





graphql 嵌套查询
This is a brief for the research paper A Principled Approach to GraphQL Query Cost Analysis, published at ESEC/FSE 2020. Alan Cha led the work, with help from Erik Wittern, Guillaume Baudart, me, Louis Mandel, and Jim Laredo. Most of these authors are affiliated with IBM Research or IBM’s product teams, as part of IBM’s ongoing involvement with GraphQL.
这是对在ESEC / FSE 2020上发表的GraphQL查询成本分析的原则性方法研究论文的简要介绍。Alan Cha在Erik Wittern,Guillaume Baudart,我,Louis Mandel和Jim Laredo的帮助下领导了这项工作。 其中大多数作者都是IBM Research或IBM产品团队的成员,这是IBM持续参与GraphQL的一部分。
This project is a follow-up to our previous work studying GraphQL schemas.
该项目是我们先前研究GraphQL模式的后续工作 。
摘要 (Summary)
The state of practice: The landscape of Web APIs is evolving to meet new client requirements and to facilitate how providers fulfill them. The latest web API model is GraphQL, through which client queries express the data they want to retrieve or mutate, and servers respond with exactly those data or changes. GraphQL reduces network roundtrips and eliminates the transmission of unneeded data.
实践状态: Web API的发展趋势是为了满足新的客户端需求并促进提供者如何实现它们。 最新的Web API模型是GraphQL ,客户端查询通过该模型表达他们想要检索或突变的数据,服务器则准确地响应那些数据或更改。 GraphQL减少了网络往返,并消除了不必要数据的传输。
What’s the problem? GraphQL’s expressiveness is risky for service providers. GraphQL clients can succinctly request stupendous amounts of data, and responding to these queries can be costly or disrupt service availability. Recent empirical work has shown that many service providers are at risk. Practitioners lack a principled means of estimating and measuring the cost of the GraphQL queries they receive.
有什么问题? GraphQL的 表达方式对服务提供商有 风险 。 GraphQL客户端可以简洁地请求大量数据,并且响应这些查询可能会导致成本高昂或中断服务可用性。 最近的经验工作表明,许多服务提供商都处于危险之中。 从业人员缺乏估算和衡量他们收到的GraphQL查询的成本的原则方法。
What did we do? Our static GraphQL query analysis measures a query’s complexity without executing it. Our analysis is provably correct based on our formal specification of GraphQL semantics. In contrast to existing static approaches, our analysis supports common GraphQL conventions that affect query complexity. Because our approach is static, it can be applied in a separate API management layer and used with arbitrary GraphQL backends.
我们做了什么? 我们的静态GraphQL查询分析无需执行查询即可测量查询的复杂性。 根据我们对GraphQL语义的正式规范, 我们的分析证明是正确的。 与现有的静态方法相比,我们的分析支持影响查询复杂性的通用GraphQL约定 。 由于我们的方法是静态的,因此可以将其应用于单独的API管理层中,并与任意GraphQL后端一起使用。
Does our analysis work? We demonstrate our approach using a novel GraphQL query-response corpus for two commercial GraphQL APIs. Our query analysis consistently obtains upper complexity bounds, tight enough relative to the true response sizes to be actionable for service providers. In contrast, existing static GraphQL query analyses exhibit over-estimates and under-estimates because they fail to support GraphQL conventions.
我们的分析有效吗? 我们针对两个商业GraphQL API使用新颖的GraphQL查询响应语料库演示了我们的方法。 我们的查询分析始终获得复杂度上限,相对于真实的响应大小足够紧,对服务提供商而言是可操作的。 相反,现有的静态GraphQL查询分析显示过高估计和过低估计,因为它们不支持GraphQL约定。
What would this look like in practice? The first figure (above) shows our vision. Our cost analysis can be applied at the client side and at the server side. It can guide clients away from accidentally-costly queries. For middleware/servers, it can be used to detect and respond to potentially costly queries.
在实践中会是什么样? 第一个数字(上方)显示了我们的愿景。 我们的成本分析可以应用于客户端和服务器端。 它可以指导客户避免意外的昂贵查询。 对于中间件/服务器,它可以用于检测和响应潜在的昂贵查询。
背景 (Background)
If you are unfamiliar with GraphQL, take a look at my earlier post and the references therein. There are plenty of other tutorials on the web, too.
如果您不熟悉GraphQL,请查看我以前的文章及其中的参考。 网络上还有许多其他教程。
动机 (Motivation)
许多GraphQL服务都支持超线性GraphQL查询 (Many GraphQL services support super-linear GraphQL queries)
Two previous empirical studies have described analyses on GraphQL schemas to understand whether they are at risk of “GraphQL Query Denial of Service” [1,2]. They wondered whether a user could send a small query and get back a really big response. They reported that this is possible for most GraphQL schemas; over 80% of the commercial or large-scale open-source schemas permitted exponentially-sized responses in the length of the input, and polynomially-sized responses were also common.
之前的两项实证研究已经描述了对GraphQL模式的分析,以了解它们是否存在“ GraphQL查询拒绝服务”的风险[1,2]。 他们想知道用户是否可以发送一个小的查询并获得很大的响应。 他们报告说,这对于大多数GraphQL模式都是可行的。 超过80%的商业或大型开源模式允许在输入长度上以指数大小响应,并且以多项式响应也很普遍。
很少有GraphQL服务记录其防御措施 (Few GraphQL services document their defenses)
We manually studied the documentation for the 30 public GraphQL APIs listed by APIs.guru. Disturbingly, 25 of these 30 providers describe neither static nor dynamic query analysis to manage access and prevent misuse. A few GraphQL APIs have incorporated customized query and/or response analysis into their management approach (GitHub, Shopify, Yelp, Contentful, and TravelGateX), but these approaches have shortcomings. See the paper ($2.2 and $6.4.3) for details.
我们手动研究了APIs.guru列出的30个公共GraphQL API的文档 。 令人不安的是,这30家提供商中有25家既没有描述静态查询也没有描述动态查询分析来管理访问并防止滥用。 一些GraphQL API已将自定义的查询和/或响应分析纳入其管理方法(GitHub,Shopify,Yelp,Contentful和TravelGateX),但是这些方法都有缺点。 有关详细信息,请参见论文(2.2美元和6.4.3美元)。
现有的GraphQL成本分析不足 (Existing GraphQL cost analyses are inadequate)
It’s easy to measure the cost of a query — just execute it! But if the query is expensive, that can backfire. A cost analysis measures the cost of a query without fulling executing it. Like most cost analyses, there are two types of cost analyses for GraphQL queries: dynamic and static.
衡量查询的成本很容易-只需执行它即可! 但是,如果查询成本很高,那可能适得其反。 成本分析可在不完全执行查询的情况下测量查询的成本。 像大多数成本分析一样,GraphQL查询有两种类型的成本分析: 动态和静态 。
Researchers have proposed a dynamic analysis [1,3], which considers a query in the context of the data graph on which it will be executed. Through lightweight query resolution, it steps through a query to determine the number of objects involved without resolving them. This cost measure is accurate but expensive to obtain. It incurs additional runtime load, and potentially entails engineering costs to support cheap queries for object counting [3].
研究人员提出了一种动态分析 [1,3],该分析考虑了要在其上执行查询的数据图的上下文中的查询。 通过轻量级查询解析,它逐步执行查询以确定涉及的对象数,而无需解决它们。 这种成本测量是准确的,但获得成本很高。 它带来了额外的运行时负载,并可能需要工程成本来支持廉价的对象计数查询[3]。
Practitioners have proposed static analyses [4,5,6], which calculate the worst-case response size for a query supposing a pathological data graph (i.e. a graph that will yield the largest possible response). Because a static analysis assumes the worst, it can efficiently provide an upper bound on a query’s complexity without interacting with the backend. The speed and generality of static query analysis make it an attractive approach for commercial GraphQL API providers.
从业人员提出了静态分析 [4,5,6],计算假设病理数据图(即将产生最大可能响应的图)的查询的最坏情况响应大小。 因为静态分析假设最坏的情况,所以它可以有效地提供查询复杂性的上限,而无需与后端进行交互。 静态查询分析的速度和通用性使其成为商业GraphQL API提供程序的一种有吸引力的方法。
Our static approach follows a similar paradigm as existing static analyses. We differ in several ways. Most notably:
我们的静态方法遵循与现有静态分析类似的范例。 我们在几个方面有所不同。 最为显着地:
- We build our analysis on formal GraphQL semantics and prove the correctness of our query complexity estimates. 我们基于形式化的GraphQL语义进行分析,并证明查询复杂度估计的正确性。
- Our analysis can be configured to handle common schema conventions to produce better estimates. 我们的分析可以配置为处理常见的架构约定,以产生更好的估计。
方法 (Approach)
Because our aim is to prove the correctness of our analysis, this section gets a bit mathematical. I’ve tried to capture the high-level ideas and leave the math to the paper.
因为我们的目的是证明分析的正确性,所以本节将进行一些数学上的说明。 我试图捕捉高级想法,然后将数学问题留给论文。
GraphQL形式化 (GraphQL formalization)
GraphQL is analogous to SQL, but in my opinion it makes the relationships between data a bit clearer. I will use (inline) notation to point out the SQL analogies.
GraphQL与SQL类似,但是在我看来,它使数据之间的关系更加清晰。 我将使用(内联)表示法指出SQL类比。
A GraphQL data graph (database instance) represents the underlying data and relationships known by the service provider.
GraphQL 数据图 (数据库实例)表示服务提供商已知的基础数据和关系。
A GraphQL schema (database schema) defines the data types that clients can query, as well as possible operations on that data.
GraphQL 模式 (数据库模式)定义客户端可以查询的数据类型以及对该数据的可能操作。
A GraphQL query (database query) requests a subset of the data that meets certain criteria, organized in terms of the relationships present in the data graph.
GraphQL 查询 (数据库查询) 请求满足某些条件的数据子集,并根据数据图中的关系进行组织。
The evaluation of a GraphQL query can be thought of as applying successive filters to a virtual data object that initially corresponds to the complete data graph. These filters are defined by the query and are applied recursively following the query’s structure (see Figure 3 in the paper). The data graph is mapped onto backend storage using resolver functions, which resolve entities for each field of each type in the schema.
GraphQL查询的评估可以认为是将连续的筛选器应用于最初对应于完整数据图的虚拟数据对象。 这些过滤器由查询定义,并按照查询的结构递归应用(请参见本文中的图3)。 使用解析器功能将数据图映射到后端存储, 解析器功能可解析架构中每种类型的每个字段的实体。
A GraphQL response consists of the entities matching the query, typed and organized according to the query’s filters.
GraphQL 响应由与查询匹配的实体组成,并根据查询的过滤器进行键入和组织。
查询复杂度-查询成本的定义 (Query complexity — Definitions of query cost)
A GraphQL query describes the structure of the response data, and also dictates the resolver functions that must be invoked to satisfy it (which resolvers, in what order, how many times). We propose two query cost definitions:
GraphQL查询描述了响应数据的结构,还规定了必须调用才能满足它的解析器功能(哪些解析器以什么顺序,多少次)。 我们提出两个查询成本定义:
Type complexity indicates the size of the response, measured by the number of fields in the response. You could simply count each entry, or you could weight the entries by the cost of representing them (e.g. the number of bytes needed to encode each type of field, like maximum string length or maximum integer width). This cost is paid by everyone — the service provider (to generate and marshal it), the network operator (to ship it), and the client (to unmarshal and process it).
类型复杂度表示响应的大小,该大小由响应中的字段数衡量。 您可以简单地对每个条目进行计数,或者可以通过表示条目的成本(例如,对每种类型的字段进行编码所需的字节数,例如最大字符串长度或最大整数宽度)对条目进行加权。 这笔费用由每个人支付-服务提供商(生成和封送),网络运营商(装运)和客户端(解封和处理)。
Response complexity indicates the GraphQL service provider’s cost to generate the response. If the provider’s greatest cost is shipping data over the network, then the type complexity might suffice for them. But the provider’s computational cost may also depend on which resolver functions are invoked and how many times each. For example, perhaps some resolvers can be resolved through a cache, others by accessing cold storage, and still others are obtained through API composition from a third party. GraphQL’s backend-agnostic nature may lead to different costs for the provider on a per-resolver basis. Our notion of response complexity captures these kinds of costs.
响应复杂度表明GraphQL服务提供商生成响应的成本。 如果提供商的最大成本是通过网络传输数据,则类型复杂性可能就足够了。 但是提供者的计算成本也可能取决于调用哪些解析程序功能以及每个调用次数多少次。 例如,也许某些解析器可以通过缓存来解析,其他解析器可以通过访问冷存储来解析,而其他解析器可以通过API组合从第三方获得。 GraphQL的与后端无关的性质可能会导致提供商在每个解析器的基础上产生不同的成本。 我们的响应复杂性概念涵盖了这些成本。
Both of these costs can be calculated using weighted recursive sums under our formalization, which is similar to Facebook’s definition of GraphQL. But this definition is silent about how to handle lists. If we simply assume that all lists are infinitely long (or contain all entries of that type in the underlying data graph), we won’t get very useful cost estimates. Happily, the community follows two pagination conventions because returning infinitely long lists isn’t helpful for anybody.
根据我们的形式化,这两个成本都可以使用加权递归总和来计算,这类似于Facebook对GraphQL的定义。 但是这个定义没有提及如何处理列表。 如果仅假设所有列表都无限长(或在基础数据图中包含该类型的所有条目),我们将不会得到非常有用的成本估算。 令人高兴的是,社区遵循两个分页约定,因为返回无限长的列表对任何人都没有帮助。
分页处理 (Accounting for pagination)
We consider two common [2] pagination conventions: the slicing pattern and the connections pattern. Slicing uses limit arguments to bound the size of the returned lists. Connections introduces a layer of indirection for more flexible pagination, with limit arguments applying to a cursor instead of to a list itself. These concepts are illustrated in the next figure.
我们考虑两种常见的[2]分页约定:切片模式和连接 模式。 切片使用限制参数来限制返回列表的大小。 Connections引入了一个间接层,以实现更灵活的分页,其中限制参数适用于游标而不是列表本身。 下图说明了这些概念。

我们的成本分析 (Our cost analysis)
We measure a query’s potential cost in terms of its type complexity and response complexity. Our analyses are essentially weighted recursive sums, with list sizes limited by the limit arguments dictated through the slicing and connections patterns.
我们根据查询的类型复杂度和响应复杂度来衡量查询的潜在成本。 我们的分析本质上是加权递归和,列表大小受限制参数限制,该限制参数由切片和连接模式决定。
Since our approach relies on conventions, the schema must be accompanied by a configuration explaining how it follows these conventions. This configuration accomplishes three things:
由于我们的方法依赖于约定,因此模式必须随附说明其如何遵循这些约定的配置 。 此配置完成三件事:
It labels the fields that contain limits, and the sub-fields (for the connections pattern) to which these limits apply.
它标记了包含限制的字段 ,以及这些限制适用的子字段(用于连接模式)。
It provides default limits in the event that a limit field has no argument supplied.
如果没有提供限制参数 ,则它提供默认限制 。
It optionally provides the weights to dictate how much each type and each resolver function costs. By default, a weight of 1 might be reasonable.
可以选择提供权重来指示每种类型和每种解析器功能要花费多少。 默认情况下,权重为1可能是合理的。
Guarantees Given a schema and a configuration, our analysis always yields an upper bound on a query’s cost in terms of its type complexity and response complexity. This guarantee assumes that all fields returning lists enforce their limit arguments and have a finite default limit. These are upper bounds because we assume that the underlying graph is pathological —that every list requested in the query will be fully populated.
保证给定一个模式和一个配置,我们的分析总是根据类型的复杂性和响应的复杂性产生查询成本的上限。 此保证假定返回列表的所有字段都强制使用其限制参数,并且具有有限的默认限制。 这些是上限,因为我们假设基础图是病态的—查询中请求的每个列表都将完全填充。
Time and space complexity of our analysis
分析的时间和空间复杂度
Time: Our analysis works its way “outwards-in” in a breadth-first manner. It visits each node of the query once, because inner layers of the query cannot increase the number of nodes at outer layers of the response. It therefore runs in time linear in the size of the query.
时间:我们的分析以广度优先的方式“向外”进行。 它访问查询的每个节点一次,因为查询的内层无法增加响应的外层节点的数量。 因此,它在时间上与查询大小成线性关系。
Space: The context of the recursive queries must be carried along in order to track the limits of sub-fields to handle the connections pattern. The convention (and our mplementation) only applies these limits to direct children, for a constant space cost. In general the space complexity matches the maximum degree of nesting within the query.
空间:必须携带递归查询的上下文 ,以便跟踪子字段的限制以处理连接模式。 约定(以及我们的执行方式)仅将这些限制适用于直系子女,而其空间成本却是不变的。 通常,空间复杂度与查询内的最大嵌套度匹配。
Implementation We implemented this approach, but have not yet persuaded IBM to open source it :-). We hope that open-source tools [4,5,6] will consider incorporating our ideas.
实现我们实现了这种方法,但是尚未说服IBM将其开源:-)。 我们希望开源工具[4,5,6]将考虑纳入我们的想法。
评价 (Evaluation)
We investigated five questions. Our evaluation used two public GraphQL services, GitHub and Yelp.
我们调查了五个问题。 我们的评估使用了GitHub和Yelp这两个公共GraphQL服务。
可以将分析(和配置)应用于实际的API吗? (Can the analysis (and configuration) be applied to real-world APIs?)
Our analysis requires a GraphQL schema to be accompanied by a configuration of limit arguments, weights, and default limits.
我们的分析需要GraphQL架构伴随有限制参数,权重和默认限制的配置。
We found it straightforward to develop a configuration for both schemas. Since GraphQL schemas follow naming conventions [2], we supported regular expressions to denote field names in our configuration language, and our configurations are thus far smaller than the corresponding schemas.
我们发现为两种模式开发配置都非常简单。 由于GraphQL模式遵循命名约定[2],所以我们支持使用正则表达式来用我们的配置语言表示字段名称,因此我们的配置远小于相应的模式。
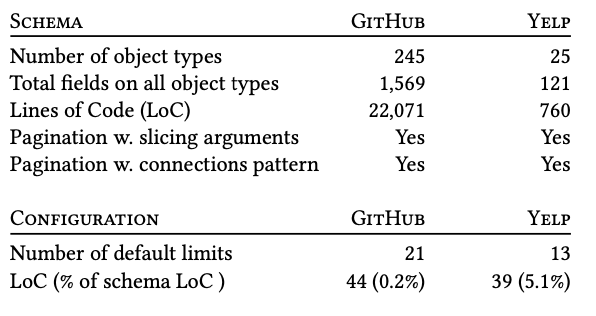
我们是否总是获得上限? (Do we always obtain upper bounds?)
Yes! We developed an open-source GraphQL query generator [7] and generated 5,000 query-response pairs for each API. The predicted and actual complexities are plotted here. We guarantee upper bounds, so our predicted costs always lie above the line y=x in the figure.
是! 我们开发了一个开源的GraphQL查询生成器[7],并为每个API生成了5,000个查询响应对。 在此绘制了预测的和实际的复杂度。 我们保证上限,因此我们的预测成本始终位于图中的y = x线上方。
这些界限是否足够有用? (Are these bounds tight enough to be useful?)
This is a bit subjective. Our bounds may be over-estimates, but are as tight as possible with a static, data-agnostic approach. The results depend on the underlying data graph.
这有点主观。 我们的界限可能被高估了,但是使用静态的,与数据无关的方法则尽可能地严格。 结果取决于基础数据图。
Data sparsity leads responses to be less complex than their worst-case potential. In the preceding figure our upper bound is close or equal to the actual type and resolve complexities of many queries —this can be seen in the high density of queries near the diagonals. Our bounds grow looser for more-complex queries. This follows intuition about the underlying graph: larger, more nested queries may not be satisfiable by an API’s real data.
数据稀疏性导致响应比最坏情况下的响应要简单。 在上图中,我们的上限接近或等于实际类型,并且可以解决许多查询的复杂性-这可以在对角线附近的高密度查询中看到。 对于更复杂的查询,我们的界限越来越宽松。 这是关于基础图的直觉:API的实际数据可能无法满足更大,嵌套更多的查询。
We quantify this in the paper (see Table 2).
我们在论文中对此进行了量化(参见表2)。
我们的分析便宜到足以适用于中间件吗? (Is our analysis cheap enough to be applicable in middleware?)
Yes! Beyond the functional correctness of our analysis, we assessed its runtime cost to see if it can be incorporated into existing request-response flows, e.g. in a GraphQL client or an API management middleware.
是! 除了分析的功能正确性之外,我们还评估了其运行时成本,以查看是否可以将其合并到现有的请求-响应流中,例如在GraphQL客户端或API管理中间件中。
We measured costs on a 2017 MacBook Pro (8-core Intel i7 processor, 16 GB of memory). As predicted, our analysis runs in linear time as a function of the query size. Nearly all queries could be analyzed in under 5 milliseconds.
我们测量了2017年MacBook Pro(8核Intel i7处理器,16 GB内存)的成本。 正如预测的那样,我们的分析以线性时间作为查询大小的函数。 几乎所有查询都可以在5毫秒内分析。
我们的方法与其他静态分析相比如何? (How does our approach compare to other static analyses?)
We compared against open-source and closed-source analyses.
我们将其与开放源代码分析和封闭源代码分析进行了比较。
Open source We compared our approach against those of three open-source libraries [4,5,6]. The following figure summarizes the results. Note that libA produces wild over-estimates, while libB and libC follow identical approaches that are susceptible to under-estimates.
开源我们将我们的方法与三个开源库的方法进行了比较[4,5,6]。 下图总结了结果。 请注意,libA会产生疯狂的高估,而libB和libC遵循容易受到低估的相同方法。
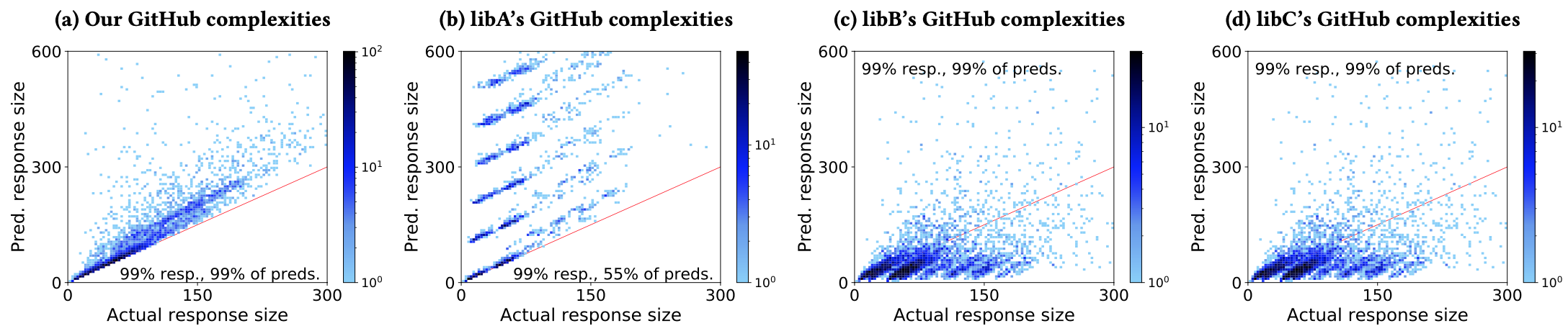
The shortcomings of these libraries can be tied to their mishandling of GraphQL pagination conventions. Problematically, these libraries do not always permit users to specify the lengths of lists, leading to over- and under-estimates.
这些库的缺点可能与对GraphQL分页约定的处理不当有关。 有问题的是,这些库并不总是允许用户指定列表的长度,从而导致高估和低估。
libA is liable to over-estimates. It only permits a global maximum on list lengths. Since these API providers have large variation in default lengths (and support limit arguments), the resulting upper bounds may be large overestimates.
libA容易被高估。 它仅允许列表长度的全局最大值 。 由于这些API提供程序的默认长度(和支持限制参数)差异很大,因此产生的上限可能过高。
libB and libC may make under-estimates. They treat unpaginated lists as always returning only one element. They also cannot support indirect limit arguments, and thus cannot handle the connections pattern.
libB和libC可能会低估。 他们将未分页的列表视为始终仅返回一个元素。 它们也不能支持间接限制参数,因此不能处理连接模式。
Closed source
封闭源
We considered the static analyses of GitHub and Yelp, which are documented although not open source.
我们考虑了对GitHub和Yelp的静态分析,尽管这些文档不是开源的,但已有记录。
GitHub At the time of our study, GitHub shared one of the limitations of libB and libC: it did not properly handle the size of unpaginated lists. The first figure illustrates this issue using the unpaginated relatedTopics field. We reported this issue and they have resolved it. Our analysis remains more flexible than their repaired analysis.
GitHub在我们研究时,GitHub共享了libB和libC的局限性之一:它无法正确处理未分页列表的大小。 第一个数字说明了使用unpaginated relatedTopics场这个问题。 我们报告了此问题,他们已经解决了。 我们的分析比经过修复的分析更具灵活性。
Yelp Yelp follows a simple rule: fields can be nested to at most four levels. Relatively large responses can still be obtained by nesting large lists. Our more accurate analysis has the same time complexity as theirs (both process the query in a single pass).
Yelp Yelp遵循一个简单的规则:字段最多可以嵌套四个级别。 仍然可以通过嵌套大列表来获得相对较大的响应。 我们更准确的分析与他们的分析具有相同的时间复杂度(都在一次通过中处理查询)。
结论 (Conclusions)
GraphQL is an emerging Web API model. Its flexibility can benefit clients, servers, and network operators. But its flexibility is also a threat: GraphQL queries can be exponentially complex, with implications for service providers including rate limiting and denial of service.
GraphQL是新兴的Web API模型。 它的灵活性可以使客户端,服务器和网络运营商受益。 但是它的灵活性也是一个威胁:GraphQL查询可能呈指数级复杂,对服务提供商有影响,包括速率限制和拒绝服务。
The fundamental requirement for service providers is a cheap, accurate way to estimate the cost of a query. We have proposed a principled, provably-correct approach to address this challenge. With proper configuration, our analysis offers tight upper bounds, low runtime overhead, and independence from backend implementation details.
服务提供商的基本要求是一种廉价,准确的方法来估算查询的成本。 我们提出了一种有原则的,可证明正确的方法来应对这一挑战。 如果配置正确,我们的分析将提供严格的上限,较低的运行时开销以及与后端实现细节的独立性。
更多信息 (More information)
The full paper is available here.
全文可在此处获得 。
- The slides will be available soon. 幻灯片即将发布。
The artifact associated with the paper is available here. Highlights include an anonymized query-response corpus and the query generator we used to generate it.
与纸张相关的工件在此处可用。 重点包括匿名查询响应语料库和我们用来生成它的查询生成器。
I’m excited to say that IBM has incorporated aspects of our work into IBM API Connect v10.x. This product helps protect GraphQL service providers from costly queries. From 1:45–3:30 in the video at the bottom of the release link, you can see the GUI that supports users in the configuration process. From 5:10–6:00 you can see how the analysis can be used in rate limiting.
我很高兴地说IBM已将我们的工作内容整合到IBM API Connect v10.x中 。 该产品有助于保护GraphQL服务提供商免受昂贵的查询。 从发行链接底部视频中的1:45–3:30,您可以看到在配置过程中支持用户的GUI。 从5:10–6:00,您可以看到如何将分析用于速率限制。
翻译自: https://medium.com/dev-genius/a-principled-approach-to-graphql-query-cost-analysis-8c7243de42c1
graphql 嵌套查询















 3043
3043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









