





如何衡量二次曲线的变化趋势
Let's do a think-experiment. Imagine that the world around you just froze. Nothing is changing. Everything is on a standstill. Is there anything, that is meaningful? Anything you can learn? Nothing. A stopped world is equivalent to a no world! The world exists because it “changes”. Rotations and revolutions of planets, the evolution of species, economic growth or decline, population mechanics, rise and fall of stock markets……..there is a notion of “change” at the heart of just every phenomenon.
L等我们做一个思考,实验。 想象一下,您周围的世界刚刚冻结。 一切都没有改变。 一切都停滞不前。 有什么有意义的吗? 有什么可以学的吗? 没有。 停止的世界等于没有的世界! 世界之所以存在是因为它在“改变”。 行星的自转和公转,物种的演变,经济增长或下降,人口机制,股票市场的兴衰……..每个现象的核心都有“变化”的概念。
And if you take a big leap of generalization, you can see that all human knowledge is about the recognition, understanding, measurement, and manipulation of changes that occur in nature. Any knowledge about a phenomenon would roughly try to answer the following questions:
而且,如果您进行了概括性的大飞跃,您会发现所有人类知识都是关于对自然界中发生的变化的识别,理解,度量和操纵的。 有关现象的任何知识都将大致尝试回答以下问题:
Is there a change? Which things are changing?
有变化吗? 哪些事情正在改变?
Does the change in one thing affects others?
一件事的改变会影响其他吗?
How can this change be measured? Is there a rule which can explain and express this change? Can it be used to predict the change in the future?
如何测量这种变化? 是否存在可以解释和表达这种变化的规则? 可以用来预测未来的变化吗?
When you are observing or studying a phenomenon, you focus on things that are involved. These things are called “variables” because they “vary” or they “change”. The kind of “changes” or “variations” they undergo depends on the kind of variables they are.
当您观察或研究现象时,您会专注于所涉及的事物。 这些事物被称为“ 变量 ”,因为它们“变化”或“变化”。 它们经历的“变化”或“变化”的类型取决于它们所具有的变量的类型。
定量或定性 (Quantitative or Qualitative)

Fundamentally, all variables (or all data) can only be of 2 types: Quantitative or Qualitative
从根本上讲,所有变量(或所有数据)只能是两种类型: 定量或定性
There are things for which you can measure the “size” or “value” like speed, distance, volume, weight, height, income, etc. These are numerical values and it makes sense to perform arithmetic operations such as addition or subtraction on such variables. Quantitative variables typically have measurement units, such as kilograms, dollars, years, and so on.
有些东西可以测量“大小”或“值”,例如速度,距离,体积,重量,高度,收入等。这些都是数值,因此对它们执行算术运算(如加法或减法)是有意义的变量。 定量变量通常具有度量单位,例如千克,美元,年等。
On the other hand, there are variables that describe something. e.g name of a person or a place, or gender or race or category of animals, and so on. The arithmetic operations on such variables do not make sense. You can not add or subtract genders or categories. These variables typically do not have units. Note that qualitative variables can also take numerical values such as PIN Codes or Social Security Numbers but you will not want to add PIN codes or SSNs. It will not make sense.
另一方面,有些变量可以描述某些事物。 例如,一个人或一个地方的名称,或性别,种族或动物类别,等等。 对此类变量的算术运算没有意义。 您不能添加或减去性别或类别。 这些变量通常没有单位。 请注意,定性变量也可以采用数字值,例如PIN码或社会安全号码,但是您不希望添加PIN码或SSN。 这没有任何意义。
Now think of any data value about anything. This value will either be Quantitative or Qualitative. Quantitative variables are also called “Continuous” variables. Inherently, they represent a “quantity” that is being measured. e.g Weight. It's “continuous” because the value can be anything. e.g 50Kgs, 50.1 Kgs, 52 Kgs, 52.5 kgs….just about anything.
现在想想任何有关任何数据的值。 此值将是“定量”或“定性”。 定量变量也称为“连续”变量。 从本质上讲,它们代表着正在测量的“数量”。 例如重量。 这是“连续的”,因为值可以是任何值。 例如50公斤,50.1公斤,52公斤,52.5公斤……几乎任何东西。
Qualitative variables are also known as “Categorical”. Inherently, they represent a “group” or a “category” and the value will belong to a fixed set of that group or category. e.g Gender — (Male or Female), Result of a Medical Test (Positive or Negative)
定性变量也称为“类别”。 它们本质上代表一个“组”或“类别”,并且值将属于该组或类别的固定集合。 例如,性别—(男性或女性)医学检查结果(阳性或阴性)
The type of variable (Quantitative or Qualitative) will determine the kind of analysis that can be done.
变量的类型(定量或定性)将确定可以进行的分析类型。
Let's look at some of the operations that can be done to describe or understand the changes in these variables.
我们来看一些可以描述或理解这些变量中的更改的操作。
集中趋势测度 (Measures of Central Tendency)

Whenever something is changing, what is our natural inclination to express or summarize these changes? On average, people will tend to find the “average”. (pun intended :)
每当发生变化时,表达或总结这些变化的自然倾向是什么? 平均而言,人们会倾向于找到“ 平均值” 。 (双关语意:)
Calculating “average” is the most intuitive thing which comes naturally when we are analyzing data. So let's say you want to know how good a batsman is? (In the game of cricket) You have been given the runs he scored in the last 10 matches.
当我们分析数据时,计算“平均值”是最直观的事情。 假设您想知道一名击球手有多出色? (在板球比赛中)您获得了他在最近10场比赛中得分的得分。

To measure his performance or to make a judgment of how good or how bad this player is, don't you have an instant urge to calculate “average” runs scored over the 10 matches? You can not make a decision or inference just by looking at the score of each match in isolation. You need 1 representative number to reflect it. And the natural tendency is to find out the “average”.
要衡量他的表现或判断该球员的好坏,您是否立刻就想计算出10场比赛的平均得分? 您不能仅通过单独查看每个比赛的分数来做出决定或推断。 您需要1个代表号码才能反映出来。 自然的趋势是找出“平均值”。
Many of us don’t realize but there are many ways to measure “average”. These measurements are known as “Measures of Central Tendency”.
我们许多人没有意识到,但是有很多方法可以测量“平均值”。 这些度量被称为“集中趋势度量”。
意思: (Mean:)
Most of the times, when people are talking about average, they actually mean “Mean” :)
在大多数情况下,当人们谈论平均水平时,实际上是指“均值” :)
Mean is simply the sum of all the given numbers divided by how many numbers are there.
平均值只是所有给定数字的总和除以其中有多少个数字。
In our example, the mean is (5+2+12+32+21+3+12+0+15+9)/10 which comes out to be 11.1
在我们的示例中,平均值为(5 + 2 + 12 + 32 + 21 + 3 + 12 + 0 + 15 + 9)/ 10,得出的平均值为11.1
You can say that “mean” is one type of “average”. Are there other types?
您可以说“平均值”是“平均值”的一种类型。 还有其他类型吗?
中位数: (Median:)
Assume, that this player had another match in which he scored whopping 400 runs!
假设这位球员还有另一场比赛,他得分高达400杆!
The mean now comes out to be: 46.45
现在的平均值是:46.45
In this case, the mean can be misleading because, in all matches, the player has scored much less than 46.45. Because of only 1 match where he scored 400, the overall summary is kind of distorted. Such data points are called outliers. In such cases, a better measure of average is “Median”, which is the middle point of the data values. In our example, we will sort all the data values and choose the middle one.
在这种情况下,均值可能会产生误导,因为在所有比赛中,玩家得分均远低于46.45。 由于只有1场比赛他获得了400分,因此总体总结有些失真。 这样的数据点称为离群值。 在这种情况下,更好的平均值度量是“中位数”,它是数据值的中间点。 在我们的示例中,我们将对所有数据值进行排序,然后选择中间的一个。

The median is 12, which is a more appropriate measure of “average” in this case.
中位数为12,在这种情况下,这是“平均值”的更合适度量。
模式: (Mode:)
A lesser-known measurement of “average” is Mode, which is the most frequently occurring data value in our data set. In our example, ‘12’ is repeating 2 times. So the mode is 12. Mean and Median are used for Quantitative variables while Mode comes in handy for Qualitative variables. There will no sense of calculating the mean or median for Qualitative variables like Gender, Colour, etc. Let's say, in our example, we have a column which tells if a particular match was won by the team or if they lost it.
对“平均值”的鲜为人知的度量是“模式”,它是数据集中最频繁出现的数据值。 在我们的示例中,“ 12”重复2次。 因此,模式为12。均值和中位数用于定量变量,而模式在定性变量派上用场。 没有必要计算诸如Gender,Colour等定性变量的平均值或中位数。在我们的示例中,我们有一个列,该列指示团队是否赢得了特定的比赛或他们是否输掉了比赛。

The mode of variable “Match Result” in this case is “Won” since “Won” came 7 times while “Lost” came only 3.
在这种情况下,变量“匹配结果”的模式为“赢”,因为“赢”获得了7次,而“迷失”仅获得了3次。
We can say that on “average”, the team is winning.
可以说,在“平均水平”上,团队是获胜的。
“Mean”, “Median” and “Mode” are the three kinds of measurements of average which give an idea about the “centrality” of data.
“平均值”,“中位数”和“模式”是三种平均值度量,它们给出了数据的“中心性”概念。
But does the average provide enough information when analyzing or summarizing data? There is more which we can do.
但是,平均值在分析或汇总数据时是否提供了足够的信息? 我们还有更多可以做的事。
变异量度 (Measures of Variability)

In addition to finding out the average of a data set, we can also look at how much the data is spread out. Or in other words, how much “variability” is there in the data set. Let us understand it by an example. Till now, we were looking at the scores of a single player. Let's say, we have been given the scores of 2 players of all 10 matches. We have to compare these scores and try to get an idea of how these players have performed in comparison to each other.
除了找出数据集的平均值之外,我们还可以查看数据散布了多少。 换句话说,数据集中有多少“可变性”。 让我们通过一个例子来理解它。 到现在为止,我们正在研究单个玩家的得分。 假设我们在所有10场比赛中得到2位球员的得分。 我们必须比较这些得分,并试图了解这些球员之间的比较情况。
Below is the data set:
以下是数据集:

Both players have a mean(average) of 50. So how can we compare them? One subtle thing to check is “how” these players have averaged over the matches. Is one player more consistent in scoring than others? Is a player scoring huge runs in few matches while scoring very few runs in other matches? How are the scores “varying” across matches for these players?
两位选手的均值(平均值)均为50。那么我们如何比较它们呢? 要检查的一件事是这些球员在比赛中的平均水平。 一个球员的得分是否比其他球员更一致? 玩家是否在很少的比赛中获得高分,而在其他比赛中得分很少? 这些球员在比赛中的得分如何变化 ?
范围 (Range)
A very basic metric to check how the scores are varying is to calculate the range of scores for each player.
检查分数如何变化的一个非常基本的指标是计算每个玩家的分数范围。
Range is simply the difference between the largest and smallest observation in the data.
范围只是数据中最大和最小观测值之间的差。
Range of Player 1 = 200–0 (Highest Score — Lowest Score) = 200
玩家1的范围= 200-0(最高分数—最低分数)= 200
Range of Player 2 = 70–30 = 40
玩家2的范围= 70–30 = 40
Looks like Player 1 has more range of scores than Player 2. It means that the scores of Player 1 tend to have more variety than Player 2. If we look at the data of Player 1 carefully, there are outliers present. In some matches this player is scoring exceptionally high like 200 and in some matches, he is scoring nothing (0). Range can measure how far the values are spread out but it's sensitive to outliers.
看起来,玩家1的得分范围比玩家2更大。这意味着玩家1的得分往往比玩家2更具多样性。如果仔细观察玩家1的数据,就会发现异常值。 在某些比赛中,该球员得分异常高,达到200,而在某些比赛中,他没有得分(0)。 范围可以测量值分布的距离,但对异常值敏感。
四分位间距(IQR): (Inter-quartile Range (IQR):)
One way to overcome the shortfall of Range is to somehow exclude outliers and construct a ‘mini-range’. One such metric is “Inter-quartile range”. We sort the data in ascending order and divide the data values into 4 groups(quartiles). We then consider only the middle 50% values. This gives us Inter-quartile range.
克服范围不足的一种方法是以某种方式排除异常值并构建“迷你范围”。 一种这样的度量标准是“四分位数间距”。 我们按升序对数据进行排序,然后将数据值分为4组(四分位数)。 然后,我们仅考虑中间的50%值。 这使我们达到四分位间距。
IQR for Player 1:
玩家1的IQR:
0 0 0 0 40 50 50 50 100 200
0 0 0 0 40 50 50 50 100 200
We have 10 scores. The position of lower Quartile is n/4 = 3 (after rounding)
我们有10分。 下四分位数的位置为n / 4 = 3(四舍五入后)
The position of Upper Quartile is 3n/4 = 8(after rounding)
高四分位的位置是3n / 4 = 8(四舍五入后)

IQR is (Score at Position 8— Score at Position 3)
IQR为(位置8的得分-位置3的得分)
IQR = 50–0 = 50
IQR = 50-0 = 50
IQR for Player 2:
玩家2的IQR:
30 34 46 50 50 50 54 56 60 70
30 34 46 50 50 50 54 56 60 70
We have 10 scores. The position of lower Quartile is n/4 = 3 (after rounding)
我们有10分。 下四分位数的位置为n / 4 = 3(四舍五入后)
The position of Upper Quartile is 3n/4 = 8(after rounding)
高四分位的位置是3n / 4 = 8(四舍五入后)

IQR is (Score at Position 8— Score at Position 3)
IQR为(位置8的得分-位置3的得分)
IQR = 56–46 = 10
IQR = 56–46 = 10
A special graph called “Box and Whisker” plot is used to visualize ranges.
称为“箱形和晶须”图的特殊图形用于可视化范围。

For a given data attribute it shows 5 metrics:
对于给定的数据属性,它显示5个指标:
- Minimum Value 最低值
- Maximum Value 最大值
- Median 中位数
- Quartile 1 四分位数1
- Quartile 3 四分位数3
Let's compare the scores of the two players by drawing box and whiskers plots:
让我们通过绘制方框图和晶须图来比较两个玩家的得分:
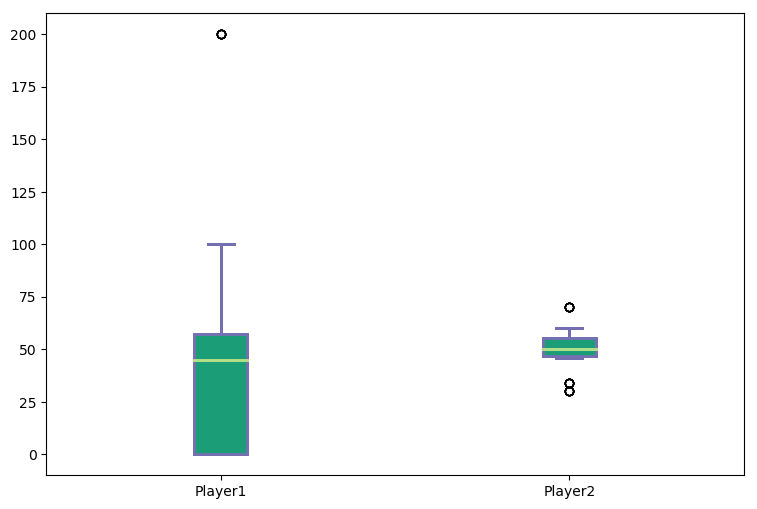
As evident from the above graph, Player 1 has more variations as compared to Player 2. The median or mean for both players is same but the scores for Player 1 differ from mean a lot more than Player 2. We can say that Player1 is less “consistent” than Player 2. Though the highest score for Player 1 i.e 200 is much more than the highest score of Player 2 (70), but he is not consistent in scoring runs.
从上图可以明显看出,与玩家2相比,玩家1的变化更大。两个玩家的中位数或均值相同,但玩家1的得分与均值的差异比玩家2大得多。我们可以说玩家1的得分更低比玩家2“一致”。尽管玩家1的最高得分(即200)比玩家2的最高得分(70)高得多,但他的得分并不始终如一。
A more effective way to judge the performance of a player is to find out much a player deviates from its “mean” score. The more the deviation, the less consistent a player is. The less the deviation, the more consistent a player is.
判断玩家表现的更有效方法是找出玩家偏离其“平均”得分的情况。 偏差越大,玩家的一致性就越差。 偏差越小,球员越稳定。
方差 (Variance)
Variance is simply a metric that expresses the “deviation” in a data attribute from its mean. You don’t have to memorize the below formula for Variance:
方差只是一个度量,表示数据属性与平均值之间的“偏差”。 您不必记住以下方差公式:

Remember, we are trying to find out how much variation is there in a data attribute. So, we can take the following simple steps:
请记住,我们正在尝试找出数据属性中有多少变化。 因此,我们可以采取以下简单步骤:
- Calculate the mean of the data attribute 计算数据属性的平均值
- Find the difference between each data point and the mean. It actually gives us how much a data value varies from the mean or average. Now this difference can be either positive or negative (because the data value can be smaller or bigger than the mean). To avoid negative and positive numbers cancelling each other, we can take the square of it. 找出每个数据点与平均值之间的差异。 它实际上为我们提供了一个数据值与平均值或平均值相差多少。 现在,此差异可以是正数或负数(因为数据值可以小于或大于平均值)。 为了避免负数和正数相互抵消,我们可以取其平方。
- Take the sum of all the differences 取所有差异的总和
- Divide by the number of data values. This gives us the average variation. 除以数据值的数量。 这给了我们平均变化。
标准偏差 (Standard Deviation)
Standard deviation is simply the square root of Variance
标准差只是方差的平方根

The square root is taken to negate the effect of the square done in Step 2 while calculating Variance.
在计算方差时,取平方根以抵消在步骤2中完成的平方的影响。
Standard Deviation is the measure of spread of data about the mean. It measures roughly how far off the entries are from their average. It tells us how the data is spread out. The more the SD, the more spread out data is. Since its simply a measure, it can’t be negative.
标准差是关于均值的数据分布的度量。 它大致衡量条目与平均值之间的距离。 它告诉我们数据如何散布。 SD越大,数据散布越多。 由于它只是一个量度,因此不能为负。
In our example,
在我们的示例中
The standard deviation of Player 1 = 59.32
玩家1的标准差= 59.32
The standard deviation of Player 2 = 11.06
玩家2的标准差= 11.06

Player2 has much less standard deviation than Player 1. Hence we can say that this player is much more consistent. He has fewer variations in his performance. Though he is not scoring big runs, he is fairly consistent in all his matches.
Player2的标准偏差比Player 1小得多。因此,可以说此Player更加一致。 他的表现变化较少。 尽管他并没有取得大的成绩,但他在所有比赛中的表现都相当稳定。
Think of any variable in nature. If the standard deviation of this variable is large, you can safely say that this variable has a lot of different values. The behavior is not consistent. But if it has a low standard deviation, then you can assume that the behavior of this variable is fairly consistent.
想一下自然界中的任何变量。 如果此变量的标准偏差较大,则可以放心地说此变量具有很多不同的值。 行为不一致。 但是,如果它的标准偏差很低,则可以假定此变量的行为是相当一致的。
Have you got a friend who is mostly calm, at all times while there is another one who is very moody(sometimes angry, sometimes composed, sometimes indifferent)? You now know whose “standard deviation” is bigger.
您有没有一个朋友在任何时候都比较平静,而另一个朋友却很喜怒无常(有时会生气,时而沉稳,时而冷漠)? 您现在知道谁的“标准偏差”更大。
If a variable has a constant value, what would be its standard deviation? You don't need the formula. It will be 0.
如果变量具有恒定值,其标准偏差是多少? 您不需要公式。 它将是0。
“Average” and “Deviations from Average” are 2 things that should be kept in mind while studying a data set.
在研究数据集时,应牢记“ 平均值 ”和“偏离平均值”两件事。
翻译自: https://towardsdatascience.com/measuring-change-54bb44e26a14
如何衡量二次曲线的变化趋势

















 330
330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









