例。 使用图像进行数据增强的一个示例是镜像图片:猫也是镜子中的猫。
In this story, we analyze the image augmentation techniques used in RandAugment [2], a 2019 algorithm by Google researchers. For this, we will use a pre-trained DenseNet [3] model available in Tensorflow 2.0 Keras. To illustrate the model outputs, we will perform a principal component analysis on the last hidden layer of the model. All codes are available on Google Colab.
在这个故事中,我们分析了Google研究人员在2019年提出的算法RandAugment [2]中使用的图像增强技术。 为此,我们将使用Tensorflow 2.0 Keras中可用的预训练DenseNet [3]模型。 为了说明模型的输出,我们将在模型的最后一个隐藏层上执行主成分分析。 所有代码均可在Google Colab上找到。
图片分类 (Image classification)
With Keras, image classification is a three-step problem. 1) load the image, 2) load the pre-trained model, 3) decode the output. The following is a small snippet to do it using TensorFlow 2.0 pre-trained Keras DenseNet model.
使用Keras时 ,图像分类是一个三步问题。 1)加载图像,2)加载预训练模型,3)解码输出。 以下是使用TensorFlow 2.0预训练的Keras DenseNet模型进行操作的一小段代码。
Image classification with a pre-trained model in Keras
在Keras中使用预训练模型进行图像分类
If we load the model with include_top the classification has an output layer with 1000 classes. The decode_predictions collects the most probable categories, and it adds the name of the classes as well.
如果我们使用include_top加载模型,则分类的输出层将包含1000个类。 decode_predictions收集最可能的类别,并添加类的名称。

For the PCA analysis, we will use the outputs of the last hidden layer of the model (before softmax). In the DenseNet 121, it means a 1024 dimension large vector space. In Keras, we will get the new model using:
对于PCA分析,我们将使用模型最后一个隐藏层的输出(在softmax之前)。 在DenseNet 121中,它表示1024维大矢量空间。 在Keras中,我们将使用以下方法获得新模型:
model_last_hidden = tf.keras.models.Model(inputs=model.input, outputs=model.layers[-2].output)
model_last_hidden = tf.keras.models.Model(inputs=model.input, outputs=model.layers[-2].output)
I use this practice to get a good representation of the model outputs without the flattening effect of the softmax layer.
我使用这种做法来很好地表示模型输出,而没有softmax层的展平效果。

使用PCA子空间识别类 (Identifying classes using PCA subspace)
主成分分析(PCA) (Principal Component Analysis (PCA))
As I discussed in earlier stories, PCA is an orthogonal transformation that we will use to reduce the dimension of the vectors [4,5]. PCA finds special basis vectors (eigenvectors) for the projection in a way that it maximizes the variance of the reduced-dimension data. Using PCA has two important benefits. On the one hand, we can project the 1024 dimension vectors to a 2D subspace where we can plot it to see the data. On the other hand, it keeps the maximum possible variance (projection loses information). Therefore, it might keep enough variance so we can identify the classes on the picture.
正如我在前面的故事中讨论的那样, PCA是一种正交变换,我们将使用它来减小向量的维数[4,5]。 PCA以最大化降维数据方差的方式找到投影的特殊基向量(特征向量)。 使用PCA有两个重要好处。 一方面,我们可以将1024维矢量投影到2D子空间中,在其中可以对其进行绘制以查看数据。 另一方面,它保持最大可能的方差(投影会丢失信息)。 因此,它可能保持足够的方差,以便我们可以识别图片上的类。

Using PCA with sklearn.decomposition.PCA is a one-liner:pred_pca = PCA(n_components=2).fit_transform(pred)
将PCA与sklearn.decomposition.PCA使用是一种方法: pred_pca = PCA(n_components=2).fit_transform(pred)
猫还是大象? (A cat or an elephant?)
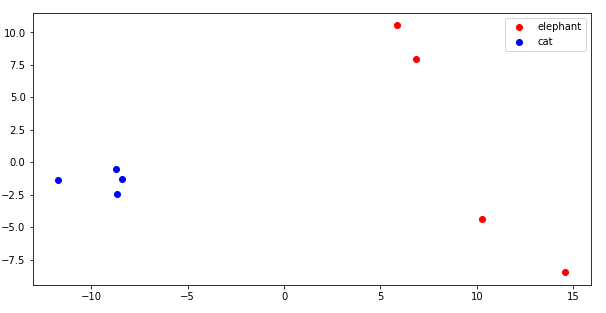
To determine a transformation from the 1024 dimension vector space to a 2D vector space, we will use eight images, four cats and four elephants. Later on, we will show the effect of the data augmentation in this projection. Images are from the Wikipedia.
为了确定从1024维向量空间到2D向量空间的转换,我们将使用八张图像,四只猫和四只大象。 稍后,我们将在此投影中展示数据增强的效果。 图片来自维基百科。

Illustrating the 2D projection, we can see that the cats are well-separated from the elephants.
举例说明2D投影,我们可以看到猫与大象之间的距离很好。
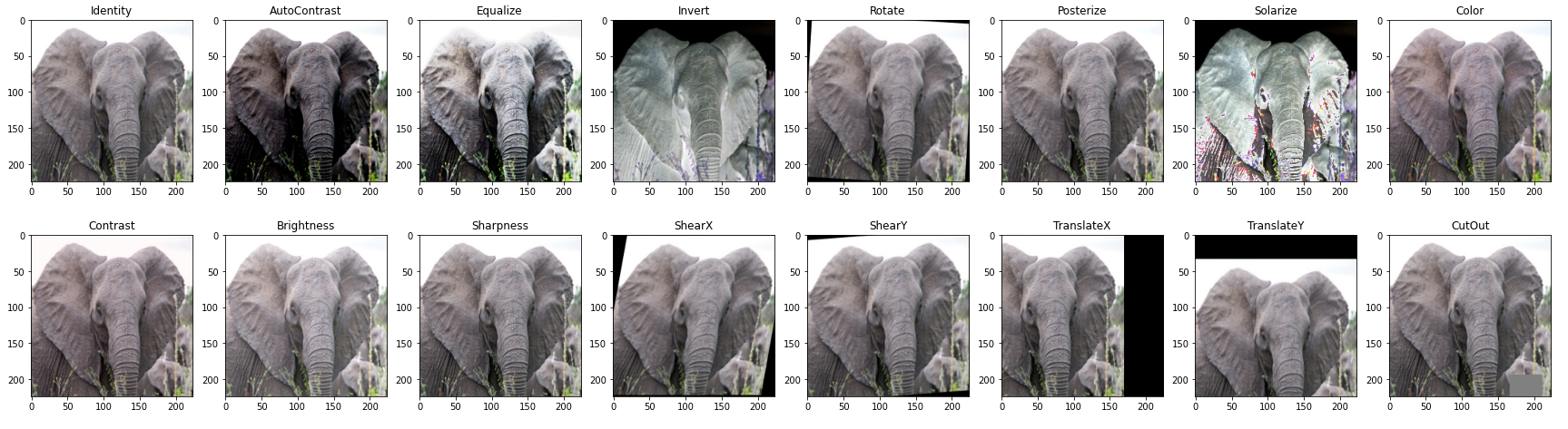
图像增强 (Image augmentation)
Data augmentation is an important part of training a machine learning model, especially when the training images are limited. For image augmentation, lots of augmentation algorithms are defined. An extensive collection of methods are available at the imgaug package for Python developers.
数据扩充是训练机器学习模型的重要部分,尤其是在训练图像有限的情况下。 对于图像增强,定义了许多增强算法。 imgaug 包中为Python开发人员提供了广泛的方法集合。
For this analysis, we will use the imgaug implementation of the methods used in RandAugment [2], an augmentation achieving SOTA on ImageNet in 2019 using an EfficientNet model, but many other algorithms use the same basic methods as well.
为了便于分析,我们将使用imgaug的RandAugment [2]中,增强使用EfficientNet模型在2019年就实现ImageNet SOTA使用的方法实施,但许多其他的算法使用相同的基本方法为好。
When it comes to data augmentation, the most crucial part is to determine the intervals of the parameters of the augmentation methods. For example, if we use rotation, a simple image augmentation technique, it is clear that rotating an image of a cat or an elephant with a few degrees does not change the meaning of the picture. However, usually, we do not expect to see an elephant rotated 180° in nature. Another example comes when we use brightness or contrast manipulation: too high modification might end up with unrecognizable data.
当涉及数据扩充时,最关键的部分是确定扩充方法的参数间隔。 例如,如果我们使用旋转(一种简单的图像增强技术),则很明显,将猫或大象的图像旋转几度不会改变图片的含义。 但是,通常情况下,我们不希望看到自然旋转180°的大象。 另一个例子是当我们使用亮度或对比度操纵时:太高的修改可能最终导致无法识别的数据。
Recent works like Population Based Augmentation [6] aims to adapt the magnitude of the modifications in training time while others like RandAugment [2] use it as hyperparameters of the training. The AutoAugment study showed that increasing the magnitude of the augmentation during the training can improve the performance of the model.
最近的工作(如基于人口的增强[6])旨在适应训练时间的变化幅度,而其他研究(如RandAugment [2])则将其用作训练的超参数。 AutoAugment研究表明,在训练过程中增加增强的幅度可以改善模型的性能。
If we process the augmented images above and project it to the same 2D vector space as the previous cat-elephant images, we can see that the new dots are around the original image’s. This is the effect of image augmentation:
如果我们对上面的增强图像进行处理并将其投影到与先前的猫大象图像相同的2D矢量空间中,我们可以看到新的点位于原始图像的周围。 这是图像增强的效果:
Augmentation expands the single point of an elephant image in the classification space to a whole area of elephant images.
增强将大象图像在分类空间中的单点扩展到大象图像的整个区域。

一站式方法 (One-shot approach)
When one has very few samples in a label class, the problem is called few-shot learning, and data augmentation is a crucial tool to solve this problem. The following experiment tries to prove the concept. Of course, here we have a pre-trained model on a large dataset, so it was not learned in a few-shot training. However, if we try to generate a projection using only one original elephant image, we can get something similar.
当一个标签类中的样本很少时,该问题称为“一次性学习”,而数据扩充是解决该问题的关键工具。 以下实验试图证明这一概念。 当然,这里我们在大型数据集上有一个预先训练的模型,因此在几次训练中就没有学习到它。 但是,如果我们尝试仅使用一个原始的大象图像生成投影,则可以获得类似的结果。
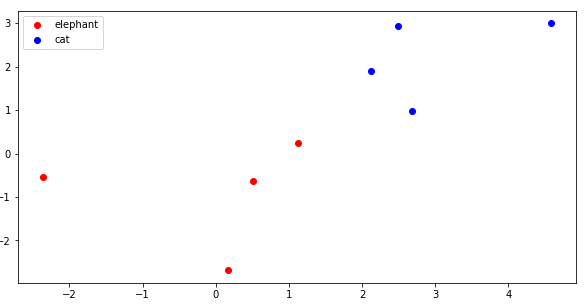
For this projection, we will use a new PCA using the original elephant image, and it’s augmented images. The augmented images in this subspace are shown in the following image.
对于此投影,我们将使用使用原始大象图像及其增强图像的新PCA。 下图显示了此子空间中的增强图像。

But can this projection, using only one elephant image separate the elephants from the cats? Well, the clusters are not as clear as in the previous case (see the first scatter plot figure), but the cats and the elephants are in fact in different parts of the vector space.
但是,仅使用一个大象图像进行的投影能否将大象与猫分开? 好吧,聚类不如前一种情况清晰(请参见第一个散点图),但是猫和大象实际上位于向量空间的不同部分。
摘要 (Summary)
In this story, we illustrated the effect of the data augmentation tools used in the state of the art image classification. We visualized images of cats and elephants and the augmented images of an elephant to understand better how the model sees the augmented images.
在这个故事中,我们说明了在最先进的图像分类中使用的数据增强工具的效果。 我们将猫和大象的图像以及大象的增强图像可视化,以更好地了解模型如何看增强图像。
翻译自: https://towardsdatascience.com/analyzing-data-augmentation-for-image-classification-3ed30aa61411
图像数据增强扩充数据库















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









