





深度之眼 alexnet
技术说明 (Technical and Explanation)
The AlexNet convolutional neural network(CNN) was introduced in the year 2012. Since then, the utilization of deep convolutional neural network has skyrocketed to the point where several machine learning solutions leverage deep CNNs.
吨他AlexNet卷积神经网络(CNN)在2012年被引入此后,深卷积神经网络的利用率已经暴涨到了这种地步几种机器学习解决方案,能利用深层细胞神经网络。
This article will present the essential findings, and talking points of the research paper, in which the AlexNet architecture was introduced.
本文将介绍引入AlexNet体系结构的研究论文的基本发现和要点。
在本文中,您可以期待找到以下内容: (In this article, you can expect to find the following:)
A breakdown of the research paper introducing AlexNet
介绍AlexNet的研究论文的细目
Illustrations of the AlexNet architecture
AlexNet体系结构的插图
Table of the inner layer compositions of AlexNet
AlexNet的内层组成表
Explanations of a variety of techniques such as dropout, data augmentation, normalization and more.
各种技术的解释,例如辍学,数据增强,规范化等等。
M
中号
介绍 (Introduction)
The AlexNet convolutional neural network architecture was presented in the paper “ImageNet Classification With Deep Convolutional Neural Network”. The paper was authored by Alex Krizhevsky, Ilya Sutskever and the godfather of deep learning, Geoffery Hinton.
AlexNet卷积神经网络架构在论文“ 使用深度卷积神经网络进行ImageNet分类 ”中进行了介绍。 该论文由Ilya Sutskever的Alex Krizhevsky和深度学习的教父Geoffery Hinton撰写。


The authors of the paper aimed to show the trivial task of image classification can be tackled by using deep convolutional neural networks, efficient computation resources and common CNN’s implementation techniques.
该论文的作者旨在显示图像分类的琐碎任务可以通过使用深度卷积神经网络,高效的计算资源和常用的CNN实现技术来解决。
The paper proved that a deep convolutional neural network consisting of 5 convolutional layers and 3 fully connected layers could classify images efficiently and accurately.
证明了由5个卷积层和3个完全连接的层组成的深度卷积神经网络可以有效,准确地对图像进行分类。
A deep convolutional neural network was called AlexNet, and it was introduced in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC 2012 contest), where it set a precedent for the field of Deep Learning.
深度卷积神经网络称为AlexNet,它是在ImageNet大规模视觉识别挑战赛(ILSVRC 2012竞赛)中引入的,它为深度学习领域开创了先例。
好时机 (Great Timing)
Before the introduction of AlexNet, many traditional neural networks and convolutional neural networks performed well on solving image classification on datasets such as the MNIST handwritten character dataset. But to solve the problem of general image classification of objects in everyday life, a larger dataset is required to account for the considerable diversity of objects that occurred within images.
在引入AlexNet之前,许多传统的神经网络和卷积神经网络在解决诸如MNIST手写字符数据集之类的数据集上的图像分类方面表现良好。 但是,为了解决日常生活中物体的一般图像分类问题,需要更大的数据集以解决图像中出现的物体的巨大差异。
The lack of robust datasets was solved by the introduction of large datasets such as ImageNet, which contained 22,000 classes across 15 million high-resolution images.
通过引入大型数据集(例如ImageNet)解决了健壮数据集的不足,该大型数据集包含1500万张高分辨率图像中的22,000个类。
Another limitation prior to the introduction of AlexNet was computer resources.
引入AlexNet之前的另一个限制是计算机资源。
To increase the capacity of a network meant to increase the number of layers and neurons within the network.
增加网络的容量意味着增加网络中的层和神经元的数量。
At the time, the compute resource to train such a network was scarce. But the introduction of optimized GPUs made the possibility of training deep conventional neural network achievable. The particular GPU used to train the AlexNet CNN architecture was the NVIDIA GTX 580 3GB GPU.
当时,用于训练这样的网络的计算资源十分匮乏。 但是,引入优化的GPU使得训练深层常规神经网络成为可能。 用于训练AlexNet CNN架构的特定GPU是NVIDIA GTX 580 3GB GPU 。

AlexNet架构的独特特征 (Unique Characteristics of AlexNet’s Architecture)
整流线性单位(ReLU) (Rectified Linear Units (ReLU))
To train neurons within a neural network, it had been standard to utilize either Tanh or sigmoid non-linearity, this was the goto activation function that was leveraged to model the internal neuron activation within CNNs.
为了训练神经网络中的神经元,利用Tanh或S形非线性是一种标准,这是goto激活函数,可用来对CNN内的内部神经元激活进行建模。
The AlexNet went on to use Rectified Linear Units, ReLU for short. ReLU was introduced in this paper by Vinod Nair and Geoffrey E. Hinton in 2010.
AlexNet继续使用整流线性单位,简称ReLU。 本文是由Vinod Nair和Geoffrey E.Hinton在2010年介绍的ReLU。
ReLu can be described as a transfer function operation that is performed on the output of the prior convolution layer. The utilization of ReLu ensures that values within the neurons that are positive their values are maintained, but for negative values, they are clamped down to zero.
ReLu可以描述为对先前卷积层的输出执行的传递函数运算。 ReLu的利用可确保神经元内的值保持为正值,但对于负值,则将其限制为零。
The benefit of using ReLu is that it enables the training process to be accelerated as gradient descent optimization occurs at a faster rate in comparison to other standard non-linearity techniques.
使用ReLu的好处是,与其他标准非线性技术相比,当梯度下降优化以更快的速度发生时,它可以加快训练过程。
Another benefit of the ReLu layer is that it introduces non-linearity within the network. It also removes the associativity of successive convolutions.
ReLu层的另一个好处是它在网络内引入了非线性。 它还消除了连续卷积的关联性。
GPU (GPUs)
In the original research paper that introduced the AlexNet neural network architecture, the training of models was conducted with the utilization of two GTX 580 GPUs with 3GB memory.
在介绍AlexNet神经网络架构的原始研究论文中,模型的训练是利用两个具有3GB内存的GTX 580 GPU进行的。
GPU parallelization and distributed training are techniques that are very much in use today.
GPU并行化和分布式训练是当今非常常用的技术。
From information derived from the research paper, the model was trained on two GPU, where half of the model’s neurons were on one, and the other half held within the memory of a second GPU. The GPUs communicated with each other, without the need of going through the host machine. Communication between the GPU is constrained on a layer basis; therefore, only specific layers can communicate with each other.
从研究论文中获得的信息,该模型在两个GPU上进行训练,其中一半模型神经元位于一个GPU上,另一半则在另一个GPU的内存中。 GPU彼此通信,而无需通过主机。 GPU之间的通信基于层进行限制; 因此,只有特定的层可以相互通信。
For example, the inputs in the fourth layer of the AlexNet network was obtained from half of the third layer’s feature maps on the current GPU, and the rest of the other half is derived from the second GPU. This will be better illustrated later in this article.
例如,AlexNet网络第四层的输入是从当前GPU上第三层特征图的一半获得的,而另一半的其余部分则是从第二GPU得出的。 本文后面将对此进行更好地说明。
本地响应规范化 (Local Response Normalisation)
Normalization is taking a set of data points and placing them on a comparable basis or scale(this is an overly simplistic description).
规范化采用一组数据点,并将它们放置在可比较的基础或规模上( 这是过于简单的描述 )。
Batch Normalization (BN) within CNNs is a technique that standardizes and normalizes inputs by transforming a batch of input data to have a mean of zero and a standard deviation of one.
CNN中的批次归一化(BN)是通过将一批输入数据转换为平均值为零且标准偏差为1来标准化和归一化输入的技术。
Many are familiar with batch normalization, but the AlexNet architecture used a different method of normalization within the network: Local Response Normalization (LRN).
许多人熟悉批处理规范化,但是AlexNet体系结构在网络中使用了另一种规范化方法:本地响应规范化(LRN)。
LRN is a technique that maximizes the activation of neighbouring neurons. Neighbouring neurons describe neurons across several feature maps that share the same spatial position. By normalizing the activations of the neurons, neurons with high activations are highlighted; this essentially mimics the lateral inhibition that happens within neurobiology.
LRN是使邻近神经元激活最大化的技术。 相邻的神经元描述跨共享相同空间位置的多个特征图的神经元。 通过标准化神经元的激活,高激活的神经元被突出显示。 这实质上是模仿神经生物学内部发生的横向抑制。
LRN are not widely utilized in modern CNN architectures, as there are other more effective methods of normalization. Although, LRN implementations can still be found in some standard machine learning libraries and frameworks, so feel free to experiment.
由于存在其他更有效的标准化方法,因此LRN在现代CNN架构中并未得到广泛使用。 虽然,仍然可以在一些标准的机器学习库和框架中找到LRN实现,因此请随时进行实验。
重叠池 (Overlapping Pooling)
Pooling layers in CNNs essentially encapsulate information within a set of pixels or values within a feature map and projects them into a lower sized grid, while reflecting the general information from the original set of pixels.
CNN中的池层实质上将信息封装在要素图中的一组像素或值内,并将它们投影到较小尺寸的网格中,同时反映来自原始像素组的一般信息。
The illustration below provides an example of a pooling, more specifically max pooling. Max pooling is a variant of sub-sampling where the maximum pixel value of pixels that fall within the receptive field of the pooling window.
下图提供了一个池化的示例,更具体地说是最大池化。 最大池化是子采样的一种变体,其中最大像素值落入池化窗口的接收范围内。
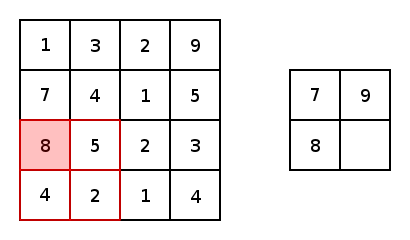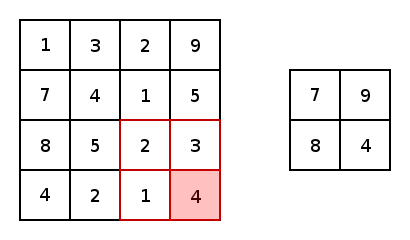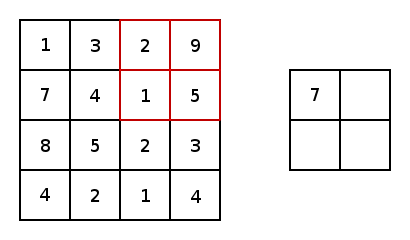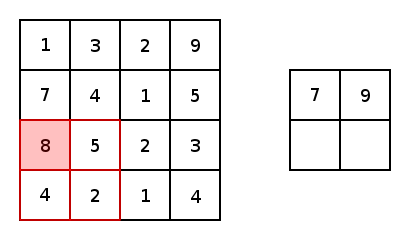
Within the paper that introduces the AlexNet CNN architecture, a different methodology of pooling was introduces and utilizes. Overlapping pooling. In traditional pooling techniques, the stride, from one centre of a pooling window to another is positioned to ensure that values from one pooling window are not within a subsequent pooling window.
在介绍AlexNet CNN架构的论文中,引入并利用了一种不同的合并方法。 重叠池。 在传统的池化技术中,从池化窗口的一个中心到另一中心的跨度被定位为确保来自一个池化窗口的值不在后续池化窗口之内。
In contrast to the traditional methodology of pooling, overlapping pooling utilizes a stride that is less than the dimension of the pooling window. This means that the outputs of subsequent pooling windows encapsulate information from pixels/values that have been pooled more than once. It’s hard to see the benefits of this, but according to the findings of the paper, overlapping pooling reduces the ability for a model to overfit during training.
与传统的池化方法相比,重叠池使用的步幅小于池化窗口的尺寸。 这意味着后续合并窗口的输出封装了已被合并多次的像素/值中的信息。 很难看到它的好处,但是根据本文的发现,重叠池降低了模型在训练期间过拟合的能力。
数据扩充 (Data Augmentation)
Another standard method of reducing the chances of overfitting a network is through data augmentation. By artificially augmenting the dataset, you increase the number of training data, which in turn increases the amount of data the network is exposed to during the training phase.
减少过度适应网络机会的另一种标准方法是通过数据增强。 通过人为地扩充数据集,您可以增加训练数据的数量,从而增加了网络在训练阶段所暴露的数据量。
Augmentation of images usually come in the form of transformation, translation, scaling, cropping, flipping etc.
图像的增强通常以变换,平移,缩放,裁剪,翻转等形式出现。
The images used to train the network in the original AlexNet paper were artificially augmented during the training phase. The augmentation techniques utilized were cropping and alteration of pixel intensities within images.
在训练阶段,人为地放大了AlexNet原始论文中用于训练网络的图像。 所使用的增强技术是裁剪和更改图像中的像素强度。
Images within the training set were randomly cropped from their 256 by 256 dimensions, to obtain a new cropped image of 224 by 224.
将训练集中的图像从其256 x 256尺寸中随机裁剪,以获得224 x 224的新裁剪图像。
Why does augmentation work?
增强为什么起作用?
It turns out that randomly performing augmentation to training set can significantly reduce the potential of a network to overfit during training.
事实证明,随机执行对训练集的扩充可以显着降低训练期间网络过度拟合的可能性。
The augmented images are simply derived from the content of the original training images, so why does augmentation work so well?
增强图像只是从原始训练图像的内容中得出的,那么增强为何如此有效?
Simply kept, data augmentation increases the invariance in your dataset without the need for sourcing new data. The ability for the network to generalize well to unseen dataset also increases.
简单来说,数据扩充可增加数据集中的不变性,而无需采购新数据。 网络能够很好地泛化到看不见的数据集的能力也有所提高。
Let’s take a very literal example; the images in the ‘production’ environment might not be perfect, some might be tilted, blurred or contain only bits of essential features. Therefore, training a network against a dataset that includes a more robust variation of training data will enable the trained network to have more success classifying images in a production environment.
让我们举一个非常真实的例子。 “生产”环境中的图像可能并不完美,某些图像可能会倾斜,模糊或仅包含一些基本特征。 因此,针对包括训练数据的更健壮变化的数据集来训练网络将使训练后的网络在生产环境中能够更成功地对图像进行分类。
退出 (Dropout)
Dropout is a term many deep learning practitioners are familiar with. Dropout is a technique that is utilized to reduce a model’s potential to overfit.
辍学是许多深度学习从业人员熟悉的术语。 Dropout是一种用于减少模型过度拟合的潜力的技术。
Dropout technique works by adding a probability factor to the activation of neurons within the layers of a CNN. This probability factor indicates to the neurons chances of been activated during a current feed-forward step and during involved in the process of backpropagation.
辍学技术是通过向CNN层内的神经元激活添加概率因子来实现的。 该概率因子向神经元指示了在当前前馈步骤期间以及在反向传播过程中被激活的机会。
Dropout is useful as it enables the neurons to reduce dependability on neighbouring neurons; each neuron learns more useful features as a result of this.
辍学是有用的,因为它使神经元能够减少对相邻神经元的依赖。 因此,每个神经元都会学习更多有用的功能。
In the AlexNet architecture, the dropout technique was utilized within the first two fully connected layers.
在AlexNet架构中,前两个完全连接的层使用了dropout技术。
One of the disadvantages of using dropout technique is that it increases the time it takes for a network to converge.
使用丢失技术的缺点之一是,它增加了网络收敛所需的时间。
Although, the advantage of utilizing dropout far beats its disadvantages.
尽管利用辍学的优势远远超过了劣势。
AlexNet架构 (AlexNet Architecture)
In this section, we will get an understanding of the internal composition of the AlexNet network. We will focus on information associated with the layers and breakdown the internal properties of each significant layers.
在本节中,我们将了解AlexNet网络的内部组成。 我们将重点关注与图层相关的信息,并细分每个重要图层的内部属性。
The AlexNet CNN architecture consists of 8 layers, which included 5 conv layers and 3 fully connected layers. Some of the conv layers are a composition of convolution, pooling and normalization layers.
AlexNet CNN体系结构由8层组成,其中包括5个conv层和3个完全连接的层。 卷积层中的一些是卷积层,池化层和规范化层的组合。
AlexNet was the first architecture to adopt an architecture with consecutive convolutional layers (conv layer 3, 4 and 5).
AlexNet是第一个采用具有连续卷积层(转换层3、4和5)的体系结构。
The final fully connected layer in the network contains a softmax activation function that provides a vector that represents a probability distribution over 1000 classes.
网络中的最终完全连接层包含softmax激活函数,该函数提供一个向量,表示1000个类别上的概率分布。
Softmax激活功能 (Softmax activation function)
Softmax activation is utilized to derive the probability distribution of a set of numbers within an input vector. The output of a softmax activation function is a vector in which its set of values represents the probability of an occurrence of a class or event. The values within the vector all add up to 1.
利用Softmax激活来得出输入向量内一组数字的概率分布。 softmax激活函数的输出是一个向量,其中的一组值表示发生类或事件的概率。 向量中的值总计为1。
Apart from the last fully connected layer, the ReLU activation function is applied to the rest of the layers included in the network.
除了最后一个完全连接的层之外,ReLU激活功能还应用于网络中包含的其余层。
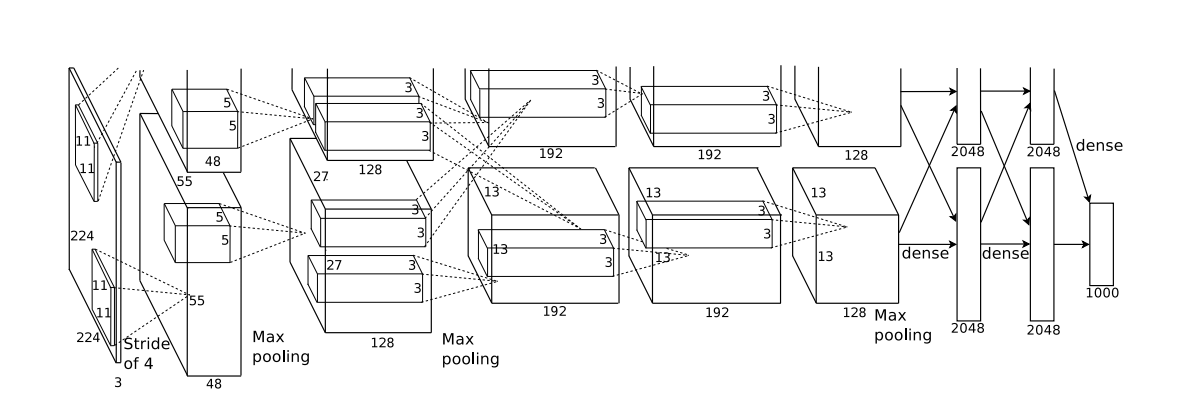
The illustration of the AlexNet network above is split into two partitions since the model was trained across two GTX 580 GPUs. Although the network is partitioned across two GPUs, from the illustration, we can see some cross GPU communication within the conv3, FC6, FC7 and FC8 layers.
由于该模型是在两个GTX 580 GPU上训练的,因此上面的AlexNet网络的图示分为两个分区。 尽管网络跨两个GPU进行了划分,但从图中可以看出,在conv3,FC6,FC7和FC8层中可以看到一些交叉的GPU通信。
The table below is a breakdown of some of the characteristics and properties of the layers in the network.
下表是网络中各层的某些特征和属性的细分。
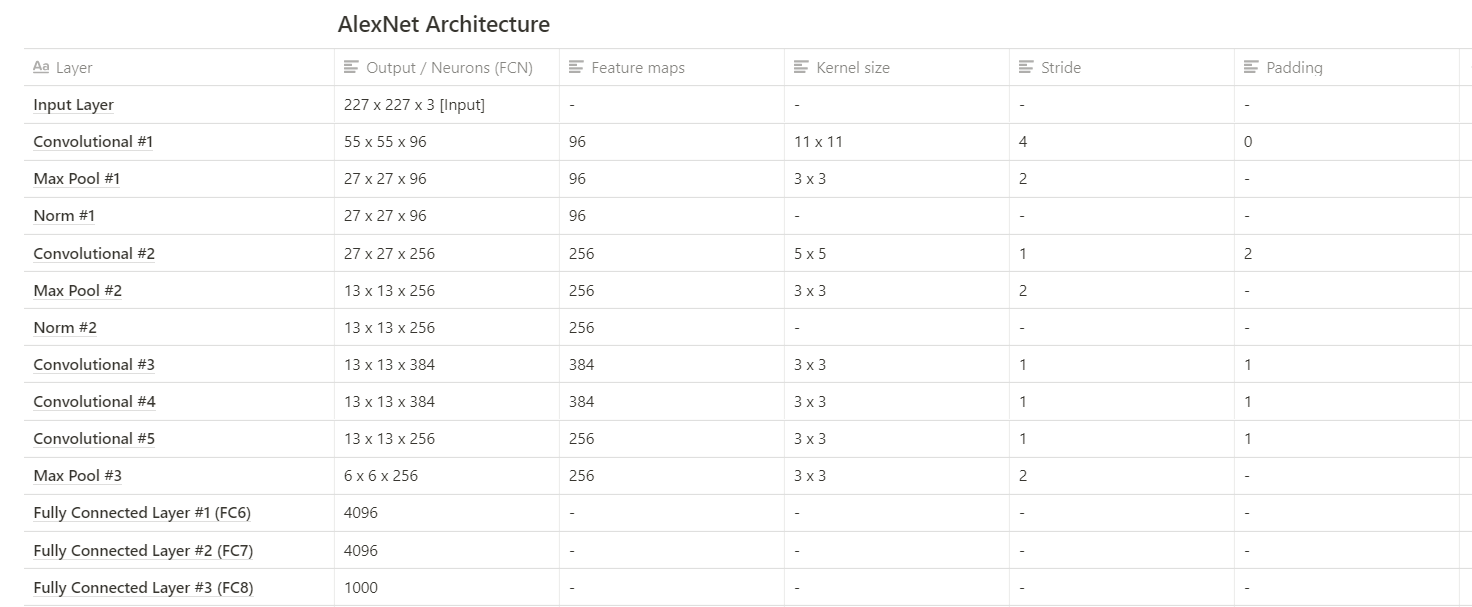
In the original paper, the input layer is said to have the dimensions 224 x 224 x 3, but in the table above the input layer has the input dimensions of 227 x 227 x 3, the discrepancies are due to the fact that there is some unmentioned padding that occurs during the actual training of the network that is not included in the published paper.
在原始纸张中,输入层的尺寸据说为224 x 224 x 3,但是在上方的表格中,输入层的输入尺寸为227 x 227 x 3,差异是由于存在一些在实际的网络训练过程中发生的未提及的填充,未包含在发表的论文中。
结论 (Conclusion)
The introduction and success of AlexNet changed the landscape of deep learning. After its triumphant performance at the ILSVRC’12 contest, the following years winning architectures were all deep convolutional neural networks.
AlexNet的引入和成功改变了深度学习的格局。 在ILSVRC'12大赛中取得了骄人的成绩之后,接下来几年获奖的体系结构都是深度卷积神经网络。
A variant of the AlexNet won the ILSVRC’13 contest with different hyperparameters. The winning architecture in the year 2014, 2015 and 2016 was built with deeper networks and smaller convolutional kernels/filters.
AlexNet的一个变体以不同的超参数赢得了ILSVRC'13竞赛。 2014年,2015年和2016年获奖的体系结构是用更深的网络和更小的卷积内核/过滤器构建的。
Understanding the architecture of AlexNet is easy, and it’s even easier to implement, especially with tools such as PyTorch and TensorFlow that include a module of the architecture within their libraries and frameworks.
了解AlexNet的体系结构很容易,并且甚至更容易实现,尤其是使用PyTorch和TensorFlow之类的工具,这些工具在其库和框架中都包含该体系结构的模块。
In a future article, I’ll be showing how the AlexNet architecture presented in this paper can be implemented and utilized with TensorFlow.
在以后的文章中,我将展示如何使用TensorFlow来实现和利用本文介绍的AlexNet架构。
希望您觉得这篇文章有用。 (I hope you found the article useful.)
To connect with me or find more content similar to this article, do the following:
要与我联系或查找更多类似于本文的内容,请执行以下操作:
翻译自: https://towardsdatascience.com/what-alexnet-brought-to-the-world-of-deep-learning-46c7974b46fc
深度之眼 alexnet














 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









