






昨天发过一篇文章,趁儿子午睡写的,当读数时间短了几十上百倍之后有点得意早了,实际上可以继续利用
data.table和dtplyr继续最大化的缩短代码运行时间,前因后果参考:
一个处理大量 EM50 数据的示例 (dtplyr版本)
主要改进有以下几点:
尽可能的最大化
data.table来处理数据,大家都知道它最大的优势是纯 C 写的,速度快。复杂的转换尽可能使用
dtplyr,减少操作难度,又兼顾了时间上的考虑。不知什么原因,
dtplyr在我这里对data.table的支持不是很足,我没找到原因的代码报错,所以最后一步又使用了部分data.table的代码。
下面内容,关键步骤都有注释,供大家参考。
先加载需要多次的包:
1library(data.table)
2library(dtplyr)
3library(dplyr, warn.conflicts = FALSE)
4library(stringr)
5library(tidyr)
6library(lubridate)
然后是最重要的部分:
1# 将序列号写到一个csv 文件内读取
2sn "./data/EM50_SN.csv")
3
4#部分数采的通道没有全部使用,为方便后续数据的处理
5#暂时将深度1000分配各这些通道,方便数据处理,
6#因为尽管无传感器,数采仍然输出了无效的数值。
7#并非一定是 1000,只要没有该深度的数据即可,比如8888
8
9depth_47373 10, 80, 1000, 140, 150)
10depth_26387 155, 165, 10, 80, 130)
11
12# 将表头改一下名字,不用port12345,方便后面处理
13name_47373 14 paste0(c("moist_", "temp_"), rep(depth_47373, each = 2))
15name_26387 16 paste0(c("moist_", "temp_"), rep(depth_26387, each = 2))
17
18# directory and pattern for list.files ------------------------------------
19data_dir "./csvdata/")
20file_pattern "*")
21file_pattern "EM\\*")
22file_dir 23file_dir "\\*\\/$")
24
25# fread 缩短读数的时间 ------------------------------------
26# 将所有文档名和路径都读入list
27all_files 28 purrr::map2(file_dir, file_pattern, list.files, full.names = TRUE)
29
30# 读取第一个list,按序列号顺序排列
31list_files 32 lapply(all_files[[1]],
33 fread,
34 skip = 3,
35 col.names = c("time", name_26387))
36# 按行将list转换为 data.table
37dt_26387 38
39# 将日期转化为日期格式
40dt_26387[, time := as.POSIXct(time)]
41
42
43# 将数据按湿度和温度整理成列 -----------------------------------------------------------
44dt_26387[, time := as.POSIXct(time)]
45dt_26387 46 dt_26387,
47 measure.vars = name_26387,
48 variable.name = "depth",
49 value.name = "val"
50)
51# 将高度与前面表示的温度和湿度拆分开
52dt_26387[, c("measure_item", "depth_val") :=
53 tstrsplit(depth, "_", fixed = TRUE)]
54
55# 按 moist 和 temp 将数据分开为 list
56dt_26387_split 57 split(dt_26387, f = as.factor(dt_26387$measure_item))
58# 再把 list 拼起来,按列
59dt_26387_split 60
61# 把数据名字改正常了,好记,选择需要的列,其他扔掉
62dt_26387_merge 63 dt_26387_split[, `:=`(moisture = val , temprature = val1)]
64dt_26387_merge 65 dt_26387_merge[, .(time, moisture, temprature), keyby = depth_val]
66
67# 转换为 lazy_dt,开始 dtplyr
68lazy_26387 69lazy_26387 %
70 rename(depth = depth_val) %>%
71 # 按照15 min 的间隔划分数据,并整理
72 # 同时不要忘记分按剖面来处理
73 mutate(sep_15 = floor_date(time, "15 mins")) %>%
74 group_by(depth, sep_15) %>%
75 summarise(
76 moisture = mean(moisture, na.rm = TRUE),
77 temp = mean(temprature, na.rm = TRUE)
78 ) %>%
79 as.data.table()
80
81# 不能使用 separate 继续转换 sep_15,不知原因
82# separate error:no applicable method for 'separate_' applied
83# to an object of class "c('dtplyr_step_group', 'dtplyr_step')"
84# 使用 data.table 继续
85# 把时间日期拆开了
86lazy_26387[, c("date", "time") :=
87 tstrsplit(sep_15, " ", fixed = TRUE)]
88lazy_26387[, c("year", "month", "day") :=
89 tstrsplit(date, "-", fixed = TRUE)]
90lazy_26387[, c("hour", "minuts", "sec") :=
91 tstrsplit(time, ":", fixed = TRUE)]
92
93# 扔掉不需要的数据
94lazy_26387[, `:=`(
95 sep_15 = NULL,
96 sec = NULL,
97 date = NULL,
98 time = NULL
99)]
100
101# 整理另一个序列号 -----------------------------------------------------------
102# 只需要将前面的代码改换序列号即可
103
104list_files 105 lapply(all_files[[2]],
106 fread,
107 skip = 3,
108 col.names = c("time", name_47373))
109# 按行将list转换为 data.table
110dt_47373 111
112# 将日期转化为日期格式
113dt_47373[, time := as.POSIXct(time)]
114
115
116# 将数据按湿度和温度整理成列 -----------------------------------------------------------
117dt_47373[, time := as.POSIXct(time)]
118dt_47373 119 dt_47373,
120 measure.vars = name_47373,
121 variable.name = "depth",
122 value.name = "val"
123)
124# 将高度与前面表示的温度和湿度拆分开
125dt_47373[, c("measure_item", "depth_val") :=
126 tstrsplit(depth, "_", fixed = TRUE)]
127
128# 按 moist 和 temp 将数据分开为 list
129dt_47373_split 130 split(dt_47373, f = as.factor(dt_47373$measure_item))
131# 再把 list 拼起来,按列
132dt_47373_split 133
134# 把数据名字改正常了,好记,选择需要的列,其他扔掉
135dt_47373_merge 136 dt_47373_split[, `:=`(moisture = val , temprature = val1)]
137dt_47373_merge 138 dt_47373_merge[, .(time, moisture, temprature), keyby = depth_val]
139
140# 转换为 lazy_dt,开始 dtplyr
141lazy_47373 142lazy_47373 %
143 rename(depth = depth_val) %>%
144 # 按照15 min 的间隔划分数据,并整理
145 # 同时不要忘记分按剖面来处理
146 mutate(sep_15 = floor_date(time, "15 mins")) %>%
147 group_by(depth, sep_15) %>%
148 summarise(
149 moisture = mean(moisture, na.rm = TRUE),
150 temp = mean(temprature, na.rm = TRUE)
151 ) %>%
152 as.data.table()
153
154# 不能使用 separate 继续转换 sep_15,不知原因
155# separate error:no applicable method for 'separate_' applied
156# to an object of class "c('dtplyr_step_group', 'dtplyr_step')"
157# 使用 data.table 继续
158# 把时间日期拆开了
159lazy_47373[, c("date", "time") :=
160 tstrsplit(sep_15, " ", fixed = TRUE)]
161lazy_47373[, c("year", "month", "day") :=
162 tstrsplit(date, "-", fixed = TRUE)]
163lazy_47373[, c("hour", "minuts", "sec") :=
164 tstrsplit(time, ":", fixed = TRUE)]
165
166# 扔掉不需要的数据
167lazy_47373[, `:=`(
168 sep_15 = NULL,
169 sec = NULL,
170 date = NULL,
171 time = NULL
172)]
结果如下:
1#最终处理好的数据,已经按 15 min 来进行整理了:
2knitr::kable(head(lazy_26387))
3knitr::kable(head(lazy_47373))
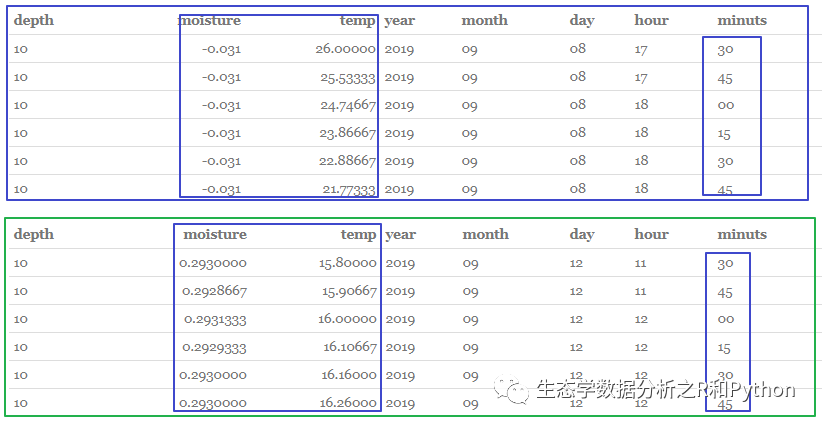
最终将数据导出:
1#最终导出 csv。
2fwrite(lazy_47373, "./final-data/ave26387.csv")
3fwrite(lazy_47373, "./final-data/ave47373.csv")
















 54
54











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









