





 本文探讨了如何使用C#进行跨平台的移动和Web应用程序开发,介绍了一个从Java、Web、Python到C#迁移的视角,并提到了C#在Linux等多平台上的应用。
本文探讨了如何使用C#进行跨平台的移动和Web应用程序开发,介绍了一个从Java、Web、Python到C#迁移的视角,并提到了C#在Linux等多平台上的应用。
c#跨平台移动开发
There is a good chance that if you are going to write complex software, you will need data storage and manipulation. We are lucky SQLite is there for us, with a small binary footprint, portable, and fully fledged. Let me show you how you can use it from your C++ code with just a bit of setup. And even better: without writing any SQL.
如果您要编写复杂的软件,则很有可能需要数据存储和处理。 我们很幸运SQLite在那里,为我们提供的二进制文件占用空间小,可移植且功能齐全。 让我告诉您如何通过一些设置就可以从C ++代码中使用它。 甚至更好:无需编写任何SQL。
The code for this tutorial is available at https://github.com/skonstant/xptuto/tree/part6_sqlite
该教程的代码可在https://github.com/skonstant/xptuto/tree/part6_sqlite获得
SQLite:完全加载但很小 (SQLite: Fully Loaded yet tiny)
SQLite is a Relational Database Management System that supports SQL-92 with plenty of cool things: full-text search, JSON, hierarchical, recursive queries, and more.
SQLite是一个关系数据库管理系统 ,它支持SQL-92,其中包含许多很酷的功能:全文搜索,JSON,分层,递归查询等。
It is an embeddable database, not a server system, perfect for what we need, and we will include it in our builds. Lots of major players use it in their own packages too.
它是一个可嵌入的数据库,而不是服务器系统,非常适合我们需要的内容,我们会将其包含在我们的构建中。 许多主要参与者也使用它们自己的软件包。
Other systems will use what they call the amalgamation. All the code of SQLite in one single .c file, albeit a large one but with our ccache setup compilation time is not a problem.
其他系统将使用它们所谓的合并 。 所有SQLite的代码都放在一个.c文件中,尽管很大,但是对于我们的ccache设置,编译时间不是问题。
XCode has SQLite as part of its iOS libraries, Mac OS too (working with CMake), Android NDK does not — surprisingly since it is the backbone of the SQL storage on Android since the beginning, it is not exposed in the NDK. Web/Emscripten does not have it of course.
XCode将SQLite作为其iOS库的一部分,也将MacOS(与CMake一起使用)作为Mac OS的一部分,而Android NDK则没有。令人惊讶的是,由于自从一开始它就成为Android上SQL存储的中坚力量,因此它在NDK中并未公开。 Web / Emscripten当然没有。
For our iOS project, let’s just add it in Build Phases 🡲 Link Binary with Libraries and add libsqlite3.tbd. Done, headers are visible and linking works.
对于我们的iOS项目,我们只需将其添加到Build Phases🡲Link Binary with Libraries并添加libsqlite3.tbd。 完成后,标题可见并且链接正常。
For our CMake projects (Android, local computer and Emscripten), we use the CMake find_package() command.
对于我们的CMake项目(Android,本地计算机和Emscripten),我们使用CMake find_package()命令。
find_package (SQLite3)if (SQLITE3_FOUND)
include_directories(${SQLITE3_INCLUDE_DIRS})else (SQLITE3_FOUND)
# add amalgamation code and include
set(SRC ${SRC} sqlite-amalgamation-3310100/sqlite3.c)
include_directories(sqlite-amalgamation-3310100)endif (SQLITE3_FOUND)This is all there is to it, now we have it in our build and can start playing around with data and SQL in-memory, only so far because we need to sort out the file storage problem.
这就是它的全部内容,现在我们可以在其内部构建它,并且可以开始处理数据和SQL内存,仅到目前为止,因为我们需要解决文件存储问题。
储存问题 (The Storage Problem)
We need to be able to write to a file in order to save our data. On Android and iOS we have access to the folders that only our app can use, we will choose the cache folders on both since this is just for caching. Beware that data in the application’s cache folders can disappear at any time. If you need something more reliable, use the file directories. Either way, these are private to your apps and require no special permission.
我们需要能够写入文件以保存数据。 在Android和iOS上,我们可以访问只有我们的应用程序可以使用的文件夹,我们将在这两个文件夹中选择缓存文件夹,因为这仅用于缓存。 请注意,应用程序的缓存文件夹中的数据可能随时消失。 如果您需要更可靠的东西,请使用文件目录。 无论哪种方式,这些都是您的应用专用的,不需要任何特殊许可。
Note that the files folders are backed up to the Google or Apple cloud by default, you can opt-out in configuration.
请注意,默认情况下,文件文件夹已备份到Google或Apple云,您可以选择退出配置。
We have added a file path parameter to our Xptuto make_instance() factory method. For Android we do:
我们已经在Xptuto make_instance()工厂方法中添加了文件路径参数。 对于Android,我们这样做:
Xptuto.makeInstance(
new JavaHttpClient(getApplicationContext()),
new AndroidThreads(),
getCacheDir().getAbsolutePath()); // or getFilesDir() For iOS, we do:
对于iOS,我们执行以下操作:
auto cacheDirectory = [NSSearchPathForDirectoriesInDomains(
NSCachesDirectory, NSUserDomainMask, true) lastObject];
// or NSApplicationSupportDirectory x = Xptuto::make_instance(
std::make_shared<AppleHttpClient>(),
std::make_shared<AppleThreads>(),
djinni::String::toCpp(cacheDirectory));For web, it is more difficult. The browser has no filesystem for us, emscript has the Filesystem API which is a bit incoherent. You need to do things in the Javascript layer in order to create the filesystem you need.
对于网络而言,这更加困难。 浏览器没有适合我们的文件系统 ,emscript具有Filesystem API ,这有点不连贯。 您需要在Javascript层中执行操作才能创建所需的文件系统。
In our initialization code we do:
在初始化代码中,我们执行以下操作:
var Module = {
onRuntimeInitialized: function() {
FS.mkdir('/cache');
FS.mount(IDBFS, {}, '/cache');
FS.syncfs(true, function (err) {
window.xptuto = Module.createInstance();
});
}
};// then in C++
xptuto::Xptuto::make_instance(
std::make_shared<WebHttpClient>(),
std::make_shared<WebThreads>(), "/cache");This looks simple enough. The problem is further down the line: we need to synchronize manually if we do writes to our files. In our case, when we write to our database. We can sync any time, the app works even without it, the changes will just be lost if we leave the web page without synchronising, bear this in mind. And we cannot synchronize in onbeforeunload because FS.syncfs() is asynchronous. Various strategies can be used to overcome this problem. In my example, I sync in the callback.
这看起来很简单。 问题很严重:如果确实要写入文件,则需要手动进行同步。 就我们而言,当我们写入数据库时。 我们可以随时同步,即使没有它,该应用程序也可以运行,如果我们不同步就离开网页,更改将丢失,请记住这一点。 而且我们无法在onbeforeunload中进行同步,因为FS.syncfs()是异步的。 可以使用各种策略来克服此问题。 在我的示例中,我同步了回调。
callback = new Module.JSGetReposCb({
on_error: (error) => console.error(error),
on_success: (repos, user) => {
...
FS.syncfs(function (err) {});This is not great but it is a small price to pay, I feel.
我觉得这不是很好,但是付出的代价很小。
保持面向对象:使用ORM (Stay Object Oriented: use the ORM)
As much as I like SQL, I dislike using strings in my code. I find Object Relational Mappers very useful: we stay in C++, so we can take advantage of our tools to check our code before deploying, and we are sure the generated SQL is always valid.
尽管我喜欢SQL,但我不喜欢在代码中使用字符串。 我发现对象关系映射器非常有用:我们仍然使用C ++,因此我们可以在部署之前利用我们的工具来检查我们的代码,并且可以确保生成SQL始终有效。
We will use SQLite ORM a header-only C++17 library, very easy to integrate and to use. Here is our definition of our Users table:
我们将使用SQLite ORM一个仅标头的C ++ 17库,它非常易于集成和使用。 这是我们对Users表的定义:
make_storage(dbFile,
make_table("users",
make_column("id", &User::id, primary_key()),
make_column("login", &User::login, unique()),
make_column("avatar_url", &User::avatar_url),
make_column("created_at", &User::created_at))It deduces the SQLite types from our field types, I have added support for std::chrono::time_point myself (I pass them as milliseconds since epoch). Like our JSON library, it provides template methods that we just specialise for our custom types.
它从我们的字段类型中推断出SQLite类型,我自己添加了对std :: chrono :: time_point的支持(自纪元以来,它们以毫秒为单位传递)。 像我们的JSON库一样,它提供了我们专门针对自定义类型的模板方法。
Now we have users in a table, let’s write a little test:
现在我们在一个表中有用户,让我们编写一些测试:
TEST_F(Xptuto, OrmTest) {
auto instance = std::make_shared<XptutoImpl>(
stubHttp,stubThreads, std::nullopt);
stubHttp->path = "/responses/users_aosp.json";
auto user = instance->get_user_sync("aosp");
auto storage = SQLStorage(":memory:");
storage.store_user(user.value());
auto u = storage.get_user("aosp");
EXPECT_EQ(u.created_at, user->created_at);
EXPECT_EQ(u.login, "aosp");
}// get_user():
User SQLStorage::get_user(const std::string &login) {
auto allUsersList =
storage.get_all<User, std::vector<User>>(
where(c(&User::login) == login));
return allUsersList.at(0);
}Simple as that, no SQL strings. SQLite Orm can do much more complex queries of course, and in last resort, it lets you write raw SQL. Note that for the test, we use “:memory:” as the database file, this tells SQLite to use an in-memory database.
如此简单,没有SQL字符串。 SQLite Orm当然可以执行更复杂的查询,并且在最后一招中,它允许您编写原始SQL。 请注意,在测试中,我们使用“:memory:”作为数据库文件,这告诉SQLite使用内存数据库。
I chose in this method to return the found user or throw, hence the use of std::vector:::at(). I find exceptions meaningful, sometimes more than returning nulls (std::nullopt better).
我在此方法中选择返回找到的用户或引发,因此使用了std :: vector ::: at() 。 我发现异常有意义,有时比返回null更好( std :: nullopt更好)。
Q-s DISABLE_EXCEPTION_CATCHING=0 to all your compile and link flags. On other platforms, exceptions are enabled by default.
Q -s DISABLE_EXCEPTION_CATCHING = 0表示所有编译和链接标志。 在其他平台上,默认情况下会启用例外。
I also defined my Repo object in a table, with a foreign key to the user.
我还在表中定义了Repo对象,并为用户提供了外键。
make_table("repos",
make_column("id", &Repo::id, primary_key()),
make_column("name", &Repo::name),
make_column("full_name", &Repo::full_name),
make_column("owner", &Repo::owner),
make_column("priv", &Repo::priv),
make_column("descr", &Repo::descr),
make_column("created_at", &Repo::created_at),
foreign_key(&Repo::owner).references(&User::id)));
// get repos for a user:
storage.get_all<Repo, std::vector<Repo>>(
where(c(&Repo::owner) == user.id));Now we can vastly improve our get_user() method (and all the other get… methods.
现在,我们可以极大地改进我们的get_user()方法(以及所有其他get ...方法)。
void XptutoImpl::get_user(const std::string &login,
const std::shared_ptr<GetUserCb> &cb) {
auto me = shared_from_this();
threads->create_thread("get_user",
std::make_shared<ThreadFuncImpl>([me, cb, login]() {
try {
try {
auto user = me->storage.get_user(login);
me->threads->run_on_main_thread(
std::make_shared<ThreadFuncImpl>([cb, user]() {
cb->on_success(user);
}));
} catch (...) {
auto user = me->get_user_sync(login);
if (!user) {
me->threads->run_on_main_thread(
std::make_shared<ThreadFuncImpl>([cb]() {
cb->on_error("could not load user");
}));
} else {
me->storage.store_user(user.value());
me->threads->run_on_main_thread(
std::make_shared<ThreadFuncImpl>([cb, user]() {
cb->on_success(user.value());
}));
}
}
} catch (...) {
me->threads->run_on_main_thread(
std::make_shared<ThreadFuncImpl>([cb]() {
cb->on_error("could not load user");
}));
}
}));
}- try and get the user from the local DB 🡲success callback 尝试从本地数据库callback成功回调中获取用户
- try from network and store to DB 🡲 success callback 尝试从网络存储到DB🡲成功回调
- error callback. 错误回调。
All callbacks are called on the main thread.
所有回调均在主线程上调用。
示例应用 (Example apps)
React (React)
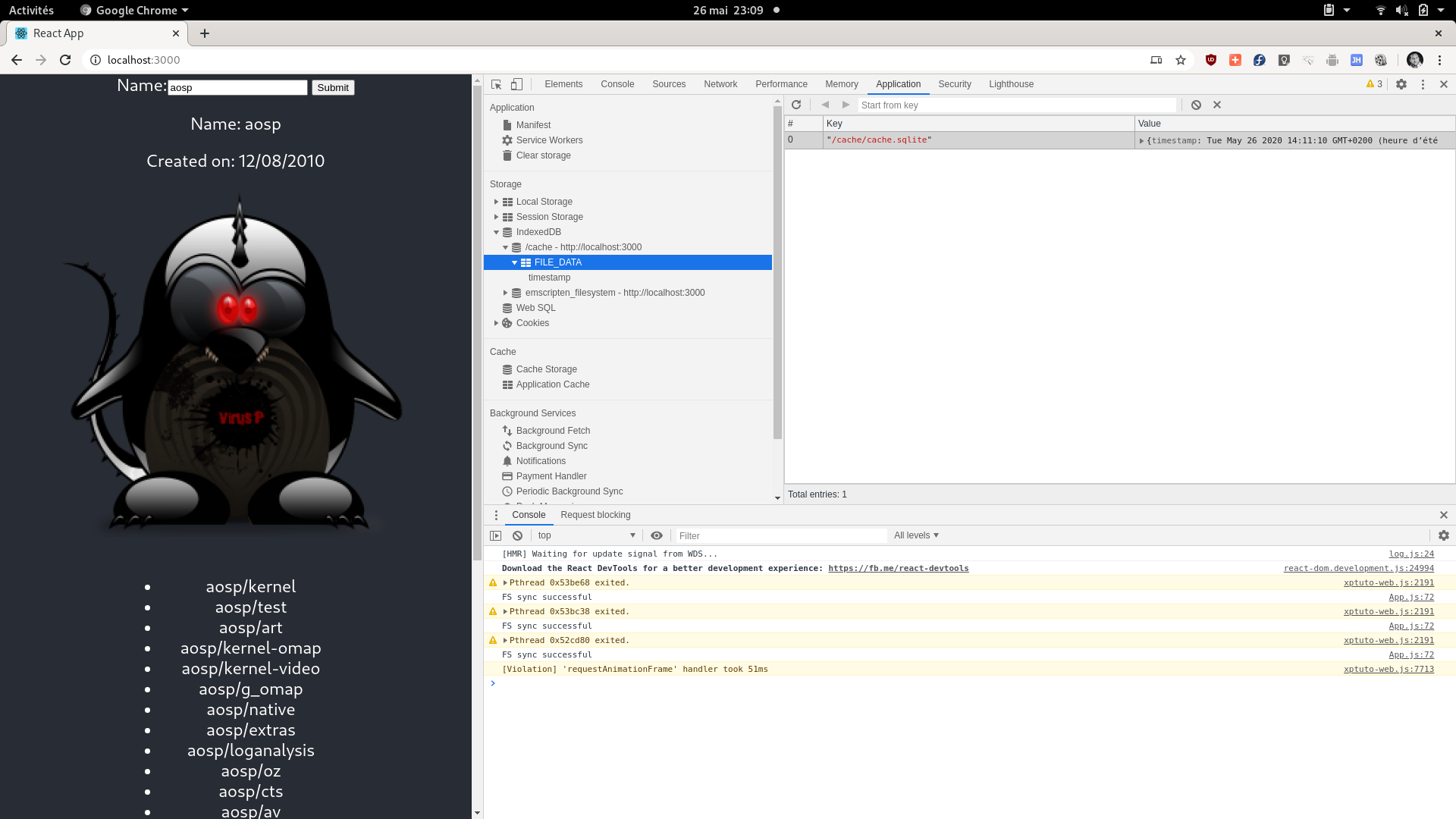
This time we created little example apps, so you can test this out. For web, I created a tiny React App, here is the User view:
这次我们创建了一些示例应用程序,因此您可以进行测试。 对于网络,我创建了一个小型的React App,这是User视图:
class UserView extends React.Component {
render() {
const user = this.props.user;
if (user) {
return (
<div className="userDetails">
<p>Name: {user.login}</p>
<p>Created on: {new Date(user.created_at.millis()).toLocaleDateString()}</p>
<p><img className="avatar" alt="avatar" src={user.avatar_url}/></p>
</div>
);
} else {
return null;
}
}
}The only thing worth noting is that we create a date from milliseconds.
唯一值得注意的是,我们以毫秒为单位创建日期。
The user is loaded from a form:
从表单加载用户:
if (!this.callback) {
// eslint-disable-next-line no-undef
this.callback = new Module.JSGetReposCb({
on_error: (error) => console.error(error),
on_success: (repos, user) => {
this.props.onUserChange(user);
this.props.onReposChange(repos);
// eslint-disable-next-line no-undef
FS.syncfs(function (err) {
...
});
}
});
}window.xptuto.get_repos_for_user_name(
this.state.value,this.callback);Nothing special here either, the work is done in the C++ layer, the view layer knows nothing about what is happening in the background. The only thing to remember is to sync the pseudo filesystem. Note the avatar is loaded automatically by setting the src attribute of the image.
这里也没有什么特别的,工作是在C ++层完成的,视图层对后台发生的事情一无所知。 唯一要记住的是同步伪文件系统。 请注意,通过设置图片的src属性来自动加载头像。
Also, the classes and functions available in the WebAssembly module are not visible to the Javascript tool (eslint and Babel here), so we need to disable checking when using them, maybe at some point the tools will be able to find what is exposed by embind, who knows.
另外,WebAssembly模块中可用的类和函数对Javascript工具(此处为eslint和Babel)不可见,因此我们需要在使用它们时禁用检查,也许在某些时候该工具将能够找到被暴露的内容。 embind,谁知道。
安卓 (Android)
For Android, I made two activities, one for the user search and details and one to list the repositories.
对于Android,我进行了两项活动,一项活动用于用户搜索和详细信息,另一项列出存储库。
x.getUser(v.getText().toString(), new GetUserCb() {
@Override
public void onSuccess(User user) {
if(!isFinishing() && !isDestroyed()){
progressBar.hide();
details.setVisibility(View.VISIBLE);
userName.setText(user.login);
creationDate.setText(DateFormat.getDateInstance(
DateFormat.MEDIUM,
Locale.getDefault()).format(user.createdAt));
avatar.setImageDrawable(null);
Glide.with(MainActivity.this)
.load(user.avatarUrl).into(avatar);
}
}
@Override
public void onError(String error) {
if(!isFinishing() && !isDestroyed()){
progressBar.hide();
notFound.setVisibility(View.VISIBLE);
}
}
});Easy again. We use Java’s Dateformat to format the date in a localised way. Glide is used to load the avatar image, that’s the best breed image loading library for Android.
再简单一点。 我们使用Java的Dateformat以本地化的方式格式化日期。 Glide用于加载头像图像,这是适用于Android的最佳品种图像加载库。
When opening the list activity, we just pass the user name in the intent, as we have the user in storage, we can retrieve it from there. I have been caught a few times passing too much data in an Intent or a Bundle, better pass an identifier.
打开列表活动时,我们只是在意图中传递用户名,因为我们将用户存储在存储区中,因此可以从那里检索它。 我曾几次被发现在Intent或Bundle中传递太多数据,最好传递一个标识符。
的iOS (iOS)
Similar to Android, two ViewControllers this time, one with the search form and the details and one with the repositories list, here is how we get the user:
与Android类似,这次有两个ViewController,一个带有搜索表单和详细信息,一个带有存储库列表,这是我们如何获取用户的方法:
__weak auto welf = self;auto x = Xptuto::get_instance();
x->get_user(djinni::String::toCpp(_userInput.text), std::make_shared<GetUserCbImpl>(
[welf](const User &user) {
[welf.progress stopAnimating];
[welf showDetails:user];
}, [welf](const std::string &error) {
[welf.progress stopAnimating];
welf.notFoundLabel.hidden = false;
}));Simple and easy. we use a weak pointer to the viewcontroller so our callback does not hold on to it.
简单容易。 我们使用了指向ViewController的弱指针,因此我们的回调不会继续保持下去。
结论 (Conclusion)
I have showed you offline and complex data manipulation is just one compilation away, you can dust your database modelling book and go implement your on portable device data cache now, no excuse.
我已经向您展示了离线状态,而复杂的数据操作仅需一本汇编,您可以对数据库建模书进行整理,现在就可以在便携式设备数据缓存中实现您的操作,没有任何借口。
And no need for funny stuff like trying to pull the SQLite databaste file out of the phone or the simulator, you can exercise your code on the computer, in memory or to a file, load it in the SQLite Browser GUI and it will behave exactly the same way on Web, iOS and Android.
无需尝试将SQLite databaste文件从电话或模拟器中拉出之类的有趣东西,您就可以在计算机上,在内存中或文件中执行代码,然后将其加载到SQLite Browser GUI中,它的行为将完全相同在Web,iOS和Android上使用相同的方法。
c#跨平台移动开发















 2370
2370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









