





azure关机后不收费?
DataOps practices are rapidly being adopted by data focused companies, especially those that are migrating to Cloud Data Warehouses. A few tools have emerged in recent years to support DataOps, such as the data build tool or dbt. Conceived and developed by Fishtown Analytics, dbt is a command line tool, that runs the data transformations in an Extract, Load, Transform (ELT) pipeline. It borrows a few of its core principles from the world of DevOps and Software Engineering and has a different approach to SQL development than most Data Engineers are used to.
d ataOps做法Swift被采纳的数据中心的公司,尤其是那些迁移到云数据仓库 。 近年来出现了一些支持DataOps的工具 ,例如数据构建工具或dbt。 构思和所开发Fishtown分析 ,DBT是一个命令行工具,运行数据转换在E XTRACT,L OAD,T ransform(ELT)管道。 它借鉴了DevOps和软件工程领域的一些核心原则,并且与大多数数据工程师习惯使用SQL开发方法不同。
DBT comes with an Apache License and typically runs in Continuous Integration and Deployment (CI/CD) pipelines or from dbt Cloud. The latter is a hosted version of the software and is offered by Fishtown Analytics with three distinct pricing plans. Batch processing workloads especially for analytics which are typical for dbt, do not require anything more than a CI/CD execution model.
DBT带有一个Apache许可和通常运行用C ontinuous 我 ntegration和d eployment(CI / CD)管线或从DBT云 。 后者是该软件的托管版本,由Fishtown Analytics提供,具有三种不同的定价计划 。 批处理工作负载(尤其是dbt的典型分析)尤其需要CI / CD执行模型。
In a recent project I was working on, we needed to use dbt in a near real-time scenario. The solution had an event-driven architecture with a Snowflake backend and Azure Functions responding to events. The challenge was to trigger dbt in near real time, with messages sent to an Azure Storage Queue by another Function. Each message contained information about data transformations, that had to execute immediately after the data was loaded. A CI/CD pipeline was out of the question here, since it is more suited to a batch process. So we had to develop an Azure Trigger Function that was running dbt. In the next few paragraphs I will show you how to do that, with a step by step guide.
在我最近从事的项目中,我们需要在接近实时的情况下使用dbt。 该解决方案具有事件驱动的体系结构,该体系结构具有Snowflake后端和响应事件的Azure功能。 面临的挑战是通过另一个功能将消息发送到Azure存储队列中,以接近实时的方式触发dbt。 每个消息都包含有关数据转换的信息,这些信息必须在数据加载后立即执行。 CI / CD管道在这里是不可能的,因为它更适合于批处理。 因此,我们必须开发一个正在运行dbt的Azure触发器功能。 在接下来的几段中,我将逐步指导您如何做到这一点。
So let’s dive straight in!
因此,让我们直接潜水吧!
让我们从DBT基础开始 (Let’s Start with DBT Basics)
I am not a Data Engineer but my first experience with dbt was a year ago, purely out of curiosity. At that point, there were only a few companies using it, with a couple of demo videos from Monzo Bank and Gitlab. Last time I checked, Fishtown Analytics had an announcement on their front page, for a Series A investment of $12.9M and a much greater and admittedly impressive list of companies, that are currently using their product. This shows how quickly DataOps tools like this are adopted by the industry and become standard practice. But what exactly does it do?
我不是数据工程师,但我最初在dbt上的经历是一年前,纯粹出于好奇。 那时,只有少数公司在使用它,还有Monzo Bank和Gitlab的一些演示视频。 上次我检查时,Fishtown Analytics在他们的首页上发布了一个公告,称其进行了1290万美元的A轮投资,并且拥有更多并令人印象深刻的公司清单,这些公司目前正在使用其产品。 这说明了像这样的DataOps工具被业界采用并成为标准实践的速度。 但是它到底是做什么的呢?
DBT is a command line tool written in Python, and uses SQL, Jinja scripting and macros to express data transformations. It comes with built-in connectors to popular Cloud Data Warehouses such as Snowflake, Redshift or Google BigQuery. Data Engineers develop their code in structured projects initialised by a dbt CLI command, and each project consists of folders with all the models, macros, ad-hoc queries, tests and more. From first glance a dbt project looks similar to any software project.
DBT是用Python编写的命令行工具,它使用SQL,Jinja脚本和宏来表示数据转换。 它带有内置连接器,可以连接流行的Cloud Data Warehouse,例如Snowflake, Redshift或Google BigQuery 。 数据工程师在由dbt CLI命令初始化的结构化项目中开发代码,每个项目都由包含所有模型,宏,即席查询,测试等的文件夹组成。 乍一看,dbt项目看起来类似于任何软件项目。

Projects can be set up to run against different databases and schemas, and with different roles and users. All of this is configured in a profiles.yml file, that serves similarly to a package.json from the world of Node.js development.
可以将项目设置为针对不同的数据库和架构,不同的角色和用户运行。 所有这些都在profiles.yml文件中配置,该文件的功能类似于Node.js开发领域的package.json 。
A common execution model for dbt is to run an Azure DevOps or Gitlab pipeline, that first installs dbt, runs some tests and then triggers the data transformations. The dbt command line offers a few options such as the execution of specific models or the grouping of models using a tagging system. This allows us to run transformations on specific tables and views without affecting the rest of the database. Model selection is useful functionality, that can be leveraged in a number of use cases such as an event-driven architecture.
dbt的常见执行模型是运行Azure DevOps或Gitlab管道,该管道首先安装dbt,运行一些测试,然后触发数据转换。 dbt命令行提供了一些选项,例如执行特定模型或使用标记系统对模型进行分组。 这使我们可以在特定的表和视图上运行转换,而不会影响数据库的其余部分。 模型选择是有用的功能,可以在许多用例(例如事件驱动的体系结构)中加以利用。
模型选择和标记 (Model Selection and Tagging)
Before delving deeper into model selection, it is important to understand first of all what a model is. Model files in a dbt project are fundamental components, where engineers develop all their data transformations. They contain a mixture of SELECT statements, Jinja macros and configuration parameters. When dbt runs a model, database tables and views get refreshed or incrementally updated. Configuration parameters define the type of model used, database schema, tags and more. Tags are a useful mechanism for grouping together a set of models. For example, you could have 3 model files that are related to a Customer order. With a single tag="CUSTOMER" you can run the transformations for all 3 models and update 3 distinct tables without having to run separate scripts or SQL statements.
在深入研究模型选择之前,重要的是首先了解什么是模型。 dbt项目中的模型文件是基本组件,工程师可以在其中开发所有数据转换。 它们包含SELECT语句,Jinja宏和配置参数的混合。 dbt运行模型时,数据库表和视图将得到刷新或增量更新。 配置参数定义使用的模型的类型,数据库架构,标签等。 标签是将一组模型组合在一起的有用机制。 例如,您可能有3个与客户订单相关的模型文件。 使用单个tag="CUSTOMER"您可以运行所有3个模型的转换并更新3个不同的表,而不必运行单独的脚本或SQL语句。
Below is an example of a model file that selects customer information from a raw source and into a target schema and table that are defined in a profile file.
下面是一个模型文件的示例,该模型文件从原始源中选择客户信息,并选择概要文件中定义的目标模式和表。
{{
config(
materialized='incremental',
schema='RAW',
tags='CUSTOMER'
)
}}
with source as (
select * from {{ ref('raw_customers') }}
),
renamed as (
select
id as customer_id,
first_name,
last_name,
email
from source
)
select * from renamedThe dbt CLI by default runs all models that reside within the models folder, however it is possible to select a specific model or a set of models using tags.
缺省情况下,dbt CLI运行驻留在models文件夹中的所有模型,但是可以使用标签选择特定模型或一组模型。
# DBT Model Selection Syntax
# runs a specific model
dbt --warn-error run --model customer_order
# runs all models with the customer tag
dbt --warn-error run --model tag:customer使用消息触发DBT (Triggering DBT with Messages)
The Microsoft Azure infrastructure supports Serverless Computing with different types of Azure Functions, that can be triggered by events or messages raised on the platform and HTTP requests. Fully automated data pipelines can benefit from these features and implemented using an event-driven approach. It is important to make a distinction here between an event and a message. An event is a lightweight notification of a condition or state change, where a message is data produced by a service such as an Azure Function.
Microsoft Azure基础结构通过各种类型的Azure功能支持无服务器计算,这可以由平台上引发的事件或消息以及HTTP请求触发。 全自动数据管道可以从这些功能中受益,并可以使用事件驱动的方法来实施。 在此处区分事件和消息很重要。 事件是状态或状态更改的轻量级通知,其中消息是由诸如Azure功能之类的服务产生的数据。
With an event-driven architecture, events are raised when data lands in Cloud storage such as Azure Blob Containers and with an event subscription send them to an Azure Storage Queue. An Azure Function is constantly listening to this queue and once it retrieves an event, it triggers a new workload based on the information received.
通过事件驱动的体系结构,当数据降落到诸如Azure Blob容器之类的云存储中时会引发事件,并通过事件订阅将事件发送到Azure存储队列 。 Azure功能不断监听此队列,一旦检索到事件,它就会根据收到的信息触发新的工作负载。

Azure Storage Queues are a reliable mechanism for accumulating events and messages, and dispatching them to Azure Functions. In some use cases, multiple queues can be in place, that allow the Functions to communicate with each other.
Azure存储队列是一种可靠的机制,用于累积事件和消息,并将其分配给Azure Functions。 在某些用例中,可以放置多个队列,以使功能可以相互通信。
In our example, an Azure Function that performs the loading part of our ELT pipeline sends a message to a dbt queue, which subsequently triggers data transformations for a specific model or tag. To create a Storage Queue, we simply have to use the Azure portal as seen below.
在我们的示例中,执行ELT管道的加载部分的Azure函数将消息发送到dbt队列,该队列随后触发特定模型或标记的数据转换。 要创建存储队列,我们只需使用Azure门户,如下所示。

创建Azure触发器功能 (Creating an Azure Trigger Function)
Once the queue is in place, we continue by creating an Azure Queue Storage Trigger Function, using Visual Studio Code and the Microsoft Azure Functions extension.
队列到位后,我们将使用Visual Studio代码和Microsoft Azure Functions扩展来创建Azure队列存储触发函数。

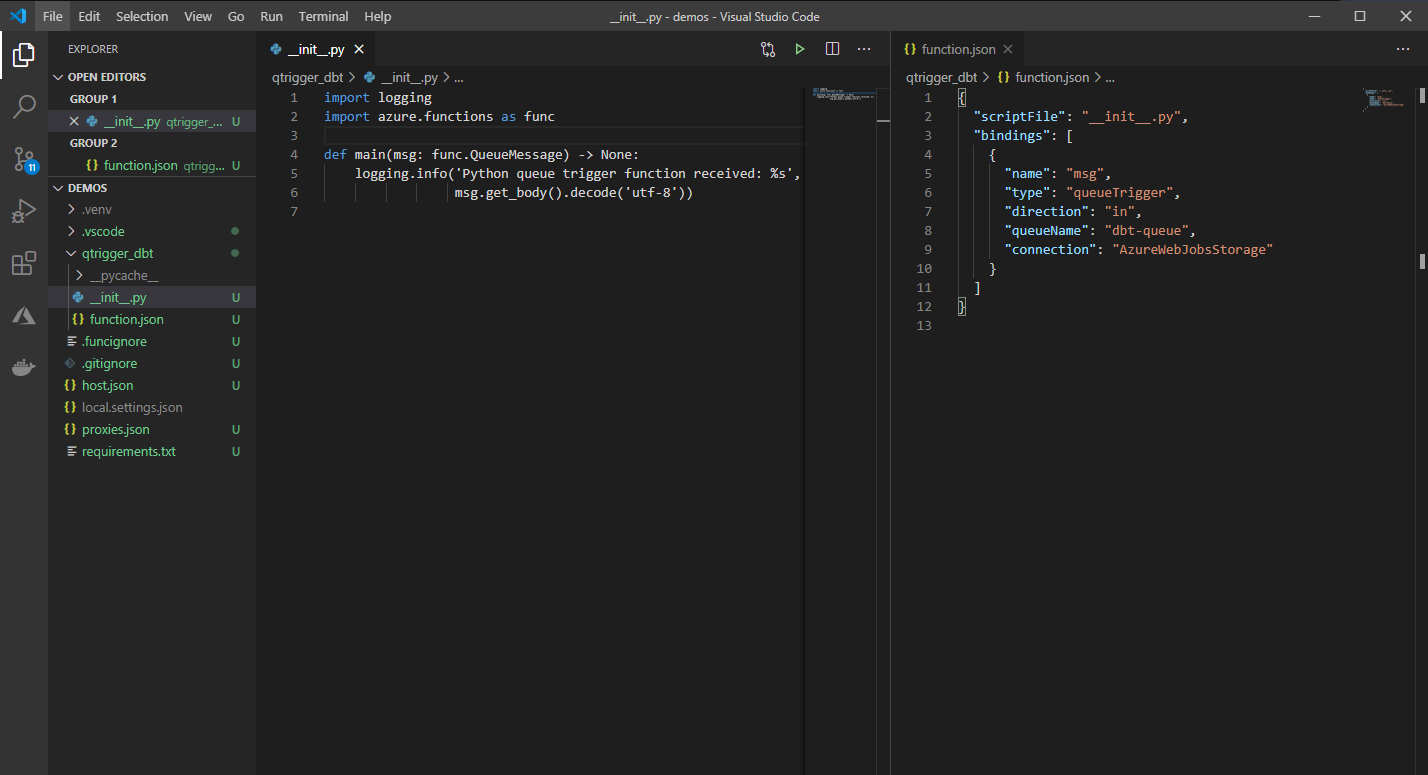
Once the Azure Function is created, we wire in the queue that our Function will be listening to for new messages. At that point, the project should have a main function that handles incoming events and a function.json that has the trigger bindings as can be seen below.
创建Azure功能后,我们将排队我们的功能将侦听新消息的队列。 到那时,该项目应该具有一个处理传入事件的main函数和一个具有触发器绑定的function.json ,如下所示。
在Azure功能中添加DBT项目 (Adding the DBT Project in the Azure Function)
Typically teams have separate repositories for their dbt projects. What we want to achieve here, is to allow dbt models to run within the Azure Function we created. One way to do that, is to add the dbt project as a git submodule in the Azure Function project. That way any changes made to the dbt project by the Data Engineering team get synchronised and all models that are running in the Function are up to date. Here I am using the jaffle_shop project, a demo repository created by Fishtown Analytics.
通常,团队为他们的dbt项目有单独的存储库。 我们要在这里实现的是允许dbt模型在我们创建的Azure Function中运行。 一种方法是,将dbt项目添加为Azure Function项目中的git submodule 。 这样,数据工程团队对dbt项目所做的任何更改都会同步,并且该功能中运行的所有模型都是最新的。 在这里,我使用的是jaffle_shop项目,这是Fishtown Analytics创建的演示存储库。

As it stands, there is no Python API for dbt, so the most robust way to run it is to create a subprocess Popen wrapper. A simple runner class is all that is needed, with a method that accepts as parameters the models and tags to be used. Below is a snippet of the DBTRunner class and the exec_dbt method that uses as an execution profile the profiles.yml, that sits at the root of our project. You can find the rest of the source code for the Function here.
就目前而言,没有针对dbt的Python API,因此运行它的最可靠的方法是创建一个subprocess Popen包装器。 只需一个简单的运行器类,即可使用要使用的模型和标签作为参数的方法。 下面是DBTRunner类和exec_dbt方法的代码片段,该方法将profiles.yml用作执行配置profiles.yml ,位于我们项目的根目录。 您可以在此处找到该函数的其余源代码。
import os
import re
import logging
from subprocess import PIPE, Popen
class DBTRunner():
#
# Initialisation code goes here
#
def exec_dbt(self, args=None):
if args is None:
args = ["run"]
final_args = ['dbt']
final_args.append('--single-threaded')
final_args.extend(args)
final_args.extend(['--profiles-dir', "../."])
log_lines = []
with Popen(final_args, stdout=PIPE) as proc:
for line in proc.stdout:
line = line.decode('utf-8').replace('\n', '').strip()
line = self.ansi_escape.sub('', line)
log_lines.append(line)
self.logger.info(line)Profile files contain connectivity information to the database and schema to be used when running dbt. All these parameters can be passed as environment variables and defined in such a way, so that they do not get exposed.
配置文件包含运行dbt时要使用的数据库和架构的连接信息。 所有这些参数都可以作为环境变量传递并以这种方式定义,以使它们不会暴露出来。
jaffle:
outputs:
dev:
# specify the snowflake connection
type: snowflake
threads: 1
account: "{{ env_var('DBT_ACCOUNT') }}"
user: "{{ env_var('DBT_USER') }}"
password: "{{ env_var('DBT_PASSWORD') }}"
role: "{{ env_var('DBT_ROLE') }}"
database: "{{ env_var('DBT_DB') }}"
warehouse: "{{ env_var('DBT_WAREHOUSE') }}"
schema: "{{ env_var('DBT_SCHEMA') }}"
target: devEvery Azure Function contains application settings that are passed as environment variables to our code and eventually replace the variables seen above. The Trigger Function is now ready to process incoming messages and run the dbt models.
每个Azure函数都包含应用程序设置,这些设置作为环境变量传递到我们的代码中,并最终替换上面看到的变量。 现在,触发器功能已准备就绪,可以处理传入消息并运行dbt模型。
设置Azure功能部署 (Setting up the Azure Function Deployment)
When dbt runs, it generates logging information and compiles code to the target SQL, that will execute in Snowflake or any other database we have chosen. This presents a challenge when running dbt in a container environment such as an Azure Function, since you will have permission issues, that will block the execution of your models and generate errors in the logs.
dbt运行时,它将生成日志记录信息并将代码编译到目标SQL,这些代码将在Snowflake或我们选择的任何其他数据库中执行。 在诸如Azure Function之类的容器环境中运行dbt时,这会带来挑战,因为您将遇到权限问题,这将阻止模型的执行并在日志中生成错误。
DBT projects contain a dbt_project.yml file, that has definitions for all the paths that are necessary. Before setting up any deployment, it is crucial to set up these paths by using the temp folders on our host Linux server. The project file should look similar to the YAML below with all the paths pointing to the Linux temp folder.
DBT项目包含dbt_project.yml文件,该文件具有所有必需路径的定义。 在设置任何部署之前,至关重要的是使用主机Linux服务器上的temp文件夹设置这些路径。 该项目文件应类似于下面的YAML ,所有路径都指向Linux temp文件夹。
# Project names should contain only lowercase characters and underscores.
# A good package name should reflect your organization's
# name or the intended use of these models
name: 'jaffle_shop'
version: '0.0.1'
# This setting configures which "profile" dbt uses for this project.
profile: 'jaffle'
# These configurations specify where dbt should look for different types of files.
# The `source-paths` config, for example, states that models in this project can be
# found in the "models/" directory. You probably won't need to change these!
source-paths: ["models"]
analysis-paths: ["analysis"]
test-paths: ["tests"]
data-paths: ["data"]
macro-paths: ["macros"]
log-path: '/tmp/dbt_log/'
target-path: "/tmp/dbt_target/" # directory which will store compiled SQL files
modules-path: "/tmp/dbt_modules/"
clean-targets: # directories to be removed by `dbt clean`
- "/tmp/dbt_target/"
- "/tmp/dbt_modules/"
- "/tmp/dbt_log/"
models:
materialized: view
jaffle_shop:
pre-hook: " alter session set TIMEZONE = 'GMT'"Now all the components are in place and we are ready to create an Azure DevOps build pipeline. The pipeline will install dbt and other libraries as defined in the requirements.txt file, build a Docker image and push it to our registry with an Azure DevOps connection svc-demo-docker-reg .
现在所有组件都就位,我们准备创建Azure DevOps构建管道。 管道将按照requirements.txt文件中的定义安装dbt和其他库,构建Docker映像,并使用Azure DevOps连接svc-demo-docker-reg将其推送到我们的注册表中。
# Python Build, Test and Publish Pipeline
#
#
# Add steps that build, run tests, deploy, and more:
# https://aka.ms/yaml
# Pipeline-level variables
variables:
workingDirectory: '$(System.DefaultWorkingDirectory)'
trigger:
- master
jobs:
- job: Build
pool:
vmImage: 'ubuntu-latest'
steps:
- task: UsePythonVersion@0
displayName: "Use Python version 3.7"
inputs:
versionSpec: '3.7'
architecture: 'x64'
- checkout: self # self represents the repo where the initial Azure Pipelines YAML file was found
displayName: 'Checkout'
submodules: true
- bash: pip install -r $(workingDirectory)/requirements.txt
displayName: 'Install Requirements'
workingDirectory: $(workingDirectory)
- task: Docker@2
displayName: Build and push the new image
inputs:
command: buildAndPush
repository: 'funcapp-dbt-trigger'
dockerfile: 'Dockerfile'
containerRegistry: 'svc-demo-docker-reg'
tags: |
$(Build.BuildId)最后一步 (The Final Step)
Before deploying the Azure Function, we need to create a Function App that serves as the host for multiple Azure Functions and sits within a specified resource group and geographical region. We simply select the subscription, resource group, name and region, and specify the deployment type to be Docker Container. We chose Docker Container here, since we found it to be the most reliable method for installing and running dbt in the Function.
在部署Azure功能之前,我们需要创建一个功能应用,该应用充当多个Azure功能的主机,并位于指定的资源组和地理区域内。 我们只需选择订阅,资源组,名称和区域,然后将部署类型指定为Docker Container即可 。 我们在这里选择了Docker Container,因为我们发现它是在Function中安装和运行dbt的最可靠方法。

Once the Function App is provisioned, we set up an Azure DevOps release pipeline to deploy our previously built Docker image. Below I am showing you an overview of the release pipeline and the main job with the App Service Deploy Task plugged in.
设置功能应用程序后,我们将建立Azure DevOps发布管道以部署我们先前构建的Docker映像。 下面,我向您展示发布管道的概述以及插入了App Service Deploy Task的主要工作。


Now that we have our Azure Function deployed and running, it is time to run some tests. The jaffle shop project contains some dummy data and models, that represent customers and orders in a fictional online shop. Let’s assume that another Azure Function has done all the data loading and is now sending a message for customer orders to be updated with some transformations. We will simulate that by adding a message to the dbt-queue .
现在我们已经部署并运行了我们的Azure功能,现在该运行一些测试了。 Jaffle Shop项目包含一些虚拟数据和模型,它们代表虚构的在线商店中的客户和订单。 假设另一个Azure Function完成了所有数据加载,现在正在发送一条消息,要求通过一些转换来更新客户订单。 我们将通过向dbt-queue添加一条消息来模拟这一点。

As soon as the message gets added, our Function gets triggered and dbt starts to run. It selects the stg_orders model and successfully runs all the transformations. Admittedly this is a very simple example but the set up works for very large projects and can easily be extended.
一旦添加了消息,我们的函数就会被触发并且dbt开始运行。 它选择stg_orders 建模并成功运行所有转换。 诚然,这是一个非常简单的示例,但是该设置适用于非常大的项目,并且可以轻松扩展。

结论 (Conclusion)
DBT is a powerful data transformation tool, that will — “no pun intended” — transform the way your data engineering team works. It has a steep learning curve and requires patience to begin with, especially for teams that are not accustomed to DataOps practices. Wiring dbt in Azure Functions and executing models based on incoming events is a powerful mechanism, that can be used in a lot of interesting scenarios. If you want to know more about the Azure set up or have any questions, please feel free to reach out.
DBT是功能强大的数据转换工具,它将“无双关” —改变您的数据工程团队的工作方式。 它具有陡峭的学习曲线,并且需要耐心地开始,尤其是对于不习惯于DataOps实践的团队。 在Azure Functions中连接dbt并根据传入事件执行模型是一种强大的机制,可以在许多有趣的情况下使用。 如果您想了解有关Azure设置的更多信息或有任何疑问,请随时与我们联系。
azure关机后不收费?















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









