





谷歌比利时

基本思路 (The basic idea)
Generating text with artificial neural networks, or neural text generation, has become very popular the last couple of years. Large-scale transformer language models such as OpenAI’s GPT-2/3 have made it possible to generate very convincing text that looks like it could have been written by a human. (If you haven’t tried it out yourself already, I highly recommend checking out the Write With Transformer page.)
在过去的几年中,使用人工神经网络生成文本或神经文本生成已变得非常流行。 诸如OpenAI的GPT-2 / 3之类的大规模转换器语言模型使得生成令人信服的文本(看起来像是人类编写的文本)成为可能。 (如果您还没有尝试过,我强烈建议您查看“ 使用变压器编写”页面 。)
While this causes a lot of concern about potentially misusing the technology, it also brings with it a lot of potential. Many creative applications have already been built using GPT-2, such as for example the text-based adventure game AI Dungeon 2. The key idea behind such applications is to fine-tune the language model on your own dataset, which teaches the model to generate text in line with your own specific domain. Make sure to check out this blog post about how my colleagues at ML6 used this approach for generating song lyrics.
尽管这引起人们对滥用该技术的广泛关注,但它也带来了很多潜力。 已经使用GPT-2构建了许多创意应用程序,例如基于文本的冒险游戏AI Dungeon 2 。 此类应用程序背后的关键思想是微调您自己的数据集上的语言模型,从而教会模型根据您自己的特定领域生成文本。 确保查看此博客文章 ,了解我的ML6同事如何使用这种方法生成歌曲歌词。
However, it is often difficult to generate text of equal quality in languages different from English since no large pre-trained models are available in other languages. Training these large models from scratch is prohibitive for most people due to the extreme amounts of compute power necessary (as well as the need for a large enough dataset).
但是,通常很难用与英语不同的语言来生成质量相同的文本,因为没有其他语言的大型预训练模型可用。 对于大多数人来说,从头开始训练这些大型模型是不可行的,因为它们需要极高的计算能力(以及对足够大的数据集的需求)。
应用这个想法 (Applying this idea)
At ML6 we wanted to experiment with large-scale Dutch text generation on a unique dataset. From our collaboration with Fednot (the Royal Federation of Belgian Notaries), we created a large dataset consisting of 1 million anonymized Belgian real estate deeds, which Fednot kindly agreed to let us work on for this experiment.
在ML6上,我们想对独特的数据集进行大规模荷兰文本生成的实验。 通过与Fednot (比利时公证人皇家联合会)的合作,我们创建了一个由100万个匿名的比利时房地产契约组成的大型数据集,Fednot同意让我们继续进行此实验。
The idea: train an autocomplete model that can ultimately be used as a writing tool for the notaries to assist in writing real estate deeds. In order to make the tool even more useful to the notaries we decided to spice up the model a bit by adding keywords as extra side input. This allows for steering the context of the text to be generated, as in the following example generated by our model:
这个想法:训练一个自动完成模型,该模型最终可以用作公证人的书写工具,以协助撰写房地产契约。 为了使该工具对公证人更加有用,我们决定通过添加关键字作为额外的辅助输入来对模型进行一些补充。 这允许控制要生成的文本的上下文,如以下示例由我们的模型生成的示例:

In this blog post we will discuss how we trained our model. We will cover both the choice of model architecture and the data preprocessing, including how we extracted keywords for our training data. At the end we will show some results and discuss possible improvements and future directions.
在此博客文章中,我们将讨论如何训练模型。 我们将介绍模型架构的选择和数据预处理,包括如何为训练数据提取关键字。 最后,我们将显示一些结果并讨论可能的改进和未来的方向。
模型架构 (The model architecture)
Text generation can be phrased as a language modeling task: predicting the next word given the previous words. Recurrent neural networks (RNNs) used to be the architecture of choice for this task because of its sequential nature and success in practice.
文本生成可被表述为语言建模任务:根据先前的单词预测下一个单词。 递归神经网络(RNN)曾经是此任务的首选架构,因为它的顺序性质和在实践中的成功。
RNN (RNNs)
In an RNN language model, an input sequence of tokens (e.g. words or characters) is processed from left to right, token by token, and at each time step the model will try to predict the next token by outputting a probability distribution over the whole vocabulary. The token with the highest probability is the predicted next token. (For an in depth explanation of how RNNs work, check out Andrej Karpathy’s legendary blog post “The Unreasonable Effectiveness of Recurrent Neural Networks”.)
在RNN语言模型中,令牌的输入序列(例如单词或字符)是从左到右,逐个令牌地处理的,并且在每个时间步,模型都会通过输出整个概率分布来尝试预测下一个令牌词汇。 概率最高的令牌是预测的下一个令牌。 (要深入了解RNN的工作原理,请查看Andrej Karpathy的传奇博客文章“循环神经网络的不合理有效性” 。)

升级:变压器 (Leveling up: transformers)
More recently, the transformer architecture from the paper Attention Is All You Need (Vaswani et al) has taken over the NLP landscape due to its computational efficiency. In a transformer model there is no sequential computation but it instead relies on a self-attention mechanism that can be completely parallelized, thereby taking full advantage of modern accelerators such as GPUs. You can find a great explanation of the transformer architecture in Jay Alammar’s “The Illustrated Transformer”.
最近,论文《 注意就是你所需要》 (Vaswani等人)中的变压器体系结构由于其计算效率而取代了NLP。 在转换器模型中,没有顺序计算,但是它依赖于可以完全并行化的自我关注机制,从而充分利用了现代加速器(如GPU)的优势。 您可以在Jay Alammar的“插图变压器”中找到有关变压器架构的绝佳说明。
Transformers are particularly successful in large scale settings, where you have several gigabytes of training data. An example of this is GPT-2, which was trained on 40GB of raw text from the internet at an estimated training cost of $256 per hour! However, RNNs (or its variant LSTM) remain competitive for language modeling and might still be better suited for smaller datasets.
变压器在大规模设置中特别成功,在这种设置中,您有几GB的训练数据。 例如GPT-2,它接受了来自互联网的40GB原始文本的培训,估计培训费用为每小时256美元! 但是,RNN(或其变体LSTM)在语言建模方面仍然具有竞争力,并且可能仍然更适合较小的数据集。
我们的模型 (Our model)
Returning to our use case, we actually have enough data (around 17GB) to train a GPT-2 like model but chose to go with an LSTM-based architecture as the data is quite repetitive since many phrases are reused in several deeds so we figured that it would probably not be necessary to go for a full-fledged transformer architecture in order to obtain good results (also check out the recent movement towards simpler and more sustainable NLP, eg. the SustaiNLP2020 workshop at EMNLP).
回到我们的用例,我们实际上有足够的数据(大约17GB)来训练类似GPT-2的模型,但由于数据重复性很强,因为许多短语已在多个实践中重复使用,因此选择了基于LSTM的体系结构,因此我们认为为了获得良好的结果,可能没有必要采用成熟的变压器架构(也请查看最近朝着更简单,更可持续的NLP发展的趋势,例如EMNLP的SustaiNLP2020研讨会)。
In the end we went for a 4 layer LSTM model with embedding size 400 and hidden size 1150, in line with the architecture in Merity et al. We tie the weights of the input embedding layer to the output softmax layer, which has been shown to improve results for language modeling. Moreover, we add dropout regularization to the non-recurrent connections of the LSTM. (Adding dropout to the recurrent connections is not compatible with the CuDNN optimized version of the LSTM architecture, which is needed for training efficiently on a GPU.)
最后,我们采用了4层LSTM模型,其嵌入尺寸为400,隐藏尺寸为1150,与Merity等人的体系结构一致 。 我们将输入嵌入层的权重绑定到输出softmax层,这已被证明可以改善语言建模的结果。 此外,我们向LSTM的非经常性连接添加了辍学正则化。 (向循环连接中添加中断与LSTM架构的CuDNN优化版本不兼容,这对于在GPU上进行有效训练是必需的。)
We use subword tokenization since it provides a good compromise between character-level and word-level input (see this blog post for more explanation). More specifically, we train our own BPE tokenizer with a vocab size of 32k using the Hugging Face tokenizers library.
我们使用子词标记化,因为它在字符级输入和词级输入之间提供了很好的折衷方案(有关更多说明,请参见此博客文章 )。 更具体地说,我们使用Hugging Face分词器库训练了自己的BPE分词器,其vocab大小为32k。
关键字介绍 (Introducing keywords)
Our basic language model architecture is now in place but the next question is how to incorporate keywords as side input. For this we take inspiration from the machine translation literature, where typically an encoder-decoder model with attention is being used (originally introduced in Bahadanu et al). Given a sentence in the source language the encoder first encodes each token into a vector representation and the decoder then learns to output the translated sentence token by token by “paying attention” to the encoder representations. In this way the decoder learns which parts of the input sentence are most important for the output at each time step. (Once again, Jay Alammar has a nice visual blog post about this.)
我们现在的基本语言模型架构已经就位,但是下一个问题是如何将关键字作为辅助输入。 为此,我们从机器翻译文献中汲取了灵感,通常会使用注意力集中的编码器/解码器模型(最初在Bahadanu等人中介绍)。 给定源语言中的句子,编码器首先将每个标记编码为矢量表示,然后解码器通过“注意”编码器表示来学习逐标记输出翻译后的句子标记。 以此方式,解码器了解每个时间步中输入句子的哪些部分对于输出最重要。 (再次,Jay Alammar有一篇不错的有关此的可视博客文章 。)
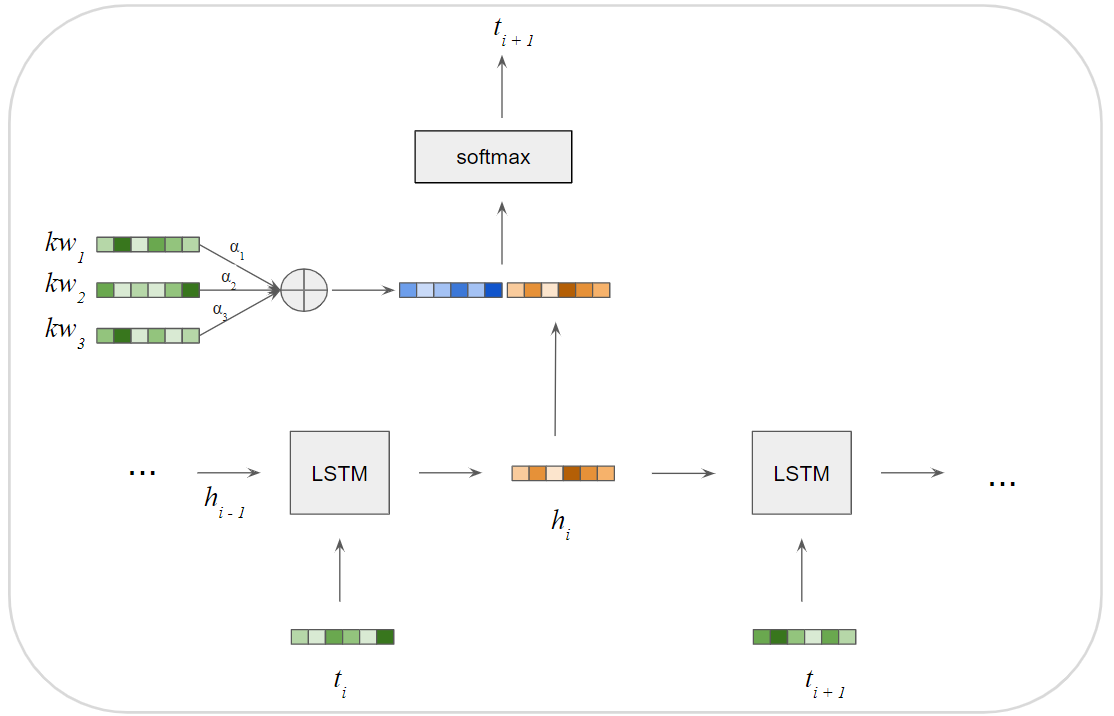
In our case, we will “encode” our input keywords with a simple embedding lookup layer. Our “decoder” is the aforementioned LSTM model, with an extra attention layer added before the final softmax layer. This attention layer allows the language model to “pay attention” to the keywords before predicting the next token.
在本例中,我们将使用简单的嵌入查找层对输入的关键字进行“编码”。 我们的“解码器”是上述LSTM模型,在最终的softmax层之前添加了额外的注意层。 该关注层允许语言模型在预测下一个标记之前“关注”关键字。
Our final model architecture looks as follows:
我们最终的模型架构如下所示:
数据 (The data)
In order to train our model we need a dataset consisting of pieces of text paired with their corresponding keywords. Our raw dataset from Fednot actually comes from scanned PDF files so the first step is to convert these PDF files into (pieces of) text. Our full data pipeline looks as follows:
为了训练我们的模型,我们需要一个数据集,该数据集由文本片段和相应的关键字组成。 我们来自Fednot的原始数据集实际上来自扫描的PDF文件,因此第一步是将这些PDF文件转换为文本(部分)。 我们完整的数据管道如下所示:
Clause detection: A deed is built up of clauses. For example there could be a clause describing the real estate property, another clause about the price, and so on. We start by training a clause detection model, which splits up a full deed PDF file into its building block clauses using computer vision.
条款检测 :契约是由条款构成的。 例如,可能有一个描述房地产的条款,另一个关于价格的条款,等等。 我们首先训练一个子句检测模型,该模型使用计算机视觉将完整的契约PDF文件拆分为其构造块子句。
OCR: We convert each clause into text by using out-of-the-box optical character recognition. This results in somewhat noisy text, which we clean up a bit by filtering out clauses with the worst OCR mistakes.
OCR :我们使用开箱即用的光学字符识别功能将每个子句转换为文本。 这样会产生一些嘈杂的文本,我们通过过滤掉OCR错误最严重的子句来对其进行清理。
Pseudonymization: The clauses are pseudonymized by replacing all sensitive named entities, such as names, addresses and account numbers, with randomized entities. The advantage of this approach is that even if our model would ever miss an entity, an adversary would never be able to recognize which entities are real and which are randomized. We trained our own custom named entity recognition model using spaCy.
假名化 :通过将所有敏感的命名实体(例如名称,地址和帐号)替换为随机实体,对子句进行假名化。 这种方法的优势在于,即使我们的模型会错过任何一个实体,对手也永远无法识别哪些实体是真实的,哪些是随机的。 我们使用sPay训练了自己的自定义命名实体识别模型。
Splitting into paragraphs: Full clauses can be very long and diverse, so we split up each clause into paragraphs that are easier to capture with keywords. Moreover, we filter out paragraphs that are either very short or very long because those paragraphs are more difficult to learn from. We only keep paragraphs that are between 8 and 256 tokens long.
分成几段 :完整的子句可能很长而且很多种,因此我们将每个子句分成几段,这些段很容易用关键字捕获。 此外,我们过滤掉很短或很长的段落,因为这些段落更难于学习。 我们只保留8到256个令牌之间的段落。
Keyword extraction: For each paragraph we extract all nouns, verbs and adjectives using spaCy. These are the keyword candidates. In some cases the paragraph starts with a short title, which we can detect heuristically. In these cases we include the title as a keyword since it contains very concise information on what the paragraph is about. We now have a (rather large and diverse) list of keywords per paragraph. At training time we sample a number of these keywords based on their TF-IDF weights so that rare words get sampled more frequently. The number of keywords to sample is also changed dynamically during training: it can be anywhere from 0 to 6 keywords per paragraph. This allows for a very diverse way of using the model since the model learns to handle both inputs without any keywords and inputs with up to 6 keywords.
关键字提取 :对于每个段落,我们都使用spaCy提取所有名词,动词和形容词。 这些是关键字候选。 在某些情况下,该段落以短标题开头,我们可以通过启发式检测。 在这种情况下,我们将标题作为关键字,因为它包含有关段落内容的非常简洁的信息。 现在,每个段落都有一个(相当大且多样的)关键字列表。 在训练时,我们会根据它们的TF-IDF权重对许多这些关键字进行抽样,以便更频繁地对稀有词进行抽样。 在训练过程中,样本关键字的数量也会动态更改:每个段落的关键字范围可以是0到6。 这允许使用模型的方式非常多样化,因为模型学会了处理没有任何关键字的输入和最多包含6个关键字的输入。
训练时间 (Training time)
The model was trained for 10 epochs using the Adam optimizer with gradient clipping and a learning rate of 3e-4. We did not do a lot of hyperparameter tuning so these training settings could probably be improved further. Our loss curve looks reasonable:
使用具有梯度裁剪和3e-4的学习率的Adam优化器,对模型进行了10个时期的训练。 我们没有进行大量的超参数调整,因此这些训练设置可能会得到进一步改善。 我们的损失曲线看起来很合理:
推断时间 (Inference time)
It is finally time to take our newly trained model out for a spin but before doing so, let us first have a quick discussion on how to actually generate text from a language model.
终于该抽出我们新训练的模型了,但是在这样做之前,让我们首先快速讨论如何从语言模型中实际生成文本。
Recall that a language model outputs a probability distribution over the whole vocabulary, capturing how likely each token is of being the next token.
回想一下,语言模型在整个词汇表上输出概率分布,捕获每个标记成为下一个标记的可能性。
贪婪解码 (Greedy decoding)
The easiest way to generate text is to simply take the most likely token at each time step, also known as greedy decoding. However, greedy decoding (or its less greedy variant, beam search) is known to produce quite boring and repetitive text that often gets stuck in a loop, even for sophisticated models such as GPT-2.
生成文本的最简单方法是在每个时间步长简单地获取最可能的令牌,也称为贪婪解码。 但是,众所周知,贪婪解码(或其贪婪程度较低的变体,即波束搜索)会产生相当无聊且重复的文本,即使对于复杂的模型(例如GPT-2),这些文本也经常陷入循环。
纯抽样 (Pure sampling)
Another option is to sample the next token from the output probability distribution at each time step, which allows the model to generate more surprising and interesting text. Pure sampling, however, tends to produce text that is too surprising and incoherent, and while it is certainly more interesting than the text from greedy decoding, it often doesn’t make much sense.
另一个选择是在每个时间步长从输出概率分布中采样下一个标记,这使模型可以生成更令人惊讶和有趣的文本。 但是,纯采样往往会产生太令人惊讶和不连贯的文本,尽管它肯定比贪婪解码的文本更有趣,但通常没有多大意义。
两全其美 (Best of both worlds)
Luckily there are also alternative sampling methods available that provide a good compromise between greedy decoding and pure sampling. Commonly used methods include temperature sampling and top-k sampling.
幸运的是,还有其他可供选择的采样方法,可以在贪婪解码和纯采样之间达成良好的折衷。 常用的方法包括温度采样和top-k采样。

We chose to go with the more recently introduced sampling technique called nucleus sampling or top-p sampling, since it has been shown to produce the most natural and human-like text. It was introduced in the paper “The Curious Case of Neural Text Degeneration” (Holtzman et al) from last year, which is a very nice and interesting read that includes a comparison of different sampling strategies.
我们选择使用最近引进的称为核采样或top-p采样的采样技术,因为它已被证明可以产生最自然且与人类相似的文本。 去年的论文“神经文本退化的奇怪案例” (Holtzman等人)对此进行了介绍,这是一本非常有趣的文章,其中包括对不同采样策略的比较。
In nucleus sampling the output probability distribution is truncated so that we only sample from the most likely tokens — the “nucleus” of the distribution. The nucleus is defined by a parameter p (usually between 0.95 and 0.99) which serves as a threshold: we only sample from the most likely tokens whose cumulative probability mass just exceeds p. This allows for diversity in the generated text while removing the unreliable tail of the distribution.
在核采样中,输出概率分布被截断,因此我们仅从最可能的标记(即分布的“核”)中采样。 原子核由用作阈值的参数p(通常在0.95和0.99之间)定义:我们仅从累积概率质量刚好超过p的最有可能的标记中采样。 这样可以在生成的文本中实现多样性,同时消除分发中不可靠的尾部。
Let’s have a look at some examples from our model (we use nucleus sampling with p=0.95 in all examples):
让我们看一下模型中的一些示例(我们在所有示例中都使用p = 0.95的核采样):

We see that the text is pretty coherent and the model has actually learned to take the keywords into account. Next, let’s try with some more rare keywords from our corpus such as “brandweer” (occurs in only 51 training examples) and “doorgang” (occurs in 114 training examples).
我们看到文本非常连贯,并且该模型实际上已经学会了将关键字考虑在内。 接下来,让我们尝试使用语料库中一些更罕见的关键字,例如“ brandweer”(仅出现在51个训练示例中)和“ doorgang”(出现在114个训练示例中)。
The text is now quite nonsensical and includes some made-up words (gehuurgen?) but still the model managed to get the context more or less right.
现在的文本已经很荒谬了,其中包含一些虚构的单词( gehuurgen ?),但是该模型还是设法使上下文或多或少地变得正确。
Let’s finish off with a couple of more examples using more keywords as input.
让我们以使用更多关键字作为输入的更多示例结束。

结论 (Conclusion)
Our first results look promising, at least when using common keywords as input. For keywords that don’t occur very often in our training corpus, the model seems to get confused and generates poor quality text. In general, we also noticed artifacts of OCR mistakes and pseudonymization mistakes from our training data, which limits the quality of the generated text. There is still lots of potential for improving our results, for example by further cleaning up the training data and by tweaking or scaling up the model architecture.
至少在使用通用关键字作为输入时,我们的第一个结果看起来很有希望。 对于在我们的训练语料库中很少出现的关键字,该模型似乎感到困惑,并生成了质量较差的文本。 通常,我们还从训练数据中注意到了OCR错误和假名错误的伪影,这限制了所生成文本的质量。 改善我们的结果仍有很多潜力,例如,通过进一步清理训练数据以及调整或扩大模型体系结构。
One of the lessons learned from this experiment is that you don’t always need a huge transformer model in order to generate good quality text and that LSTMs can still be a viable alternative. The model architecture should be chosen according to your data. That being said it would be interesting to further scale up our approach, using more training data and a bigger model to analyse this trade-off.
从该实验中学到的教训之一是, 您不一定总需要一个庞大的转换器模型来生成高质量的文本 ,而且LSTM仍然是可行的选择。 应根据您的数据选择模型架构。 话虽这么说,使用更多的训练数据和更大的模型来分析这种折衷方法,进一步扩展我们的方法将很有趣。
Text generation is a fun topic within natural language processing but applying it to real-life use cases can be hard due to the lack of control of the output text. Our keyword-enriched autocomplete tool provides a way of controlling the output through the use of keywords. We hope that this will provide notaries with a useful writing tool for assisting in writing Dutch real estate deeds.
在自然语言处理中,文本生成是一个有趣的话题,但是由于缺乏对输出文本的控制,很难将其应用于现实生活中的用例。 我们丰富的关键字自动填充工具提供了一种通过使用关键字来控制输出的方法。 我们希望这将为公证人提供有用的写作工具,以协助撰写荷兰房地产契约。
关于ML6 (About ML6)
We are a team of AI experts and the fastest growing AI company in Belgium. With offices in Ghent, Amsterdam, Berlin and London, we build and implement self learning systems across different sectors to help our clients operate more efficiently. We do this by staying on top of research, innovation and applying our expertise in practice. To find out more, please visit www.ml6.eu
我们是AI专家团队和比利时发展最快的AI公司。 通过在根特,阿姆斯特丹,柏林和伦敦的办事处,我们建立和实施跨不同部门的自学系统,以帮助我们的客户更有效地运作。 我们通过始终保持研究,创新和在实践中运用我们的专业知识来做到这一点。 要了解更多信息,请访问www.ml6.eu
翻译自: https://blog.ml6.eu/neural-text-generation-from-1-million-belgian-real-estate-deeds-9230c940432c
谷歌比利时















 8260
8260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









