





python joblib
Make your Python work faster!
使您的Python工作更快!

动机: (Motivation:)
With the addition of multiple pre-processing steps and computationally intensive pipelines, it becomes necessary at some point to make the flow efficient. This can be achieved either by removing some of the redundant steps or getting more cores/CPUs/GPUs to make it faster. Often times, we focus on getting the final outcome regardless of the efficiency. We rarely put in the efforts to optimize the pipelines or do improvements until we run out of memory or out computer hangs. And eventually, we feel like…
通过增加多个预处理步骤和大量计算管线,有必要在某些时候使流程高效。 这可以通过删除一些冗余步骤或增加内核/ CPU / GPU来使其更快来实现。 通常,无论效率如何,我们都专注于获得最终结果。 在内存不足或计算机挂起之前,我们很少努力优化管道或进行改进。 最终,我们觉得……
Fortunately, there is already a framework known as joblib that provides a set of tools for making the pipeline lightweight to a great extent in Python.
幸运的是,已经有了一个称为joblib的框架,该框架提供了一套工具,可以在很大程度上简化Python管道的工作。
为什么选择joblib? (Why joblib?)
There are several reasons to integrate joblib tools as a part of the ML pipeline. There are major two reasons mentioned on their website to use it. However, I thought to rephrase it again:
将Joblib工具集成为ML管道的一部分有多个原因。 他们的网站上提到使用它的主要原因有两个。 但是,我想再次改写一下:
- Capability to use cache which avoids recomputation of some of the steps 使用缓存的能力,避免重新计算某些步骤
- Execute Parallelization to fully utilize all the cores of CPU/GPU.执行并行化以充分利用CPU / GPU的所有核心。
Beyond this, there are several other reasons why I would recommend joblib:
除此之外,还有其他一些为什么我推荐joblib的原因:
- Can be easily integrated 可以轻松整合
- No specific dependencies没有特定的依赖
- Saves cost and time节省成本和时间
- Easy to learn简单易学
There are other functionalities that are also resourceful and help greatly if included in daily work.
如果日常工作中包含其他功能,它们也很实用,可以提供很大帮助。
1.使用缓存的结果 (1. Using Cached results)
It often happens, that we need to re-run our pipelines multiple times while testing or creating the model. Some of the functions might be called several times, with the same input data and the computation happens again. Joblib provides a better way to avoid recomputing the same function repetitively saving a lot of time and computational cost. For example, let's take a simple example below:
这经常发生,我们需要在测试或创建模型时多次重新运行管道。 使用相同的输入数据可能会多次调用某些功能,并且计算会再次发生。 Joblib提供了一种更好的避免重复计算相同函数的方法,从而节省了大量时间和计算成本。 例如,让我们在下面举一个简单的例子:

As seen above, the function is simply computing the square of a number over a range provided. It takes ~20 s to get the result. Now, let's use joblib’s Memory function with a location defined to store a cache as below:
如上所示,该函数只是在提供的范围内计算一个数字的平方。 大约需要20秒才能得到结果。 现在,让我们将Joblib的Memory函数与定义为存储缓存的位置一起使用,如下所示:

On computing the first time, the result is pretty much the same as before of ~20 s, because the results are computing the first time and then getting stored to a location. Let's try running one more time:
第一次计算时,结果与〜20 s之前的结果几乎相同,因为结果是第一次计算,然后存储到某个位置。 让我们尝试再运行一次:

And VOILA! It took 0.01 s to provide the results. The time reduced almost by 2000x. This is mainly because the results were already computed and stored in a cache on the computer. The efficiency rate will not be the same for all the functions! It might vary majorly for the type of computation requested. But you will definitely have this superpower to expedite the pipeline by caching!
和VOILA! 提供结果花费了0.01 s。 时间减少了近2000倍。 这主要是因为结果已经被计算并存储在计算机的缓存中。 并非所有功能的效率都相同! 对于所请求的计算类型,它可能会有很大不同。 但是,您绝对具有通过缓存来加速管线的超级能力!
To clear the cache results, it is possible using a direct command:
要清除缓存结果,可以使用直接命令:
Be careful though, before using this code. You might wipe out your work worth weeks of computation.
但是,在使用此代码之前要小心。 您可能需要花费数周的时间才能完成工作。
2.并行化 (2. Parallelization)
As the name suggests, we can compute in parallel any specified function with even multiple arguments using “joblib.Parallel”. Behind the scenes, when using multiple jobs (if specified), each calculation does not wait for the previous one to complete and can use different processors to get the task done. For better understanding, I have shown how Parallel jobs can be run inside caching.
顾名思义,我们可以使用“ joblib.Parallel”并行计算甚至具有多个参数的任何指定函数。 在后台,当使用多个作业(如果指定)时,每个计算都不会等待上一个计算完成,而是可以使用不同的处理器来完成任务。 为了更好地理解,我展示了如何在缓存中运行并行作业。
Consider the following random dataset generated:
考虑以下生成的随机数据集:
Below is a run with our normal sequential processing, where a new calculation starts only after the previous calculation is completed.
以下是我们正常顺序处理的运行,其中新的计算仅在先前的计算完成后才开始。

For parallel processing, we set the number of jobs = 2. The number of jobs is limit to the number of cores the CPU has or are available (idle).
对于并行处理,我们将作业数设置为2。作业数限制为CPU具有或可用的内核数(空闲)。

Here we can see that time for processing using the Parallel method was reduced by 2x.
在这里我们可以看到使用Parallel方法处理的时间减少了2倍。
Note: using this method may show deteriorated performance if used for less computational intensive functions.
注意:如果将这种方法用于较少的计算密集型函数,则性能可能会下降。
3.转储和加载 (3. Dump and Load)
We often need to store and load the datasets, models, computed results, etc. to and from a location on the computer. Joblib provides functions that can be used to dump and load easily:
我们经常需要将数据集,模型,计算结果等存储到计算机上的某个位置并从中加载。 Joblib提供可轻松转储和加载的功能:
4.压缩方式(4. Compression methods)
When dealing with larger datasets the size occupied by these files is massive. With feature engineering, the file size gets even larger as we add more columns. Fortunately, nowadays, with the storages getting so cheap, it is less of an issue. However, still, to be efficient there are some compression methods that joblib provides are very simple to use:
当处理较大的数据集时,这些文件占用的空间很大。 通过功能工程,随着我们添加更多列,文件大小将变得更大。 幸运的是,如今,随着存储变得如此便宜,这已不再是一个问题。 但是,为了提高效率, joblib提供了一些非常简单的压缩方法:
a. Simple Compression:
一种。 简单压缩:
The very simple is the one shown above. It does not provide any compression but is the fastest method to store any files
上面显示的非常简单。 它不提供任何压缩,但是是存储任何文件的最快方法


b. Using Zlib compression:
b。 使用Zlib压缩:
This is a good compression method at level 3, implemented as below:
这是第3级的一种很好的压缩方法,实现如下:


c. Using lz4 compression:
C。 使用lz4压缩:
This is another great compression method and is known to be one of the fastest available compression methods but the compression rate slightly lower than Zlib. Personally I find this to be the best method, as it is a great trade-off between compression size and compression rate. Below is the method to implement it:
这是另一种出色的压缩方法,已知是可用的最快压缩方法之一,但是压缩率略低于Zlib。 我个人认为这是最好的方法,因为这是压缩大小和压缩率之间的巨大折衷。 下面是实现它的方法:


Putting everything in one table it looks like below:
将所有内容放在一个表中,如下所示:
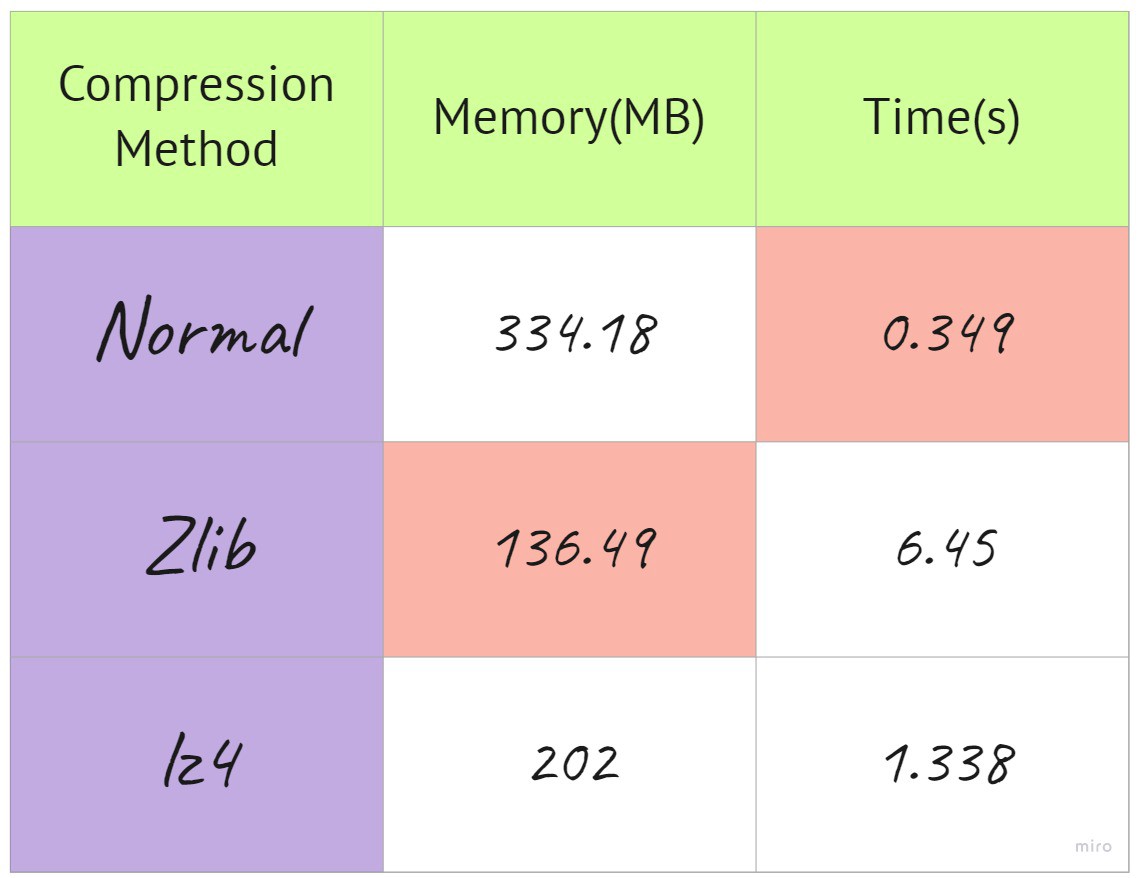
结束语:(Concluding Remarks:)
I find joblib to be a really useful library. I have started integrating them into a lot of my Machine Learning Pipelines and definitely seeing a lot of improvements.
我发现joblib是一个非常有用的库。 我已经开始将它们集成到我的许多机器学习管道中,并且肯定会看到很多改进。
Thank you for taking out time to read the article. Any comments/feedback are always appreciated!
感谢您抽出宝贵的时间阅读本文。 任何意见/反馈总是很感激!
翻译自: https://towardsdatascience.com/using-joblib-to-speed-up-your-python-pipelines-dd97440c653d
python joblib















 2019
2019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









