





大数据分析师与数据分析师
In this article, I attempt to demonstrate that with a minor amount of coding experience, a bit of data background, and a pinch of study and effort —even an inexperienced individual can discover insightful information from data.
在本文中,我试图证明,以少量的编码经验,少量的数据背景以及少量的学习和努力即可—即使是没有经验的人也可以从数据中发现有见地的信息。
Just a little background which may help provide a preface:
只是一点点背景可能有助于提供序言:
I’m not an analyst.
我不是分析师。
I’m not actually technically a “data” anything…
从技术上讲,我实际上并不是任何“数据”……
My official position is a Planner. It just so happens that what I “plan” is data and data-related activities (collection, compilation, QAQC, management, and reporting)
我的正式职位是规划师。 碰巧的是,我“计划”的是数据和与数据相关的活动(收集,编译,QAQC,管理和报告)
Sometimes, it feels like I’m swimming (or drowning) in data and yet I don’t really get the opportunity to fully unravel the data to create a meaningful data product, to truly tell a story with the data I work with.
有时候,感觉就像我在游刃有余(或淹死)于数据中,但是我并没有真正获得完全解开数据以创建有意义的数据产品,用我使用的数据真正讲述故事的机会。
On that sentiment, I unknowingly embarked on a journey to get more information from the data I worked with; information that could tell a story. The journey continues but I’d like to share what I’ve experienced thus far.
因此,我在不知不觉中踏上了从我使用的数据中获取更多信息的旅程。 可以讲故事的信息。 旅程继续进行,但我想分享到目前为止的经验。
So…
所以…
像我这样的人,没有经验或没有分析师的背景,怎么能以讲故事的方式分析数据? (How does someone like me, with no experience or background as an analyst, analyze data in a way that can tell a story?)

Imaginably, there’s not one way to analyze data to extract meaningful information. This notebook is a little snapshot into my organic and yet cosmopolitan methodology, and is as follows:
我可以说,没有一种方法可以分析数据以提取有意义的信息。 这个笔记本是我有机但又国际化的方法的一个小快照,内容如下:
EDA (Exploratory Data Analysis)
EDA(探索性数据分析)
Data Wrangling/Cleaning
数据整理/清理
Visualization/Reporting
可视化/报告
There are only 3 required packages and 2 optional packages (and one unlisted optional one, whoops)
只有3个必需软件包和2个可选软件包(还有一个未列出的可选软件包,哎呀)
所需包装: (Required Packages:)
可选包装:(Optional Packages:)
This is purposeful because, unless you are a full-time data professional, you probably don’t have excess time to learn a myriad of coding techniques and packages that get touted about your favorite Medium channels and StackOverflow threads. So simplicity and directness is key.
这是有目的的,因为除非您是一名全职数据专业人员,否则您可能没有多余的时间来学习大量的编码技术和软件包,这些技术和软件包被吹捧为您最喜欢的Medium通道和StackOverflow线程。 因此,简单和直接是关键。
I’ll try to keep this brief.
我会尽量保持简短。
Alright then, shall we?
好吧,我们可以吗?
P技术1:EDA(探索性数据分析) (Part 1: EDA (Exploratory Data Analysis))

I’m not sure how to even really begin talking about EDA, which coincidentally enough is probably similar to how most non-analyst (or maybe even some analysts) feel about doing EDA.
我不知道怎么竟然真的开始谈论EDA,巧合足够大概类似于大多数非分析员(或者甚至一些分析师)感觉如何做EDA。
It can be hard to know where to begin -
很难知道从哪里开始-
but it’s not impossible…
但这并非不可能……
In fact, sometimes you just gotta start walking to get there.
实际上,有时您只是必须开始步行才能到达那里。
import pandas as pd
import numpy as np
df = pd.read_csv('your_data')
df.sample(15)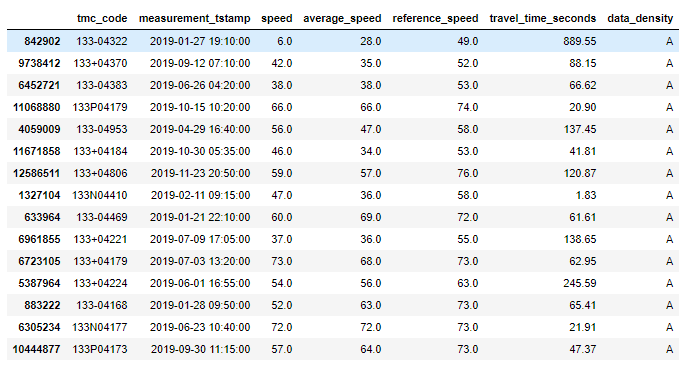
And you’re off, as it were.
和你一样,你离开了。
Now, granted it may feel overwhelming, but for me, this is the adventure of it all. It’s time to sleuth, explore, dissect, and imagine. I love patterns and puzzle-solving so I find this part riveting.
现在,尽管它可能会让您感到不知所措,但是对我而言,这是这一切的冒险。 是时候探寻,探索,剖析和想象了。 我喜欢模式和解决难题的方法,所以我发现这部分很吸引人。
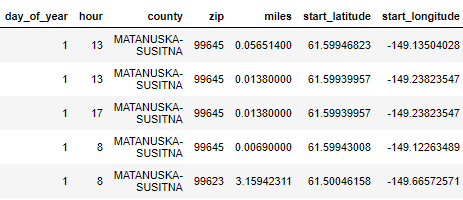
In our above example, this is actual data taken from my notebook. You don’t have to be extremely familiar with the data, transportation data, or really much of anything to understand to some degree what is happening.
在上面的示例中,这是从笔记本中获取的实际数据。 您不必非常了解数据,运输数据或任何东西,就可以在某种程度上了解正在发生的事情。
We have some sort of identifier or ID field (tmc_code), a near-datetime field (measurement_tstamp) which informs when the recording transpired, various different speed fields which are all nearly similar, an unique column dealing with travel duration (travel_time_seconds), and a bit of an odd-ball field at the end which presumably is a coded value for amount of data (data_density).
我们有某种标识符或ID字段(tmc_code),一个近日期时间字段(measurement_tstamp),该字段通知记录何时发生,各种不同的速度字段几乎都相似,一个唯一的列处理行进时间(travel_time_seconds),以及末尾的奇数球字段的一点,大概是数据量(data_density)的编码值。
不要再猜测自己了,您可能已经弄清楚了这些数据是如何工作的。 (Don’t second guess yourself, you probably already figured out how this data works.)
The tmc_code is a sort of station (in fact, raw probe) that records a number vehicles (data_density) during different timeframes (measurement_tstamp) at certain speeds (speed, average_speed, reference_speed). The amount of time it takes to travel the segment that the tmc_code is recording is travel_time_seconds.
tmc_code是一种工作站(实际上是原始探测器),它以一定的速度( speed,average_speed,reference_speed)在不同的时间段( measurement_tstamp)记录多个车辆( data_density ) 。 行进tmc_code记录的段所花费的时间为travel_time_seconds。
So data like this will provoke questions that inspire stories, questions like:
因此,像这样的数据将引发激发故事的问题,例如:
how long does it take to travel on a certain road and how often is it like that?
在某条道路上行驶需要多长时间?这样多久一次?
But we’re getting ahead of ourselves here; we can still get to know the data a lot more.
但是我们在这里取得了领先。 我们仍然可以了解更多数据。
# statistical description
df.describe()
# dataframe information
df.info()
# quick look at null values in the dataset
df.isnull().sum()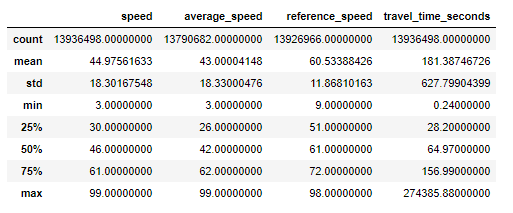
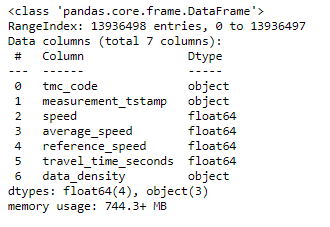
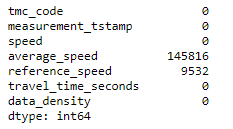
Those are fairly easy lines of codes to memorize and you can already tell a lot about this data and specifically this dataset.
这些都是很容易记住的代码行,您已经可以对这些数据,特别是该数据集进行很多介绍。
In fact, you probably noticed that:
实际上,您可能已经注意到:
- It’s a fairly big dataset (nearly 14 million rows) 这是一个相当大的数据集(近1400万行)
- It has some missing values (but nothing crazy) 它具有一些缺失的值(但没什么疯狂的)
Something odd is happening with the travel_time_seconds field (hint: look at the max value compared to the 75%)
travel_time_seconds字段发生了一些奇怪的事情(提示:查看与75%相比的最大值)
If you didn’t notice that right away, don’t fret. I’ve found that it’s one of those sort of things that once you’ve noticed it, you start to notice it everywhere.
如果您没有立即注意到这一点,请不要担心。 我发现这是其中的一种,一旦您注意到它,便开始在各处发现它。
This is probably also a good time to mention a handy tool called pandas-profiling
现在也许是提起一个名为pandas-profiling的方便工具的好时机
import pandas_profiling
# call pandas_profiling
df.profile_report()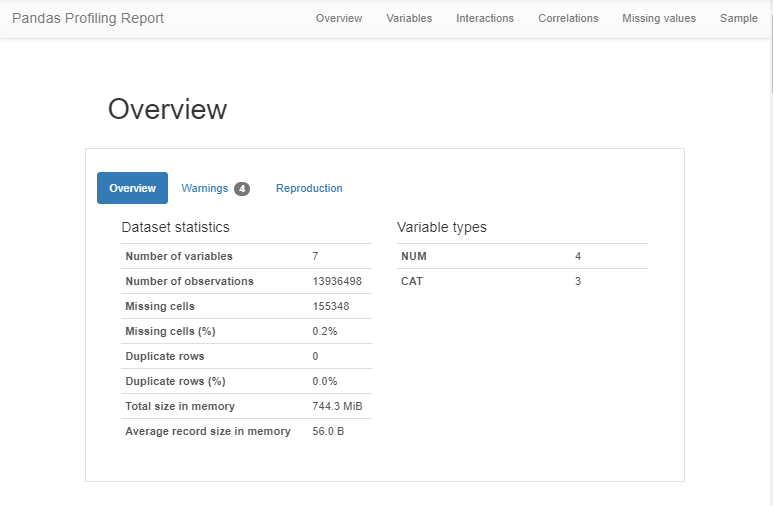
If you were second guessing yourself (don’t worry, I live there), Pandas-Profiling is an awesome tool to verify or clarify the nature or characteristics of your dataset.
如果您第二次猜测自己(不用担心,我住在这里),Pandas-Profiling是一个很棒的工具,可用来验证或阐明数据集的性质或特征。
In fact, remember how we noticed the travel_time_seconds field and its strangely large maximum value?
实际上,还记得我们如何注意到travel_time_seconds字段及其奇怪的最大值吗?
So did Pandas-Profiling:
熊猫分析也是如此:
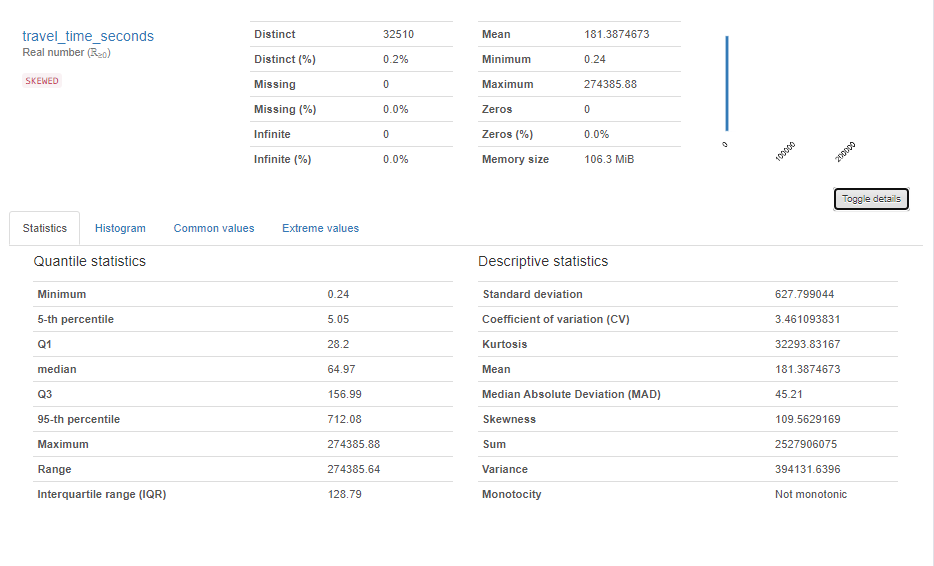
This is my data and I’ll be the first to admit that I don’t fully understand it — but I’m gonna bet that not many roads take 274385.88 seconds (or ~76.22 hours).
这是我的数据,我将是第一个承认我不完全理解的数据-但我敢打赌,没有多少道路需要274385.88秒(或〜76.22小时)。
Actually, in Alaska, the longest road is the Dalton Highway, which is 414 miles and takes about 12 hours to drive (give or take).
实际上,在阿拉斯加,最长的道路是道尔顿高速公路,该高速公路长414英里,开车或开车需要12个小时。
The longest tmc_code (which happens to be on the Dalton) is ~282 miles (length in miles present in other data.
最长的tmc_code(恰好在道尔顿上)是〜282英里(其他数据中以英里为单位的长度) 。
So something is amiss.
所以有些不对劲。
This is the part where the EDA will have its value revealed. This is the part where decisions are made.
这是EDA将会显示其价值的部分。 这是做出决定的部分。
第2部分:数据整理/清理 (Part 2: Data Wrangling/Cleaning)

Data wrangling/cleaning can be pretty intense and some pretty smart guys out there do stuff that I don’t fully understand. But I have learned enough to make things come together in a dataset.
数据争用/清理可能非常激烈,并且一些聪明的家伙在做一些我不完全了解的事情。 但是我学到了足够多的知识,可以使数据集中在一起。
Like how this dataset is unnecessarily big, or specifically, inefficient.
就像该数据集不必要地大,或者效率低下一样。
# values over 50,000 are about 14 hours, which is longer than any driving time in Alaska even with reasonable delays
# However, in other situations, it would make sense to leave those values in so use with caution
ttr_df = df.loc[df['travel_time_seconds']<50000]
# drop nulls as they are likely not consequential and will help to reduce dimensionality/size
print('dropping nulls')
ttr_df = ttr_df.dropna()
print('dropped shape: ' + str(ttr_df.shape))
print('original shape: ' + str(df.shape))
'''dropped shape: (13784065, 7)
original shape: (13936498, 7)'''
# replace string values for integers
ttr_df['data_density'].replace({"A":'1',"B":'2',"C":'3'}, inplace=True)
#create dictionary for converting values
convert_dict={'speed': int,
'average_speed': int,
'reference_speed': int,
'data_density': int}
print('converting types')
ttr_df_2= ttr_df.astype(convert_dict)
print('conversion complete')
ttr_df_2.info()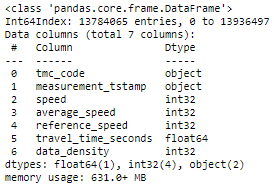
That’s better.
这样更好
But it’d be even better if we had fields to easily filter things like time and location.
但是,如果我们有可以轻松过滤时间和位置等内容的字段,那就更好了。
# transform values from measurement_tstamp to datetime
print('datetime transform')
ttr_df_2['measurement_tstamp'] = pd.to_datetime(ttr_df_2['measurement_tstamp'])
ttr_dfc = ttr_df_2
print('indexing datetime')
ttr_dfc.index = ttr_dfc['measurement_tstamp']
# some of the visualizations are greatly enhanced bythe datetime values parsed out
print('adding month/day columns for slider')
ttr_dfc['month'] = ttr_dfc['measurement_tstamp'].dt.month
ttr_dfc['day_of_year'] = ttr_dfc['measurement_tstamp'].dt.dayofyear
ttr_dfc['hour'] = ttr_dfc['measurement_tstamp'].dt.hour
convert_dict2={'month': int,
'day_of_year': int,
'hour':int}
# convert the field types
print('converting types')
ttr_dfc= ttr_dfc.astype(convert_dict2)
print('Complete')
print()
ttr_dfc.info()
# data itself does not have geographic coordinates, but the tmc's are physical locations
print('Getting Spatial data')
# add in additional sheet for getting coordinates to tmc's
tmc_df = pd.read_csv(r'TMC_Identification.csv')
# rename column for easier merging
print('renaming columns for merge')
tmc_df = tmc_df.rename(columns={'tmc':'tmc_code'})
# there are duplicates for start/end active dates, unnecessary for the scope of appending spatial values
print(tmc_df.tmc_code.count())
tmc_df.drop_duplicates(subset=['tmc_code'],inplace=True)
print(tmc_df.tmc_code.count())
# merge for future use involving mapping or geospatial components
print('Merge started')
ttf_df_xy = ttr_dfc.merge(tmc_df[['tmc_code','county', 'zip', 'miles','start_latitude','start_longitude']], on='tmc_code', how='left')
ttf_df_xy.dropna()
print('Merge complete')
convert_dict3={'start_latitude': 'float32',
'start_longitude': 'float32',
'zip': 'int32',
'miles':'float32'}
print('converting types')
ttf_df_xy= ttf_df_xy.astype(convert_dict3)
ttf_df_xy.info()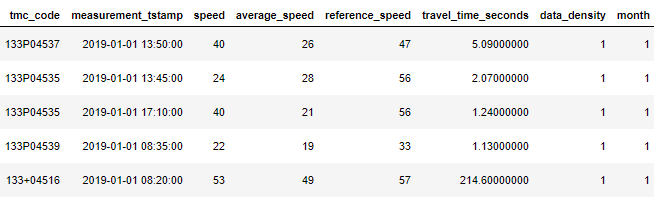
Neat.
整齐。
It’s definitely a bigger dataset now, but it’s all useful and more efficient.
现在肯定是一个更大的数据集,但它既有用又高效。
The data wrangling here is not very sophisticated and there is a lot more that we could do or do differently, but for brevity’s sake — let’s get the fun stuff.
此处处理的数据不是很复杂,还有很多我们可以做或做的不同,但是为了简洁起见,让我们获得一些有趣的东西。
第3部分:可视化/报告 (Part 3: Visualization/Reporting)
Visualization is one of my favorite parts of doing anything, as I tend to really get into aesthetics and UX concepts.
V isualization是我最喜欢做什么的地方之一,因为我倾向于真正进入美学和UX概念。
As far as visualizing large datasets (like millions of row records across thousands of features), I’m still looking for an insightful and efficient way to display such a dataset. But otherwise —
至于可视化大型数据集(例如成千上万个功能中的数百万行记录),我仍在寻找一种有见地且高效的方式来显示此类数据集。 然而在其他方面 -
You can:
您可以:
减少 (Reduce)
地图(Map)
约束 (Constrain)
ttr_df_juneau_std = ttr_df_juneau.groupby('tmc_code')['travel_time_seconds'].std().sort_values(ascending=False)Ultimately, for simplicity sake, we’re going to constrain our scope.
最终,为了简单起见,我们将限制我们的范围。
This is actually fitting because, at least in my business unit, people generally want to know about certain subsections; either by area, time, or facet.
这实际上是合适的,因为至少在我的业务部门中,人们通常希望了解某些子节。 按面积,时间或方面。
We’ll focus in on the tmc_codes with the widest or most irregular spread of values in Juneau, Alaska (my hometown).
我们将重点介绍阿拉斯加朱诺(我的家乡)中值分布最广或最不规则的tmc_code。
那么……我们如何可视化这些潜在的不可靠tmc_codes? (So… How can we visualize these potentially unreliability tmc_codes?)
Visualizations with Plotly Express makes it very simple and direct, which is perfect for when you’re just assessing things and feeling out the edges
V isualizations与Plotly快递 使其非常简单直接,非常适合当您只是评估事物并感觉到边缘时
- with animations带有动画
print('creating line graph')
fig = px.line(ttr_df_juneau, x="hour",
y="travel_time_seconds",
color='tmc_code',
log_y=True,
title='TTR',
animation_frame='day_of_year',
line_group="county",
hover_name="tmc_code",
hover_data=['tmc_code','miles','travel_time_seconds'],
line_shape="spline", render_mode="svg")
fig.show()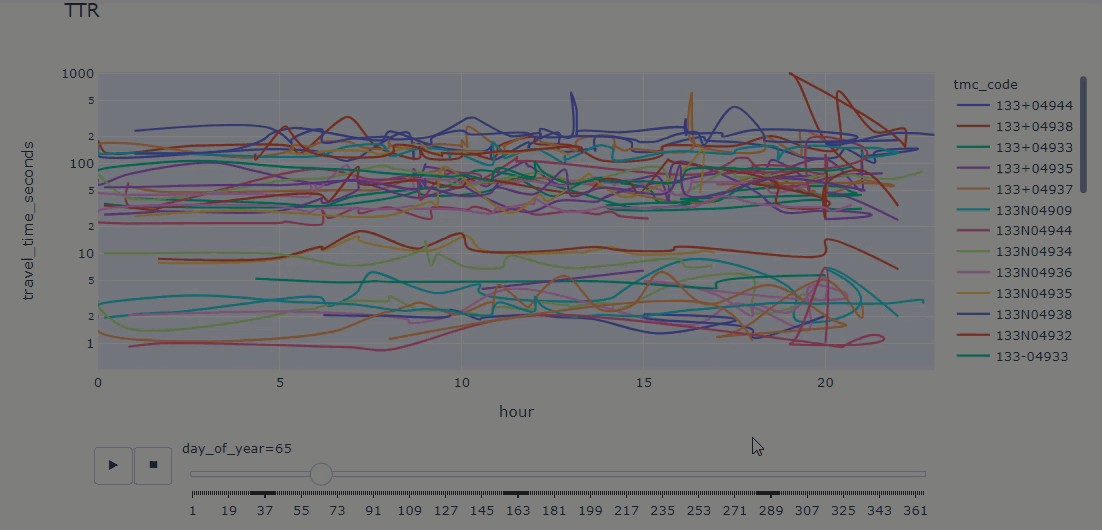
- interactive visualizations of different plots不同地块的交互式可视化
ttr_df_juneau_delay = ttr_df_juneau.loc[ttr_df_juneau['tmc_code'].isin(['133-04910', '133+04911', '133-04911', '133+04912'])]
ttr_df_juneau_delay.tmc_code.value_counts()
fig = px.histogram(ttr_df_juneau_delay, x="travel_time_seconds", log_y='count')
fig.show()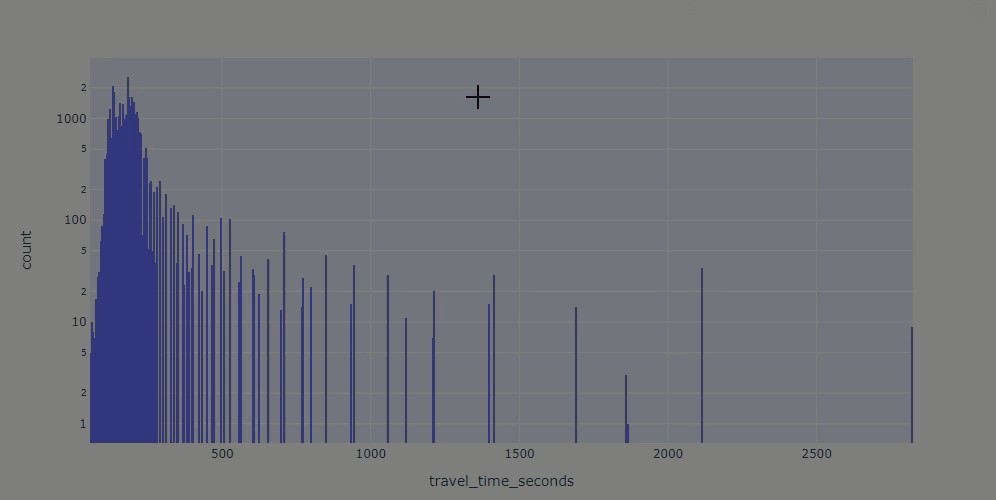
- combining plots结合地块
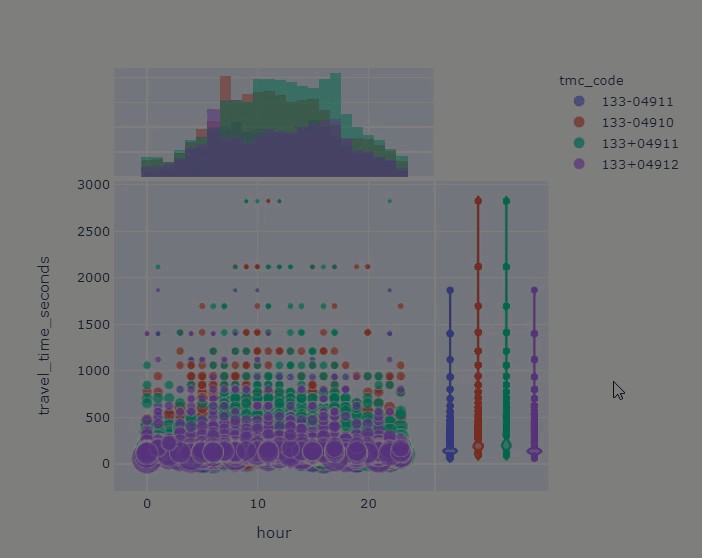
# try double-clicking on 133+04911, again under the "tmc_code" and verify what hours may be the offenders
fig_margin = px.scatter(ttr_df_juneau_delay, x="hour", y="travel_time_seconds",
color="tmc_code", size='speed',
hover_data=['tmc_code',
'travel_time_seconds',
'hour',
'day_of_year',
'month',
'speed',
'data_density'],
marginal_x='histogram', marginal_y='violin')
fig_margin.show()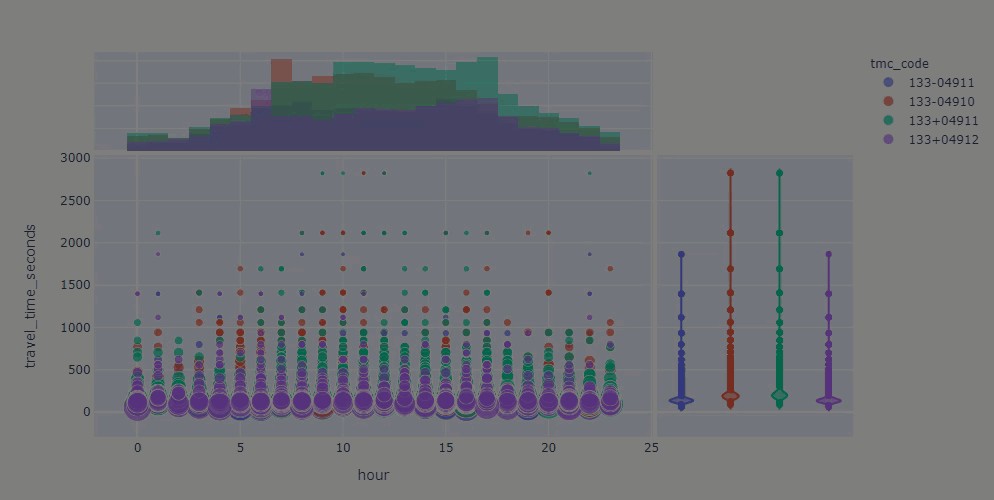
- or parsing facets或解析方面
# try double-clicking on 133+04911 under "tmc_code" and assess what hours may be the offenders
fig = px.scatter(ttr_df_juneau_delay, x="speed", y="travel_time_seconds", log_y=True,
color="tmc_code", size='speed',
hover_data=['tmc_code',
'travel_time_seconds',
'hour',
'day_of_year',
'month',
'speed',
'data_density'],
facet_col='hour', facet_col_wrap=4,
category_orders={'hour': [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23]})
fig.show()
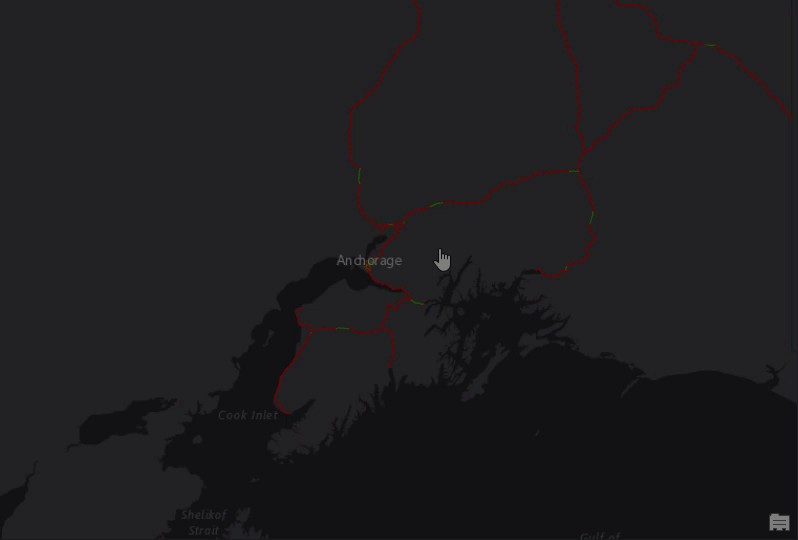
And of course, being able to map it on the fly without using a GIS platform/framework is a big advantage as well —
当然,无需使用GIS平台/框架就可以即时对其进行映射也是一大优势-
# density mapbox plot
fig = px.density_mapbox(ttr_df_juneau_delay, lat='start_latitude', lon='start_longitude', z='travel_time_seconds', radius=10,
center=dict(lat=58.373940, lon=-134.618457), zoom=12,
mapbox_style="stamen-terrain",
animation_frame='day_of_year')
# had to read documentation to sort out this part
fig.update_layout(
mapbox_style="white-bg",
mapbox_layers=[
{
"below": 'traces',
"sourcetype": "raster",
"source": [
"https://basemap.nationalmap.gov/arcgis/rest/services/USGSImageryOnly/MapServer/tile/{z}/{y}/{x}"
]
}
])
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
fig.show()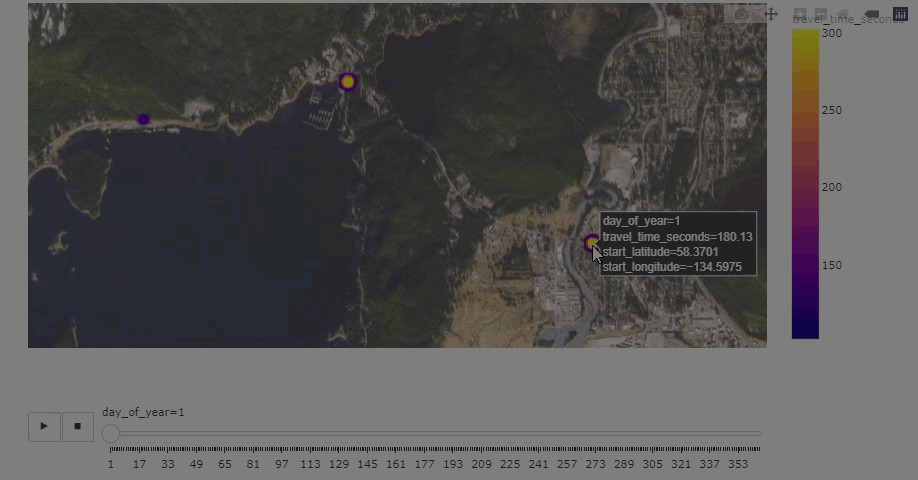
Hopefully, you can see that fairly insightful and attractive visualizations can be accomplished with just a little study on the arguments. No need to become a webapp developer just to communicate something meaningful with stakeholders or your team.
希望您可以看到,只需对参数进行一点研究,就可以完成颇具洞察力和有吸引力的可视化。 无需成为Webapp开发人员,只需与利益相关者或您的团队进行有意义的交流即可。
Speaking of which, what is a good way to share this visualization with someone?
说到哪一种,与某人共享此可视化效果的好方法是什么?
Reporting (or sharing) is a key part of visualization because while running a notebook may work with doing a live presentation/recorded presentation — it wouldn’t easily work for someone else to run your notebook and view your data approach/methods/results.
[R eporting(或共享)是可视化的重要组成部分,因为同时运行的笔记本电脑可以用做现场演讲/录制演示文稿-它不会轻易被别人跑你的笔记本电脑和查看数据的方法/方法/结果工作。
There’s other ways to share and deploy solutions/visualizations, but I’ve really enjoyed the simplicity of Datapane.
还有其他共享和部署解决方案/可视化的方法,但是我真的很喜欢Datapane的简单性。
import datapane as dp
r = dp.Report(dp.Table(ttr_df_juneau_delay), dp.Plot(fig))
r.publish(name='TTR', open=True)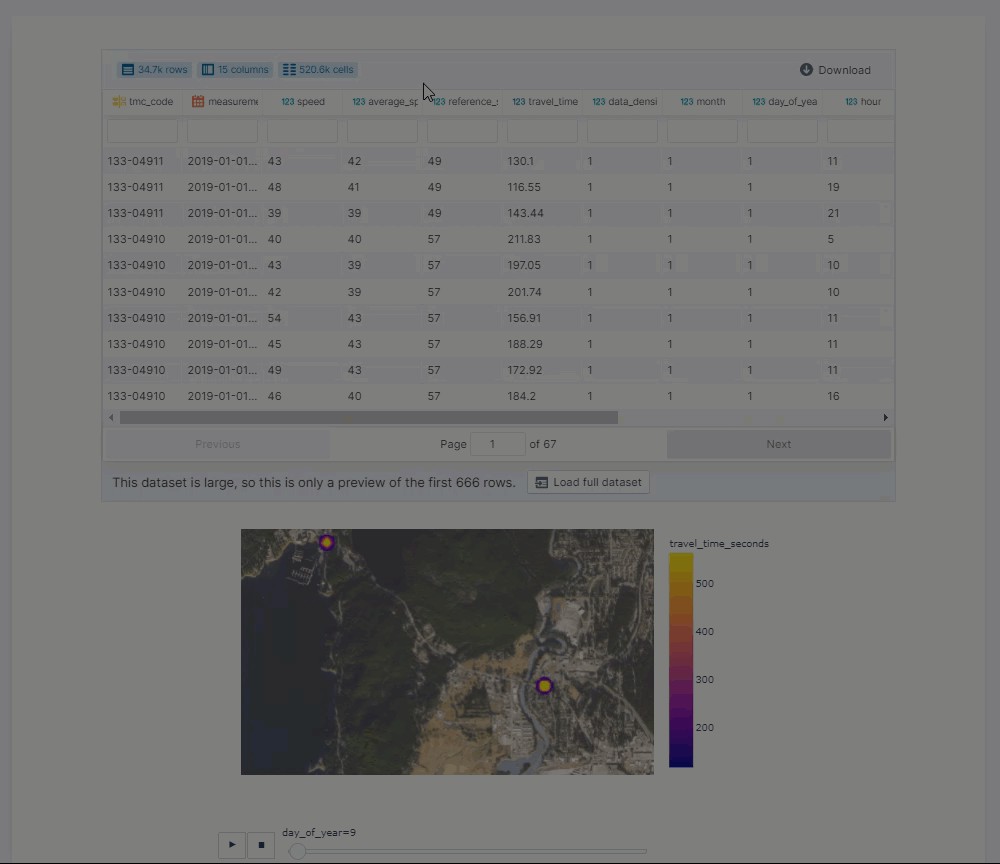
From a very minimal amount of code (and a login if you are uploading to it), you can share your results with anyone or by use of the private link.
只需很少的代码(如果要上传,则需要登录),您可以与任何人或通过专用链接共享结果。
This way, they can inspect your data and see if it is truly the sort of meaningful insight they are looking for, then download it themselves.
这样,他们可以检查您的数据并查看它是否确实是他们所寻找的有意义的见解,然后自行下载。
结论: (Conclusion:)
Data analysis, as I understand it, is any process to collect, inspect, clean, and transform data into meaningful insight and communication.
d ATA分析,按照我的理解,是任何过程,收集,检查,清洁,以及将数据转换为有意义的洞察力和沟通。
Though I do aspire to gain more technical skills in this area, I don’t personally see why creating stories from data must wait until one has mastered certain techniques and technological/programmable applications.
尽管我确实渴望在这方面获得更多的技术技能,但我个人不明白为什么从数据创建故事必须等到人们掌握某些技术和技术/可编程应用程序之后再进行。
Would I bank the direction of my section and our objectives off my simple analysis? Maybe not so much so soon.
我可以通过简单的分析来确定本节的方向和我们的目标吗? 也许没有那么快。
But it is a powerful way to substantiate an observation and to tell a story, which I think anyone, including the non-analyst, can do.
但这是证实观察结果和讲故事的有力方法,我认为包括非分析师在内的任何人都可以做到。
In case, you missed it, here’s the link to my notebook!
万一您错过了它,这是我笔记本的链接!
Thank you!
谢谢!
翻译自: https://medium.com/@ejmdpg/data-analysis-for-the-non-analyst-b959bfdb9d66
大数据分析师与数据分析师














 1585
1585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









