





气流预测网站
Deploy Operators and DAGs to a AWS hosted Apache Airflow and execute your Data Pipelines with DAG and Data Lineage Visualisation.
将操作员和DAG部署到AWS托管的Apache Airflow,并通过DAG和数据沿袭可视化执行数据管道。
是否想偶尔听到有关Tensorflow,Keras,DeepLearning4J,Python和Java的抱怨? (Wanna hear occasional rants about Tensorflow, Keras, DeepLearning4J, Python and Java?)

Join me on twitter @ twitter.com/hudsonmendes!
和我一起在twitter @ twitter.com/hudsonmendes上!
Taking Machine Learning models to production is a battle. And there I share my learnings (and my sorrows) there, so we can learn together!
将机器学习模型投入生产是一场战斗。 我在那里分享我的学习(和悲伤),所以我们可以一起学习!
数据科学系列的数据管道 (Data Pipeline for Data Science Series)
This is a large tutorial that we tried to keep conveniently small for the occasional reader, and is divided into the following parts:
这是一个很大的教程,我们试图为偶尔阅读的读者提供一些便利,并且将其分为以下几部分:
Part 1: Problem/Solution FitPart 2: TMDb Data “Crawler”Part 3: Infrastructure As CodePart 4: Airflow & Data Pipelines
(soon available) Part 5: DAG, Film Review Sentiment Classifier Model
(soon available) Part 6: DAG, Data Warehouse Building
(soon available) Part 7: Scheduling and Landings
第1部分:问题/解决方案拟合第2部分:TMDb数据“抓取工具” 第三部分:基础架构即代码第4部分:气流和数据管道(即将推出)第5部分:DAG,电影评论情感分类器模型(即将推出)第6部分:DAG,数据仓库构建(即将推出)第7部分:计划和着陆
问题:通过气流部署DAG(The Problem: Deploying DAGs with Airflow)
This project has the following problem statement:
该项目具有以下问题陈述:
Data Analysts must be able to produce reports on-demand, as well as run several roll-ups and drill-down queries into what the Review Sentiment is for both IMDb films and IMDb actors/actresses, based on their TMDb Film Reviews; And the Sentiment Classifier must be our own.
数据分析师必须能够按需生成报告,并能够基于他们的TMDb电影评论,对IMDb电影和IMDb演员/女演员的评论情绪进行多次汇总和深入查询; 情感分类器必须是我们自己的。
In our Part 3 we have setup the entire Airflow & Redshift infrastructure.
在第3部分中,我们设置了整个Airflow&Redshift基础架构。
Now all we have to do is use it to run our DAGs using Airflow and deploying our Data Warehouse into AWS Redshift, so that we can run our Analytics.
现在,我们要做的就是使用它来通过Airflow运行DAG,并将数据仓库部署到AWS Redshift中,以便我们可以运行Analytics。
The full source code for this solution can be found at:
该解决方案的完整源代码可以在以下位置找到:
使用Jupyter部署DAG? 没有! (Deploying DAGs with Jupyter? No!)

Our code to deploy DAGs lives in a Jupyter Notebook, but this choice was only done due to the explanatory nature of this project.
我们用于部署DAG的代码存在于Jupyter Notebook中,但之所以选择此选项,仅是因为该项目具有解释性。
Very Important: your code to deploy DAGs must NOT be in a Jupyter Notebook. You should instead use a Continuous Integration system such as Jenkins.
非常重要:部署DAG的代码不得位于Jupyter Notebook中。 您应该改用诸如Jenkins之类的持续集成系统。
Your Continuous Integration pipeline must cover the following:
您的持续集成管道必须包括以下内容:
- Build code 建立程式码
- Runs Lint + Static Code Analysis运行Lint +静态代码分析
- Runs Unit & Integration Tests运行单元和集成测试
- Deploys DAGs into the server将DAG部署到服务器中
共享组件(Shared Components)
The following components are used through out the DAG setup process.
在DAG设置过程中,将使用以下组件。
AWS EC2密钥对 (AWS EC2 KeyPair)
In the previous article (Part 3) we have created a very important file: the "udacity-data-eng-nano'
在上一篇文章(第3部分)中,我们创建了一个非常重要的文件:“ udacity-data-eng-nano”
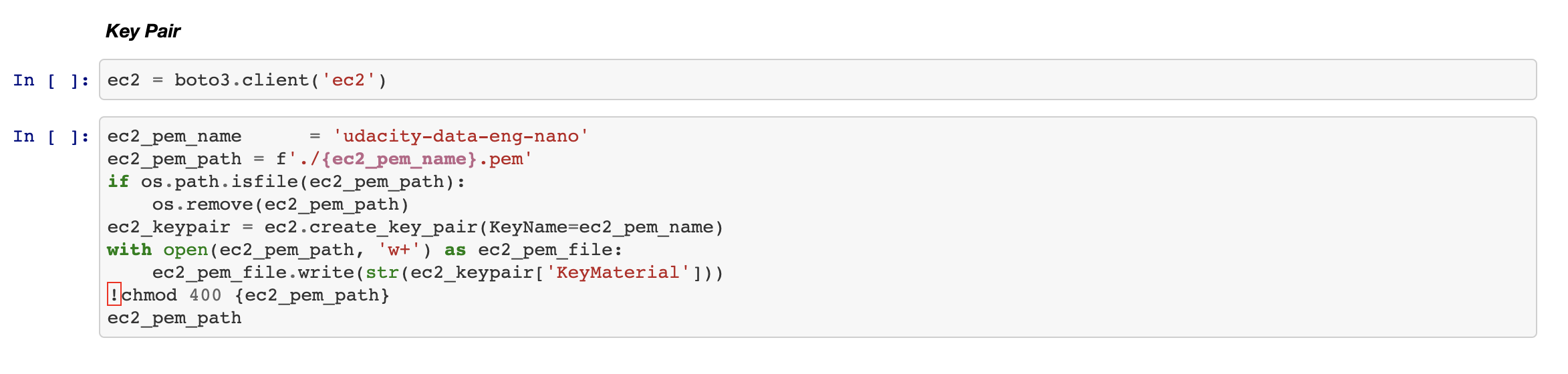
This file will now be used to SCP (copy) the DAG files into our Airflow Server.
现在,该文件将用于将DAG文件SCP(复制)到我们的Airflow Server中。
SCP上传程序 (SCP Upload Procedure)
As the next step, we have a routine that copies files from the local machine into our Airflow DAGs folder.
下一步,我们有一个例程,可将文件从本地计算机复制到Airflow DAGs文件夹中。

Once files are dropped into that folder, they are automatically picked up by Airflow, as long as there is no compilation errors!
将文件放入该文件夹后,只要没有编译错误,Airflow就会自动拾取它们!
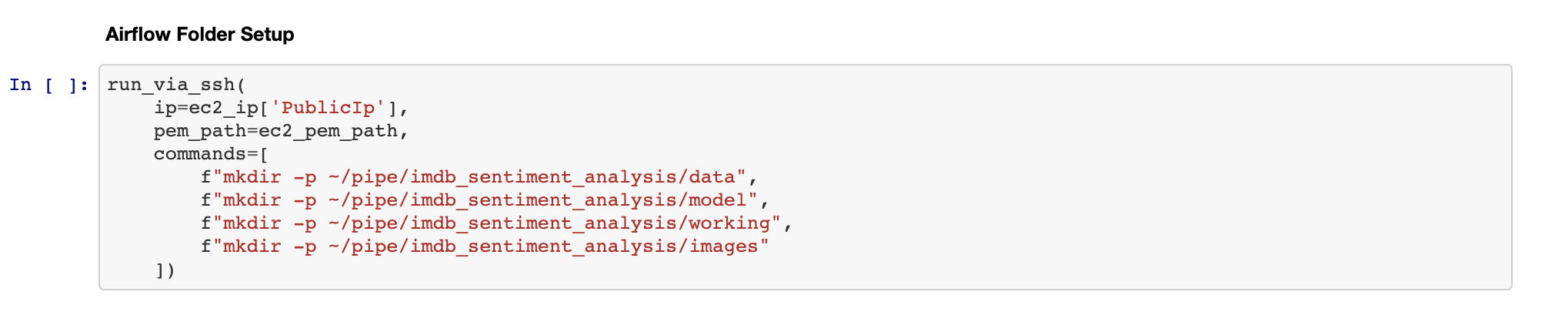
气流夹结构 (Airflow Folder Structure)
In order to run our Data Pipeline, we need a few folders created:
为了运行我们的数据管道,我们需要创建一些文件夹:
Data: where the raw data copied from HTTP sources will be dropped
数据:将从HTTP源复制的原始数据删除的位置
Model: where we placed the Tensorflow Saved Model
模型:放置Tensorflow保存模型的位置
Working: Temporary folder for files being generated
工作:临时文件夹,用于生成文件
Images: Where we place assets used in the file generated PDF report
图片:我们在文件生成的PDF报告中放置使用的资产的位置
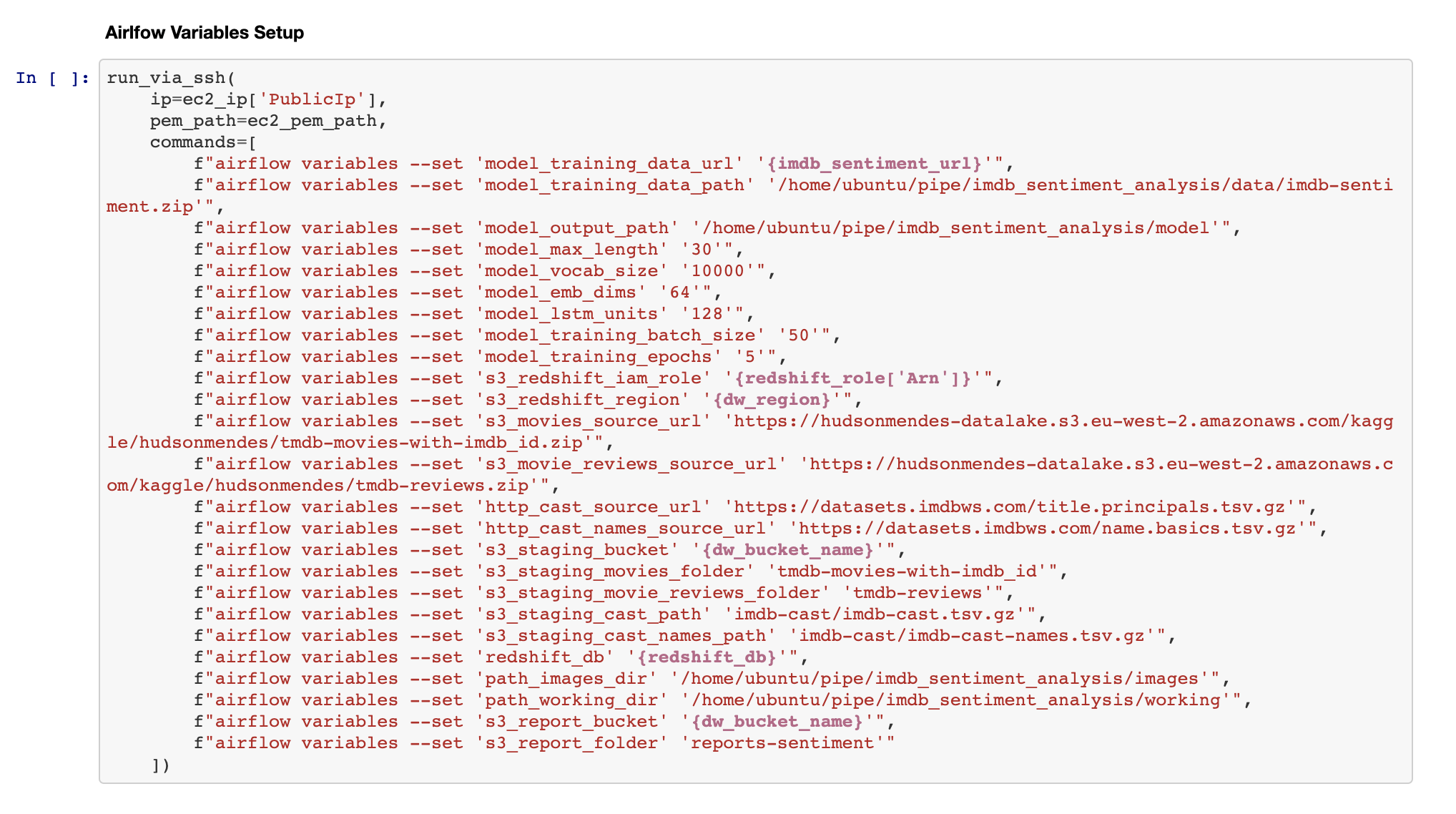
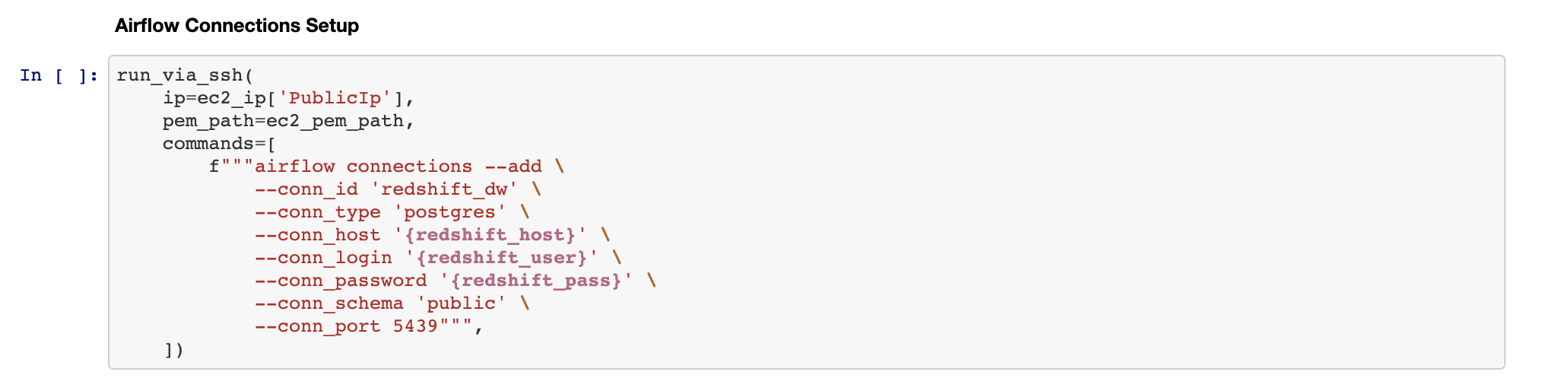
气流配置(Airflow Configuration)
Our DAGs use a number of Variables and Connections (check the Airflow documentation to understand better these definitions).
我们的DAG使用许多变量和连接(请参阅Airflow文档以更好地理解这些定义)。
Here we setup both, so that our DAGs can run:
在这里,我们都进行了设置,以便我们的DAG可以运行:
上载运算子 (Uploading Operators)
DAGs are graphs formed by operators (vertices) edged to one another. In this step we shall upload our custom operators to the DAGs folder.
DAG是由彼此相邻的算子(顶点)形成的图。 在这一步中,我们将自定义运算符上载到DAGs文件夹。

最后,上传DAG (Finally, Uploading DAGs)
The DAGS (or Directed Acyclical Graphs) are the main pieces of program in our Data Pipeline.
DAGS(或有向无环图)是我们数据管道中的主要程序。
By uploading these, should they have no compilation errors, Airflow will pick them up automatically and present them in the Airflow web interface.
通过上传这些文件(如果它们没有编译错误),Airflow会自动选择它们并将它们显示在Airflow Web界面中。

在Airflow Web界面中启动DAG (Launching DAGs in the Airflow Web Interface)
Once Airflow has recognised the DAGs, it will display them in their web interface, such as in the image below:
一旦Airflow识别出DAG,它将在其Web界面中显示它们,如下图所示:
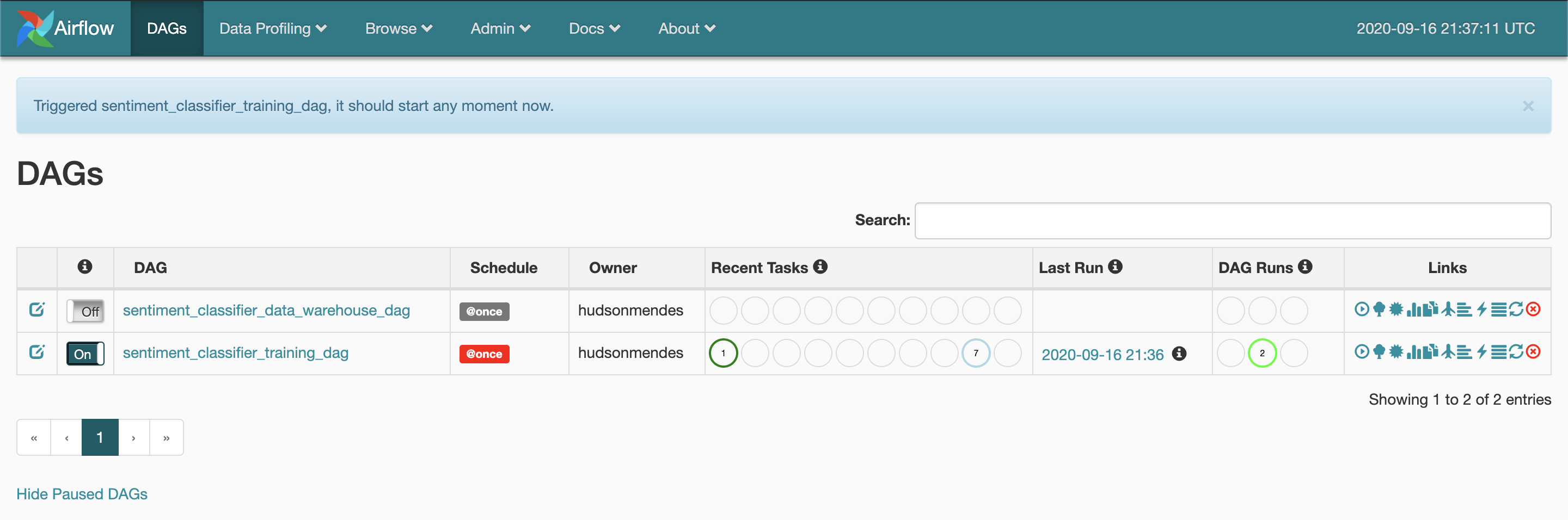
In order to launch them, you must first enable them and then click the Launch button.
为了启动它们,您必须首先启用它们,然后单击“启动”按钮。
After doing that, you can check on the DAG execution illustration and the Lineage Illustration, such as you see below:
之后,您可以检查DAG执行图和沿袭图,如下所示:
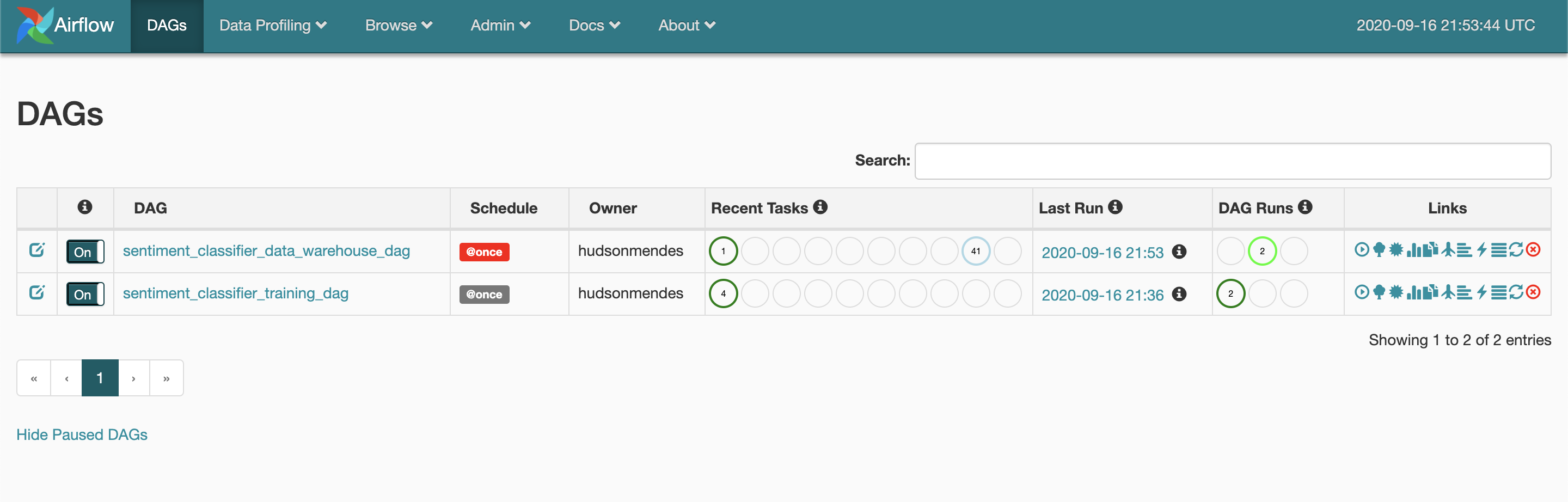
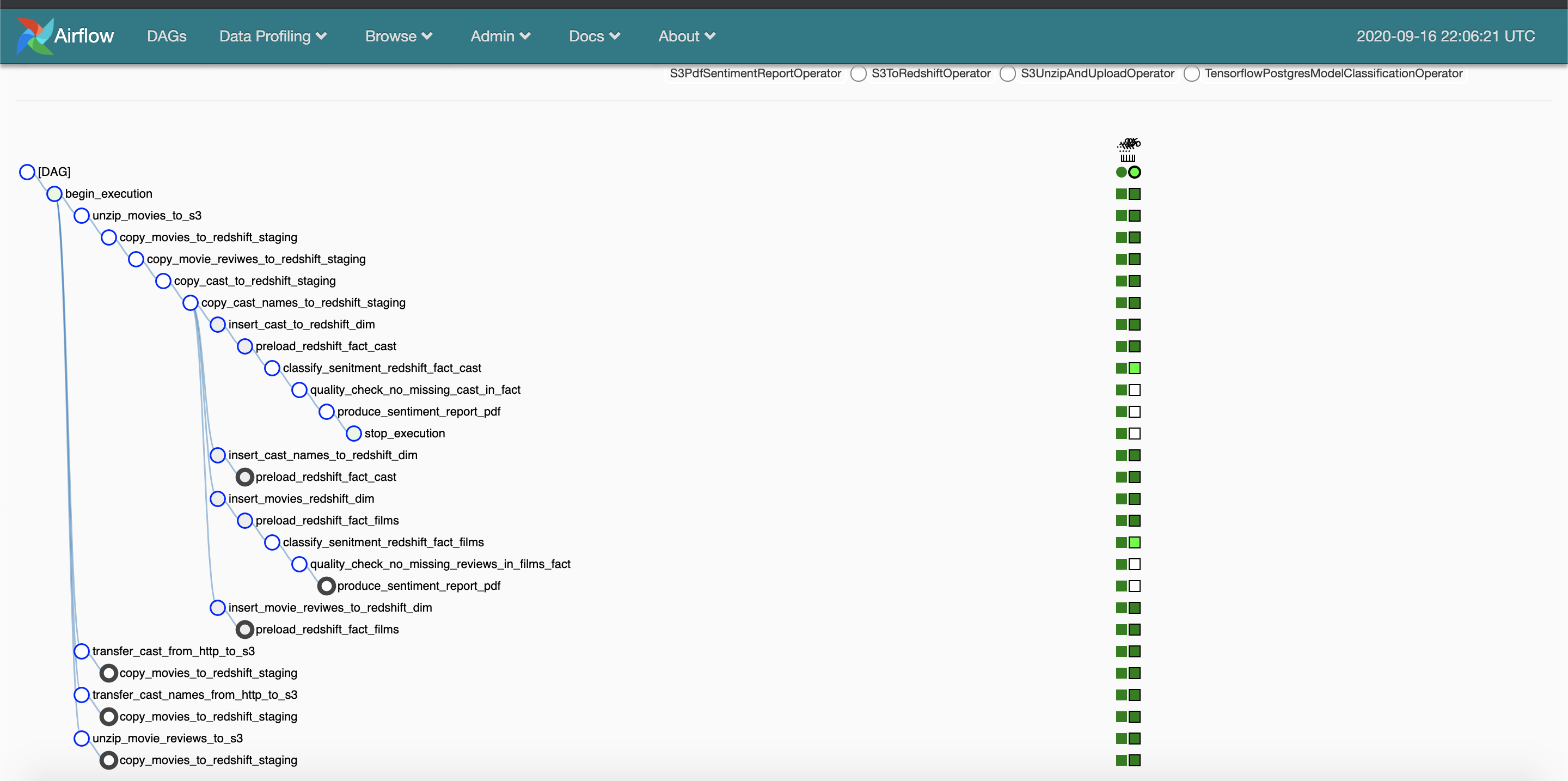
综上所述 (In Summary)
Using python, we have:
使用python,我们可以:
- Used scp to copy the DAG Operators and the DAGs 使用scp复制DAG运算符和DAG
- Used the Web Interface to Launch the Data Pipelines 使用Web界面启动数据管道
- Checked the DAG Run检查DAG运行
Now our Data Pipeline run, we have our Data Warehouse waiting for us to run queries and achieve our objective of running drill downs and roll ups in our facts table.
现在,我们的数据管道运行了,我们的数据仓库正在等待我们运行查询,并达到在事实表中运行追溯和汇总的目标。
下一步 (Next Steps)
In the next article Part 5: DAG, Film Review Sentiment Classifier Model we will understand what the Classification Model Trainer DAG does, and how we leveraged Data Science to produce our Data Warehouse.
在下一篇文章第5部分:DAG,电影评论情感分类器模型中,我们将了解分类模型训练器DAG的功能,以及我们如何利用数据科学来生产数据仓库。
Find the end-to-end solution source code at https://github.com/hudsonmendes/nanodataeng-capstone.
在https://github.com/hudsonmendes/nanodataeng-capstone中找到端到端解决方案源代码。
想保持联系吗? 推特! (Wanna keep in Touch? Twitter!)
I’m Hudson Mendes (@hudsonmendes), coder, 36, husband, father, Principal Research Engineer, Data Science @ AIQUDO, Voice To Action.
我是Hudson Mendes ( @hudsonmendes ),编码员,36岁,丈夫,父亲,数据科学@ AIQUDO的首席研究工程师,语音行动。

I’ve been on the Software Engineering road for 19+ years, and occasionally publish rants about Tensorflow, Keras, DeepLearning4J, Python & Java.
我从事软件工程工作已有19年以上,偶尔发布有关Tensorflow,Keras,DeepLearning4J,Python和Java的文章。
Join me there, and I will keep you in the loop with my daily struggle to get ML Models to Production!
加入我的行列,我将每天为使ML模型投入生产而竭尽全力!
气流预测网站















 2205
2205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









