





In order for a conversational assistant to respond to a user’s request automatically, it is necessary to train the user to correctly recognize questions and thus trigger the right scenarios. For this, industrial solutions (i.e. chatbot solutions) mostly use machine learning to perform this detection by creating a model (the result of the learning process) to classify requests by intent. The literature on learning recommends us to check the performance of the model via the Precision and Recall indicators. From experience, I have found that these indicators are actually irrelevant in conversational situations and lead to misinterpretation, overconfidence and, ultimately, are lures for the analyst. I recommend the use of the Critical Success Index (CSI), but as it is still not sufficient, to complete this indicator by an analysis of the unbiased coefficient of variation of our old friends and the new one.
为了使对话助手能够自动响应用户的请求,有必要培训用户正确识别问题并触发正确的方案。 为此,工业解决方案(即聊天机器人解决方案)大多使用机器学习通过创建模型(学习过程的结果)来按意图对请求进行分类来执行此检测。 有关学习的文献建议我们通过 Precision 和Recall指标 检查模型的性能 。 从经验中,我发现这些指标实际上与对话环境无关,并会导致误解,过度自信,并最终吸引分析人员。 我建议使用关键成功指数(CSI),但由于仍不足以通过分析我们的老朋友和新朋友的无偏变异系数来完成此指标。
介绍 (Introduction)
In conversational AI, systems must “understand” the user’s request before they can perform the requested action (e.g. “turn on the light”, “order me a pizza”, “how can I turn off the TV”, etc.). To do this, these systems use one of the techniques of machine learning, which consists of automatically creating classification models from groupings of sentences that have the same meaning, which implicitly mean the same thing. For this, the dialoguer (i.e. the one who writes the dialogues of a conversational assistant) must supervise the training of a detector (the classifier) by providing him with a set of example sentences and grouping them by intent (by type of request).
在对话式AI中,系统必须先“理解”用户的请求,然后才能执行所请求的操作(例如,“开灯”,“向我订购披萨”,“如何关闭电视”等)。 为此,这些系统使用一种机器学习技术,该技术包括根据具有相同含义(暗含相同意思)的句子分组自动创建分类模型。 为此,对话者(即编写对话助手对话的人)必须监督检测器(分类器)的训练,方法是为检测器(分类器)提供一组示例语句并按意图(按请求类型)将它们分组。

After learning, the system must be tested to ensure that it will be “smart” enough to understand all the requests. Especially since these systems are used for their ability to detect demand even if it varies from what was expected. For a description of the processing of user requests, you can refer to my previous article on Conversational AI for dialogers: the 4 complexity levels scale.
学习之后,必须对系统进行测试,以确保它足够“智能”以理解所有请求。 尤其是由于这些系统用于检测需求,即使需求与预期有所不同也是如此。 有关处理用户请求的描述,您可以参考我以前的关于对话者的对话式AI的文章:4个复杂度等级。
To test his assistant, the dialoguer must ask questions that are not in the training and check that the system detects the intent despite variations that he will introduce in order to verify that the system is able to fetch different sentences. A training defect, for example as a result of undertraining, can lead to negative effects for the user since the system will trigger an action that does not correspond to his initial request.
要测试其助手,对话者必须提出培训中未涉及的问题,并检查系统是否会检测到意图,尽管他会引入各种变化,以便验证系统是否能够提取不同的句子。 训练缺陷(例如由于训练不足而导致的缺陷)可能会给用户带来负面影响,因为系统将触发与他的初始请求不符的动作。

理论 (The Theory)
In automatic classification, Precision (also called Positive Predictive Value) is the proportion of relevant information among all the proposed items. Recall (sensitivity) is the proportion of relevant items proposed among all relevant items [1].
在自动分类中,精度(也称为正预测值)是所有建议项目中相关信息的比例。 召回(敏感度)是所有相关项目中提议的相关项目的比例[1]。
When a conversational assistant answers correctly 20 times (also called True Positive or TP), executes an action when it is not the request 10 times (called False Positive or FP), does not execute the expected action 40 times (called False Negative or FN), its Precision is then 20/(20+10) = 0.667 (66.7%) and its Recall is equal to 20/(20+40) = 0.334 (33.4%). A system capable of detecting without error has an Precision equal to 1 (100%) and a Recall also equal to 1 (100%).
当对话助手正确回答20次(也称为“正肯定”或TP)时,如果不是请求10则执行一个动作(称为“假肯定”或FP),不执行预期的操作40次(称为“否定”或FN) ),则其精度为20 /(20 + 10)= 0.667(66.7%),其召回率等于20 /(20 + 40)= 0.334(33.4%)。 能够无错误检测的系统的精度等于1(100%),召回率也等于1(100%)。


In multi-class systems (in our case, multiple-intent systems and therefore it concerns all conversational assistants), the Overall System Precision is the average of the Precisions of all intents and the Recall is the average of the Recalls of all intents. These values are called the macro-average of Precision and the macro-average of Recall.
在多类系统(在我们的示例中是多意图系统,因此它涉及所有会话助手)中,总体系统精度是所有意图的精度的平均值,而召回率是所有意图的召回率的平均值。 这些值称为Precision的宏平均值和Recall的宏平均值。
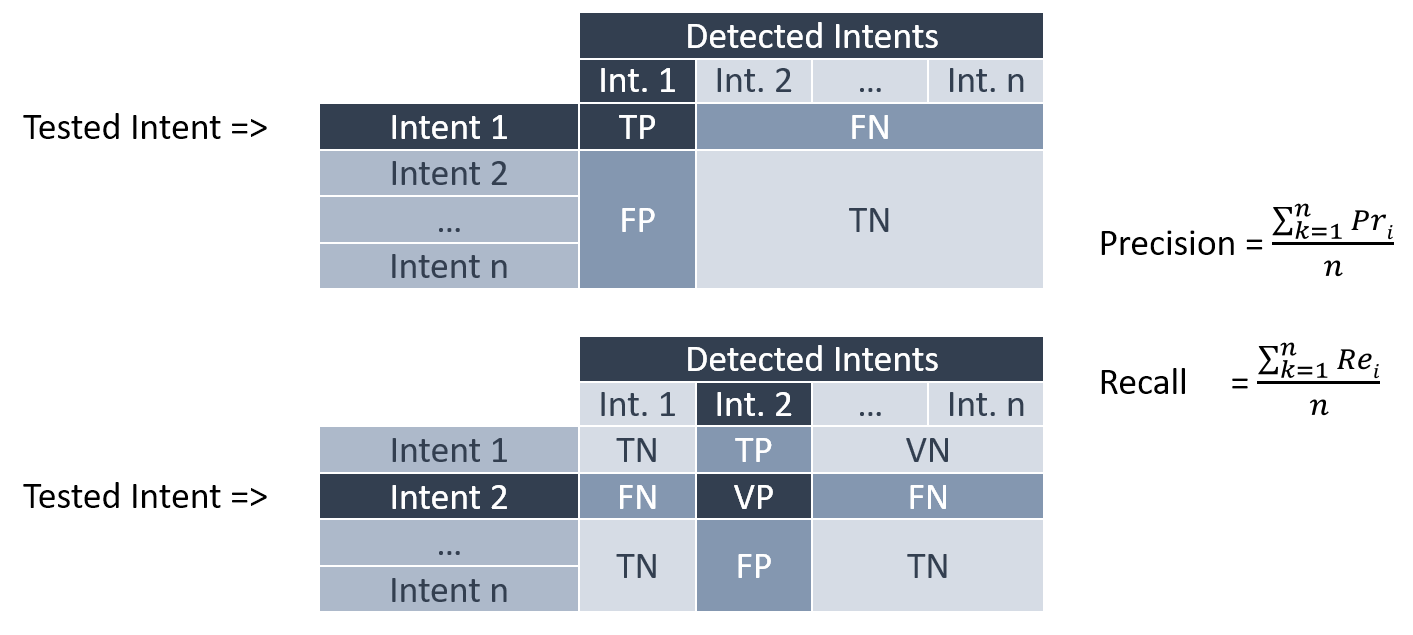
Precision and Recall are calculated for each of the intents and the overall results are averaged. The True Positive result corresponds to the correct detection of the intent. The False Negative corresponds to the case where our intent test sentence gave another intent as a result (one of the other intents). False Positive corresponds to sentences of the other intents that gave that intent. And the True Negative corresponds to all other tests that did not give our intent as a result.
为每个意图计算精确度和召回率,并对总体结果取平均值。 真实肯定结果对应于对意图的正确检测。 假否定词对应于我们的意图测试句子给出另一个意图(其他意图之一)的情况。 误报对应于给出该意图的其他意图的句子。 而“真阴性”对应于所有其他没有给出我们意图的测试。
There is another indicator which is the micro-average of the Precisions and which corresponds to the sum of the TPs of the different classes divided by the sum of TPs and FPs. This calculation consists in summing all the values in denominator which leads to the calculation of the success rate in the end.
还有另一个指标是精度的微平均值,它对应于不同类别的TP的总和除以TP和FP的总和。 该计算包括对分母中的所有值求和,最终得出成功率。
To test the system, the dialoguer prepares a set of test phrases (called the validation data set) consisting of phrases that are not part of the training (called the training data set). Each sentence is linked to one of the intents.
为了测试系统,对话者准备一组测试短语(称为验证数据集),这些短语由不属于训练的短语(称为训练数据集)组成。 每个句子都链接到一个意图。
It is also possible to use automatic testing techniques by separating the available data into training data and test data according to a rule depending on the type of cross-validation chosen. In non-cross separation, a ratio is chosen to separate the data into two sets. Often the ratios 50/50, 66/33 or 80/20 are used. However, separating the available data into two disjoint subsets can generate detection biases if the number of data is small. These biases may be underfitting or too large margin error.
通过根据选择的交叉验证的类型,根据规则将可用数据分为训练数据和测试数据,也可以使用自动测试技术。 在非交叉分离中,选择比率可将数据分为两组。 通常使用比率50 / 50、66 / 33或80/20。 但是,如果数据数量少,则将可用数据分为两个不相交的子集会产生检测偏差。 这些偏差可能是拟合不足或边缘误差太大。

One solution to this problem is to use the cross-validation technique of separating sets by folds called the k-fold. The k-fold proposes to perform a separation of the data into k folds. One fold is kept for testing and the remaining folds (k-1) are used for training [2]. In systems where the dialoguer can intervene directly on the model, this test mode allows to adjust the hyper-parameters of the model and stop the training at the right time (i.e. before over-fitting).
解决此问题的一种方法是使用交叉验证技术,通过称为k折叠的折叠来分离集。 k折建议将数据分离为k折。 保留一折用于测试,其余的折(k-1)用于训练[2]。 在对话者可以直接干预模型的系统中,此测试模式允许调整模型的超参数并在正确的时间(即在过度拟合之前)停止训练。

In systems with unbalanced intents (i.e. having different numbers of sentences per intent, which is also often the case in the conversational solutions), it is important to keep the block ratios in the intent. This technique is called stratified cross validation.
在意图不均衡的系统中(即,每个意图具有不同数量的句子,在会话解决方案中也经常出现这种情况),将阻止率保持在意图中非常重要。 该技术称为分层交叉验证。
In “off-the-shelf” conversational AI solutions (i.e. almost all commercial Chatbot solutions), it is not possible to select these hyper-parameters and the system sets itself “on its own”. This black box side makes it difficult to know whether the system is factory preset or whether it automatically adapts using internal cross-validation and early shutdown features.
在“现成的”会话式AI解决方案(即几乎所有的商用Chatbot解决方案)中,无法选择这些超参数,并且系统将“自行设置”。 黑匣子的一面使得很难知道系统是出厂预设的还是使用内部交叉验证和早期关闭功能自动适应的。
实践 (The Practice)
Let’s take as an example a 4-intent system with the constitution of a test set that has been specially created for validation. Suppose it is trained after a first business iteration, i.e. the subject matter experts have given the set of sentences that correspond, according to them, to the most common user requests for the domains that need to be automated. Let’s assume that a first phase of testing gave the following results:
让我们以一个4意图系统为例,该系统具有专门为验证而创建的测试集的构造。 假设在第一次业务迭代之后对其进行了培训,即,主题专家给出了与之对应的,最需要自动查询域名的句子集合。 假设测试的第一阶段得出以下结果:
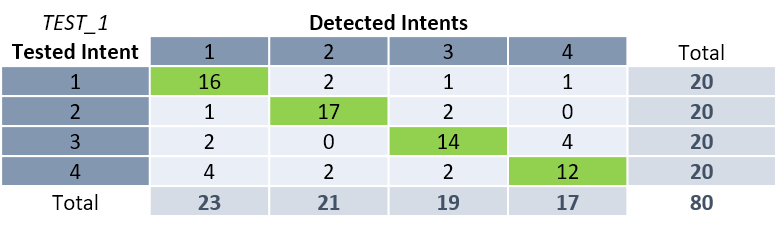
The classifier is tested using the test sentences (20 sentences per intent) and the results of the detections are noted in a table called the confusion matrix, divided into rows for the intents to be tested and columns for the intents that are detected. The numbers at the intersections correspond to the numbers of detection occurrences for the tested intent.
使用测试语句(每个意图20个句子)测试分类器,并将检测结果记录在称为混淆矩阵的表中,该表分为要测试的意图行和要检测的意图列。 相交处的数字对应于测试意图的检测发生次数。
In the example TEST_1, the 20 test phrases of the first intent were correctly classified 16 times and 4 errors were found. Of the 80 test phrases, 59 phrases were globally correctly detected and 21 resulted in classification errors. The average Precision of this classifier is 74% and the Recall is also 74%. The success rate (correctly identified sentences / total number of sentences) gives a result of 74% (59/80) which is relatively correct for a first iteration.
在示例TEST_1中,将第一个意图的20个测试短语正确分类了16次,发现了4个错误。 在80个测试短语中,有59个短语在全局范围内被正确检测,其中21个导致分类错误。 该分类器的平均精度为74%,召回率也为74%。 成功率(正确识别的句子/句子总数)得出74%(59/80)的结果,该结果对于第一次迭代而言是相对正确的。
After a second iteration to complete the overall training, the system is tested again with the initial test sentences. This new test gives the following results:
在进行第二次迭代以完成总体培训之后,系统将使用初始测试语句再次进行测试。 此新测试给出以下结果:

The new success rate is identical to the previous training, i.e. 59/80 = 74%. The Precision on the Intent 3 test is 100% and the Recall is 5%. The set of averages means that the overall Precision of this training is 80% and the Recall is 74%, i.e. a 6% increase in Precision and identical Recall, whereas the result has deteriorated sharply on the intent 3 test, which is practically no longer recognised. The analysis of the overall Precision therefore gives a positive result whereas there is a strong degradation of the user experience since the system will practically no longer be able to answer a category of questions. Only the fine analysis of each intent allows to check the evolution of the system after the new training.
新的成功率与之前的培训相同,即59/80 = 74%。 Intent 3测试的Precision为100%,召回率为5%。 一组平均值意味着此训练的整体精度为80%,召回率为74%,即精度和相同的召回率分别提高了6%,而意图3的测试结果却急剧恶化,实际上已经不再公认的。 因此,对整体精度的分析给出了肯定的结果,而由于系统实际上将不再能够回答一类问题,因此用户体验会大大下降。 只有对每个意图进行精细分析,才能在新培训后检查系统的发展。
Suppose that the analyst performs additional work on intent 3 to correct the problem identified, increases learning about this intent, and performs a new set of tests.
假设分析人员对意图3进行了其他工作以更正所发现的问题,增加了对该意图的了解,并执行了一组新的测试。

The new success rate is 74%, which is the same as the other 2 trials. The Precision is 87%, an increase of 7% compared to the previous test and the Recall is 74%, a value that remains unchanged on all the tests. For the analyst, the system shows a global progression of the Precision which suggests an improvement of the system! By analyzing the results in more detail, we can see that Intent 3 is now over-detected with almost a Precision for this intent of 20/41 = 49%, which is lower than the previous test. From the user’s point of view, and this is what is most important in the end, the system gives the impression of systematically triggering the same action (50% of requests with 25% that are nevertheless justified).
新的成功率为74%,与其他2个试验相同。 精度为87%,与之前的测试相比增加了7%,而召回率为74%,在所有测试中该值均保持不变。 对于分析人员而言,该系统显示了Precision的全球发展,这表明该系统有所改进! 通过更详细地分析结果,我们可以看到,针对此意图的20/41 = 49%几乎可以精确检测到意图3,这比以前的测试要低。 从用户的角度来看,这最终是最重要的,系统给人的印象是系统触发相同的操作(50%的请求中有25%的请求是合理的)。
Analysis of the overall changes in Precision would therefore not have identified any misclassifications. Analysis of the Recall would also have been inconclusive in these cases since it did not vary over the 3 tests. From the tester’s point of view, the distinction between a non-detection or a false detection is important for the analysis of the results and to determine the actions to be carried out on the trainings (create new intents, group them together, add sentences to intents…).
因此,对Precision总体变化的分析不会发现任何错误分类。 在这些情况下,对召回的分析也没有定论,因为在3个测试中它没有变化。 从测试人员的角度来看,未检测到还是错误检测之间的区别对于分析结果以及确定在训练中要执行的操作很重要(创建新的意图,将它们分组在一起,在句子中添加句子)。意图...)。
However, from the end-user’s perspective, the important thing is that the system responds correctly most of the time and the overall analysis of these values would have missed errors that would have penalized the user experience. Of course, the performance of the classifier must be globally balanced. Nevertheless, a less good detection can be envisaged on less frequent requests. It is then necessary to correlate the results with the frequency of requests but this is another subject.
但是,从最终用户的角度来看,重要的是系统在大多数情况下都可以正确响应,并且对这些值的整体分析会漏掉会损害用户体验的错误。 当然,分类器的性能必须全局平衡。 然而,可以设想在较不频繁的请求下进行较差的检测。 然后有必要将结果与请求的频率相关联,但这是另一个主题。
专注于不平衡系统 (A Focus on Unbalanced Systems)
When testing the performance of a classifier, it is important to consider the balance of test sets and to have the same number of test values in each intent if possible.
测试分类器的性能时,重要的是要考虑测试集的平衡,并在可能的情况下在每个意图中使用相同数量的测试值。
To highlight this, let’s try another example. We are performing a detection test but we do not have a balanced system since the number of test sentences varies according to the intent: intent 1 has only 10 test sentences, intent 2 has 20, intent 3 is the most complete with 45 sentences and intent 4 has only 5 sentences.
为了突出这一点,让我们尝试另一个示例。 我们正在执行检测测试,但我们没有一个平衡的系统,因为测试句子的数量根据意图而变化:意图1仅包含10个测试句子,意图2具有20个意图,意图3最完整,包含45个句子和意图4只有5个句子。
The test gives the following results:
该测试给出以下结果:

We have the following indicators: Precision = 86%, Recall = 84% and Success Rate = 86%. To balance the results, it is necessary to introduce the notion of weighted indicator. The values of the respective indicators of the different classes must be multiplied by the ratio of the sentences used for the test. The ratio of intent 1 is 10/80 = 0.125. The weighted indicators are then Weighted Precision = 87% and Weighted Recall = 86%.
我们有以下指标:精度= 86%,召回率= 84%,成功率= 86%。 为了平衡结果,有必要引入加权指标的概念。 必须将不同类别的各个指标的值乘以用于测试的句子比率。 意向1的比率是10/80 = 0.125。 然后,加权指标为:加权精度= 87%,加权召回率= 86%。
We modify the training to try to improve our system.
我们修改培训内容以尝试改善我们的系统。

The indicators have the following values : Precision = 80%, Recall = 89% for a Success Rate of 90%. The weighted Precision is 93% and the weighted Recall is 90%. In the calculation without weighting, we would have seen a 6% decrease in Precision, whereas the system has improved overall, which is shown by the weighted value, since we see a 7% improvement in Precision. This very important difference comes from the fact that the weight of instance 4 is identical to the other classes while the number of tests is low for this instance. The low number of tests for instance 4 means that the impact of a bad result gives a lot of weight to the results of the test for this instance, which is highlighted here.
指标具有以下值:精度= 80%,召回率= 89%,成功率为90%。 加权精度为93%,加权召回率为90%。 在不进行加权的计算中,我们会发现Precision降低了6%,而系统总体上有所改善,这由加权值表示,因为我们看到Precision提升了7%。 这个非常重要的区别来自以下事实:实例4的权重与其他类相同,而该实例的测试次数却很少。 实例4的测试数量较少,这意味着不良结果的影响对该实例的测试结果具有很大的影响力,在此重点介绍。
然后选择哪些指标? (Which Indicator(s) To Choose Then?)
We have seen that the Precision and Recall indicators do not highlight localized classification errors, which can penalize the entire system. In the case of TEST_3, the system detects a bad intent in a quarter of the requests, which will most certainly lead to the rejection of the conversational assistant. In addition, Precision and Recall focus on 2 different axes: the first one highlights False Positive problems when the second one highlights False Negative problems. For the user, this remains a wrong answer and therefore we need a new indicator that takes to group these two axes together.
我们已经看到,Precision和Recall指标没有突出显示局部分类错误,这会给整个系统带来不利影响。 在TEST_3的情况下,系统在四分之一的请求中检测到不良意图,这肯定会导致拒绝对话助手。 此外,“精确度”和“召回率”集中在两个不同的轴上:第一个突出显示误报问题,第二个突出显示误报问题。 对于用户而言,这仍然是错误的答案,因此我们需要一个新的指示器来将这两个轴组合在一起。
This indicator exists (although it is not too visible) and it is the Critical Success Index (CSI) rather used in weather forecasting elsewhere. It is also called Threat Score TS. The CSI is a performance verification measure for categorical detections. It is equal to the total number of correct event forecasts (TP) divided by the total number of false detections (FN + FP) to which TP is added to obtain a performance ratio.
该指标存在(尽管不太明显),并且是关键成功指数(CSI),而在其他地方的天气预报中使用。 也称为威胁得分TS。 CSI是用于分类检测的性能验证措施。 它等于正确事件预测(TP)的总数除以添加了TP以获得性能比率的错误检测的总数(FN + FP)。
To finalize our tests before going into live, we are carrying out a new training that globally improves our model, placing it at a fully operational level with an Precision of 90%, a Recall of 89% and a Success Rate of 89%.
为了在投入使用之前完成测试的最终确定,我们正在进行一次新的培训,以在全球范围内改进我们的模型,使其处于完全可操作的水平,其准确度为90%,召回率为89%,成功率为89%。

We then calculate several indicators that you will find listed on this Wikipedia page.
然后,我们计算该Wikipedia页面上列出的几个指标。

A study of the table shows that no indicator really highlights the problems of the TEST_2 and TEST_3 classifiers. Only the indicators CSI, F1-score, Matthews Correlation Coefficient (MCC) and the Fowlkes-Mallows index highlight a decrease in quality on the TEST_2 classifier. There is no indicator to detect the TEST_3 problem. The CSI indicator is the closest to an expectation of overall system performance, which makes it a more relevant indicator than Precision, Recall and even Accuracy.
对该表的研究表明,没有任何指标能真正突出TEST_2和TEST_3分类器的问题。 只有指标CSI,F1得分,马修斯相关系数(MCC)和Fowlkes-Mallows指数突出显示了TEST_2分类器的质量下降。 没有指示器可以检测到TEST_3问题。 CSI指标最接近整体系统性能的期望值,这使其比Precision,Recall甚至Accuracy更为相关。
Since the indicators do not give any indication, we are obliged to look at the details of the tests of values for each intent in order to determine which intents are problematic.
由于指标没有给出任何指示,因此我们有义务查看每种意图的值测试的详细信息,以确定哪些意图存在问题。

Since this work is tedious over a large number of tests and for many intents, I propose to use a dispersion indicator called coefficient of variation (or relative standard deviation). This indicator is defined as the ratio of the standard deviation to the mean [3]. This number without unit allows a comparison between several series which makes it interesting for automated tests. This value must nevertheless be adjusted to take into account the small number of samples. The formula for this indicator is then as follows:
由于这项工作在大量测试中且对于许多意图而言都是乏味的,因此我建议使用一种称为偏差系数(或相对标准偏差)的色散指标。 该指标定义为标准偏差与平均值的比率[3]。 这个没有单位的数字允许在几个系列之间进行比较,这使得它对于自动化测试很有趣。 但是,必须将这个值调整为考虑到少量的样本。 该指标的公式如下:

The calculation of this indicator for our 4 tests gives the following results for Precision, Recall and CSI:
对于我们的4个测试,该指标的计算得出了Precision,Recall和CSI的以下结果:

Exceeding a threshold (e.g. 20%) of one of these 3 values can thus be used to inform the analyst of a training quality problem. This indicator complements the classic analysis of performance indicators, i.e. low overall Precision for example. When the threshold is reached, it is then advisable to analyse the results more closely in order to determine the problematic intent(s) and thus see how to modify the training, or even reject the new training.
因此,超过这三个值之一的阈值(例如20%)可用于告知分析员培训质量问题。 该指标是对性能指标的经典分析的补充,例如,总体精度较低。 达到阈值后,建议更仔细地分析结果,以确定有问题的意图,从而了解如何修改训练,甚至拒绝新训练。
结论 (Conclusion)
In the area of conversational assistants, one of the causes of rejection of systems is when they do not correctly recognize requests. It is therefore important to test the performance of your assistant before publishing it and making it available to users. We have seen how to calculate Precision and Recall values for a multi-class system and how important it is to weight the values when the number of test sentences is unbalanced. Nevertheless, the Precision and Recall indicators, the most commonly used in machine learning, do not allow us to conclude whether a system does not contain an error on one or more intents since we are only studying a global value.
在对话助手方面,拒绝系统的原因之一是他们无法正确识别请求。 因此,重要的是在发布助手并将其提供给用户之前测试助手的性能。 我们已经看到了如何为一个多类系统计算Precision和Recall值,以及当测试语句的数量不平衡时加权这些值的重要性。 但是,由于机器学习中最常用的精确度和召回率指标,由于我们仅研究全球价值,因此我们无法得出一个系统是否不包含一个或多个意图错误的结论。
I, therefore, invite you to complete your calculation by adding the CSI indicator, which is more relevant to user expectations, i.e. an assistant that responds correctly as often as possible (regardless of type I or II error). Complete this indicator by calculating the Adjusted Coefficient of Variation (unbiased) for Precision, Recall and CSI. Setting an alert threshold on the maximum of these 3 values allows you to highlight a learning problem without having to check the indicators one by one and thus save time in the analysis of your training iterations.
因此,我邀请您添加与用户期望更相关的CSI指标来完成计算,即尽可能多地正确响应(无论I型或II型错误)的助手。 通过计算精度,召回率和CSI的调整后的变异系数(无偏差)来完成此指标。 在这三个值中的最大值上设置警报阈值,可以突出显示学习问题,而不必一一检查指标,从而节省了分析训练迭代的时间。















 1692
1692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









