






数据库模式分解方法
For every data scientist, data availability is a crucial pre-requisite for their work. Most commonly, data are acquired from internal and external (paid) sources via APIs. On one hand, data scientists usually don’t care a lot about how the data are provided to them, they are satisfied when they can query them from a database or retrieve from an excel sheet. On the other hand, quick data availability is very important for building any analytics tools.
对于每位数据科学家而言,数据可用性是其工作的关键先决条件。 最常见的是,数据是通过API从内部和外部(收费)来源获取的。 一方面,数据科学家通常并不关心数据如何提供给他们,当他们可以从数据库中查询数据或从excel工作表中检索数据时,他们会感到满意。 另一方面,快速的数据可用性对于构建任何分析工具都非常重要。
Usually, the data must go through processing done by integration engineers, before they are ready to be consumed, and that can take a lot of time. Additionally, data mapping is a very tedious task. It is believed that 90% of developers do not enjoy the decomposition of data and their mapping. Raw data from external sources are usually acquired as XML or JSON files for given parameters. Nowadays, one of the most common concepts of storing such data in the cloud is inside a data lake. Once the data is stored there, an engineer develops a pipeline to propagate them into tables in a normalized form in a relational database, or more likely, into a data warehouse.
通常,在准备使用数据之前,数据必须经过集成工程师的处理,这会花费很多时间。 此外,数据映射是一项非常繁琐的任务。 据认为,有90%的开发人员不喜欢数据分解和映射。 对于给定的参数,通常从XML或JSON文件获取来自外部源的原始数据。 如今,在云中存储此类数据的最常见概念之一是在数据湖内部。 一旦将数据存储到那里,工程师就会开发出一条管道,以规范化的形式将它们传播到关系数据库中的表中,或者更有可能传播到数据仓库中。
The concept of the data flow has been heavily automated with tools in the cloud. Namely in AWS, one can use S3, Glue, Athena, Lake Formation, and Redshift for data management and storage. This time we will challenge heuristics in AWS to automatically detect the format and properties of the input data and will see how the grouping into tables works.
数据流的概念已通过云中的工具高度自动化。 即在AWS中,可以使用S3,Glue,Athena,Lake Formation和Redshift进行数据管理和存储。 这次,我们将挑战AWS中的启发式算法,以自动检测输入数据的格式和属性,并查看分组到表的工作方式。
汽车登记册示例 (Car register example)
In our hypothetical example, let’s suppose we are retrieving historical data about cars identified by their VIN number. The first API provides us a history of the mileage measured by the car service stations and the other API returns the history of the registration plates. Below there is an example API call for a car with VIN identifier 1HGBH41JXMN203578.
在我们的假设示例中,让我们假设正在检索有关由其VIN编号标识的汽车的历史数据。 第一个API向我们提供了汽车维修站测量的里程历史,另一个API返回了车牌的历史。 下面有一个示例示例API调用,用于具有VIN标识符1HGBH41JXMN203578的汽车。
The first API returns the VIN of the vehicle together with the attribute mileageHistory, which is an array of elements, containing the mileage in km, measured on a particular day. The registration API returns again the VIN together with the array storing the dates when the registration number has changed. Altogether, in these two JSON responses we have three entities:
第一个API返回车辆的VIN以及属性mileageHistory ,该属性是一个元素数组,包含在特定日期测量的公里数(公里)。 注册API再次返回VIN以及存储注册号已更改的日期的数组。 总之,在这两个JSON响应中,我们具有三个实体:
- Vehicle identification (through VIN), 车辆识别(通过VIN),
- Mileage history (for each vehicle), 里程历史记录(每辆车)
- Plate history (for each vehicle). 车牌历史(每辆车)。
Let’s have a look at one of the possible ways of mapping and decomposition this data into database tables. Allowing each entity to have its own table and each records its own identifier, the schema could look like this.
让我们看一下将这些数据映射和分解为数据库表的可能方法之一。 允许每个实体拥有自己的表并记录各自的标识符,该模式可能如下所示。
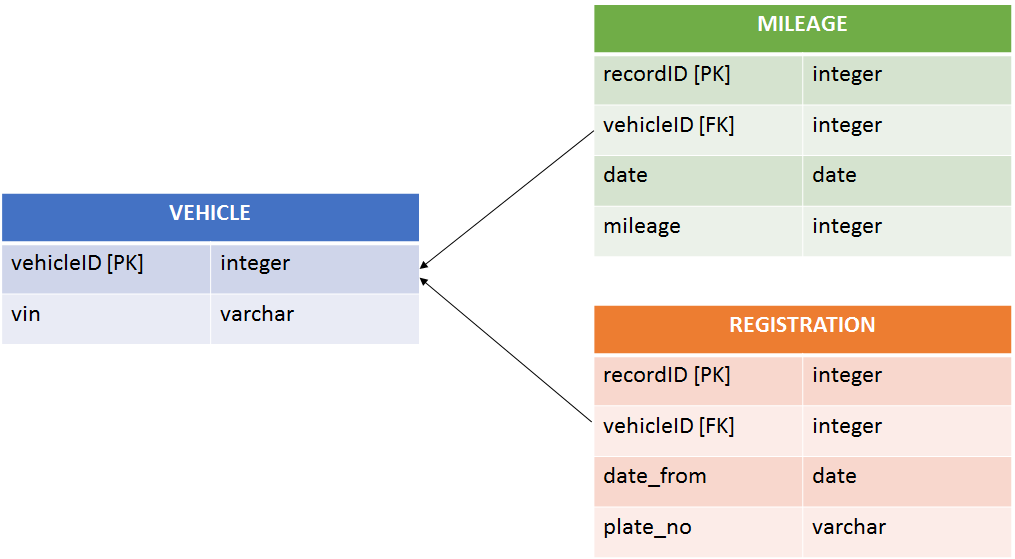
The table vehicle is storing the vinand vehicleIDis used as a vehicle identifier for saving the historical data, every element of the array as one row. This decomposition is definitely at least in the 3rd normal form and it describes the most common way on how the data could be represented. In general, delivering a system that will automatically populate a DB scheme like this is not trivial — one has to first do a business analysis of the data and analyze their relationship, decide on how to parse the data, how to structure the database, and finally map the data into the appropriate fields.
表格车辆存储vin并且vehicleID用作车辆标识符以保存历史数据,该数组的每个元素都为一行。 这种分解肯定至少是第三范式,它描述了如何表示数据的最常用方法。 总的来说,提供一种可以自动填充数据库方案的系统并非易事-必须首先对数据进行业务分析并分析它们之间的关系,决定如何解析数据,如何构建数据库以及最后将数据映射到适当的字段中。
具有挑战性的AWS Glue (Challenging AWS Glue)
According to the definition in AWS docs, a crawler can automate the process of data decomposition and from raw data. Here is its description:
根据AWS文档中的定义,搜寻器可以自动执行数据分解过程以及原始数据。 这是它的描述:
Classifies data to determine the format, schema, and associated properties of the raw data — You can configure the results of classification by creating a custom classifier.
对数据进行分类,以确定 原始数据 的格式,架构和相关属性 -您可以通过创建自定义分类器来配置分类结果。
Groups data into tables or partitions, while grouped based on crawler heuristics.
根据爬虫启发式将数据分组 到表或分区中 。
We will use two responses of our fictive API as an example, to feed the heuristics and grouping in AWS. The following files were uploaded to S3 and the crawler was applied to them.
我们将以虚拟API的两个响应为例,来提供AWS中的启发式方法和分组。 以下文件已上载到S3,并且对它们应用了搜寻器。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3013
3013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









