





遗传算法解决函数优化问题
The solution to an optimization problem can be done by selecting different methods. Moreover, the user can navigate on the surface or curve to establish an initial point and find the optimal or critical point, which can be observed on the plotted function.
优化问题的解决方案可以通过选择不同的方法来完成。 此外,用户可以在表面或曲线上导航以建立初始点并找到最佳点或临界点,这可以在绘制的函数中观察到。
内容 (Contents)
1.Single Value Differentiation
1,单值差异
2. Minima and Maxima
2.最小值和最大值
3. Gradient descent algorithm
3.梯度下降算法
4. Steps for Gradient descent algorithm
4.梯度下降算法的步骤
5. Types of Gradient Descent algorithms
5.梯度下降算法的类型
6. Implementation of Stochastic Gradient Descent
6.随机梯度下降的实现
For Optimization problems Differentiation is very important, Let’s see some maths,
对于优化问题,求差非常重要,让我们看一些数学,
单值差异 (Single Value Differentiation)
Differentiation allows us to find rates of change. Intuitively dy/dx means how much does y changes as x changes.
差异使我们能够找到变化率。 直观上dy / dx表示y随着x的变化而变化了多少。
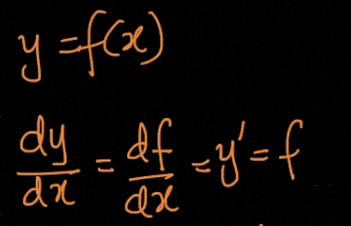
Geometrically the derivative [f’(x) or dy/dx] of the function y = f(x) at the point P(x, y) (when exists) is equal to the slope (or gradient) of the tangent line to the curve y = f(x) at P(x, y).
在几何上,函数y = f(x)在点P(x,y)(如果存在)上的导数[f'(x)或dy / dx]等于切线相对于的切线的斜率(或斜率)曲线y = f(x)在P(x,y)处。
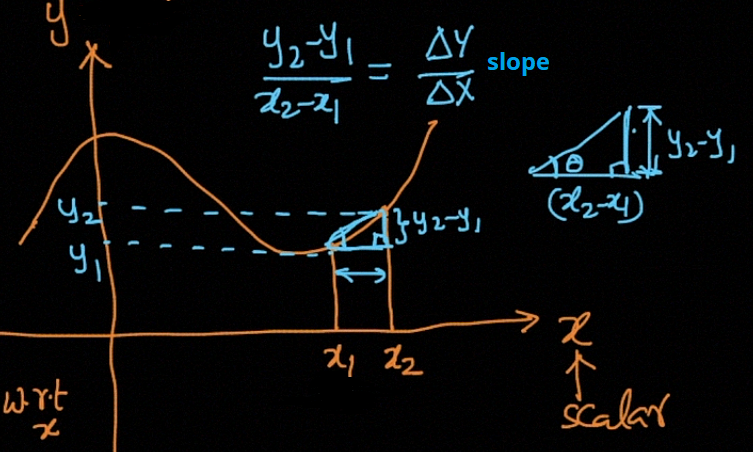
Tangent: In geometry, the tangent line to a plane curve at a given point is the straight line that “just touches” the curve at that point. Mathematically tangent is given by,
切线:在几何中,在给定点上与平面曲线的切线是在该点“仅接触”曲线的直线。 数学上的切线由
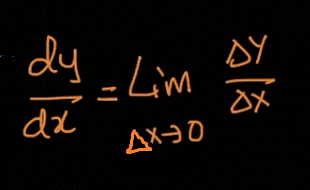
dy/dx is the slope of the tangent to f(x).
dy / dx是与f(x)的切线的斜率。
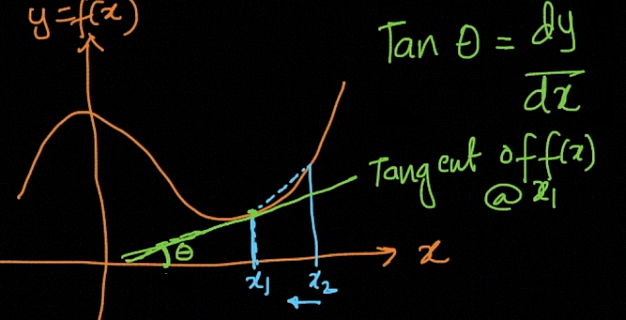
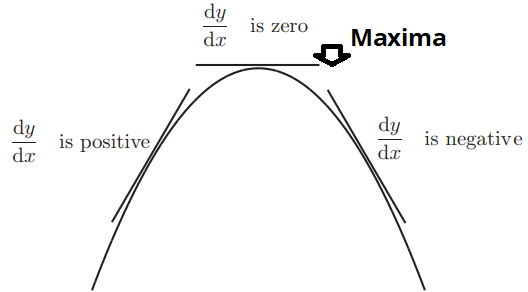
极小值和千里马 (Minima and Maxima)
A maximum is a high point and a minimum is a low point.
最大值是高点,最小值是低点。

In a smoothly changing function, a maximum or minimum is always where the function flattens out (except for a saddle point).
在平稳变化的函数中,最大值或最小值始终是函数展平的位置(鞍点除外)。
Where does it flatten out? Where the slope is zero.
它在哪里展平? 斜率为零的地方。
Where is the slope zero? The Derivative tells us!
斜率零在哪里? 导数告诉我们!
And there is an important technical point that the function must be differentiable.
还有一个重要的技术要点,就是功能必须是可区分的。
A stationary point on a curve is defined as one at which the derivative vanishes i.e. a point (x0, f(x0)) is a stationary point of f(x) if [dx/df]=0.
曲线上的固定点定义为导数消失的点,即如果[ dx / df ] = 0,则点(x0,f(x0))是f(x)的固定点。
Clearly, the derivative of the function has to go to 0 at the point of Local Maximum; otherwise, it would never attain a maximum value with respect to its neighbors.
显然,函数的导数必须在“局部最大值”处变为0。 否则,它将永远无法达到其邻居的最大值。
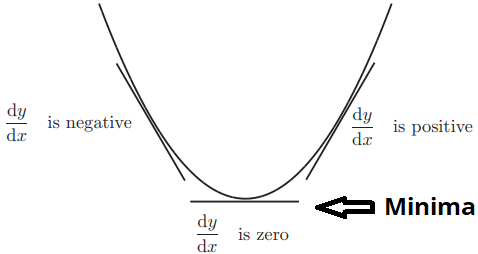
One can see that the slope of the tangent drawn at any point on the curve i.e. dy/dx changes from a negative value to 0 to a positive value, near the point of local minima.
可以看到在曲线的任何一点处绘制的切线的斜率(即dy / dx)在局部极小点附近从负值变为0变为正值。
First, we find the points that are maxima and minima using the following steps.
首先,使用以下步骤找到最大和最小的点。
Find the derivative of the function.
找到函数的导数。
- Set the derivative equal to 0 and solve for x. 将导数设置为0并求解x。
Plug the value you found for x into the function to find the corresponding y value. This is your maximum or minimum point.
插上你发现x的值到函数找到对应的y值。 这是您的最高或最低点。
But some functions are very complex we can’t find maxima and minima by solving that function is non-trivial shown below,
但是某些函数非常复杂,我们无法通过解决以下所示的平凡函数来找到最大值和最小值,
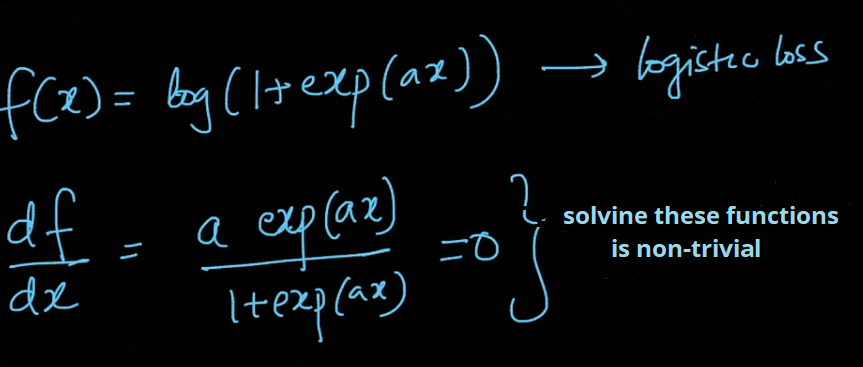
梯度下降算法 (Gradient descent algorithm)
Some functions are very complex to solve, so the computer science technique to solve those types of functions is the Gradient descent algorithm.
有些函数的求解非常复杂,因此解决这些函数类型的计算机科学技术是Gradient descent算法。
Gradient descent is an optimization algorithm that is mainly used to find the minimum of a function. In machine learning, gradient descent is used to update parameters in a model. Parameters can vary according to the algorithms.
梯度下降是一种优化算法,主要用于查找函数的最小值。 在机器学习中,梯度下降用于更新模型中的参数。 参数可以根据算法而变化。
Think of a valley you would like to descend when you are blind-folded. Any sane human will take a step and look for the slope of the valley, whether it goes up or down. Once you are sure of the downward slope you will follow that and repeat the step again and again until you have descended completely (or reached the minima).
想一想当你被蒙住眼睛时想要下降的山谷。 任何理智的人都会迈出一步,寻找山谷的坡度,无论它向上还是向下。 一旦确定下降斜率,就可以遵循该方法,并一次又一次地重复此步骤,直到完全下降(或达到最小值)为止。
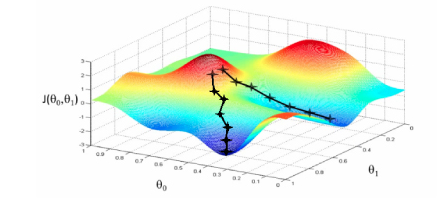
This is exactly what happens in gradient descent. The inclined and/or irregular is the cost function when it is plotted and the role of gradient descent is to provide direction and the velocity (learning rate) of the movement in order to attain the minima of the function i.e where the cost is minimum.
这正是梯度下降发生的情况。 倾斜和/或不规则是绘制时的成本函数,而梯度下降的作用是提供运动的方向和速度(学习率),以使函数达到最小值,即成本最小。
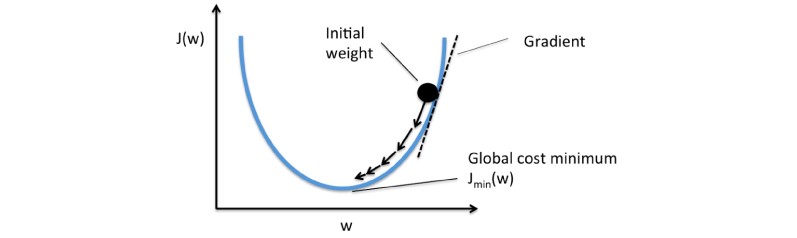
A gradient is a vector-valued function that represents the slope of the tangent of the graph of the function, pointing the direction of the greatest rate of increase of the function. It is a derivative that indicates the incline or the slope of the cost function.
梯度是一个矢量值函数,代表函数图的切线的斜率,指向函数最大增长率的方向。 它是表示成本函数的斜率或斜率的导数。
Consider the objective function f: Rd→Rf that takes any multi-dimensional vector x=[x1,x2,…, xd] as its input. The gradient of f(x) with respect to xx is defined by the vector of partial derivatives.
考虑目标函数f:Rd→Rf,它将任何多维矢量x = [x1,x2,…,xd]作为其输入。 f(x)相对于xx的梯度由偏导数向量定义。
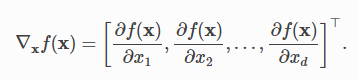
each element ∂f(x)/∂xi of the gradient indicates the rate of change for f at the point x with respect to the input xi only.
梯度的每个元素∂f(x)/∂xi表示f在x点处相对于输入xi的变化率。
f(x) gives the rates of change of ff at the point xx in all possible directions, to minimize f, we are interested in finding the direction where f can be reduced fastest.
f(x)给出点xx在所有可能的方向上ff的变化率,为了使f最小,我们有兴趣寻找f可以最快减小的方向。

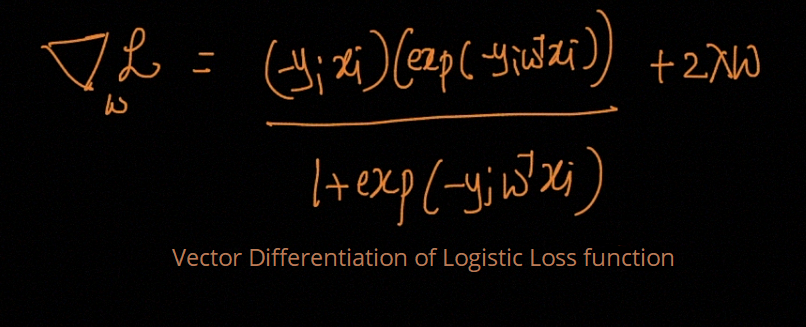
For Linear regression, we use a cost function known as the mean squared error or MSE.
对于线性回归,我们使用称为均方误差或MSE的成本函数。
梯度下降算法的步骤 (Steps for Gradient descent algorithm)
- First, we take a function we would like to minimize and very frequently given the gradient, calculate the change in the parameters with the learning rate.首先,我们采用一个函数,该函数要最小化并且非常频繁地给出梯度,然后根据学习率计算参数的变化。
- Re-calculate the new gradient with the new value of the parameter. 使用参数的新值重新计算新的梯度。
- Repeat step 1 until convergence. 重复步骤1,直到收敛为止。
Here is the formula of the gradient descent algorithm:
这是梯度下降算法的公式:
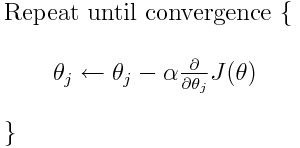
Convergence is a name given to the situation where the loss function does not improve significantly, and we are stuck in a point near to the minima.
收敛是损失函数没有显着改善并且我们陷入极小值附近的情况下的名称。
where α, alpha, is the learning rate, or how rapidly do we want to move towards the minimum. We can always overshoot if the value of α is too large.
其中,α是学习率,或者我们想要多快达到最小值。 如果α的值太大,我们总是可以超调的。
The gradient is a vector-valued function, and as a vector, it has both a direction and a magnitude. The Gradient descent algorithm multiplies the gradient by a number (Learning rate or Step size) to determine the next point.
梯度是矢量值的函数,作为矢量,它既具有方向又具有大小。 梯度下降算法将梯度乘以一个数字(学习率或步长)来确定下一个点。
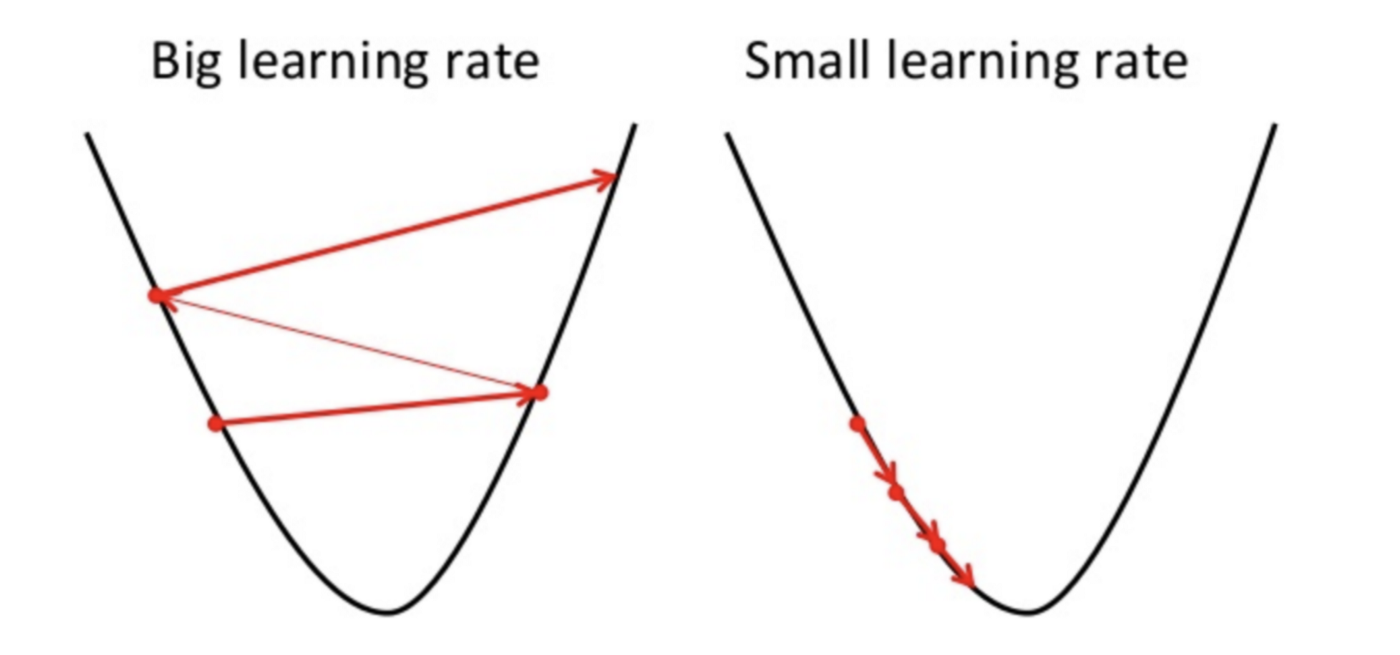
One of the problems is the value of the learning rate. The learning rate is a randomly chosen number that tells how far to move the weights. A small learning rate and you will take forever to reach the minima, a large learning rate and you will skip the minima.
问题之一是学习率的价值。 学习率是一个随机选择的数字,用于指示将权重移动多远。 学习率低时,您将永远花时间达到最小值;学习率高时,您将跳过最小值。
The parameters are updated by taking the gradient of the parameters and then the learning rate is multiplied which suggests how quickly we should go towards the minimum. The learning rate is a hyper-parameter and while choosing its value you should be careful.
通过采用参数的梯度来更新参数,然后将学习率相乘,这表明我们应多快达到最小值。 学习率是一个超参数,选择它的值时应小心。
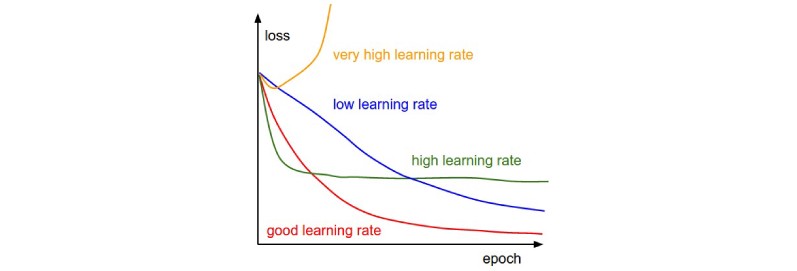
Typically, the value of the learning rate is chosen manually, starting with 0.1, 0.01, or 0.001 as the common values, and then adapt it whether the gradient descent is taking too long to calculate (you need to increase the learning rate), or is exploding or being erratic (you need to decrease the learning rate).
通常,手动选择学习率的值,以0.1、0.01或0.001作为常用值,然后根据梯度下降花费的时间太长来计算(您需要提高学习率),或者爆炸或不稳定(您需要降低学习率)。
梯度下降算法的类型 (Types of Gradient Descent Algorithms)

There are three variants of gradient descent based on the amount of data used to calculate the gradient:
根据用于计算梯度的数据量,可以使用三种梯度下降方法:
- Batch gradient descent 批次梯度下降
- Stochastic gradient descent随机梯度下降
- Mini-batch gradient descent小批量梯度下降
Batch Gradient Descent:
批次梯度下降:
Batch Gradient Descent, aka Vanilla gradient descent, calculates the error for each observation in the dataset but performs an update only after all observations have been evaluated.
批梯度下降(又称香草梯度下降)可为数据集中的每个观测值计算误差,但仅在评估所有观测值后才执行更新。
Batch gradient descent is not often used, because it represents a huge consumption of computational resources, as the entire dataset needs to remain in memory.
批梯度下降法不经常使用,因为它代表了计算资源的巨大消耗,因为整个数据集都需要保留在内存中。
Stochastic Gradient Descent:
随机梯度下降:
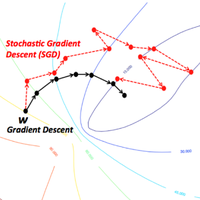
Stochastic gradient descent (SGD) performs a parameter update for each observation. So instead of looping over each observation, it just needs one to perform the parameter update. SGD is usually faster than batch gradient descent, but its frequent updates cause a higher variance in the error rate, which can sometimes jump around instead of decreasing.
随机梯度下降(SGD)对每个观测值执行参数更新。 因此,它不需要遍历每个观察值,而只需要执行一个即可进行参数更新。 SGD通常比批处理梯度下降快,但是SGD的频繁更新会导致错误率的变化较大,有时会跳动而不是减小。
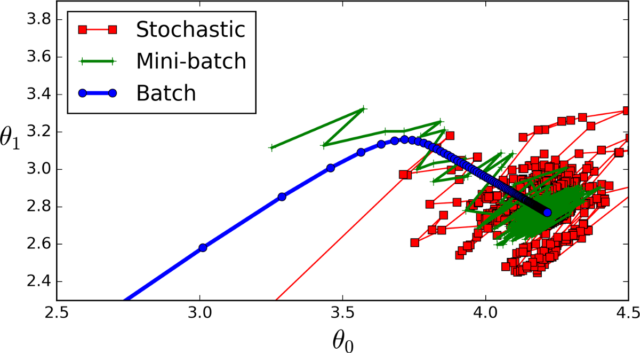
Mini-Batch Gradient Descent:
小批量梯度下降:
It is a combination of both bath gradient descent and stochastic gradient descent. Mini-batch gradient descent performs an update for a batch of observations. It is the algorithm of choice for neural networks, and the batch sizes are usually from 50 to 256.
它是浴梯度下降和随机梯度下降的组合。 小批量梯度下降对一批观测值进行更新。 它是神经网络的首选算法,批量大小通常为50到256。
线性回归的随机梯度下降的实现 (Implementation of Stochastic Gradient Descent for Linear Regression)
Objective :
目的:
- Take the Boston data set from sklearn. 从sklearn获取波士顿数据集。
- Write the SGDRegressor from scratch. 从头开始编写SGDRegressor。
- You don’t need to split the data into train and test, you consider whole data for this implementation. 您无需将数据拆分为训练和测试,而是需要考虑此实施的整个数据。
- Get weights( coefs_ and intercept ) from your model and the MSE value. 从模型和MSE值中获取权重(coefs_和intercept)。
- Don’t forget to standardize the data, and choose the appropriate learning rate. 不要忘记标准化数据,并选择合适的学习率。
- Train your model using SGDRegressor with the same parameters, and find the MSE on the same data. 使用具有相同参数的SGDRegressor训练模型,并在相同数据上找到MSE。
- Compare these two results. 比较这两个结果。
- You can choose any other metric other than MSE to compare them. They both should be the same. 您可以选择MSE以外的任何其他指标进行比较。 他们应该是相同的。
For Linear Regression, we use a cost function known as the mean squared error or MSE.
对于线性回归,我们使用称为均方误差或MSE的成本函数。
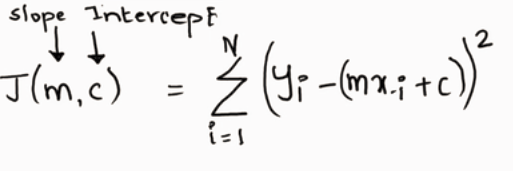
Now we will apply partial derivative with respect to m and c and will equate it to zero to find the least value of m and c for which our cost function gets the lowest value as possible.
现在,我们将对m和c应用偏导数,并将其等于零,以找到m和c的最小值,我们的成本函数将获得最小值。

First, we want to import all the required Libraries
首先,我们要导入所有必需的库
Importing the Boston data set from sklearn.
从sklearn导入波士顿数据集。

Data Standardization
数据标准化

SGDRegressor for Linear Regression using sklearn Library
使用sklearn库进行线性回归的SGDRegressor

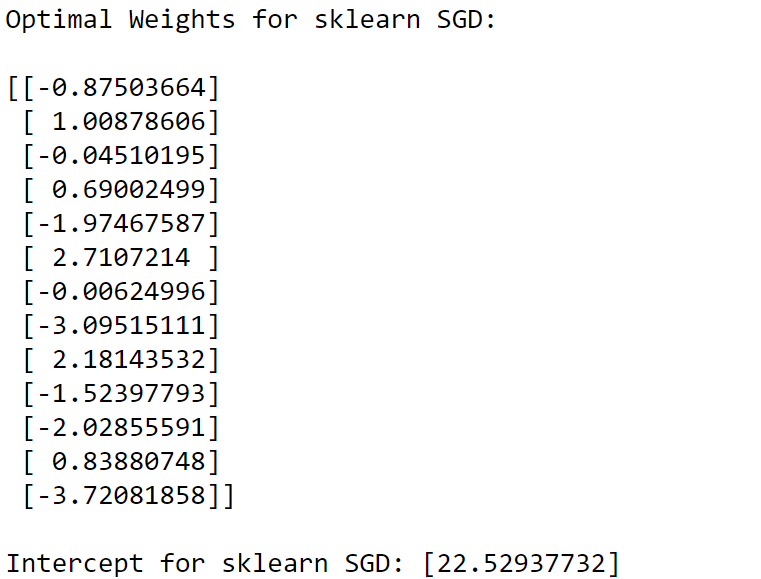
Optimal Weights and Intercept using sklearn SGD
使用sklearn SGD的最佳权重和拦截
Visualizing the results
可视化结果

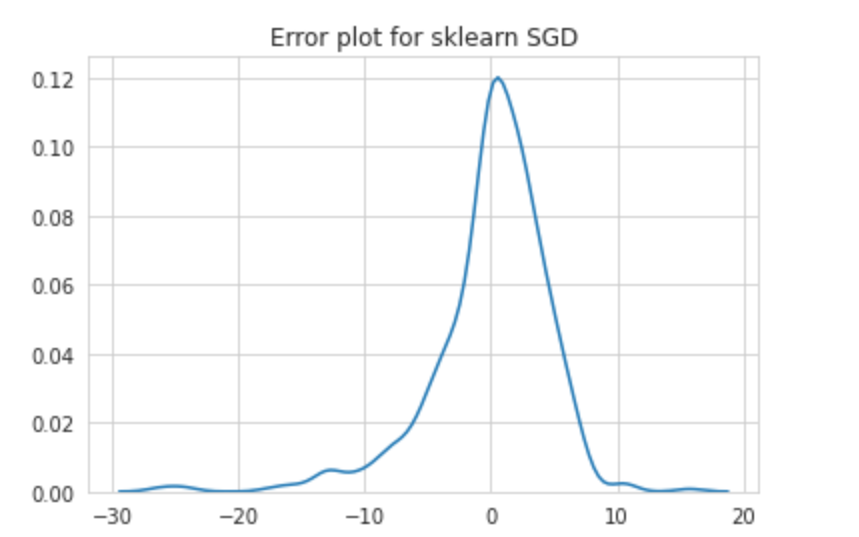
Error plot for sklearn SGD
sklearn SGD的误差图
We are also implemented using without using Library to know the full code visit my GitHub link here.
我们使用的是不使用库知道完整的代码访问我的GitHub的链接也实行这里。
comparing the Error plot for Sklearn SGD and Self Implemented SGD
比较Sklearn SGD和自实施SGD的误差图
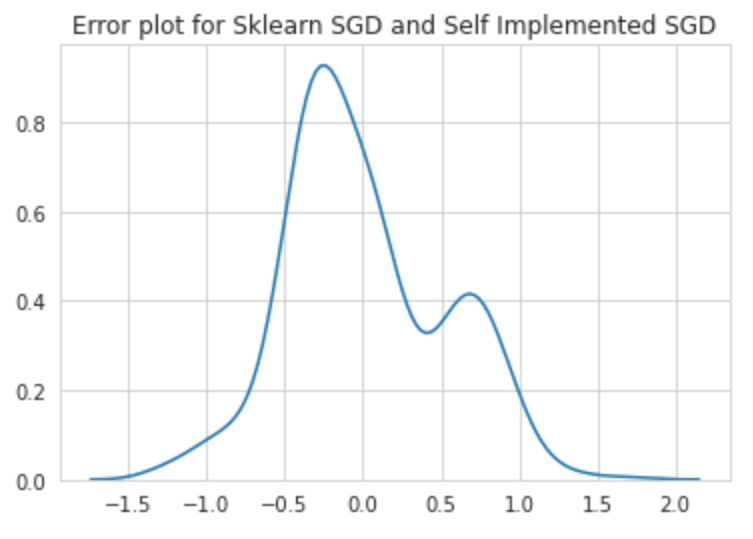
结论(Conclusion)

As from the above, we can see that mean of the differences in the prediction of the two models is at 0 As we can see above intercept and weight(coef) is almost same for sklearn SGD and self-implemented SGD.
从上面我们可以看到,两个模型的预测差异的均值为0。正如我们可以看到,对于sklearn SGD和自实现SGD,截距和权重(coef)几乎相同。
To understand the full code please visit my GitHub link.
要了解完整的代码,请访问我的GitHub链接。
I also Implemented Gradient descent using different Data sets to understand the full code please visit my GitHub link.
我还使用不同的数据集实现了梯度下降以了解完整代码,请访问我的GitHub链接。
To Know detailed information Linear Regression please visit my previous blog link here.
要了解线性回归的详细信息,请访问我以前的博客链接 这里。
翻译自: https://medium.com/analytics-vidhya/solving-for-optimization-problems-fee1e7ee5d22
遗传算法解决函数优化问题














 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









