





线性回归随机梯度下降
In this article, we will introduce about batch gradient and stochastic gradient descent method for solving the linear regression optimization problem. The linear regression problem frequently appears in machine learning. There are different ways of solving the linear regression optimization problem. The operation research methods uses the batch gradient descent, whereas the machine learning methods uses the stochastic gradient descent to solve the linear regression optimization problem. When we have millions of training examples, it might not be feasible to compute the gradient by using all the training examples as the system might run out of memory. Therefore, the stochastic gradient descent method is developed for machine learning problem to sample the training examples, compute the gradient in the sampled data and update the direction to find the optimal solution of the cost function.
在本文中,我们将介绍解决线性回归优化问题的批梯度和随机梯度下降方法。 线性回归问题经常出现在机器学习中。 有多种解决线性回归优化问题的方法。 运筹学方法采用批量梯度下降法,而机器学习方法采用随机梯度下降法解决线性回归优化问题。 当我们有数百万个训练示例时,通过使用所有训练示例来计算梯度可能不可行,因为系统可能会耗尽内存。 因此,针对机器学习问题开发了一种随机梯度下降方法,对训练样本进行采样,计算采样数据中的梯度,并更新方向,以寻找成本函数的最优解。
Given the training examples of size m * n represented by pairs (x¹¹,x¹²,x¹³,…,y¹) (x²¹,x²²,x²³,…,y²), where each x represents the training example and y represents the corresponding labels of the training example. Let 𝝷¹, 𝝷²,… 𝝷^n be the parameters of the models then, the hypothesis of the linear regression is defined as follows:
给定大小为m * n的训练示例,用对(xx¹,x1,2,x¹³,…,y¹)(x²¹,x²²,x²³,…,y²)表示,其中每个x代表训练示例,y代表对应的标签训练示例。 令𝝷,𝝷,…𝝷 n为模型的参数,则线性回归的假设定义如下:
h(xi) = 𝝷.X + b, where X is the m * n matrix of the coefficient and 𝝷 is the parameter of the model, whose value is obtained by solving the least square cost function.
h(xi)= 𝝷.X + b,其中X是系数的m * n矩阵,𝝷是模型的参数,其值通过求解最小二乘成本函数获得。
The cost function for the linear regression is defined as :
线性回归的成本函数定义为:
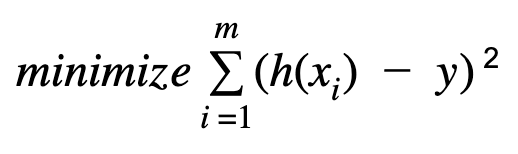
The above cost function can be solved using the batch gradient and stochastic gradient descent method. The choice of batch vs stochastic gradient descent method depends on the value of m. If we have a large number of ‘m’, computing the gradient at each training example may not be feasible as it requires the substantial memory space. On the other hand, if the value of ‘m’ is small, we could use the batch gradient to solve the optimization problem.
可以使用批量梯度法和随机梯度下降法求解上述成本函数。 分批与随机梯度下降法的选择取决于m的值。 如果我们有大量的“ m”,则在每个训练示例中计算梯度可能不可行,因为它需要大量的存储空间。 另一方面,如果“ m”的值较小,则可以使用批处理梯度来解决优化问题。
The batch gradient descent could produce the better model than that by the stochastic gradient descent.The batch gradient converges faster than the stochastic gradient descent, and thus takes substantial lower time to train the model than that taken by the stochastic gradient descent. When we use the stochastic gradient descent, we often stop the training after the maximum number of iterations as converging to an optimal solution requires a substantially large number of iterations. This has the problem of early termination of the optimization algorithm and thus producing the sub-optimal model. On the other hand, the batch gradient descent converges to the optimal solution in fewer iterations and tends to produce the optimal solution of the cost function.
批次梯度下降比随机梯度下降能产生更好的模型,批次梯度的收敛速度比随机梯度下降快,因此训练模型所需的时间比随机梯度下降要少得多。 当我们使用随机梯度下降法时,我们经常在最大迭代次数之后停止训练,因为收敛到最优解需要大量迭代。 这具有优化算法的提前终止并因此产生次优模型的问题。 另一方面,批次梯度下降以较少的迭代收敛到最优解,并且倾向于产生成本函数的最优解。
The choice of batch vs stochastic depends on the size of your problem. If you could load your data in the memory and compute the gradient, then we should use batch gradient instead of stochastic gradient descent for training the model. In many real-world applications, we end up with few number of data points in training even if the raw data has millions of rows. This is because we need to aggregate data to extract the data points for modeling and the aggregation often reduces the number of data points in the model. In such scenarios, we could load all data in the memory and batch gradient might give better model than the stochastic gradient descent method.
批量还是随机的选择取决于问题的大小。 如果您可以将数据加载到内存中并计算梯度,那么我们应该使用批梯度而不是随机梯度下降来训练模型。 在许多实际应用中,即使原始数据具有数百万行,我们最终在训练中得到的数据点数量也很少。 这是因为我们需要聚合数据以提取用于建模的数据点,并且聚合通常会减少模型中数据点的数量。 在这种情况下,我们可以将所有数据加载到内存中,并且批次梯度可能比随机梯度下降方法提供更好的模型。
线性回归随机梯度下降















 2022
2022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









