





 本文探讨了如何解决AI项目中遇到的数据质量问题,包括数据清洗、缺失值处理、异常检测等方面,旨在提高机器学习和人工智能模型的性能。
本文探讨了如何解决AI项目中遇到的数据质量问题,包括数据清洗、缺失值处理、异常检测等方面,旨在提高机器学习和人工智能模型的性能。
ai 数据质量差 解决方法
常见数据质量问题 (Common Data Quality Issues)
Before jumping right into how to solve data quality issues we need to know what are the common issues and how to spot them.
在深入探讨如何解决数据质量问题之前,我们需要知道什么是常见问题以及如何发现它们。
Missing value: this is the easiest one to identify, simply look at if there are any null values, maybe apply a filter to make them more obvious.
缺失值 :这是最容易识别的值,只需查看是否有空值,或者应用过滤器使其更明显。
Duplicate value: when several rows of data appear to be the same then most likely they have been mistakenly recorded multiple times.
重复值:当几行数据看起来相同时,很可能已经多次错误地记录了它们。
Inconsistent value: the string values of the same attributes do not follow the same naming convention, e.g. both LA and “Los Angeles” are present in the City data field.
值不一致:具有相同属性的字符串值未遵循相同的命名约定,例如,“城市”数据字段中同时存在LA和“ Los Angeles”。
There are also many data quality issues requires certain domain knowledge to identify, hence it is important to do some research on the industry before investigating, e.g. a record of 121 degrees water temperature is most likely to be wrong.
还有许多数据质量问题需要某些领域的知识来识别,因此在进行调查之前对行业进行一些研究非常重要,例如,记录121度水温很可能是错误的。
This article will mainly focus on how to address inconsistent value. There will be more articles coming up to discuss more data quality issues.
本文将主要关注如何解决价值不一致的问题 。 将会有更多的文章讨论更多的数据质量问题。
Usually, inconsistent values are mitigated using REGEX, however, Tableau Prep Builder provides a more intuitive way to solve the issue without coding or programming knowledge. The functionality of Tableau Prep Builder is to carry out data processing. It follows the basic system of input -> process -> output. The most basic data preprocessing flow involves three phases:
通常,使用REGEX可以消除不一致的值,但是,Tableau Prep Builder提供了一种更直观的方法来解决问题,而无需进行编码或编程知识。 Tableau Prep Builder的功能是执行数据处理。 它遵循输入->处理->输出的基本系统。 最基本的数据预处理流程涉及三个阶段:

connect to data source
连接到数据源
cleaning step
清洁步骤
output the prepared data
输出准备好的数据
Data quality issues are mainly addressed in the Cleaning Step. After selecting one data field, we can see that there are several options in the drop-down menu that can be applied to string type attribute. Clean and Group Values are commonly applied to address inconsistent data. Note that, in the older version of Tableau Prep Builder, it was “Group and Replace” rather than “Group Values”.
数据质量问题主要在清理步骤中解决。 选择一个数据字段后,我们可以看到下拉菜单中有多个选项可以应用于字符串类型属性。 清除 值和组值通常用于解决不一致的数据。 请注意,在旧版本的Tableau Prep Builder中,它是“分组并替换”而不是“分组值”。
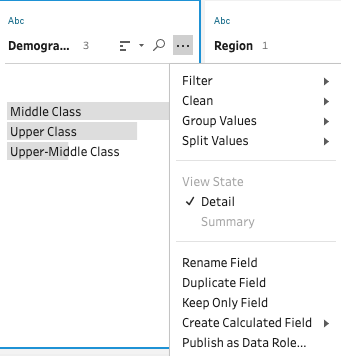
Then what’s the difference between Clean and Group Values and when should we use which? Clean can be applied prior to Group Values. This is because after having a glimpse of the values, we would have an idea of whether they appear to be messy. This could be having random numbers concatenated to the string values or inconsistent use of upper/lower cases. In this case, use Group Values on each of them will become very tedious. Therefore, Clean function will be more handy to tackle these inconsistencies all together.
那么,“ 清除 值 ”和“ 组值”之间有什么区别,何时应使用? 可以在组值之前应用“ 清除” 。 这是因为在看过这些值之后,我们将对它们是否看起来很凌乱有所了解。 这可能是随机数与字符串值连接在一起,或者大小写不一致。 在这种情况下,在每个值上使用组值将变得非常乏味。 因此, 清理功能将更方便地一起解决这些不一致问题。
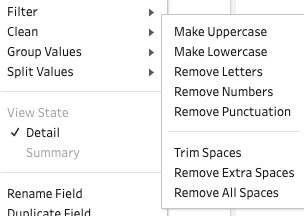
The Clean methods in the picture above (e.g. make uppercase/ lowercase, remove letters, remove numbers, remove punctuation etc) will transform all the values of that data field at the same time. They are good at addressing issues at the data field level. For example, if perform Make Lowercase, all the values will be transformed into lowercase.
上图中的Clean方法(例如,使大写/小写,删除字母,删除数字,删除标点符号等)将同时转换该数据字段的所有值 。 他们擅长在数据字段级别解决问题。 例如,如果执行Make小写 ,则所有值都将转换为小写。
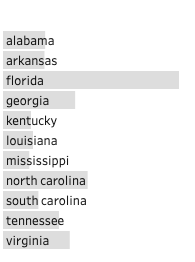
On the other hand, Group Values method is applied after we have taken a closer look at individual string values. It can be very useful to solve specific types of inconsistent values. It might be the result of typos or missing character etc. There are four main methods and each deal with different scenarios.
另一方面,在仔细研究了各个字符串值之后,将应用“ 组值”方法。 解决特定类型的不一致值可能非常有用。 这可能是拼写错误或缺少字符等的结果。有四种主要方法,每种方法都处理不同的情况。
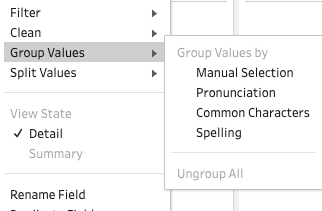
manual selection method: usually applied when grouping syntactically irrelevant values together, because this can be easily identified without specific domain knowledge, e.g. USA and United State
手动选择方法:通常在将语法无关的值组合在一起时使用,因为无需特定领域知识即可轻松识别,例如美国和美国
pronunciation method: group values with similar pronunciation but different text form, e.g. South Africa and south Africa
发音方法:将具有相似发音但文本形式不同的值分组,例如南非和南非
common characters method: usually applied when there are typos e.g. smith and simth
常用字符法:通常在有拼写错误时使用,例如史密斯和西姆斯
spelling method: usually applied when there are missing characters in the values e.g. smith and smth
拼写方法:通常在值中缺少字符(例如史密斯和史密斯)时应用
Using these four methods, most of the inconsistent naming of specific string values can be addressed properly.
使用这四种方法,可以正确解决大多数特定字符串值不一致的问题。
未来如何防止价值不一致? (How to Prevent Inconsistent Value in the Future?)
The easiest way to prevent this data quality issue from happening is to enforce a drop-down list during the data entry phase. Only allowing to select value from the list will mitigate any inconsistent format, typos or irrelevant data.
防止发生此数据质量问题的最简单方法是在数据输入阶段强制执行下拉列表 。 仅允许从列表中选择值将减轻格式不一致,错别字或不相关的数据。
更多资源 (More Resources)
翻译自: https://medium.com/analytics-vidhya/how-to-address-common-data-quality-issues-2cb58a09b225
ai 数据质量差 解决方法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









