





数据分析师sql
Analytical functions are one of the most popular tools among BI/Data analysts for performing complex data analysis. These functions perform computations over multiple rows and return the multiple rows as well. Today we’ll cover 5 functions I find most useful, with a lot of practical examples.
分析功能是BI / Data分析师中用于执行复杂数据分析的最受欢迎的工具之一。 这些函数对多行执行计算,并返回多行。 今天,我们将介绍许多我认为最有用的5个函数,并提供许多实际示例。
For the uninitiated, the relative size of a query with an analytical function might seem a bit intimidating. Don’t worry, we have you covered. Most of these functions follow a basic syntax:
对于没有经验的人,具有分析功能的查询的相对大小似乎有点令人生畏。 不用担心,我们已经覆盖了您。 这些功能大多数遵循基本语法:
analytic_function_name([argument_list])
OVER (
[PARTITION BY partition_expression,…]
[ORDER BY sort_expression, … [ASC|DESC]])There are three parts to this syntax, namely function, partition by and order by. Let’s briefly cover what each one does:
该语法分为三部分,即function , by分区和by by 顺序 。 让我们简单介绍一下每个人的工作:
analytic_function_name: name of the function — likeRANK(),SUM(),FIRST(), etcanalytic_function_name:函数的名称,例如RANK(),SUM(),FIRST()等partition_expression: column/expression on the basis of which the partition or window frames have to be createdpartition_expression:必须根据其创建分区或窗口框架的列/表达式sort_expression: column/expression on the basis of which the rows in the partition will be sortedsort_expression:列/表达式,分区中的行将基于该列/表达式进行排序
Okay, we’ve covered the basics thus far. For the practical part we’re gonna use the Orders table stored inside the PostgreSQL database:
好的,到目前为止,我们已经介绍了基础知识。 在实际操作中,我们将使用存储在PostgreSQL数据库中的Orders表 :

Let’s begin with the practical part now, shall we?
现在让我们从实践部分开始吧?
AVG()和SUM() (AVG() and SUM())
We’ve all been using aggregate functions such as SUM, AVG, MIN, MAX, and COUNT in our GROUP BY clauses. But when these functions are used over an ORDER BY clause they can give us running sum, mean, total, etc.
我们都在GROUP BY子句中使用了聚合函数,例如SUM , AVG , MIN , MAX和COUNT 。 但是,当在ORDER BY子句上使用这些函数时,它们可以为我们提供运行总和,均值,总计等。
The following example will make it a lot more clear — we want to calculate the running average revenue and total revenue for each agent in the third quarter:
下面的示例将使它更加清楚- 我们要计算第三季度每个代理商的移动平均收入和总收入:
SELECT ord_date, agent_code, AVG(ord_amount) OVER (
PARTITION BY agent_code
ORDER BY ord_date
) running_agent_avg_revenue,
SUM (ord_amount) OVER (
PARTITION BY agent_code
ORDER BY ord_date
) running_agent_total_revenue
FROM orders
WHERE ord_date BETWEEN ‘2008–07–01’ AND ‘2008–09–30’;And here are the results:
结果如下:
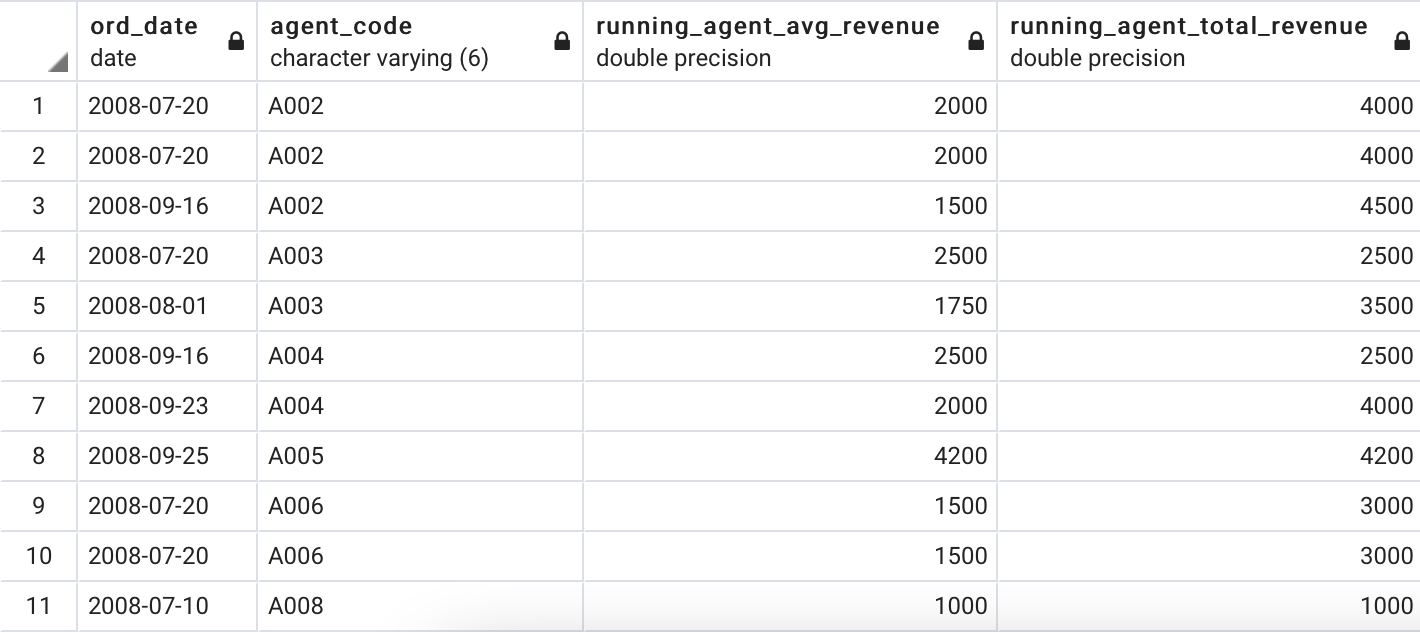
Awesome! These functions are simple and require no additional explanations. Let’s proceed.
太棒了! 这些功能很简单,不需要其他说明。 让我们继续。
FIRST_VALUE(),LAST_VALUE()和NTH_VALUE() (FIRST_VALUE(), LAST_VALUE(), and NTH_VALUE())
FIRST_VALUE() is an analytical function that returns the value of the specified column from the first row of the window frame. If you‘ve understood the previous sentence, LAST_VALUE() is self-explanatory. It fetches the value from the last row.
FIRST_VALUE()是一个分析函数,它从窗口框架的第一行返回指定列的值。 如果您已理解上一句话,则LAST_VALUE()是不言自明的。 它从最后一行获取值。
PostgreSQL provides us with one more additional function called NTH_VALUE(column_name, n) that fetches the value from the n-th row. Isn’t it great? No more complex self joins.
PostgreSQL为我们提供了另一个称为NTH_VALUE(column_name, n)附加函数NTH_VALUE(column_name, n)该函数从第n行获取值。 很好吗? 不再需要复杂的自我联接。
Let’s answer the following question — How many days after the first purchase of a customer was the next purchase made?
让我们回答以下问题- 第一次购买客户后有几天?
SELECT cust_code, ord_date, ord_date — FIRST_VALUE(ord_date) OVER (
PARTITION BY cust_code
ORDER BY ord_date) next_order_gap
FROM orders
ORDER BY cust_code, next_order_gap;And here are the results:
结果如下:
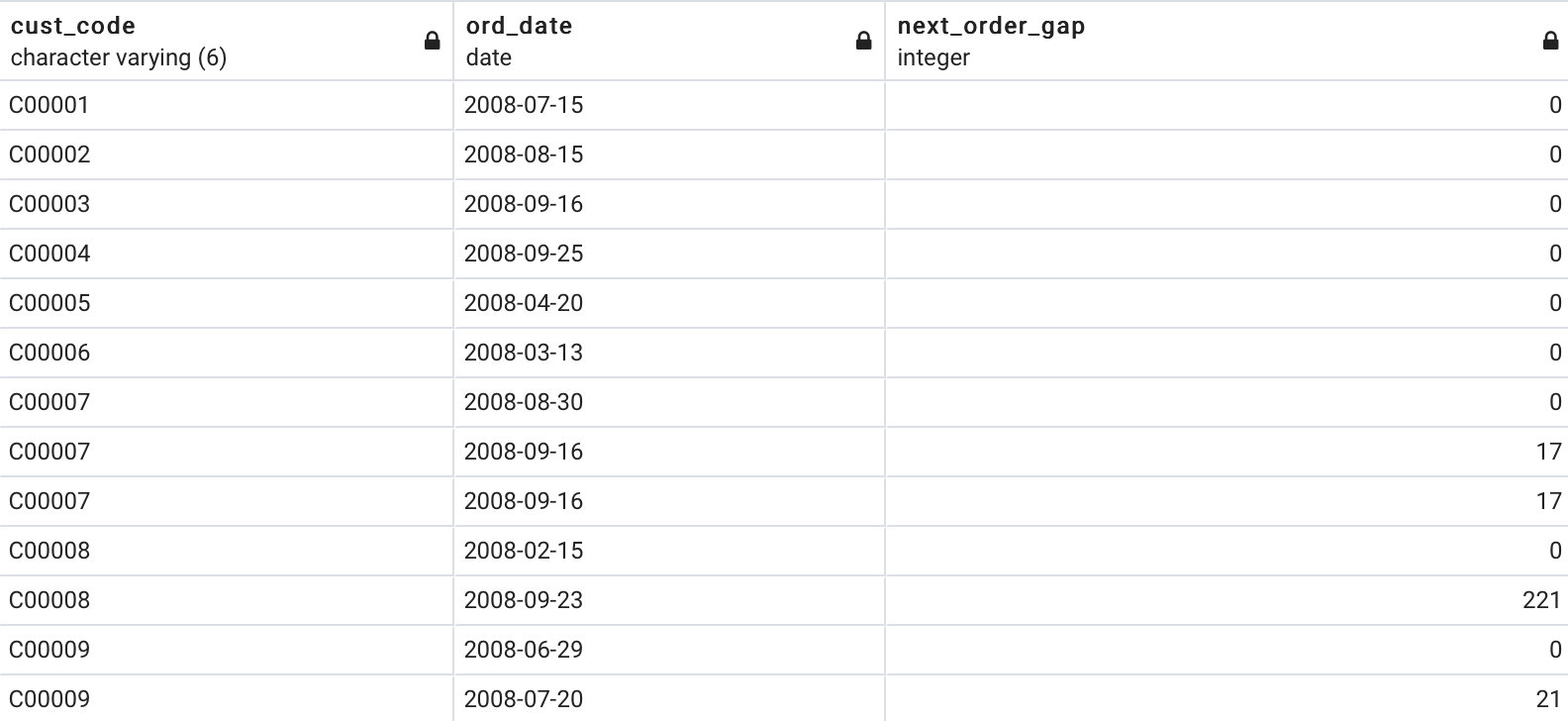
There are just so many occasions where this function might be useful. Also, it’s nice to know the results can be obtained from the database directly, so we don’t have to do this calculation manually with Python/R.
在很多情况下,此功能可能有用。 另外,很高兴知道可以直接从数据库获得结果,因此我们不必使用Python / R手动进行此计算。
Let’s proceed with the next one.
让我们继续下一个。
LEAD()和LAG() (LEAD() and LAG())
LEAD() function, as the name suggests, fetches the value of a specific column from the next row and returns the fetched value in the current row. In PostgreSQL, LEAD() takes two arguments:
顾名思义, LEAD()函数从下一行获取特定列的值,并在当前行中返回获取的值。 在PostgreSQL中 , LEAD()有两个参数:
column_namefrom which the next value has to be fetched必须从中获取下一个值的
column_nameindexof the next row relative to the current row.下一行相对于当前行的
index。
LAG() is just the opposite of. It fetches values from the previous rows.
LAG()与之相反。 它从前几行中获取值。
Let’s answer the following question to make this concept a bit more clear — what is the last highest amount for which an order was sold by an agent?
让我们回答以下问题,以使这个概念更加清楚- 代理商销售订单的最后最高金额是多少?
SELECT agent_code, ord_amount, LAG(ord_amount, 1) OVER (
PARTITION BY agent_code
ORDER BY ord_amount DESC
) last_highest_amount
FROM orders
ORDER BY agent_code, ord_amount DESC;And here are the results:
结果如下:
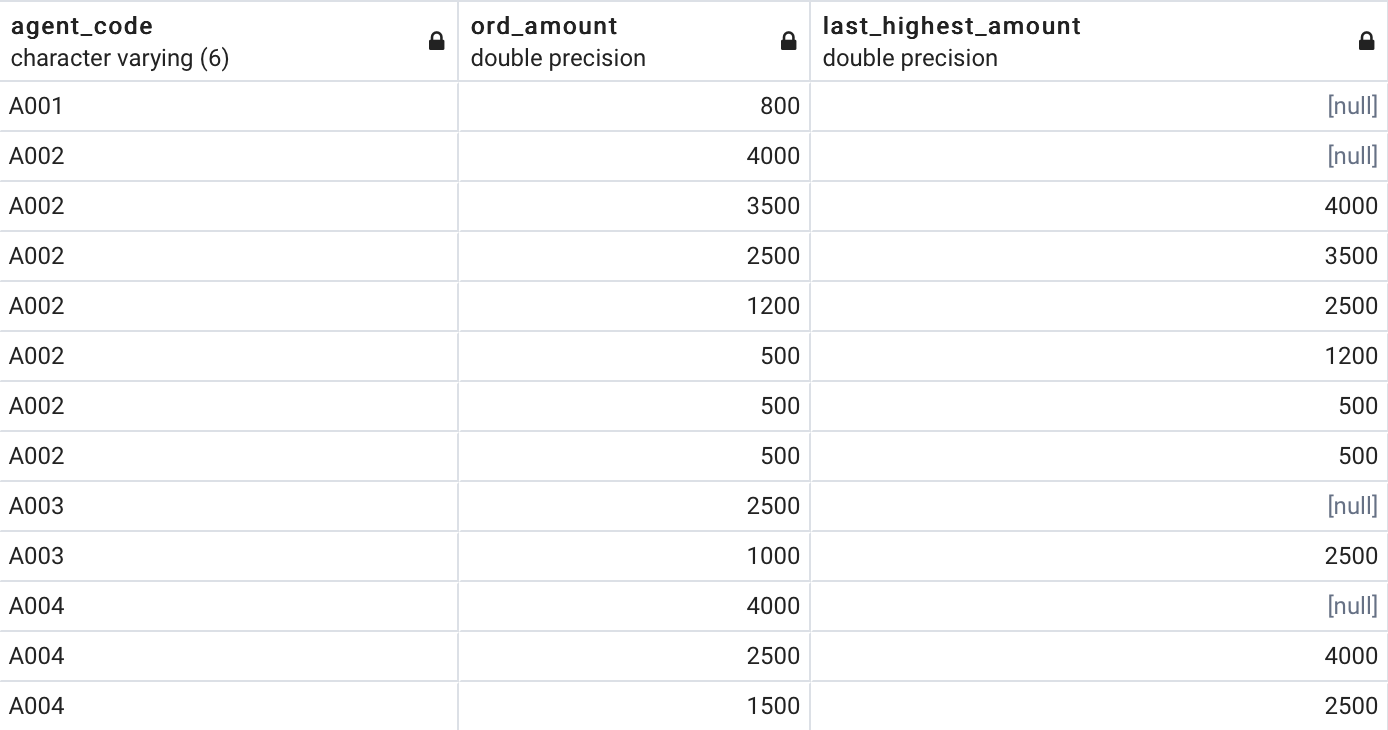
Above you can see how last_highest_amount clearly shows data per agent — that’s why there’s no result for agent A001, and first values for other agents are NULL.
在上方,您可以看到last_highest_amount如何清楚地显示每个座席的数据-这就是为什么座席A001没有结果,而其他座席的第一个值为NULL的原因。
RANK()和DENSE_RANK() (RANK() and DENSE_RANK())
RANK() and DENSE_RANK() are numbering functions. They assign an integer value to a row depending upon the partition and the ordering. I cannot stress enough on the importance of these functions when it comes to finding the nth highest/lowest record from the table.
RANK()和DENSE_RANK()是编号函数。 它们根据分区和顺序为行分配一个整数值。 当从表中查找第n个最高/最低记录时,我对这些功能的重要性没有足够的强调。
DENSE_RANK() and RANK() differ on the point that in the former we get consecutive ranks while in the later the rank after a tie is skipped. For example, ranking using DENSE_RANK() would be something like (1,2,2,3) whereas ranking using RANK() would be (1,2,2,4). Hope you get the difference.
DENSE_RANK()和RANK()区别在于,前者获得连续排名,而后者则跳过并列。 例如,使用DENSE_RANK()进行排名将类似于(1,2,2,3),而使用RANK()进行排名将为(1,2,2,4)。 希望你能有所作为。
Anyhow, let’s answer the following question with the help of these functions — what are the second highest order values for each month?
无论如何,让我们借助这些功能来回答以下问题- 每个月的第二大订单值是多少?
SELECT * FROM (
SELECT ord_num, ord_date, ord_amount, DENSE_RANK() OVER(
PARTITION BY DATE_PART(‘month’, ord_date)
ORDER BY ord_amount DESC) order_rank
FROM orders
) t
WHERE order_rank = 2
ORDER BY ord_date;And here are the results:
结果如下:

Cool! Let’s proceed with the next one.
凉! 让我们继续下一个。
CUME_DIST() (CUME_DIST())
CUME_DIST() function is used to calculate the cumulative distribution of values within a given partition. It computes the fraction of rows in the partition that is less than or equal to the current row. It’s very helpful when we have to fetch only the top n% of the results.
CUME_DIST()函数用于计算给定分区内值的累积分布。 它计算分区中小于或等于当前行的行的分数。 当我们只需要获取结果的前n%时,这将非常有帮助。
Let’s use it to calculate the revenue percentile for each order in August and September:
让我们用它来计算8月和9月每个订单的收入百分比 :
SELECT DATE_PART(‘Month’,ord_date), agent_code, ord_amount, CUME_DIST() OVER(
PARTITION BY DATE_PART(‘Month’,ord_date)
ORDER BY ord_amount
)
FROM orders
WHERE ord_date BETWEEN ‘2008–08–01’ AND ‘2008–09–30’;And here are the results:
结果如下:

It’s not the function I use on a daily basis, but it’s nice to know it exists.
这不是我每天使用的功能,但是很高兴知道它的存在。
你走之前 (Before you go)
And there you have it — 5 most common analytical functions I use when performing analysis in the database. It’s not as common for me as doing analysis with Python and Pandas, but I still find this useful from time to time — especially for analysts limited only to SQL.
在那里,您便拥有了我在数据库中执行分析时使用的5个最常用的分析功能。 对于我来说,这不像使用Python和Pandas进行分析那样普遍,但是我仍然不时发现这一点有用-特别是对于仅限于SQL的分析师。
I hope this 5 will suit you well, and feel free to research and study more on your own. Thanks for reading.
我希望这5个适合您,并随时可以自己进行更多的研究和学习。 谢谢阅读。
数据分析师sql















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









