





数据可视化 信息可视化
The role of a data scientists involves retrieving hidden relationships between massive amounts of structured or unstructured data in the aim to reach or adjust certain business criteria. In recent times this role’s importance has been greatly magnified as businesses look to expand insight about the market and their customers with easily obtainable data.
数据科学家的作用涉及检索大量结构化或非结构化数据之间的隐藏关系,以达到或调整某些业务标准。 近年来,随着企业希望通过易于获得的数据来扩大对市场及其客户的洞察力,这一作用的重要性已大大提高。
It is the data scientists job to take that data and return a deeper understanding of the business problem or opportunity. This often involves the use of scientific methods of which include machine learning (ML) or neural networks (NN). While these types of structures may find meaning in thousands of data points much faster than a human can, they can be unreliable if the data that is fed into them is messy data.
数据科学家的工作是获取这些数据并返回对业务问题或机会的更深刻理解。 这通常涉及使用科学方法,包括机器学习(ML)或神经网络(NN)。 尽管这些类型的结构可以在数千个数据点中找到比人类更快得多的含义,但是如果馈入其中的数据是凌乱的数据,则它们可能不可靠。
Messy data could cause have very negative consequences on your models they are of many forms of which include:
杂乱的数据可能会对您的模型造成非常不利的影响,它们的形式很多,包括:
缺少数据 : (Missing data:)
Represented as ‘NaN’ (an acronym of Not a Number) or as a ‘None’ a Python singleton object.
表示为“ NaN”(不是数字的缩写)或Python单例对象的“无”。
Sometimes the best way to deal with problems is the simplest.
有时,解决问题的最佳方法是最简单的。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsdf = pd.read_csv('train.csv')df.info()A quick inspection of the returned values shows the column count of 891 is inconsistent across the different columns a clear sign of missing information. We also notice some fields are of type “object” we’ll look at that next.
快速检查返回的值会发现在不同的列中891的列数不一致,明显缺少信息。 我们还注意到,接下来将要介绍一些字段属于“对象”类型。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 11 columns):
survived 891 non-null int64
pclass 891 non-null int64
name 891 non-null object
sex 891 non-null object
age 714 non-null float64
sibsp 891 non-null int64
parch 891 non-null int64
ticket 891 non-null object
fare 891 non-null float64
cabin 204 non-null object
embarked 889 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 76.7+ KBAlternatively you can plot the missing values on a heatmap using seaborn but this could be very time consuming if handling big dataframes.
或者,您可以使用seaborn在热图上绘制缺失值,但是如果处理大数据帧,这可能会非常耗时。
sns.heatmap(df.isnull(), cbar=False)数据不一致 : (Inconsistent data:)
- Inconsistent columns types: Columns in dataframes can differ as we saw above. Columns could be of a different types such as objects, integers or floats and while this is usually the case mismatch between column type and the type of value it holds might be problematic. Most important of format types include datetime used for time and date values. 列类型不一致:数据框中的列可能会有所不同,如上所述。 列可以具有不同的类型,例如对象,整数或浮点数,虽然通常这是列类型与其所拥有的值类型不匹配的情况,但可能会出现问题。 最重要的格式类型包括用于时间和日期值的日期时间。
- Inconsistent value formatting: While this type of problem might mainly arise during categorical values if misspelled or typos are present it can be checked with the following: 值格式不一致:虽然这种类型的问题可能主要在分类值期间出现(如果存在拼写错误或错字),但可以使用以下方法进行检查:
df[‘age’].value_counts()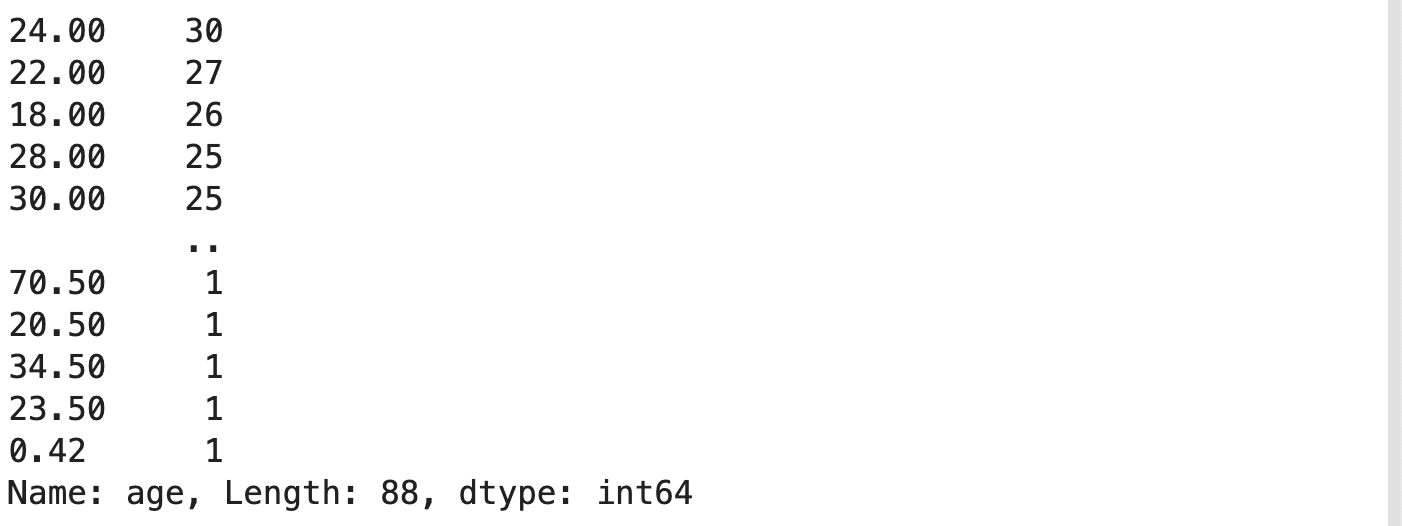
This will return the number of iterations each value is repeated throughout the dataset.
这将返回在整个数据集中重复每个值的迭代次数。
离群数据 : (Outlier data:)
A dataframe column holds information about a specific feature within the data. Hence we can have a basic idea of the range of those values. For example age, we know there is going to be a range between 0 or 100. This does not mean that outliers would not be present between that range.
数据框列保存有关数据中特定功能的信息。 因此,我们可以对这些值的范围有一个基本的了解。 例如,年龄,我们知道将有一个介于0或100之间的范围。这并不意味着在该范围之间不会出现异常值。
A simple illustration of the following can be seen graphing a boxplot:
可以通过绘制箱形图来简单了解以下内容:
sns.boxplot(x=df['age'])
plt.show()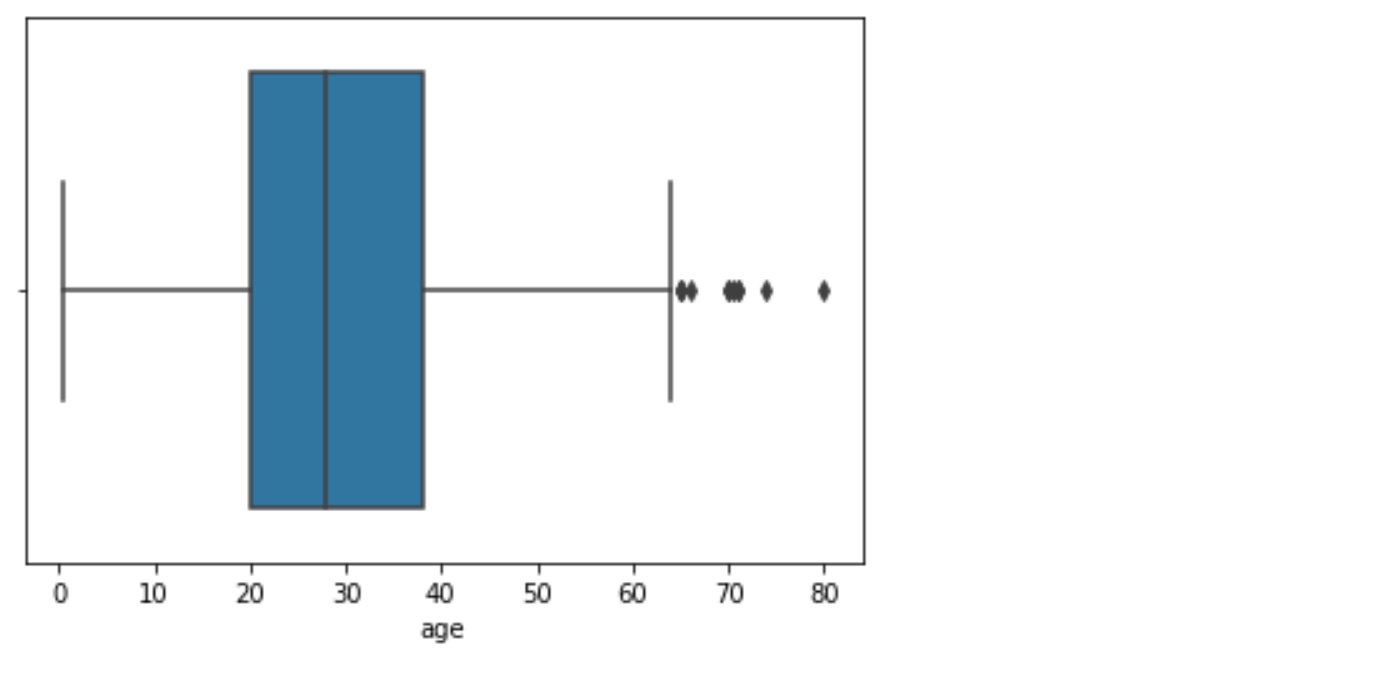
The values seen as dots on the righthand side could be considered as outliers in this dataframe as they fall outside the the range of commonly witnessed values.
在此数据框中,右侧的点表示的值可以视为离群值,因为它们不在通常见证的值范围之内。
多重共线性: (Multicollinearity:)
While multicollinearity is not considered to be messy data it just means that the columns or features in the dataframe are correlated. For example if you were to have a a column for “price” a column for “weight” and a third for “price per weight” we expect a high multicollinearity between these fields. This could be solved by dropping some of these highly correlated columns.
虽然多重共线性不被认为是凌乱的数据,但这仅意味着数据框中的列或要素是相关的。 例如,如果您有一个“价格”列,一个“重量”列和一个“每重量价格”列,那么我们期望这些字段之间具有较高的多重共线性。 这可以通过删除一些高度相关的列来解决。
f, ax = plt.subplots(figsize=(10, 8))corr = df.corr()
sns.heatmap(corr, mask=np.zeros_like(corr, dtype=np.bool), cmap=sns.diverging_palette(220, 10, as_cmap=True), square=True, ax=ax)
In this case we can see that the values do not exceed 0.7 either positively nor negatively and hence it can be considered safe to continue.
在这种情况下,我们可以看到值的正或负均不超过0.7,因此可以认为继续操作是安全的。
使此过程更容易: (Making this process easier:)
While data scientists often go through these initial tasks repetitively, it could be made easier by creating structured functions that allows the easy visualisation of this information. Lets try:
尽管数据科学家经常重复地完成这些初始任务,但通过创建结构化的函数可以使此信息的可视化变得更加容易。 我们试试吧:
----------------------------------------------------------------
from quickdata import data_viz # File found in repository
----------------------------------------------------------------from sklearn.datasets import fetch_california_housingdata = fetch_california_housing()
print(data[‘DESCR’][:830])
X = pd.DataFrame(data[‘data’],columns=data[‘feature_names’])
y = data[‘target’]1-Checking Multicollinearity
1-检查多重共线性
The function below returns a heatmap of collinearity between independent variables as well as with the target variable.
下面的函数返回自变量之间以及目标变量之间共线性的热图。
data = independent variable df X
数据 =自变量df X
target = dependent variable list y
目标 =因变量列表y
remove = list of variables not to be included (default as empty list)
remove =不包括的变量列表(默认为空列表)
add_target = boolean of whether to view heatmap with target included (default as False)
add_target =是否查看包含目标的热图的布尔值(默认为False)
inplace = manipulate your df to save the changes you made with remove/add_target (default as False)
inplace =操纵df保存使用remove / add_target所做的更改(默认为False)
*In the case remove was passed a column name, a regplot of that column and the target is also presented to help view changes before proceeding*
*如果为remove传递了一个列名,该列的重新绘制图和目标,则在继续操作之前还会显示目标以帮助查看更改*
data_viz.multicollinearity_check(data=X, target=y, remove=[‘Latitude’], add_target=False, inplace=False)
data_viz.multicollinearity_check(data = X,target = y,remove = ['Latitude'],add_target = False,inplace = False)
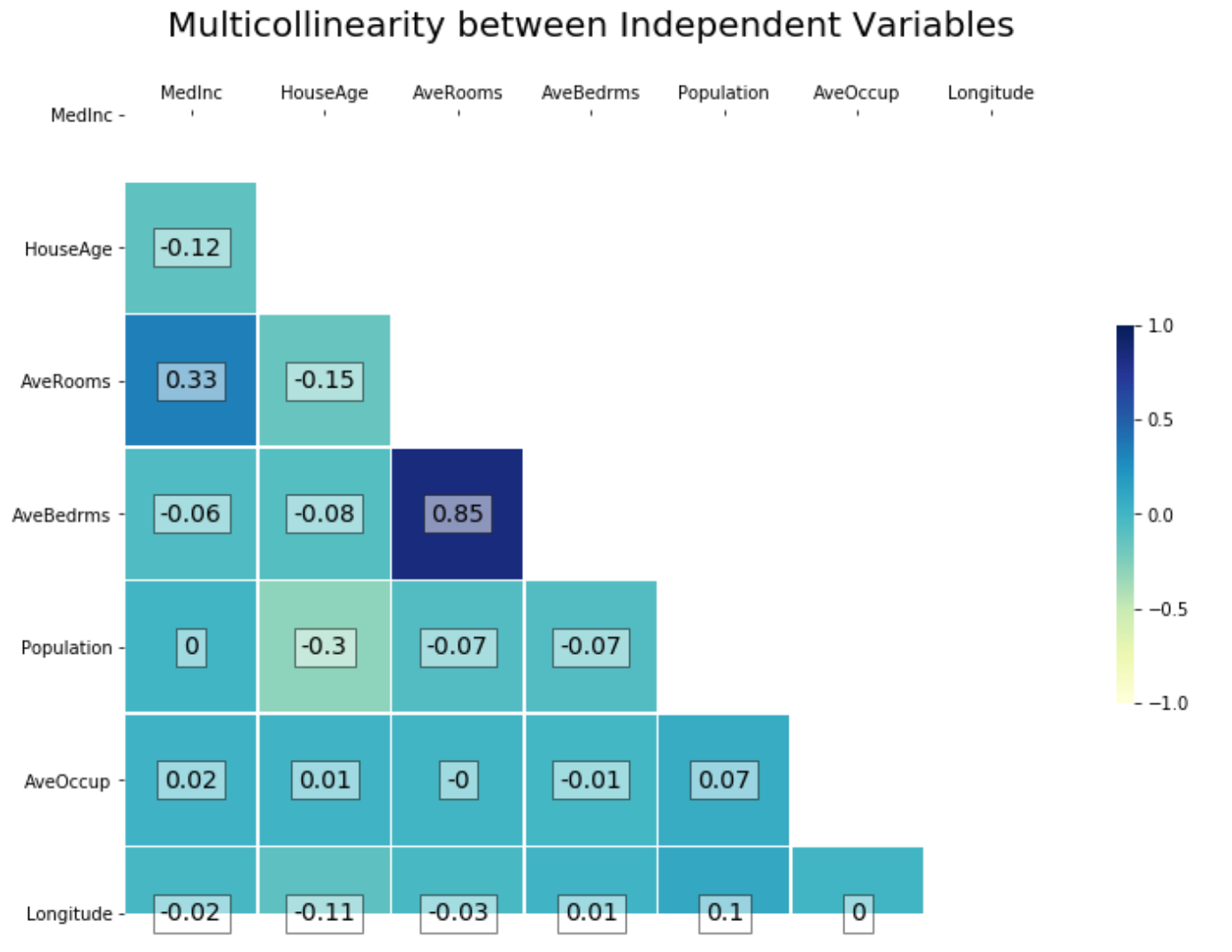

2- Viewing Outliers:This function returns a side-by-side view of outliers through a regplot and a boxplot visualisation of a the input data and target values over a specified split size.
2-查看离群值:此函数通过regplot和箱形图可视化返回离群值的并排视图,该图显示输入数据和目标值在指定分割范围内的情况。
data = independent variable df X
数据 =自变量df X
target = dependent variable list y
目标 =因变量列表y
split = adjust the number of plotted rows as decimals between 0 and 1 or as integers
split =将绘制的行数调整为0到1之间的小数或整数
data_viz.view_outliers(data=X, target=y, split_size= 0.3 )
data_viz.view_outliers(data = X,target = y,split_size = 0.3)

It is important that these charts are read by the data scientist and not automated away to the machine. Since not all datasets follow the same rules it is important that a human interprets the visualisations and acts accordingly.
这些图表必须由数据科学家读取,而不是自动传送到计算机,这一点很重要。 由于并非所有数据集都遵循相同的规则,因此重要的是,人类必须解释视觉效果并据此采取行动。
I hope this short run-through of data visualisation helps provide more clear visualisations of your data to better fuel your decisions when data cleaning.
我希望这段简短的数据可视化过程有助于为您的数据提供更清晰的可视化,以便在清理数据时更好地推动您的决策。
The functions used in the example above is available here :
上面示例中使用的功能在此处可用:
Feel free to customise these as you see fit!
随意自定义这些内容!
翻译自: https://medium.com/@rani_64949/visualisations-of-data-for-help-in-data-cleaning-dce15a94b383
数据可视化 信息可视化















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









