





kmeans
Clustering is part of an unsupervised algorithm in machine learning. Unlike supervised algorithms like linear regression, logistic regression, etc, clustering works with unlabeled data or data without target variables.
聚类是机器学习中无监督算法的一部分。 与线性回归,逻辑回归等监督算法不同,聚类适用于未标记的数据或没有目标变量的数据。
The task of clustering is to group similar data points.
聚类的任务是对相似的数据点进行分组。
聚类类型: (Types of Clustering:)
Clustering comes under the data mining topic and there is a lot of research going on in this field and there exist many clustering algorithms.
聚类属于数据挖掘主题,并且在该领域中进行了大量研究,并且存在许多聚类算法。
The following are the main types of clustering algorithms.
以下是聚类算法的主要类型。
K-Means
K均值
Hierarchical clustering
层次聚类
DBSCAN
数据库扫描
集群的应用: (Applications of Clustering:)
Following are some of the applications of clustering
以下是集群的一些应用
- Customer Segmentation: This is one of the most important use-cases of clustering in the sales and marketing domain. Here the aim is to group people or customers based on some similarities so that they can come up with different action items for the people in different groups. One example could be, amazon giving different offers to different people based on their buying patterns. 客户细分:这是销售和营销领域中最重要的集群用例之一。 此处的目的是基于某些相似之处将人员或客户分组,以便他们可以为不同组中的人员提出不同的操作项。 一个例子可能是,亚马逊根据他们的购买方式向不同的人提供不同的报价。
- Image Segmentation: Clustering is used in image segmentation where similar image pixels are grouped together. Pixels of different objects in the image are grouped together. 图像分割:聚类用于图像分割中,其中将相似的图像像素分组在一起。 图像中不同对象的像素被分组在一起。

3. Pre-processing steps: Supervised machine learning algorithms are more robust and interpretable than unsupervised algorithms but you can’t use supervised algorithms unless you have labeled data. In such cases Clustering is used as a pre-processing step where clustering is used to group unlabeled data and then labeled are assigned to it and then this data can be used for supervised algorithms.
3.预处理步骤:有监督的机器学习算法比无监督的算法更健壮和易于解释,但除非已标记数据,否则您不能使用有监督的算法。 在这种情况下,将聚类用作预处理步骤,其中将聚类用于将未标记的数据分组,然后将标记的数据分配给它,然后可以将此数据用于监督算法。
K均值: (K-means:)
K- means also called Lloyd’s algorithm.
K-也称为劳埃德算法。
Steps in K-means:
K-均值中的步骤:
- Initialize k centroid randomly. 随机初始化k重心。
- Assign each point to its nearest centroid. 将每个点分配给它最近的质心。
- Re-compute all k centroids 重新计算所有k个质心
- repeat steps 2 and 3 until centroid does not change. 重复步骤2和3,直到质心不变。
The centroid is a point at the center of the cluster.
重心是群集中心的一个点。
距离功能: (Distance Functions:)
At step 2, each point is assigned yo it’s the nearest centroid, now the obvious question is how model find out which is the nearest centroid?
在第2步,每个点都被分配了,它是最接近的质心,现在显而易见的问题是模型如何找出最接近的质心?
There are many ways to calculate the distance between data point and centroid and some of the distance functions are the following:
有许多方法可以计算数据点和质心之间的距离,其中一些距离函数如下:

Intra-Cluster Distance: Distance between points within the same cluster.
集群内距离:同一集群内点之间的距离。
Inter-Cluster Distance: Distance between points within a Different cluster
群集间距离:不同群集中点之间的距离
如何选择最佳的K? (How to select the best K?)
K is the hyper-parameter in the K-mean algorithm which we have to provide before the model starts training.
K是我们必须在模型开始训练之前提供的K均值算法中的超参数。
Inertia: This is the mean squared distance between each data point and its closest centroid.
惯性 :这是每个数据点与其最接近的质心之间的均方距离。

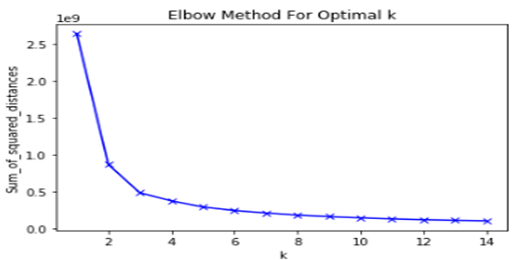
Run the model with a different value of K and check the value of inertia, smaller the value of Inertia better the value of K.
使用不同的K值运行模型并检查惯性值,惯性值越小,K值越好。
Silhouette Metrics:
轮廓指标 :

b: Inter-cluster distance.a: intra-cluster distance.
b:集群间距离。a:集群内距离。
1≤s≤1: Higher the Silhouette score, better the cluster.
1≤s≤1: Silhouette得分越高,聚类越好。
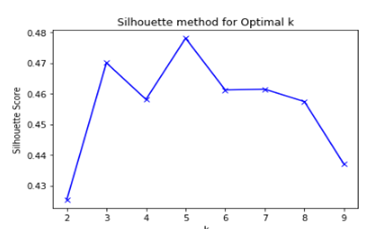
如何初始化K? (How to Initialize K?)
We have seen how to select the best value for K using either Inertia or Silhouette score. Once we select the best value of K, the next question is how to initialize it?
我们已经看到了如何使用惯性或轮廓分数为K选择最佳值。 一旦选择了K的最佳值,下一个问题是如何初始化它?
Random Initialization: In this, each data point has an equal probability of getting selected as a centroid.
随机初始化:在这种情况下,每个数据点被选择为质心的概率均等。
K-means++: In this,1st centroid is selected randomly from given data points and the next centroid gets selected based on its distance from other centroids. Higher the distance of the data point from the centroid, the higher the probability of getting selected as the next centroids.
K-均值++ :在这种情况下,从给定的数据点中随机选择第一个质心,然后根据与其他质心的距离选择下一个质心。 数据点到质心的距离越大,被选为下一个质心的可能性就越高。
K-均值的局限性: (Limitations of K-means:)
- It does not work that well if natural clusters in the original data are of different sizes. 如果原始数据中的自然簇具有不同大小,则效果不佳。

2. It does not work that well if natural clusters in the original data are of different density.
2.如果原始数据中的自然簇具有不同的密度,则效果不佳。

3. It does not work that well if natural clusters in the original data are of non-spherical shape.
3.如果原始数据中的自然簇为非球形,则效果不佳。

层次聚类: (Hierarchical Clustering:)
One of the main issues with the K-means algorithm is that we have to provide the value of K to the model before training starts. To overcome that hierarchical clustering is used.
K均值算法的主要问题之一是,我们必须在训练开始之前将K的值提供给模型。 为了克服该分层聚类问题。
K模式和K原型: (K-Mode & K-prototype:)
K-means algorithm works with numerical data only. If you have categorical data only then use the K-mode algorithm. If you have both categorical and numerical data then use the k-prototype algorithm.
K-means算法仅适用于数字数据。 如果仅具有分类数据,则使用K模式算法。 如果您同时拥有分类数据和数值数据,请使用k-prototype算法。
Thanks for your time. If you find this useful then please like and comment.
谢谢你的时间。 如果您觉得此功能有用,请喜欢并发表评论。
Happy reading!
祝您阅读愉快!
翻译自: https://medium.com/@nish2288_97533/kmeans-clustering-basics-96fb7c4279ef
kmeans















 3644
3644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









