





熊猫烧香源码分析
介绍(Introduction)
Being a data scientist in today's age is an incredibly exciting and rewarding career. With the explosion of technology and the immense amount of data and content created daily, data scientist continually need to be learning new ways of efficiently analysing this data. One of the most crucial parts of any new data project is the exploratory data analysis phase. As a data scientist, this phase allows you to learn and familiarize yourself with that data at hand, where the data is collected from, any gaps in the data, any potential outliers and the range of data types used. One tool that has become a staple among data scientist is Pandas Profiling. Pandas Profiling is an open-source tool written in Python that has the ability to generate interactive HTML reports which detail the types of data within the dataset; Highlights missing values; Provides descriptive statistics including mean, standard deviation and skewness; Creates histograms and returns any potential correlations.
身为当今时代的数据科学家,是一项令人难以置信的激动人心的职业。 随着技术的爆炸式增长以及每天创建的大量数据和内容,数据科学家不断需要学习有效分析此数据的新方法。 探索性数据分析阶段是任何新数据项目中最关键的部分之一。 作为数据科学家,此阶段使您可以学习和熟悉手头的数据,从中收集数据,数据中的任何空白,任何潜在的异常值以及所用数据类型的范围。 Pandas Profiling是数据科学家中最常用的一种工具。 Pandas Profiling是一个用Python编写的开放源代码工具,具有生成详细描述数据集中数据类型的交互式HTML报告的功能; 突出显示缺失的值; 提供描述性统计信息,包括均值,标准差和偏度; 创建直方图并返回任何潜在的相关性。
安装熊猫分析 (Installing Pandas Profiling)
For this article, we are using PyCharm which is an integrated development environment created by JetBrains. PyCharm is an excellent tool to use as it handles tasks including creating a virtual environment for the project and the installation of packages referenced in your code.
对于本文,我们使用的是PyCharm ,它是JetBrains创建的集成开发环境。 PyCharm是一个出色的工具,可用于处理任务,包括为项目创建虚拟环境以及安装代码中引用的软件包。
To get started open PyCharm and selected File > New Project, you will be presented with a dialogue where you can name the project and create an associated virtual environment. Virtual environments allow you to install specific python packages that your project can reference without having to globally install the packages on your machine. This is handy when you have multiple projects running that require a different version of the same package.
首先,打开PyCharm并选择File > New Project ,将显示一个对话框,您可以在其中命名项目并创建关联的虚拟环境。 虚拟环境允许您安装项目可以引用的特定python软件包,而无需在计算机上全局安装这些软件包。 当您有多个运行的项目需要同一个程序包的不同版本时,这很方便。
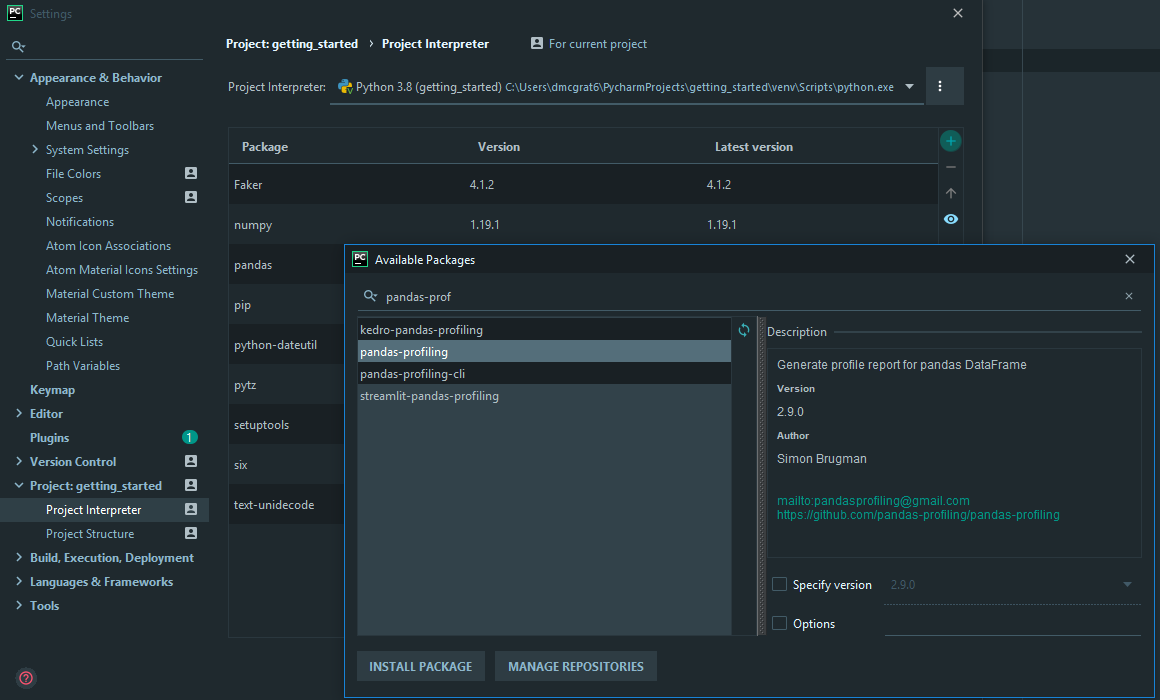
Once the default packages have been installed in the virtual environment we need to install Pandas Profiling. To do this navigate to File > Settings > Project > Project Interpreter select the + button in the top right and search for pandas-profiling then press Install Package.
在虚拟环境中安装了默认软件包后,我们需要安装Pandas Profiling。 为此,请导航至“ File > Settings > Project > Project Interpreter选择右上角的+按钮并搜索pandas-profiling然后按Install Package 。
入门 (Getting Started)
For this example, we have created a simple Python script that you can use to get started. If this is your first time using Python please read Getting Started — Python Pandas where we explain the code within the script below.
在此示例中,我们创建了一个简单的Python脚本,您可以使用它开始入门。 如果这是您第一次使用Python,请阅读“入门-Python Pandas” ,我们在下面的脚本中解释代码。
After executing the script a new HTML file called pandas_profile_text.html will be created in your project root directory. To view the report right-click on the HTML file and select Open in Browser > Default.
执行脚本后,将在项目根目录中创建一个名为pandas_profile_text.html的新HTML文件。 要查看报告,请右键单击HTML文件,然后选择Open in Browser > Default 。
熊猫分析报告 (Pandas Profiling Report)
总览(Overview)

The Overview section, the first section within the Pandas Profiling Report, shows summarised statistics for the dataset as a whole. It returns the number of variables, which is the number of columns that were included in the passed DataFrame. The number of observations is the number of rows that were received. The Overview also provides the number of missing cells or duplicate rows and a percentage of total records that were impacted. The missing cells and duplicate row statistics are quite important as a data scientist as these may indicate broader data quality issues or issues with the code used to extract the data. The overview section also includes data around the size of the dataset in memory, the average record size in memory and any data types that are recognised.
概述部分(Pandas分析报告的第一部分)显示了整个数据集的摘要统计信息。 它返回变量的数量,即传递的DataFrame中包含的列数。 观察数是已接收的行数。 概述还提供了丢失的单元格或重复的行数以及受影响的总记录的百分比。 作为数据科学家,缺失的单元格和重复的行统计信息非常重要,因为它们可能表示更广泛的数据质量问题或用于提取数据的代码问题。 概述部分还包括有关内存中数据集大小,内存中平均记录大小以及可识别的任何数据类型的数据。
Under the Warnings tab within the Overview section, you can find collated warnings for any of the variables within the dataset. In this example, we received a high cardinality warning for name, email and city. Within this context, the high cardinality means that the columns that were flagged contain a very high number of distinct values, you would expect this for employee number and email in the real world.
在“概述”部分的“警告”选项卡下,可以找到数据集中任何变量的整理的警告。 在此示例中,我们收到了有关名称,电子邮件和城市的高基数警告。 在这种情况下,高基数意味着标记的列包含非常多的不同值,您希望在现实世界中对雇员编号和电子邮件使用此值。
变量—分类 (Variables — Categorial)

The Variables section within the Pandas Profiling report analyses the columns within the passed DataFrame. A categorical variable is a column that contains data that represents a Python string type.
Pandas Profiling报告中的Variables部分分析了传递的DataFrame中的列。 分类变量是一列,其中包含表示Python字符串类型的数据。
A typical metric returned for categorical variables is the length of the strings within the column. To view the generated histogram select Toggle Details then navigate to the Length tab. The length tab also contains statistics regarding the maximum, median, mean and minimum values of the string length.
返回的用于分类变量的典型指标是列中字符串的长度。 要查看生成的直方图,请选择“ Toggle Details然后导航到“ Length选项卡。 长度选项卡还包含有关字符串长度的最大值,中位数,平均值和最小值的统计信息。
变量-数值 (Variables — Numerical)

Pandas Profiling offers an incredibly in-depth analysis of numerical variables covering quantile and descriptive statistics. It returns the minimum and maximum values within the dataset and the range between. It displays quartile values which measure the distribution of the ordered values in the dataset above and below the median by dividing the set into four bins. When considering the quartile values, if there is a greater distance between quartile one and the median verse the median and quartile three then we interpret this as meaning a greater scatter of smaller values than the larger values. The interquartile range is simply the results of quartile three minus quartile one.
熊猫分析提供了涵盖分位数和描述性统计数据的令人难以置信的深度分析。 它返回数据集中的最小值和最大值及其之间的范围。 它显示其中通过将所述一组为四个二进制位测量有序值的在上方和下方的中值数据集的分布的四分位数的值。 在考虑四分位数时,如果四分位数1与中位数和中位数与四分位数3之间的距离较大,则我们将其解释为意味着较小值的分散程度大于较大值。 四分位数范围仅是四分位数三减四分之一的结果。
Standard deviation reflects the distributions of the dataset with regards to its mean value. A low standard deviation implies that the values in the data set are closer to the mean, whereas a higher standard deviation value implies that the dataset values are spread over a greater range. The coefficient of variation, also known as relative standard deviation, is the ratio of the standard deviation to the mean. Kurtosis can be used to describe the shape of the data by measuring the values within the tails of the distribution relative to the mean of the ordered dataset. The Kurtosis value varies depending on the distribution of the data and the presence of extreme outliers. The median absolute deviation is another statistical measure that reflects the distribution of the data around the median and is a more robust measure of the spread when an extreme outlier is present. Skewness reflects the level of distortion from a standard bell-shaped probability distribution. Positive skewness is considered skewness to the right and has a longer tail to the right of the distribution and a negative to the left.
标准差反映有关数据集平均值的分布。 低标准偏差表示数据集中的值更接近平均值,而较高的标准偏差值表示数据集值分布在较大范围内。 变异系数,也称为相对标准偏差,是标准偏差与平均值的比率。 峰度可用于通过测量分布尾部相对于有序数据集平均值的值来描述数据的形状。 峰度值根据数据分布和极端异常值的存在而变化。 中位数绝对偏差是另一种统计量度,可反映数据在中位数附近的分布,并且是在存在极端离群值时对散布的更可靠度量。 偏斜度反映了标准钟形概率分布的失真程度。 正偏度被认为是右侧偏度,并且在分布的右侧具有较长的尾巴,而在左侧则为负。
互动与相关 (Interaction and Correlations)

The Interaction and Correlations sections are where Pandas Profiling really sets itself ahead of other exploratory tools. It analyses all the variables as pairs and highlights any highly correlating variables using Pearson, Spearman, Kendal and Phik measures. It provides a powerful easy to understand visual representation of any data that correlations strongly together. As a data scientist, this is a great starting point for questions as to why these data pairs may correlate.
交互和关联部分是Pandas Profiling真正领先于其他探索工具的地方。 它对所有变量进行成对分析,并使用Pearson,Spearman,Kendal和Phik度量突出显示任何高度相关的变量。 它提供了强大且易于理解的任何紧密关联在一起的数据的视觉表示。 作为数据科学家,这是质疑为什么这些数据对可能相互关联的一个很好的起点。
缺失值 (Missing Values)

The Missing Values section builds on the missing cells metric from the Overview section. It visually represents where the missing values are occurring against all the columns within the DataFrame. This section may highlight data quality issues and may require missing data to be mapped to a default value which we will cover in a later article.
“缺少值”部分基于“概述”部分中的“缺少单元格”度量标准。 它直观地表示DataFrame中所有列的缺失值发生在哪里。 本节可能重点介绍数据质量问题,并且可能要求将丢失的数据映射到默认值,我们将在以后的文章中介绍。
样品部分 (Sample Section)
The sample section displays a snapshot of results from the head and tail of the dataset. If the dataset is ordered on a particular column you can use this section to gain an understanding of what type of records the minimum and maximum column values are associated with.
样本部分显示了数据集头部和尾部的结果快照。 如果数据集在特定列上排序,则可以使用本节来了解最小和最大列值与哪种记录类型相关联。
概要 (Summary)
Pandas Profiling is an incredible open-source tool that every data scientist should consider adding to their toolbox for the data exploration phase in any project. It is an efficient way to digest and analyse an unfamiliar dataset by providing in-depth descriptive statistics, visual distribution graphs and a powerful set of correlation tools.
Pandas Profiling是令人难以置信的开源工具,每个数据科学家都应考虑将其添加到工具箱中,以进行任何项目中的数据探索阶段。 通过提供深入的描述性统计信息,可视化分布图和一组强大的关联工具,这是一种有效的方法来消化和分析不熟悉的数据集。
Thank you for taking the time to read our article, we hope you have found it valuable.
感谢您抽出宝贵的时间阅读我们的文章,希望您发现它有价值。
翻译自: https://towardsdatascience.com/learning-pandas-profiling-fc533336edc7
熊猫烧香源码分析















 259
259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









