






其实了解MapReduce的人应该都会知道,只要我们做MapReduce相关开发就会去编写MR相应的程序,就连简单的计数也要做MR编程,非常的“白痴”,不切实际,以致不好利用数据做分析。
根据上述的问题,Hive它提供了很好地解决方案,它只需提供一条简单的sql语句count就能完成数据的计数,不必在浪费时间去写简单而无聊的编程。
Hive是基于Hadoop的一个数据仓库工具,可以将我们结构化的数据文件映射为一张数据库表,并且提供简单的sql查询功能,可以将sql语句转换为MR任务进行运行。 其优点是学习成本低,可以通过SQL语句快速实现简单的MapReduce统计,所以不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
我们可以看下图,来直接了解hive与hadoop的关系

我们可以看下图,发现hive与传统数据之间的区别
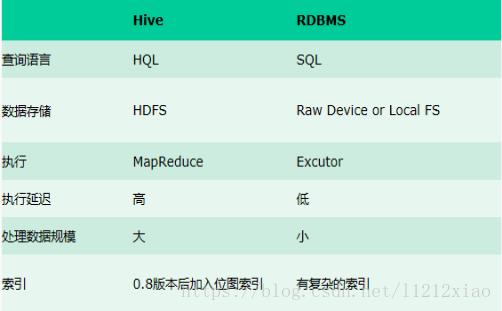
既然hive能够更好的取代hadoop做数据分析,那它与hadoop的区别
一、 直接使用hadoop所面临的问题
1、他人学习成本太高
2、项目周期要求的太短
3、MapReduce实现复杂查询逻辑开发难度太大
二、使用hive的好吃
1、采用类SQL语法,提供快速开发的能力。
2、并避免了去写MapReduce,可以减少开发人员的学习成本。
3、扩展功能非常地方便。
Hive的安装与部署
Hive根据元数据的存储位置有两种模式:
1、本机模式:使用hive自带的derby来存储元数据。
2、远程模式:使用远程的mysql数据表来存储元数据。
我们都是使用第二种模式来进行hive的搭建。所以一开始我们得需要安装一个mysql,然后再进行hive搭建。
yum install -y mysql-server
service mysqld start
chkconfig mysqld on
chkconfig mysqld --list 2:on
以上是mysql的安装
接着在进入hive-site.xml配置文件中修改,如下(ip地址记得改下哦):
javax.jdo.option.ConnectionUserName用户名(这4是新添加的,记住删除配置文件原有的!)
root
javax.jdo.option.ConnectionPassword密码
123456
javax.jdo.option.ConnectionURLmysql
jdbc:mysql://192.168.1.68:3306/hive
javax.jdo.option.ConnectionDriverNamemysql驱动程序
com.mysql.jdbc.Driver
以上代码插入到一下代码的上面
hive.exec.script.wrapper
接着将复制mysql的驱动程序到hive/lib下面,完成后在mysql中hive的schema(在此之前需要创建mysql下的hive数据库)。这样hive的安装与配置就这样OK了,最后我们直接敲hive来进入hive吧!
Hive的用法
Hive的用法其实是在sql语言上在进行扩展的,如果你熟悉sql语言,自然而然你进入hive学习也会非常的快。以下举了两个主题,想要精学的人可以登陆hive官网
https://cwiki.apache.org/confluence/display/Hive/LanguageManual
Hive的数据存储
1、Hive中的数据都是存储在 HDFS 中的,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、我们需在创建表的时候考虑 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含数据模型:DB、Table,External Table,Partition,Bucket。
db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在hdfs中表现所属db目录下一个文件夹
external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径
普通表: 删除表后, hdfs上的文件都删了
外部表删除后, hdfs上的文件没有删除, 只是把文件删除了
partition:在hdfs中表现为table目录下的子目录
bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根 据不同的文件把数据放到不同的文件中
hive创建数据库操作
hive提供database的定义,database的主要作用是提供数据分割的作用,方便数据关闭, 命令如下所示:
#创建:
create (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES] (property_name=value,name=value...)
#显示描述信息:
describe DATABASE|SCHEMA [extended] database_name。
#删除:
DROP DATABASE|SHCEMA [IF EXISTS] database_Name [RESTRICT|CASCADE]
#使用:
user database_name;
Hive的优化
1. 大数据场景下不害怕数据量大,害怕的是数据倾斜,怎样避免数据倾斜,找到可能产生数据倾斜的函数尤为关键,数据量较大的情况下,慎用count(distinct),count(distinct)容易产生倾斜问题。
2. 设置合理的map reduce 的task数量
map阶段优化
a) 假设有一个文件a,它的大小为780M,那么hadoop会将该文件a分隔成7个块(6个128m的块和1个12m的块),从而产生7个map数
b) 假设某目录下有3个文件a,b,c,大小分别为10m,20m,130m,那么hadoop会分隔成4个块(10m,20m,128m,2m),从而产生4个map数
即如果文件大于块大小(128m),那么会拆分,如果小于块大小,则把该文件当成一个块。
其实这就涉及到小文件的问题:如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,
而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。
而且,同时可执行的map数是受限的。那么问题又来了。。是不是保证每个map处理接近128m的文件块,就高枕无忧了?
答案也是不一定。比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,
如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。
reduce阶段优化
Hive自己如何确定reduce数:
reduce个数的设定极大影响任务执行效率,不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下两个设定:
hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,默认为1000^3=1G)
hive.exec.reducers.max(每个任务最大的reduce数,默认为999)
计算reducer数的公式很简单N=min(参数2,总输入数据量/参数1)
即,如果reduce的输入(map的输出)总大小不超过1G,那么只会有一个reduce任务;
什么情况下只有一个reduce;
很多时候你会发现任务中不管数据量多大,不管你有没有设置调整reduce个数的参数,任务中一直都只有一个reduce任务;
其实只有一个reduce任务的情况,除了数据量小于hive.exec.reducers.bytes.per.reducer参数值的情况外,还有以下原因:
没有group by的汇总,比如把select pt,count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04’ group by pt;
写成 select count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04’;
这点非常常见,希望大家尽量改写。
用了Order by
有笛卡尔积
通常这些情况下,除了找办法来变通和避免,我暂时没有什么好的办法,因为这些操作都是全局的,所以hadoop不得不用一个reduce去完成;
同样的,在设置reduce个数的时候也需要考虑这两个原则:使大数据量利用合适的reduce数;使单个reduce任务处理合适的数据量。














 2690
2690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









