





A sentiment analysis of Fyodor Dostoevsky’s greatest novels
费奥多尔·陀思妥耶夫斯基最伟大小说的情感分析
Reading the great works of Russian novelist Fyodor Dostoevsky is like having your amygdala stung by wasps for roughly 500 pages straight. It’s emotional. His five masterpieces, Notes from the Underground, Crime and Punishment, The Idiot, The Possessed, and The Brothers Karamazov, are considered some of the darkest and most violent novels of the 19th century. The following sentiment analysis is my effort to leverage the tools of Natural Language Processing to gain new insight into these groundbreaking pieces of literature.
阅读俄罗斯小说家费奥多尔·陀思妥耶夫斯基(Fyodor Dostoevsky)的伟大作品,就像是用WaSP把杏仁核st了大约500页一样。 令人感动。 他的五本杰作《地下笔记》,《犯罪与惩罚》,《白痴》,《拥有者》和《卡拉马佐夫兄弟》被认为是19世纪最黑暗,最暴力的小说。 以下情感分析是我努力利用自然语言处理工具来获得对这些开创性文献的新见解。
This article is intended for readers with an understanding of some basic concepts of data science and natural language processing. The analysis was performed in Python, so familiarity with the language will help you to follow along and adapt the code for your own work. All code needed is shown throughout the article. You can also check it out on Github.
本文面向了解数据科学和自然语言处理一些基本概念的读者。 该分析是使用Python执行的,因此对这种语言的熟悉将有助于您继续学习并使代码适应您的工作。 整篇文章都显示了所需的所有代码。 您也可以在Github上查看。
Crucial to this analysis are the AFINN and NRC lexicons:
该分析的关键是AFINN和NRC词典:
“The AFINN lexicon is a list of English terms manually rated for valence with an integer between -5 (negative) and +5 (positive) by Finn Årup Nielsen between 2009 and 2011.” http://corpustext.com/reference/sentiment_afinn.html
“ AFINN词典是由FinnÅrupNielsen在2009年至2011年之间手动对价进行评级的英语术语列表,其整数在-5(负)和+5(正)之间。” http://corpustext.com/reference/sentiment_afinn.html
“[The NRC lexicon] lists associations of words with eight emotions (anger, fear, anticipation, trust, surprise, sadness, joy, and disgust) and two sentiments (negative and positive). Created by manual annotation on a crowdsourcing platform.” https://nrc.canada.ca/en/research-development/products-services/technical-advisoryservices/sentiment-emotion-lexicons
“ [NRC词典]列出了具有八种情感(愤怒,恐惧,预期,信任,惊奇,悲伤,喜悦和厌恶)和两种情感(消极和积极)的单词联想。 由众包平台上的手动注释创建。” https://nrc.canada.ca/en/research-development/products-services/technical-advisoryservices/sentiment-emotion-lexicons
Here are the basic imports, we’ll add more as we go:
这是基本的导入,我们将继续添加更多内容:
获取和清理数据 (Getting and Cleaning the Data)
Each of Dostoevsky’s five masterpieces is now in the public domain. Many works in the public domain that have been digitized are available on gutenberg.org. Using some web scraping, we can get the books as follows:
陀思妥耶夫斯基的五个杰作中的每一个现在都在公共领域。 gutenberg.org上提供了许多已被数字化的公共领域的作品。 使用一些网络抓取,我们可以获得以下书籍:
from urllib import request
def get_book(url):
response = request.urlopen(url)
return response.read().decode('utf8')
notes_from_underground_raw = get_book("http://www.gutenberg.org/files/600/600.txt")
crime_and_punishment_raw = get_book("http://www.gutenberg.org/files/2554/2554-0.txt")
the_idiot_raw = get_book("http://www.gutenberg.org/files/2638/2638-0.txt")
the_possessed_raw = get_book("http://www.gutenberg.org/files/8117/8117-0.txt")
the_brothers_karamazov_raw = get_book("http://www.gutenberg.org/files/28054/28054-0.txt")We now have all five books at our fingertips. However, in their present form, they do not lend themselves to analysis. Our first step in cleaning the data is to scrub out extraneous text added by Project Gutenberg (which is mostly copyright information). Each Gutenberg page has similar ways of announcing the start and end of the actual book. Using regular expressions, we can get each book’s contents:
现在,我们所有五本书都唾手可得。 但是,以目前的形式,它们不适合进行分析。 清理数据的第一步是清除由Gutenberg项目添加的多余文本(主要是版权信息)。 古腾堡书的每个页面都有相似的方式来宣布实际书籍的开始和结束。 使用正则表达式,我们可以获得每本书的内容:
import re
def get_book_contents(book_raw):
start = re.compile(r"START OF (?:THE|THIS) PROJECT GUTENBERG", flags=re.IGNORECASE)
end = re.compile(r"END OF (?:THE|THIS) PROJECT GUTENBERG", flags=re.IGNORECASE)
book_start = start.search(book_raw)
book_end = end.search(book_raw)
return book_raw[book_start.span()[1]:book_end.span()[1]]
notes = get_book_contents(notes_from_underground_raw)
crime = get_book_contents(crime_and_punishment_raw)
idiot = get_book_contents(the_idiot_raw)
possessed = get_book_contents(the_possessed_raw)
brothers = get_book_contents(the_brothers_karamazov_raw)Let’s do some more cleaning by tokenizing the text and removing the stop words. We want raw, undiluted emotions. Using the Natural Language Toolkit suite, this can be done like so:
让我们通过标记文本并删除停用词来进行更多清理。 我们想要原始的,未经稀释的情感。 使用自然语言工具包套件,可以这样进行:
import nltk
stop_words = nltk.corpus.stopwords.words('english')
def clean(book, stop_words):
book = book.lower()
#tokenizing
book_tokens_clean = nltk.tokenize.RegexpTokenizer(r'\w+').tokenize(book)
book_clean = pd.DataFrame(book_tokens_clean, columns = ['word'])
#removing stop words
book_clean = book_clean[~book_clean['word'].isin(stop_words)]
#removing extraneous spaces
book_clean['word'] = book_clean['word'].apply(lambda x: re.sub(' +', ' ', x))
book_clean = book_clean[book_clean['word'].str.len() > 1]
return book_cleanA necessary step for this sentiment analysis is to introduce context into our model. As motivation, consider this sentence in Notes from the Underground: “I am not a hero to you now, as I tried to seem before, but simply a nasty person, an impostor.” The AFINN lexicon will assign a positive score of 2.0 to the word hero when, given the context, the word conveys negative sentiment. To correct these errors, we’ll introduce some negation words to our analysis and convert our tokenized data frames into data frames of bigrams. The negation words “no” and “not” are in our current list of stop words, so we’ll have to update the list.
这种情绪分析的必要步骤是将上下文引入我们的模型。 作为动机,请考虑一下《地下笔记》中的这一句话:“我现在不像我以前所看到的那样成为英雄 ,而只是一个讨厌的人,冒名顶替者。” 在给定上下文的情况下,AFINN词典会向英雄一词分配2.0的积极评分,该单词传达了负面情绪。 为了纠正这些错误,我们将在分析中引入一些否定词,并将标记化的数据帧转换为双字母组的数据帧。 否定词“ no”和“ not”在我们的停用词列表中,因此我们必须更新该列表。
keep_words = ['no', 'not']
stop_words_context = [w for w in stop_words if w not in keep_words]
negations = ['not', 'no', 'never', 'without']
def bigram(book):
book_context = clean(book, stop_words_context)
book_bigrams = pd.DataFrame(list(nltk.bigrams(book_context['word'])),
columns = ['word1', 'word2'])
return book_bigrams
notes_bigrams = bigram(notes)
crime_bigrams = bigram(crime)
idiot_bigrams = bigram(idiot)
possessed_bigrams = bigram(possessed)
brothers_bigrams = bigram(brothers)If a word in column word2 is preceded by a negation word in word1, the associated score with be multiplied by -1.
如果word2列中的单词前面有word1中的否定单词,则相关分数将与-1相乘。
使用AFINN词典进行情感分析 (Sentiment analysis with the AFINN lexicon)
To begin with the AFINN lexicon, we’ll import the afinn package and apply scores to the books with the afinn.score function:
首先从AFINN词典开始,我们将导入afinn包,并使用afinn.score函数将分数应用到书中:
from afinn import Afinn
afinn = Afinn()
def afinn_context(book_bigrams):
book_bigrams['score'] = book_bigrams['word2'].apply(afinn.score)
book_bigrams['score'] = book_bigrams.apply(
lambda x: x['score'] * -1 if x['word1'] in negations else x['score'],
axis = 1)
return book_bigrams
notes_afinn = afinn_context(notes_bigrams)
crime_afinn = afinn_context(crime_bigrams)
idiot_afinn = afinn_context(idiot_bigrams)
possessed_afinn = afinn_context(possessed_bigrams)
brothers_afinn = afinn_context(brothers_bigrams)We can use these scores to visualize the trajectory of sentiment within each book. We’ll achieve this by breaking up each book into 500 words chunks, summing over the scores in each chunk, and using the sum as a data point.
我们可以使用这些分数来形象化每本书中的情感轨迹。 通过将每本书分成500个单词块,将每个块的分数相加,然后将总和用作数据点,即可实现这一目标。
def plot_afinn(df, title):
i = 0
scores = []
while i < df.shape[0] - 500:
scores.append(df.iloc[i:i + 500].loc[:, 'score'].sum())
i += 500
plt.plot(scores, c=np.random.rand(3,))
plt.ylabel("AFINN score")
plt.title(title)
plt.xticks([])
#y-axis limits were arrived at from the observed limits in the data.
#These should be changed if you're working with a different corpus.
plt.ylim(top = 165, bottom = -165)
plt.axhline(y = 0, color = 'gray')
plt.show()This gives us the following plots, where the x-axis represents narrative time:
这提供给我们以下图表,其中x轴表示叙述时间:
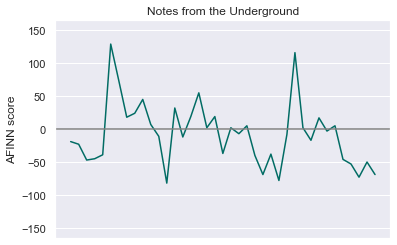
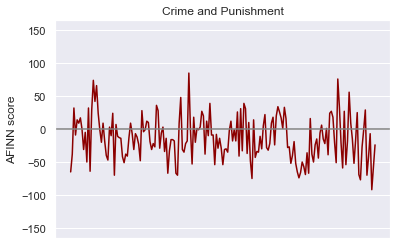
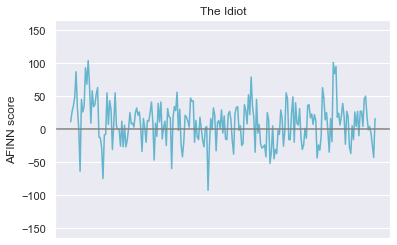
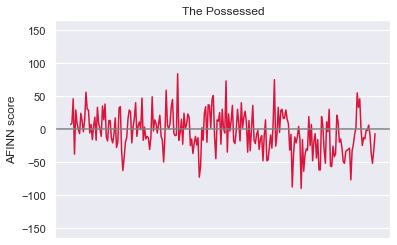

A natural question to ask now is: using the above methods of quantifying sentiment, what is the average sentiment of each novel? Regardless of the corpus being used, most of the words will receive a score of 0. So even deviations from 0 in average sentiment of magnitude 0.001 are strong indications of the document’s overall sentiment.
现在要问的自然问题是:使用上述量化情感的方法,每本小说的平均情感是多少? 无论使用哪种语料库,大多数单词的得分都为0。因此,平均情感度0.001甚至与0的偏离也很能说明文档的总体情感。

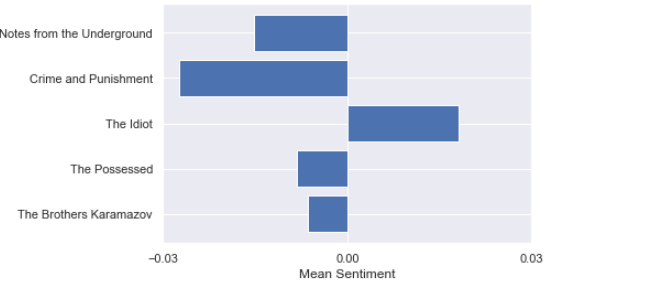
Viola! I was expecting Notes from the Underground to have the highest average negative sentiment. However, upon reflection, the book does contain much less blood and physical horror than Crime and Punishment. It is no surprise to me that The Idiot ranks most positive. It is, at least ostensibly, the least grueling of the bunch. Weighing each book equally, the overall average ≈ -0.0078. Not for the faint of heart.
中提琴! 我期望地下笔记的平均负面情绪最高。 然而,经过反思,这本书所包含的血液和身体恐怖要比《犯罪与惩罚》少得多。 我对《白痴》的排名是最积极的,这不足为奇。 至少从表面上看,这是一堆最少的麻烦。 平均称量每本书的总平均≈ - 0.0078。 不是为了胆小的人。
使用NRC词典进行情感分析 (Sentiment analysis with the NRC lexicon)
The NRC lexicon is available for non-commercial research use here. If you plan on working with this lexicon, please make sure you understand the terms of use.
NRC词典可在此处用于非商业研究。 如果您打算使用此词典,请确保您了解使用条款 。
For each emotion and sentiment, we want to classify words as either conveying the emotion/sentiment or not. I think the best way to describe how to do this is by showing the code, followed by short explanations of each function. I’ll try to keep this brief and somewhat interesting, but no guarantees.
对于每种情感和情感,我们都希望将单词分类为传达情感或不表达情感。 我认为描述此操作的最佳方法是显示代码,然后对每个功能进行简短说明。 我会尽量保持简短和有趣,但不能保证。
NRC = pd.read_csv("NRC.csv", names=["word", "sentiment", "classifaction"])
NRC_sentiments = ['anger', 'anticipation', 'disgust', 'fear', 'joy', 'negative',
'positive', 'sadness', 'suprise', 'trust']
def nrc_classify(word):
return NRC[NRC['word'] == word].loc[:, 'classifaction'].tolist()
def nrc_clean(book_nrc):
book_nrc['classifications'] = book_nrc['word2'].apply(nrc_classify)
book_nrc = book_nrc[book_nrc['classifications'].str.len() > 0]
classification_df = pd.DataFrame.from_dict(dict(book_nrc['classifications'])).transpose()
classification_df.columns = NRC_sentiments
book_nrc = book_nrc.join(classification_df)
book_nrc = book_nrc.drop(['classifications'], axis = 1)
return book_nrc
def nrc_context(book_bigrams):
for e in NRC_sentiments:
book_bigrams[e] = book_bigrams.apply(
lambda x: x[e] * -1 if x['word1'] in negations else x[e],
axis = 1)nrc_classify(word) returns a list of 10 binary digits indicating the word’s affiliation with each NRC emotion/sentiment. The association of each element in the list with each emotion is mapped by ascending alphabetical order (meaning the first element corresponds to Anger and the last corresponds to Trust).
nrc_classify(word)返回一个由10个二进制数字组成的列表,该列表指示该单词与每个NRC情绪/情感的联系。 列表中每个元素与每种情绪的关联都按字母升序映射(这意味着第一个元素对应于Anger ,最后一个元素对应于Trust )。
nrc_clean(book_nrc) takes a data frame of bigrams. In lines 9–10, we add a column to the data frame containing the list of classifications generated by nrc_classify(word) and remove all rows in which the list is empty (empties are caused by words not classified by the lexicon). In lines 12–13, we create a new data frame in which each column is an NRC emotion or sentiment. Each entry in this data frame is created from the lists computed in our previous step. In the final lines of the function, we join our new data frame to book_nrc and remove the column of lists computed in lines 9–10. The result looks like:
nrc_clean(book_nrc)接受一个二元组的数据帧。 在第9-10行中,我们在数据框中添加一列,其中包含由nrc_classify(word)和 删除列表为空的所有行(空是由词典未分类的单词引起的)。 在第12-13行中,我们创建一个新的数据框,其中每一列都是NRC情绪或情感。 该数据框中的每个条目都是从上一步中计算出的列表中创建的。 在函数的最后几行中,我们将新的数据框连接到book_nrc并删除在第9-10行中计算出的列表的列。 结果如下:
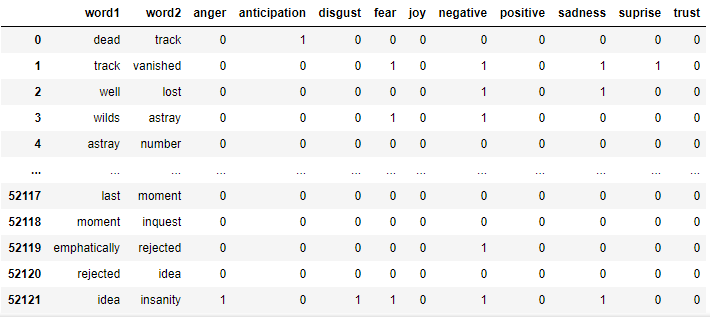
Finally, nrc_context(book_bigrams) provides context to the analysis the same way we did before. If word2 is proceeded by a negation word, the function negates all associated quantities.
最后, nrc_context(book_bigrams)像以前一样为分析提供了上下文。 如果单词2 后面带有否定单词,则该函数将否定所有关联的数量。
I’ve used heat maps to visualize the results. Each block in the plot represents a 750-word chunk. The brightness indicates the amount of emotion conveying words:
我使用热图来可视化结果。 图中的每个块代表一个750字的块。 亮度表示传达情感的单词的数量:
def plot_nrc(df, title):
i = 0
j = 0
scores = pd.DataFrame(np.zeros((df.shape[0] // 750, 10)), columns = NRC_sentiments)
while i < df.shape[0] - 750:
scores.iloc[j] = df.loc[i:i + 750, 'anger':'trust'].sum()
i += 750
j += 1
grid_kws = {"height_ratios": (.9, .05), "hspace": .2}
f, (ax, cbar_ax) = plt.subplots(2, gridspec_kw=grid_kws, figsize=(10,3))
ax = sns.heatmap(scores.transpose(),
ax=ax,
cbar_ax=cbar_ax,
cbar_kws={"orientation": "horizontal", "label" : \
"Number of words conveying sentiment"},
linewidths = 0.01,
xticklabels = False,
vmin = 0,
vmax = 125).set_title(title)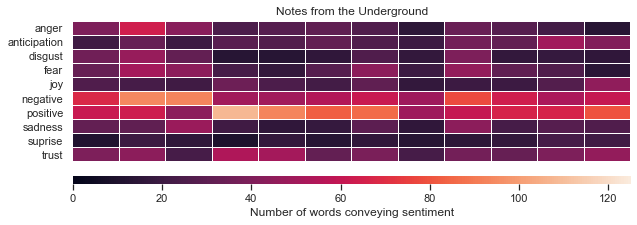
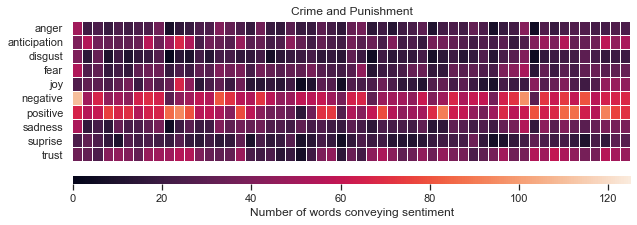
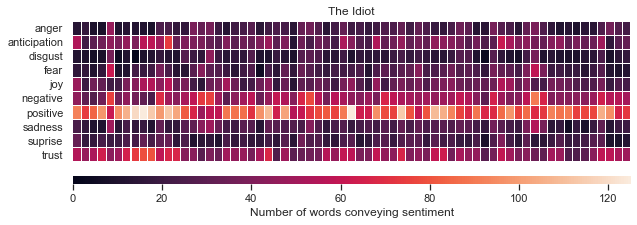


Our last method of analysis with NRC will be to look at the average prevalence of emotions. This will give us a quick snapshot of the overall pervasiveness of different emotions for each book.
我们使用NRC进行分析的最后一种方法是查看情绪的平均患病率。 这将使我们快速了解每本书的不同情绪的普遍性。
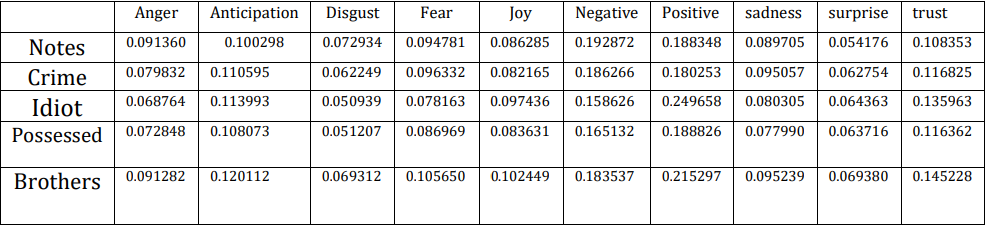
Interesting! In my estimation, the most salient insights gained from the analysis with this lexicon are:
有趣! 据我估计,使用该词典进行分析所得的最突出见解是:
- Like our results form AFINN, Notes from the Underground and Crime and Punishment score highest in negative sentiment. Unlike AFINN, however, Notes from the Underground scores higher than Crime and Punishment in average negative sentiment. 就像我们AFINN的结果一样,《地下笔记》和《犯罪与惩罚》在负面情绪方面得分最高。 但是,与AFINN不同,地下笔记的平均负面情绪得分高于犯罪和惩罚。
- Both AFINN and NRC analyses suggest that The Idiot has the highest average positive sentiment. AFINN和NRC的分析均表明,《白痴》的平均积极情绪最高。
- The Brothers Karamazov is high in both negative and positive sentiment. This agrees with my experience reading the book. Often grueling, but ultimately uplifting. 卡拉马佐夫兄弟的消极情绪和积极情绪都很高。 这与我阅读本书的经验相吻合。 经常令人生厌,但最终会令人振奋。
Thank you for reading, friends. If you enjoyed this article, you may enjoy my follow up piece in which I use some more advanced statistics to gain deeper insights.
谢谢你的阅读,朋友们。 如果您喜欢这篇文章,则可能会喜欢我的后续文章 ,其中我使用一些更高级的统计信息来获得更深入的见解。
翻译自: https://medium.com/@joshtaylor361/nlp-from-the-underground-part-i-7d5cac2cbb8a















 1828
1828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









