






 本文详细介绍了如何从PDF文件中提取表格数据,包括使用Python、Java等编程语言的方法,以及可能涉及的数据存储选项如Excel和MySQL。对于大数据处理场景,此过程尤为重要。
本文详细介绍了如何从PDF文件中提取表格数据,包括使用Python、Java等编程语言的方法,以及可能涉及的数据存储选项如Excel和MySQL。对于大数据处理场景,此过程尤为重要。
怎么提取pdf中的表格数据
In this article, we talk about the challenges and principles of extracting tabular data from PDF docs. We also compare six software tools to find out how they perform their respective tasks of parsing PDF tables and getting data out of them.
在本文中,我们讨论了从PDF文档中提取表格数据的挑战和原理。 我们还比较了六个软件工具,以了解它们如何执行各自的任务以解析PDF表并从中获取数据。
为什么从PDF中提取表格数据是一个挑战 (Why It’s a Challenge to Extract Tabular Data from PDF)
Today PDF is used as the basis of communication between companies, systems, and individuals. It is regarded as the standard for finalized versions of documents as it is not easily editable except in fillable PDF forms. Most popular use cases for PDF documents in the business environment are:
今天,PDF用作公司,系统和个人之间进行交流的基础。 它被认为是文档定稿版本的标准,因为除了可填写的PDF表格外,它不容易编辑。 在业务环境中,PDF文档的最流行用例是:
- Invoices 发票
- Purchase Orders 订单
- Shipping Notes 运输注意事项
- Reports 报告书
- Presentations 简报
- Price & Product Lists 价格和产品清单
- HR Forms 人力资源表格
The sheer volume of information exchanged in PDF files means that the ability to extract data from PDF files quickly and automatically is essential. Spending time extracting data from PDFs to input into third party systems can be very costly for a company.
PDF文件中大量的信息交换意味着快速,自动地从PDF文件提取数据的能力至关重要。 花费时间从PDF提取数据以输入到第三方系统对于公司而言可能是非常昂贵的。
The main problem is that PDF was never really designed as a data input format, but rather, it was designed as an output format ensuring that data will look the same at any device and be printed correctly. A PDF file defines instructions to place characters (and other components) at precise x,y coordinates. Words are simulated by placing some characters closer than others. Spaces are simulated by placing words relatively far apart. As for tables — you are right — they are simulated by placing words as they would appear in a spreadsheet.
主要问题是PDF从来没有真正设计成数据输入格式,而是设计成输出格式,以确保数据在任何设备上看起来都一样并且可以正确打印。 PDF文件定义了将字符(和其他组件)放置在精确的x,y坐标处的指令。 通过将某些字符放置得比其他字符更近来模拟单词。 通过将单词相对分开放置来模拟空间。 至于表,您是对的,它们是通过像在电子表格中一样放置单词来模拟它们的。
We see that the PDF format has no internal representation of a table structure, which makes it difficult to extract tables for analysis. Unfortunately, a lot of open data is stored in PDFs, which was not designed for tabular data in the first place.
我们看到PDF格式没有表结构的内部表示,这使得提取表进行分析变得很困难。 不幸的是,许多开放数据存储在PDF中,而这些数据最初并不是为表格数据而设计的。
Luckily, different tools for extracting data from PDF tables are available in the market. Being somewhat similar to each other, they have their own advantages and disadvantages. In this article, we compare the most popular software that can help get tabular data out of PDFs and present it in an easy-to-read, editable, and searchable format.
幸运的是,市场上有多种用于从PDF表提取数据的工具。 它们彼此有点相似,但各有优缺点。 在本文中,我们将比较最流行的软件,该软件可以帮助从PDF中获取表格数据,并以易于阅读,可编辑和可搜索的格式显示它们。
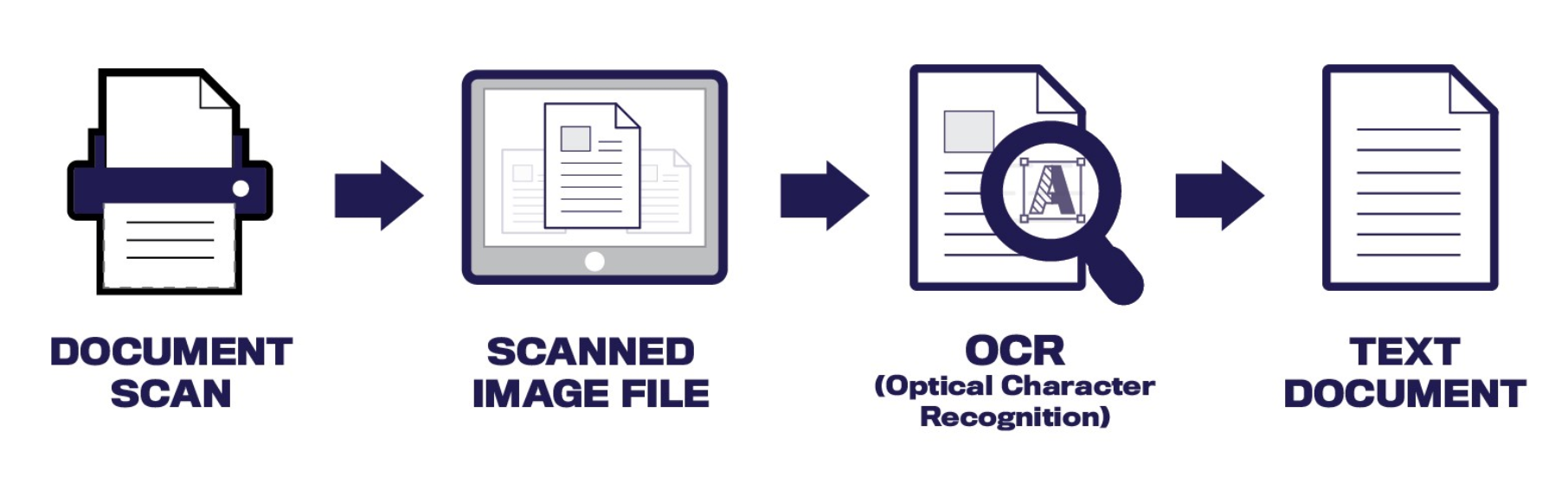
OCR:何时以及为什么使用它 (OCR: When and Why to Use It)
Before choosing a tool, the first point is to understand what type of PDF files — text- or image-based — you will work with. It will impact on whether to use Optical Character Recognition (OCR) or not.
在选择工具之前,首先要了解您将使用哪种类型的PDF文件(基于文本或图像)。 这将影响是否使用光学字符识别(OCR)。
For example, we have a report generated as an output by a piece of software and imported in PDF format. Commonly, it is a text-based PDF.
例如,我们有一个报告,它是由一个软件生成的输出,并以PDF格式导入。 通常,它是基于文本的PDF。
If you work with image-based PDFs like scanned paper docs, or, for example, files captured by a digital camera — this is where OCR comes in. OCR enables machines to recognize written text or printed letters inside images. In other words, the technology helps to convert ‘text-as-an-image’ into an editable and searchable format.
如果您使用基于图像的PDF(例如,扫描的纸张文档),或者使用数码相机捕获的文件,则可以使用OCR。OCR使机器可以识别图像中的文字或印刷字母。 换句话说,该技术有助于将“文本图像”转换为可编辑和可搜索的格式。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2069
2069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









