



 本文深入探讨了Python中Mask的实用概念,特别是在数据科学项目中处理不必要的、缺失的或无效数据时。通过一维和二维数组的例子,展示了如何使用Mask来过滤特定条件下的数据,以及在数据科学问题中应用Mask来突出相关性矩阵中的关键值。
本文深入探讨了Python中Mask的实用概念,特别是在数据科学项目中处理不必要的、缺失的或无效数据时。通过一维和二维数组的例子,展示了如何使用Mask来过滤特定条件下的数据,以及在数据科学问题中应用Mask来突出相关性矩阵中的关键值。
binary masks
All men are sculptors, constantly chipping away the unwanted parts of their lives, trying to create their idea of a masterpiece … Eddie Murphy
所有的人都是雕塑家,不断地消除生活中不必要的部分,试图建立自己的杰作理念……埃迪·墨菲(Eddie Murphy)
If you ever wonder how to filter or handle unwanted, missing, or invalid data in your data science projects or, in general, Python programming, then you must learn the helpful concept of Masking. In this post, I will first guide you through an example for 1-d arrays, followed by 2-d arrays (matrices), and then provide an application of Masking in a Data Science Problem.
如果您想知道如何过滤或处理数据科学项目或通常是Python编程中不需要的,丢失的或无效的数据,那么您必须学习Masking的有用概念。 在本文中,我将首先为您介绍一个1-d数组的示例,然后是一个2-d数组(矩阵)的示例,然后提供在数据科学问题中屏蔽的应用 。
一维阵列 (1-d Arrays)
Suppose we have the following NumPy array:
假设我们有以下NumPy数组:
import numpy as nparr = np.array([1, 2, 3, 4, 5, 6, 7, 8])Now, we want to compute the sum of elements smaller than 4 and larger than 6. One tedious way is to use a for loop, check if a number fulfills these conditions, and then add it to a variable. This would look something like:
现在,我们要计算小于4和大于6的元素之和。一种乏味的方法是使用for循环,检查数字是否满足这些条件,然后将其添加到变量中。 这看起来像:
total = 0 # Variable to store the sumfor num in arr:
if (num<4) or (num>6):
total += numprint(total)
>>> 21You can reduce this code to a one-liner using a list comprehension as,
您可以使用列表推导将代码简化为单行代码,如下所示:
total = sum([num for num in arr if (num<4) or (num>6)])
>>> 21The same task can be achieved using the concept of Masking. It essentially works with a list of Booleans (True/False), which when applied to the original array returns the elements of interest. Here, True refers to the elements that satisfy the condition (smaller than 4 and larger than 6 in our case), and False refers to the elements that do not satisfy the condition.
使用Masking的概念可以实现相同的任务。 本质上,它与布尔值列表(True / False)一起使用 ,将其应用于原始数组时会返回感兴趣的元素。 在这里, True表示满足条件的元素(在我们的例子中,小于4且大于6),而False表示不满足条件的元素。
Let us first create this mask manually.
让我们首先手动创建此蒙版。
mask = [True, True, True, False, False, False, True, True]Next, we pass this mask (list of Booleans) to our array using indexing. This will return only the elements that satisfy this condition. You can then sum up this sub-array. The following snippet explains it. You will notice that you do not get back 4, 5, and 6 because the corresponding value was False.
接下来,我们使用索引将此掩码(布尔值列表)传递给我们的数组。 这将仅返回满足此条件 的元素 。 然后,您可以总结此子数组。 以下代码段对此进行了说明。 您会注意到,由于相应的值为False ,所以您没有取回4、5和6。
arr[mask]
>>> array([1, 2, 3, 7, 8])arr[mask].sum()
>>> 21Numpy的MaskedArray模块 (Numpy’s MaskedArray Module)
Numpy offers an in-built MaskedArray module called ma. The masked_array() function of this module allows you to directly create a "masked array" in which the elements not fulfilling the condition will be rendered/labeled "invalid". This is achieved using the mask argument, which contains True/False or values 0/1.
Numpy提供了一个名为ma 的内置MaskedArray模块 。 该模块的masked_array()函数使您可以直接创建一个“ masked array”,在其中将不满足条件的元素呈现/标记为“ invalid” 。 这可以使用mask参数实现,该参数包含True / False或值0/1。
Caution: Now, when the mask=False or mask=0, it literally means do not label this value as invalid. Simply put, include it during the computation. Similarly, mask=True or mask=1 means label this value as invalid. By contrast, earlier you saw that False value was excluded when we used indexing.
注意 :现在,当mask=False或mask=0 ,字面意思是不要将此值标记为无效。 简而言之,在计算时将其包括在内 。 同样, mask=True或mask=1表示将此值标记为 无效。 相比之下,您先前发现使用索引时排除了False值。
Therefore, you have to now swap the True and False values while using thema module. So, the new mask becomes
因此,您现在必须在使用 ma 模块 时交换True和False值 。 所以,新的面具变成
mask = [False, False, False, True, True, True, False, False]
mask = [False, False, False, True, True, True, False, False]
import numpy.ma as ma"""First create a normal Numpy array"""
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])ma_arr = ma.masked_array(arr, mask=[False, False, False, True,
True, True, False, False])
>>> masked_array(data=[1, 2, 3, --, --, --, 7, 8],
mask=[False, False, False, True, True, True, False,
False], fill_value=999999)
ma_arr.sum()
>>> 21The masked (invalid) values are now represented by --. The shape/size of the resulting masked_array is the same as the original array. Previously, when we used arr[mask], the resulting array was not of the same length as the original array because the invalid elements were not in the output. This feature allows easy arithmetic operations on arrays of equal length but with different maskings.
掩码的(无效)值现在由--表示。 生成的masked_array的形状/大小与原始数组相同 。 以前,当我们使用arr[mask] ,结果数组与原始数组的长度不同,因为无效元素不在输出中。 此功能允许对长度相等但具有不同掩码的数组进行简单的算术运算。
Like before, you can also create the mask using list comprehension. However, because you want to swap the True and False values, you can use the tilde operator ~ to reverse the Booleans.
和以前一样,您也可以使用列表推导来创建掩码。 但是,由于要交换True和False值,因此可以使用波浪号~来反转布尔值。
"""Using Tilde operator to reverse the Boolean"""
ma_arr = ma.masked_array(arr, mask=[~((a<4) or (a>6)) for a in arr])ma_arr.sum()
>>> 21You can also use a mask consisting of 0 and 1.
您还可以使用由0和1组成的掩码。
ma_arr = ma.masked_array(arr, mask=[0, 0, 0, 1, 1, 1, 0, 0])Depending on the type of masking condition, NumPy offers several other in-built masks that avoid your manual task of specifying the Boolean mask. Few such conditions are:
根据屏蔽条件的类型,NumPy提供了其他几种内置屏蔽,从而避免了您手动指定布尔屏蔽的任务。 这些条件很少是:
- less than (or less than equal to) a number 小于(或小于等于)一个数字
- greater than (or greater than equal to) a number 大于(或大于等于)数字
- within a given range 在给定范围内
- outside a given range 超出给定范围
小于(或小于等于)数字 (Less than (or less than equal to) a number)
The function masked_less() will mask/filter the values less than a number.
函数masked_less()将屏蔽/过滤小于数字的值。
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])ma_arr = ma.masked_less(arr, 4)
>>> masked_array(data=[--, --, --, 4, 5, 6, 7, 8],
mask=[True, True, True, False, False, False,
False, False], fill_value=999999)ma_arr.sum()
>>> 30To filter the values less than or equal to a number, use masked_less_equal().
要过滤小于或等于数字的值,请使用masked_less_equal() 。
大于(或大于等于)数字 (Greater than (or greater than equal to) a number)
We use the function masked_greater() to filter the values greater than 4.
我们使用函数masked_greater()过滤大于 4的值。
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])ma_arr = ma.masked_greater(arr, 4)>>> masked_array(data=[1, 2, 3, 4, --, --, --, --],
mask=[False, False, False, False, True, True,
True, True], fill_value=999999)ma_arr.sum()
>>> 10Likewise, masked_greater_equal()filters value greater than or equal to 4.
同样, masked_greater_equal()过滤大于或等于 4的值。
在给定范围内 (Within a given range)
The function masked_inside() will mask/filter the values lying between two given numbers (both inclusive). The following filter values between 4 and 6.
函数masked_inside()将屏蔽/过滤两个给定数字(包括两个数字)之间的值。 以下4到6之间的过滤器值。
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])ma_arr = ma.masked_inside(arr, 4, 6)
>>> masked_array(data=[1, 2, 3, --, --, --, 7, 8],
mask=[False, False, False, True, True, True,
False, False], fill_value=999999)ma_arr.sum()
>>> 21超出给定范围 (Outside a given range)
The function masked_inside() will mask/filter the values lying between two given numbers (both inclusive). The following filter values outside 4-6.
函数masked_inside()将屏蔽/过滤两个给定数字(包括两个数字)之间的值。 以下4-6之外的过滤器值。
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])ma_arr = ma.masked_outside(arr, 4, 6)
>>> masked_array(data=[--, --, --, 4, 5, 6, --, --],
mask=[True, True, True, False, False, False,
True, True], fill_value=999999)ma_arr.sum()
>>> 15 在算术运算期间忽略NaN和/或infinite值 (Neglecting NaN and/or infinite values during arithmetic operations)
This is a cool feature! Often a realistic dataset has lots of missing values (NaNs) or some weird, infinity values. Such values create problems in computations and, therefore, are either neglected or imputed.
这是一个很酷的功能! 实际的数据集通常具有许多缺失值(NaN)或一些奇怪的无穷大值。 这样的值在计算中产生问题,因此被忽略或推算。
For example, the sum or the mean of this 1-d NumPy array will benan.
例如,此1-d NumPy数组的总和或平均值将为nan 。
arr = np.array([1, 2, 3, np.nan, 5, 6, np.inf, 8])
arr.sum()
>>> nanYou can easily exclude the NaN and infinite values using masked_invalid() that will exclude these values from the computations. These invalid values will now be represented as --. This feature is extremely useful in dealing with the missing data in large datasets in data science problems.
您可以使用masked_invalid()轻松排除NaN和无限值,该值将从计算中排除这些值。 这些无效值现在将表示为-- 。 此功能对于处理数据科学问题中大型数据集中的丢失数据非常有用 。
ma_arr = ma.masked_invalid(arr)
>>> masked_array(data=[1.0, 2.0, 3.0, --, 5.0, 6.0, --, 8.0],
mask=[False, False, False, True, False, False,
True, False], fill_value=1e+20)ma_arr.mean()
>>> 4.166666666666667Let’s say you want to impute or fill these NaNs or inf values with the mean of the remaining, valid values. You can do this easily using filled() as,
假设您要用剩余的有效值的平均值来估算或填充这些NaN或inf值。 您可以使用filled()轻松地做到这一点,
ma_arr.filled(ma_arr.mean())
>>> [1., 2., 3., 4.16666667, 5., 6., 4.16666667, 8.]遮罩二维数组(矩阵) (Masking 2-d arrays (matrices))
Often your big data is in the form of a large 2-d matrix. Let’s see how you can use masking for matrices. Consider the following 3 x 3 matrix.
通常,您的大数据是以大二维矩阵的形式出现的。 让我们看看如何对矩阵使用掩码。 考虑下面的3 x 3矩阵。
arr = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])Suppose we want to compute the column-wise sum excluding the numbers that are larger than 4. Now, we have to use a 2-d mask. As mentioned earlier, you can also use a 2-d mask of True/False in the following.
假设我们要计算不包括大于4的数字在内的按列求和。 现在,我们必须使用 2-d mask 。 如前所述,您还可以在下面使用True / False的二维遮罩。
ma_arr = ma.masked_array(arr, mask=[[0, 0, 0],
[0, 1, 1],
[1, 1, 1]])>>> masked_array(data=[[1, 2, 3],
[4, --, --],
[--, --, --]],
mask=[[False, False, False],
[False, True, True],
[True, True, True]], fill_value=999999)"""Column-wise sum is computed using the argument
ma_arr.sum(axis=0)>>> masked_array(data=[5, 2, 3], mask=[False, False, False],
fill_value=999999)In the above code, we created a 2-d mask manually using 0 and 1. You can make your life easier by using the same functions as earlier for a 1-d case. Here, you can use masked_greater() to exclude the values greater than 4.
在上面的代码中,我们使用0和1手动创建了二维蒙版。 通过对1-d情况使用与以前相同的功能,可以使生活更轻松。 在这里,您可以使用masked_greater()排除大于4的值。
ma_arr = ma.masked_greater(arr, 4)ma_arr.sum(axis=0)
>>> masked_array(data=[5, 2, 3], mask=[False, False, False],
fill_value=999999)NOTE: You can use all the functions, earlier shown for 1-d, also for 2-d arrays.
注意:可以将所有功能(前面显示的用于1-d)也用于2-d阵列。
在数据科学问题中使用掩蔽 (Use of masking in a data science problem)
A routine task of any data science project is an exploratory data analysis (EDA). One key step in this direction is to visualize the statistical relationship (correlation) between the input features. For example, Pearson’s correlation coefficient provides a measure of linear correlation between two variables.
任何数据科学项目的例行任务都是探索性数据分析(EDA)。 朝这个方向迈出的关键一步是可视化输入要素之间的统计关系(相关性)。 例如,皮尔逊相关系数提供了两个变量之间线性相关的度量。
Let’s consider the Boston Housing Dataset and compute the correlation matrix which results in coefficients ranging between -1 and 1.
让我们考虑波士顿住房数据集并计算相关矩阵,得出系数在-1和1之间。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_bostonboston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)Let’s now plot the correlation matrix using the Seaborn library.
现在让我们使用Seaborn库绘制相关矩阵。
correlation = df.corr()ax = sns.heatmap(data=correlation, cmap='coolwarm',
linewidths=2, cbar=True)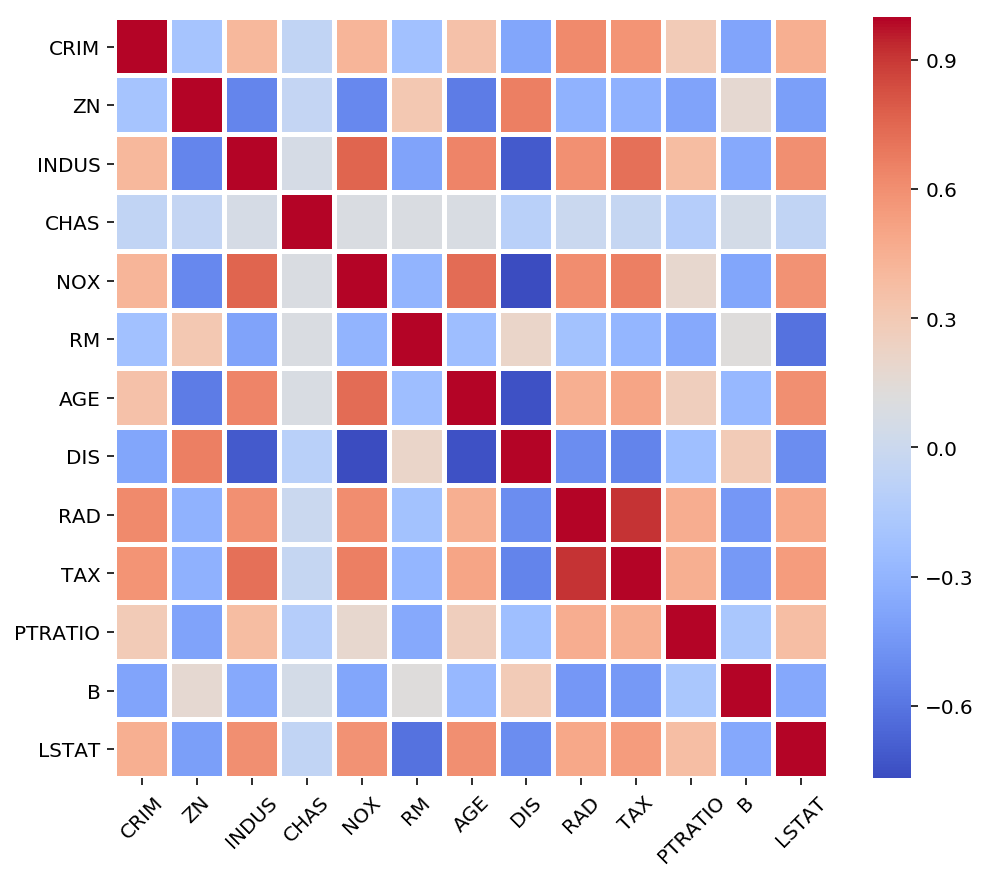
Now, suppose you want to highlight or easily distinguish the values which are having an absolute correlation of over 70%, i.e. 0.7. The above-introduced concepts of Masking come into play here. You can use the masked_outside() function, explained earlier, to mask your required values and highlight them using a special color in your Seaborn plot.
现在,假设您要突出显示或轻松区分绝对相关度超过70%(即0.7)的值 。 上面介绍的“掩蔽”概念在这里起作用。 您可以使用前面解释过的masked_outside()函数来掩盖所需的值,并在Seaborn图中使用特殊颜色突出显示它们。
correlation = df.corr()"""Create a mask for abs(corr) > 0.7"""
corr_masked = ma.masked_outside(np.array(correlation), -0.7, 0.7)"""Set gold color for the masked/bad values"""
cmap = plt.get_cmap('coolwarm')
cmap.set_bad('gold')ax = sns.heatmap(data=correlation, cmap=cmap,
mask=corr_masked.mask,
linewidths=2, cbar=True)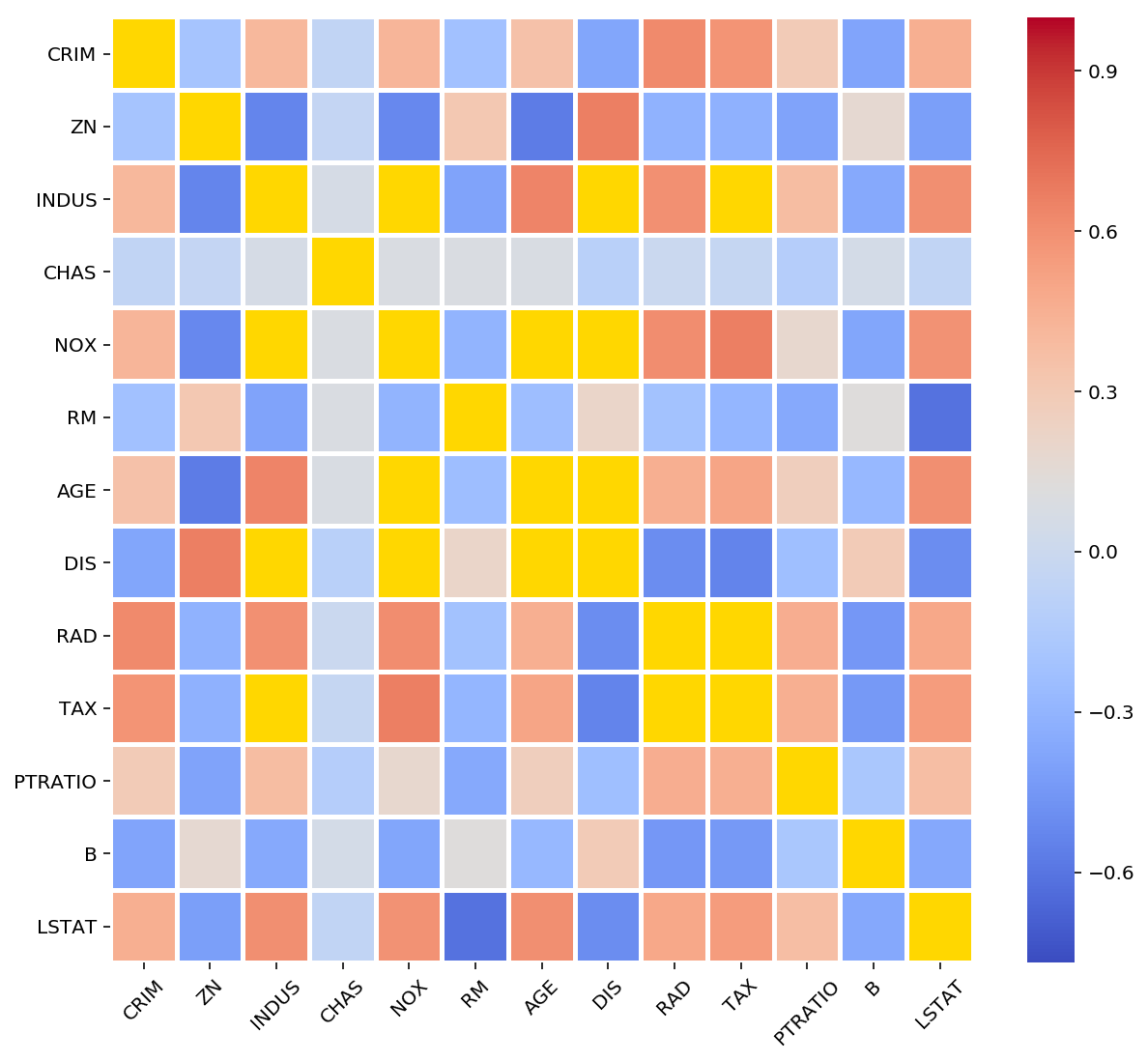
翻译自: https://towardsdatascience.com/the-concept-of-masks-in-python-50fd65e64707
binary masks

















 3759
3759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









