






aws spark
技术提示 (TECHNICAL TIPS)
介绍 (Introduction)
At first, it seemed to be quite easy to write down and run a Spark application. If you are experienced with data frame manipulation using pandas, numpy and other packages in Python, and/or the SQL language, creating an ETL pipeline for our data using Spark is quite similar, even much easier than I thought. And comparing to other database (such as Postgres, Cassandra, AWS DWH on Redshift), creating a Data Lake database using Spark appears to be a carefree project.
最初,写下并运行一个Spark应用程序似乎很容易。 如果您熟悉使用Python和/或SQL语言中的pandas,numpy和其他软件包进行数据帧操作的经验,那么使用Spark为我们的数据创建ETL管道非常相似,甚至比我想象的要容易得多。 与其他数据库(例如Postgres,Cassandra,Redshift上的AWS DWH)相比,使用Spark创建Data Lake数据库似乎是一个轻松的项目。
But then, when you deployed Spark application on the cloud service AWS with your full dataset, the application started to slow down and fail. Your application ran forever, you even didn’t know if it was running or not when observing the AWS EMR console. You might not know where it was failed: It was difficult to debug. The Spark application behaved differently between the local mode and stand alone mode, between the test set — a small portion of dataset — and full dataset. The list of problems went on and on. You felt frustrated. Really, you realized that you knew nothing about Spark. Well, optimistically, then it was indeed a very good opportunity to learn more about Spark. Running into issues is the normal thing in programming anyway. But, how to solve problems quickly? Where to start?
但是,当您将具有完整数据集的Spark应用程序部署到云服务AWS上时,该应用程序开始运行缓慢并失败。 您的应用程序永远运行,在观察AWS EMR控制台时,您甚至都不知道它是否正在运行。 您可能不知道它在哪里失败:这很难调试。 在局部模式和独立模式之间,测试集(数据集的一小部分)和完整数据集之间,Spark应用程序的行为有所不同。 问题的清单还在不断。 你感到沮丧。 确实,您意识到自己对Spark一无所知。 好吧,乐观的话,那确实是一个很好的机会,更多地了解Spark。 无论如何,遇到问题是编程中的正常现象。 但是,如何快速解决问题? 从哪儿开始?
After struggling with creating a Data Lake database using Spark, I feel the urge to share what I have encountered and how I solved these issues. I hope it is helpful for some of you. And please, correct me if I am wrong. I am still a newbie in Spark anyway. Now, let’s dive in!
在努力使用Spark创建Data Lake数据库之后,我感到有分享自己遇到的问题以及如何解决这些问题的渴望。 希望对您中的某些人有所帮助。 如果我错了,请纠正我。 无论如何,我还是Spark的新手。 现在,让我们开始吧!
Cautions
注意事项
1. This article assumes that you already have some working knowledge of Spark, especially PySpark, command line environment, Jupyter notebook and AWS. For more about Spark, please read the reference here.
1.本文假设您 已经具备一些Spark的工作知识,尤其是PySpark,命令行环境,Jupyter Notebook和AWS。 有关Spark的更多信息,请在此处阅读参考。
2. This is your responsibility for monitoring usage charges on the AWS account you use. Remember to terminate the cluster and other related resources each time you finish working. The EMR cluster is costly.
2.这是您负责监视所使用的AWS账户的使用费用的责任。 请记住,每次完成工作时都要终止集群和其他相关资源。 EMR集群的成本很高。
3. This is one of the accessing projects for the Data Engineering nanodegree on Udacity. So to respect the Udacity Honor Code, I would not include the full notebook with the workflow to explore and build the ETL pipeline for the project. Part of the Jupyter notebook version of this tutorial, together with other tutorials on Spark and many more data science tutorials could be found on my github.
3.这是Udacity上的数据工程纳米学位的访问项目之一。 因此,为了遵守Udacity荣誉守则,我不会在工作流程中包括完整的笔记本来探索和构建该项目的ETL管道。 本教程的Jupyter笔记本版本的一部分,以及Spark上的其他教程以及更多数据科学教程,都可以在我的github上找到。
项目介绍 (Project Introduction)
项目目标 (Project Goal)
Sparkify is a startup company working on a music streaming app. Through the app, Sparkify has collected information about user activity and songs, which is stored as a directory of JSON logs (log-data - user activity) and a directory of JSON metadata files (song_data - song information). These data resides in a public S3 bucket on AWS.
Sparkify是一家致力于音乐流应用程序的新兴公司。 通过该应用程序,Sparkify收集了有关用户活动和歌曲的信息,这些信息存储为JSON日志的目录( log-data -用户活动)和JSON元数据文件的目录( song_data歌曲信息)。 这些数据位于AWS上的公共S3存储桶中。
In order to improve the business growth, Sparkify wants to move their processes and data onto the data lake on the cloud.
为了提高业务增长,Sparkify希望将其流程和数据移至云上的数据湖中。
This project would be a workflow to explore and build an ETL (Extract — Transform — Load) pipeline that:
该项目将是一个工作流程,用于探索和构建ETL(提取-转换-加载)管道 ,该管道包括:
- Extracts data from S3 从S3提取数据
- Processes data into analytics tables using Spark on an AWS cluster 在AWS集群上使用Spark将数据处理到分析表中
- Loads the data back into S3 as a set of dimensional and fact tables for the Sparkify analytics team to continue finding insights in what songs their users are listening to. 将数据作为一组维度表和事实表加载到S3中,以供Sparkify分析团队继续查找其用户正在收听的歌曲的见解。
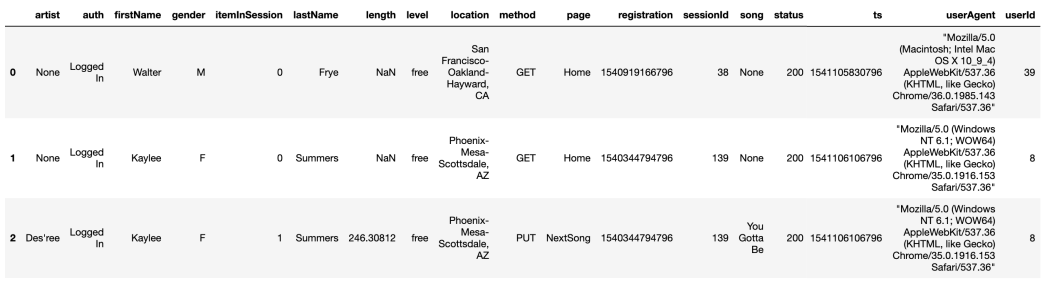
Below are the sample from JSON log file and JSON song file:
以下是JSON日志文件和JSON歌曲文件的示例:

The dimension and fact tables for this database were designed as followed: Fields in bold: partition keys.
此数据库的维和事实表的设计如下: 粗体字的字段:分区键。

(ERD diagram was made using https://dbdiagram.io/)
(ERD图是使用https://dbdiagram.io/制作的 )
Project Workflow
项目工作流程
This is my workflow for the project. An experienced data engineer might skip many of these steps, but for me, I would rather go slowly and learn more:
这是我的项目工作流程。 经验丰富的数据工程师可能会跳过许多步骤,但是对我来说,我宁愿慢慢学习并了解更多信息:
- Build the ETL process step-by-step using Jupyter notebook on sample data in local directory; write output to local directory. 使用Jupyter Notebook在本地目录中的示例数据上逐步构建ETL流程; 将输出写入本地目录。
- Validate the ETL Process using the sub-dataset on AWS S3; write output t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









