





机器学习 贝叶斯方法
There has always been a debate between Bayesian and frequentist statistical inference. Frequentists dominated statistical practice during the 20th century. Many common machine learning algorithms like linear regression and logistic regression use frequentist methods to perform statistical inference. While Bayesians dominated statistical practice before the 20th century, in recent years many algorithms in the Bayesian schools like Expectation-Maximization, Bayesian Neural Networks and Markov Chain Monte Carlo have gained popularity in machine learning.
贝叶斯和常态统计推断之间一直存在争论。 在20世纪,常客主导了统计实践。 许多常见的机器学习算法(例如线性回归和逻辑回归)都使用常客性方法来执行统计推断。 尽管贝叶斯技术在20世纪之前主导了统计实践,但近年来,贝叶斯学派中的许多算法,例如期望最大化,贝叶斯神经网络和马尔可夫链蒙特卡洛算法,都在机器学习中广受欢迎。
In this article, we will talk about their differences and connections in the context of machine learning. We will also use two algorithms for illustration: linear regression and Bayesian linear regression.
在本文中,我们将讨论它们在机器学习中的区别和联系。 我们还将使用两种算法进行说明: 线性回归和贝叶斯线性回归。
假设条件 (Assumptions)
For simplicity, we will use θ to denote the model parameter(s) throughout this article.
为简单起见,在本文中,我们将使用θ表示模型参数。
Frequentist methods assume the observed data is sampled from some distribution. We call this data distribution the likelihood: P(Data|θ), where θ is treated as is constant and the goal is to find the θ that would maximize the likelihood. For example, in logistic regression the data is assumed to be sampled from Bernoulli distribution, and in linear regression the data is assumed to be sample from Gaussian distribution.
常用方法假定观察到的数据是从某种分布中采样的。 我们称此数据分布为似然性:P(Data |θ),其中θ被视为常数,目标是找到将似然性最大化的θ。 例如,在逻辑回归中,假定数据是从伯努利分布中抽样的,在线性回归中,数据是从高斯分布中抽样的。
Bayesian methods assume the probabilities for both data and hypotheses(parameters specifying the distribution of the data). In Bayesians, θ is a variable, and the assumptions include a prior distribution of the hypotheses P(θ), and a likelihood of data P(Data|θ). The main critique of Bayesian inference is the subjectivity of the prior as different priors may arrive at different posteriors and conclusions.
贝叶斯方法假设数据和假设(指定数据分布的参数)的概率。 在贝叶斯算法中,θ是变量,假设包括假设P(θ)的先验分布和数据P(Data |θ)的似然性。 贝叶斯推理的主要批评是先验的主观性,因为不同的先验可能得出不同的后验和结论。
参数学习 (Parameter Learning)
Frequentists use maximum likelihood estimation(MLE) to obtain a point estimation of the parameters θ. The log-likelihood is expressed as:
经常使用最大似然估计(MLE)来获得参数θ的点估计。 对数似然表示为:

The parameters θ are estimated by maximizing the log-likelihood, or minimizing the negative log likelihood(loss function):
通过最大化对数似然或最小化负对数似然(损失函数)来估计参数θ:

Instead of a point estimate, Bayesians estimate a full posterior distribution of the parameters using the Bayes’ formula:
贝叶斯代替点估计,而是使用贝叶斯公式估计参数的全部后验分布:

You might have noticed the computation of the denominator can be NP-hard because it has an integral (or summation in the case of classification) over all possible values of θ. You might also wonder if we can have a point estimate of θ, just like what MLE does. That’s where Maximum A Posteriori(MAP) estimation comes into play. MAP bypasses the cumbersome computation of the posterior distribution and instead tries to find the point estimates of θ that maximize the posterior distribution.
您可能已经注意到,分母的计算可能是NP难的,因为它在所有可能的θ值上都有一个积分(或分类的总和)。 您可能还会想知道,是否可以像MLE一样获得θ的点估计。 那就是最大后验 ( MAP )估计起作用的地方。 MAP绕过了后验分布的繁琐计算,而是尝试找到最大化后验分布的θ的点估计。

Since logarithmic functions are monotonic, we can rewrite the above equation in the log space and decompose it into 2 parts: maximizing the likelihood and maximizing the prior distribution:
由于对数函数是单调的,因此我们可以在对数空间中重写以上方程,并将其分解为两部分:最大化似然性和最大化先验分布:

Doesn’t this look similar to MLE?
这看起来不像MLE吗?
In fact, the connection between these two is that MAP can be treated as performing MLE on a regularized loss function where the prior corresponds to the regularization term. For example, if we assume the prior distribution to be Gaussian, MAP is equal to MLE with L2 regularization; if we assume the prior distribution to be Laplace, MAP is equal to MLE with L1 regularization.
实际上,这两者之间的联系在于,可以将MAP视为对正则化损失函数执行MLE,其中先验对应于正则化项。 例如,如果我们假设先验分布为高斯分布,则MAP等于经过L2正则化的MLE; 如果我们假设先验分布为Laplace,则MAP等于具有L1正则化的MLE。
There is another method to get a point estimate of the posterior distribution: Expected A Posteriori(EAP) estimation. The difference between MAP and EAP is that MAP gets the mode(maximum) of the posterior distribution whereas EAP gets the expected value of the posterior distribution.
还有一种获得后验分布的点估计的方法: 期望后验(EAP)估计。 MAP和EAP之间的区别在于MAP获取后验分布的众数(最大值),而EAP获取后验分布的期望值。
不确定 (Uncertainty)
The main difference between frequentist and Bayesian approaches is the way they measure uncertainty in parameter estimation.
贝叶斯方法和贝叶斯方法之间的主要区别在于它们在参数估计中测量不确定性的方式。
As we mentioned earlier, frequentists use MLE to get point estimates of unknown parameters and they don’t assign probabilities to possible parameter values. Therefore, to measure uncertainty, Frequentists rely on null hypothesis and confidence intervals. However, it’s important to point out that confidence intervals don’t directly translate to probabilities of hypothesis. For example, with a confidence interval of 95%, it only means 95% of the confidence intervals you’ve generated will cover the true estimate, but it’s incorrect to say that it covers the true estimate with a probability of 95% .
正如我们前面提到的, 常客使用MLE来获取未知参数的点估计,并且他们不会将概率分配给可能的参数值。 因此,为了衡量不确定性,经常性主义者依靠无效假设和置信区间。 但是,必须指出,置信区间不会直接转化为假设的概率。 例如,置信区间为95%,这仅意味着您生成的置信区间的95%将覆盖真实估计,但是说它以95%的概率覆盖真实估计是不正确的。
Bayesians, on the other hand, have a full posterior distribution over the possible parameter values and this allows them to get uncertainty of the estimate by integrating the full posterior distribution.
另一方面, 贝叶斯在可能的参数值上具有完整的后验分布,这使他们可以通过对完整的后验分布进行积分来获得估计的不确定性。
计算方式 (Computation)
Bayesians are usually more computationally intensive than frequentists due to integration over many parameters. There are some approaches to reduce the computational intensity by using conjugate priors or approximating the posterior distribution using sampling methods or variational inference.
由于集成了许多参数,因此贝叶斯算法通常比频繁用户要占用更多的计算资源。 有一些方法可以通过使用共轭先验或使用采样方法或变分推论来近似后验分布来降低计算强度。
例子 (Examples)
In this section, we will see how to train and make predictions with two algorithms: linear regression and Bayesian linear regression.
在本节中,我们将看到如何使用两种算法训练和做出预测:线性回归和贝叶斯线性回归。
线性回归(频率) (Linear Regression (frequentist))
We assume the below form of a linear regression model where the intercept is incorporated in the parameter θ:
我们假设以下形式的线性回归模型,其中截距包含在参数θ中:

The data is assumed to be distributed according to Gaussian distribution:
假定数据根据高斯分布进行分布:

Using MLE to maximize the log likelihood, we can get the point estimate of θ as shown below:
使用MLE最大化对数似然,我们可以得到θ的点估计,如下所示:

Once we’ve learned the parameters θ from the training data, we can directly use it to make predictions with new data:
一旦从训练数据中学到了参数θ,就可以直接使用它来对新数据进行预测:

贝叶斯线性回归(贝叶斯) (Bayesian Linear Regression (bayesian))
As mentioned earlier, the Bayesian way is to make assumptions for both the prior and likelihood:
如前所述,贝叶斯方法是对先验和可能性进行假设:

Using these assumptions and the Bayes’ formula, we can get the posterior distribution:
使用这些假设和贝叶斯公式,我们可以得出后验分布:
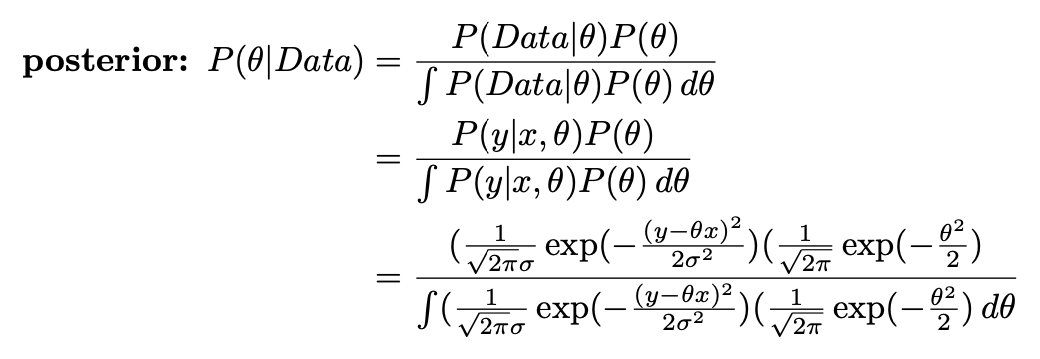
At prediction time, we use the posterior distribution and the likelihood to calculate the posterior predictive distribution:
在预测时,我们使用后验分布和可能性来计算后验预测分布:

Notice that the estimation for both the parameters and predictions are full distributions. Of course, if we only need a point estimate, we can always use MAP or EAP.
注意,参数和预测的估计都是完整分布。 当然,如果我们只需要一个点估计,则可以始终使用MAP或EAP。
结论 (Conclusions)
The main goal of machine learning is to make predictions using the parameters learned from training data. Whether we should achieve the goal using frequentist or Bayesian approach depends on :
机器学习的主要目标是使用从训练数据中学到的参数进行预测。 我们是否应该使用常客或贝叶斯方法实现目标取决于:
- The type of predictions we want: a point estimate or a probability of potential values. 我们想要的预测类型:点估计或潜在值的概率。
- Whether we have prior knowledge that can be incorporated into the modeling process. 我们是否具有可以纳入建模过程的先验知识。
On a side note, we discussed discriminative and generative models earlier. A common misconception is to label discriminative models as frequentist and generative models as Bayesian. In fact, both frequentist and Bayesian approaches can be used for discriminative or generative models. You can refer to this post for more clarification.
附带说明,我们之前讨论了判别模型和生成模型 。 一个常见的误解是将歧视性模型标记为贝叶斯主义的频繁性和生成性模型。 实际上,常客和贝叶斯方法均可用于判别或生成模型。 您可以参考该帖子以获取更多说明。
I hope you enjoyed reading this article. :)
希望您喜欢阅读本文。 :)
翻译自: https://towardsdatascience.com/frequentist-vs-bayesian-approaches-in-machine-learning-86ece21e820e
机器学习 贝叶斯方法















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









