






 本文探讨了最大似然(ML)方法与残差最大似然(REML)方法之间的区别,这两种方法常用于估计混合模型的参数。REML在处理存在随机效应的模型时能提供更公正的估计,因为它消除了固定效应的尺度不确定性。文章来源于数据科学领域的深度解析。
本文探讨了最大似然(ML)方法与残差最大似然(REML)方法之间的区别,这两种方法常用于估计混合模型的参数。REML在处理存在随机效应的模型时能提供更公正的估计,因为它消除了固定效应的尺度不确定性。文章来源于数据科学领域的深度解析。
reml
生命科学的数学统计和机器学习 (Mathematical Statistics and Machine Learning for Life Sciences)
This is the nineteenth article from the column Mathematical Statistics and Machine Learning for Life Sciences where I try to explain some mysterious analytical techniques used in Bioinformatics and Computational Biology in a simple way. This is the final article in the series dedicated to the Linear Mixed Model (LMM). Previously we talked about How Linear Mixed Model Works, how to derive and program Linear Mixed Model from Scratch in R from the Maximum Likelihood (ML) principle. Today we will discuss the concept of Restricted Maximum Likelihood (REML), why it is useful and how to apply it to the Linear Mixed Models.
这是生命科学的数学统计和机器学习专栏的第十九篇文章,我试图以一种简单的方式来解释生物信息学和计算生物学中使用的一些神秘的分析技术。 这是致力于线性混合模型(LMM)的系列文章中的最后一篇。 先前我们讨论了线性混合模型的工作原理,如何从头开始导出和编程线性混合模型。 R来自最大似然(ML)原理。 今天,我们将讨论限制最大似然(REML)的概念,为何有用以及如何将其应用于线性混合模型。
通过最大似然估计的偏差方差估算器 (Biased Variance Estimator by Maximum Likelihood)
The idea of Restricted Maximum Likelihood (REML) comes from realization that the variance estimator given by the Maximum Likelihood (ML) is biased. What is an estimator and in which way it is biased? An estimator is simply an approximation / estimate of model parameters. Assuming that statistical observations follow Normal distribution, there are two parameters: μ (mean) and σ² (variance) to estimate if one wants to summarize the observations. It turns out that the variance estimator given by Maximum Likelihood (ML) is biased, i.e. the value we obtain from the ML model over- or under-estimates the true variance, see the figure below.
限制最大似然( REML )的思想来自于认识到最大似然(ML)给出的方差估计量是有偏差的。 什么是估计量,以哪种方式产生偏差? 估计器只是模型参数的近似/估计。 假设的统计观察遵循正态分布,有两个参数:μ(平均值)和σ²(方差)如果一个人想总结的意见来估计。 事实证明,最大似然(ML)给出的方差估计量是有偏差的 ,即我们从ML模型获得的值高估或低估 了真实方差 ,请参见下图。
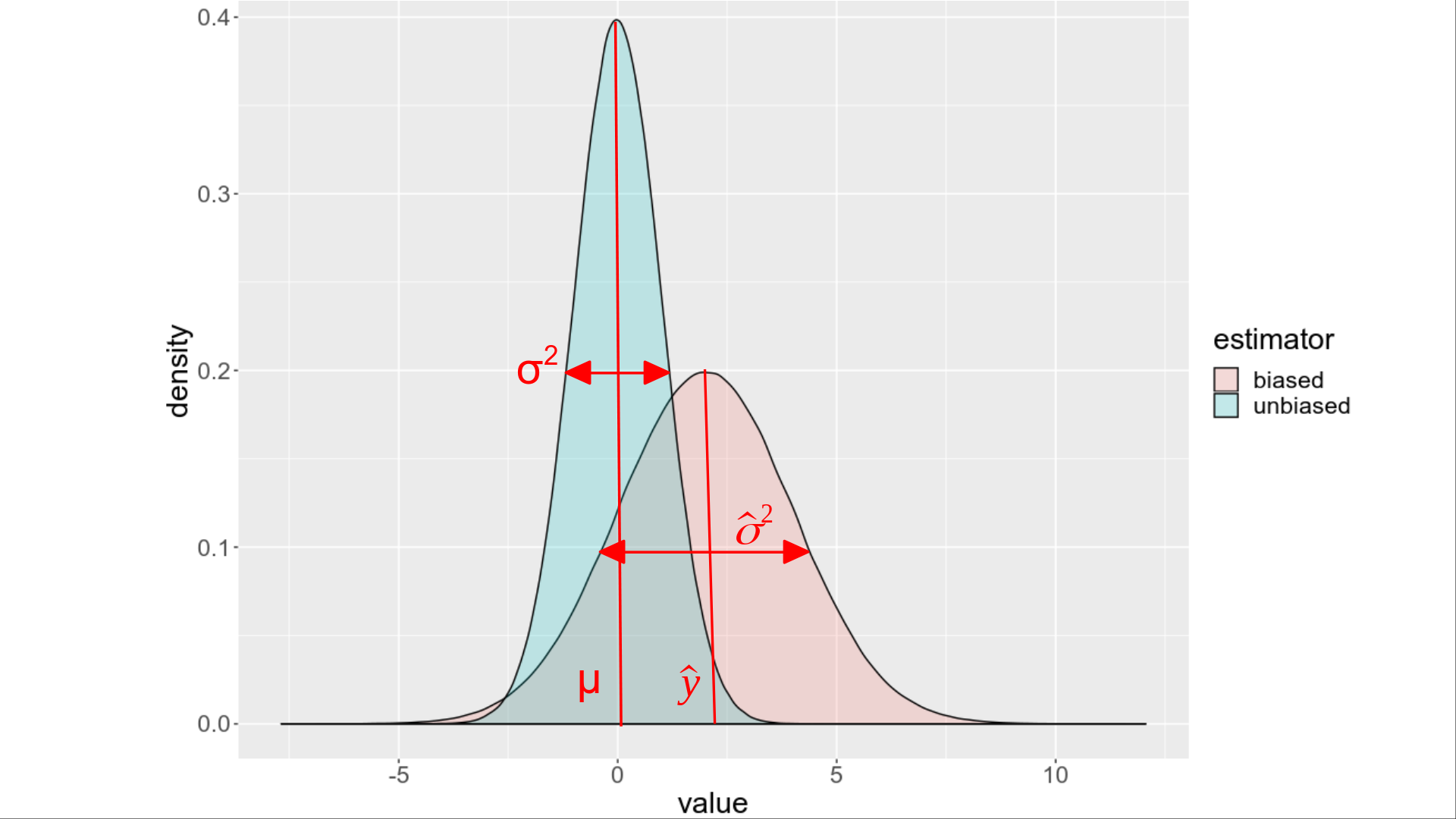
In practice, when we e.g. solve a Linear Regression model using ML, we rarely think about the bias in the variance estimator, since we are usually interested in the coefficients of the linear model, which is the mean, and often do not even realize that in parallel we estimate one more fitting parameter, which is the variance. In this case the variance is considered to be a so-called nuisance parameter that is not of our primary interest.
在实践中,当我们使用ML求解线性回归模型时,我们很少考虑方差估计量中的偏差,因为我们通常对线性模型的系数感兴趣,该系数是 均值 ,甚至常常没有意识到并行地,我们估计另一个拟合参数,即方差。 在这种情况下,方差被认为是所谓的讨厌参数 那不是我们的主要利益。
To demonstrate that ML indeed gives a biased variance estimator, consider a simple one-dimensional case with a variable y = (y1,y2,…,yN) following e.g. the Normal distribution.
为了证明ML确实给出了偏差方差估计量,请考虑一个简单的一维情况,其变量y =( y 1, y 2,…, yN ),例如正态分布。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









