






张玉欣
⋆
{ }^{\star}
⋆ 范美浩
⋆
{ }^{\star}
⋆ 范菊
⋆
{ }^{\star}
⋆ 易明洋
⋆
{ }^{\star}
⋆ <br>罗宇宇
⋄
{ }^{\diamond}
⋄ 谭健
⊙
{ }^{\odot}
⊙ 李国良
⋆
{ }^{\star}
⋆
中国人民大学
⋆
{ }^{\star}
⋆ 香港科技大学(广州)
⋄
{ }^{\diamond}
⋄
阿里巴巴云计算
⊙
{ }^{\odot}
⊙ 清华大学
⋆
{ }^{\star}
⋆
{yuxin.zhang, fsh1art,fanj,yimingyang}@ruc.edu.cn
yuyuluo@hkust-gz.edu.cn, j.tan@alibaba-inc.com, liguoliang@tsinghua.edu.cn
摘要
最近的大语言模型(LLMs)进展显著提高了Text-to-SQL任务的性能,这得益于其强大的推理能力。为了在推理过程中提高准确性,可以在训练和推理阶段引入外部过程奖励模型(PRMs)以提供精细监督。然而,如果使用不当,PRMs可能会扭曲推理轨迹,导致次优或错误的SQL生成。为了解决这一挑战,我们提出了ReWARD-SQL,这是一种系统探索如何有效将PRMs纳入Text-to-SQL推理过程的框架。我们的方法遵循“冷启动,然后PRM监督”的范式。具体来说,我们首先训练模型将SQL查询分解为结构化的逐步推理链,使用公共表表达式(Chain-of-CTEs),建立强大且可解释的推理基线。然后,我们研究了四种集成PRMs的策略,发现将PRM作为在线训练信号(例如GRPO)与PRM引导的推理(例如最佳N采样)相结合可以产生最佳结果。实证表明,在BIRD基准测试中,REWARD-SQL使由7B PRM监督的模型在各种指导策略下实现了 13.1 % 13.1 \% 13.1%的性能提升。值得注意的是,基于Qwen2.5-Coder-7BInstruct的GRPO对齐策略模型在BIRD开发集上达到了 68.9 % 68.9 \% 68.9%的准确率,超过了相同模型大小的所有基线方法。这些结果证明了REWARD-SQL在利用奖励监督进行Text-to-SQL推理的有效性。我们的代码公开可用 3 { }^{3} 3。
1 引言
Text-to-SQL是一项旨在将自然语言问题转换为SQL查询的任务,使非技术用户能够轻松与复杂数据库交互 [ 6 , 18 , 19 , 46 , 14 ] [6,18,19,46,14] [6,18,19,46,14]。该领域的最新进展集中在增强模型推理能力[10, 11, 21, 22, 29]以改进Text-to-SQL性能。然而,扩展推理链本质上增加了幻觉的风险[8, 35],这可能损害模型性能。为了解决这个问题,研究人员提出使用奖励模型来评估和监督LLM输出[2, 25, 16]。从技术角度来看,奖励模型主要分为两类:结果监督奖励模型(ORMs)[36],提供对完整响应的整体评估,以及过程监督奖励模型(PRMs)[15],提供更细粒度的步骤级评估。正如[15]中提到的那样,
预印本。正在审查中。
这项工作是在张玉欣在阿里巴巴云计算实习期间完成的。
†
{ }^{\dagger}
† 对应作者:范菊,易明洋
†
{ }^{\dagger}
† https://github.com/ruc-datalab/RewardSQL
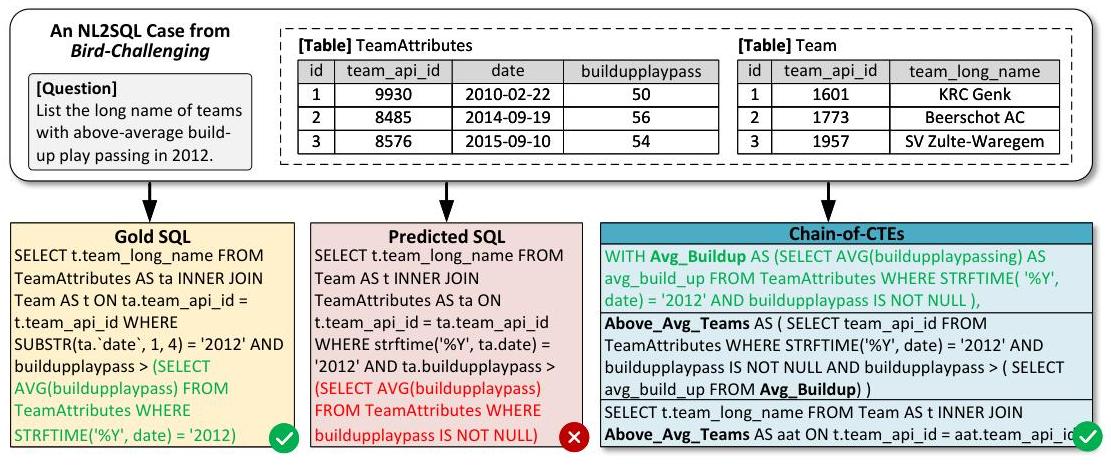
图1:SQL生成的Chain-of-CTEs范式。它将Text-to-SQL过程分解为一系列逐步推理的公共表表达式(CTEs),增强了模型的推理能力。
对于代码生成,PRM在训练过程中提供了更详细的反馈,并能识别推理过程中的关键错误,相比ORM。因此,本文主要关注PRM。
尽管奖励模型对改善输出质量有显著好处,但将其有效应用于Text-to-SQL任务需要仔细考虑。具体来说,对于Text-to-SQL任务,理想的过程奖励模型(PRM)应该准确预测生成的SQL查询是否与真实值对齐,在推理过程中提供可靠的逐步指导。除此之外,提出的PRM还期望在后训练阶段改进Text-to-SQL模型。鉴于这些考虑,一个重要的问题是:
如何有效设计和利用适用于Text-to-SQL任务的PRM?
为回答这个问题,提出了两个关键挑战:
挑战1:CoT(思维链)和PRM设计。从技术角度而言,PRM会对推理过程中的中间推理步骤打分。因此,与为数学问题设计的经典PRM不同[15],设计的PRM应适合Text-to-SQL任务的中间推理步骤(类似于CoT步骤[39])。因此,我们应该首先构建Text-to-SQL的中间推理步骤,并设计一个既理解SQL语法又理解数据库组件之间语义关系的准确PRM。
挑战2:PRM利用。即使有了精心设计的PRM,如何将其最佳整合到训练和推理管道中仍需探索。不同的方法在利用PRM反馈的方式上有所不同,这对模型学习和性能有影响。挑战在于最大化PRM指导的好处,同时确保生成的模型发展出真实的SQL推理能力,而不仅仅是优化奖励信号。
为应对上述挑战,我们首先设计了Text-to-SQL的中间推理步骤,即提议的CoCTEs及其相应的PRM。借助PRM,我们提出了ReWARDSQL,这是一种利用PRM(专为Text-to-SQL应用的CoCTEs设计)增强Text-to-SQL任务推理能力的新框架。我们的框架遵循三阶段设计:1)在推理模板数据上进行监督微调(SFT)作为冷启动;2)过程奖励模型训练;3)探索PRM使用方式,如图2所示。
首先,我们将Chain-of-CTEs(CoCTE)作为专门针对Text-to-SQL的中间推理步骤。从技术角度来看,CoCTE是专门为Text-to-SQL设计的思维链(CoT),将复杂查询分解为一系列公共表表达式(CTEs)。公共表表达式是在SQL查询中定义的临时命名结果集,使得复杂查询更加易于管理和阅读[23]。如图1所示,CoCTE允许逐步构建复杂的SQL查询,有效解决了在处理复杂嵌套查询时预测SQL中经常出现的条件缺失问题。
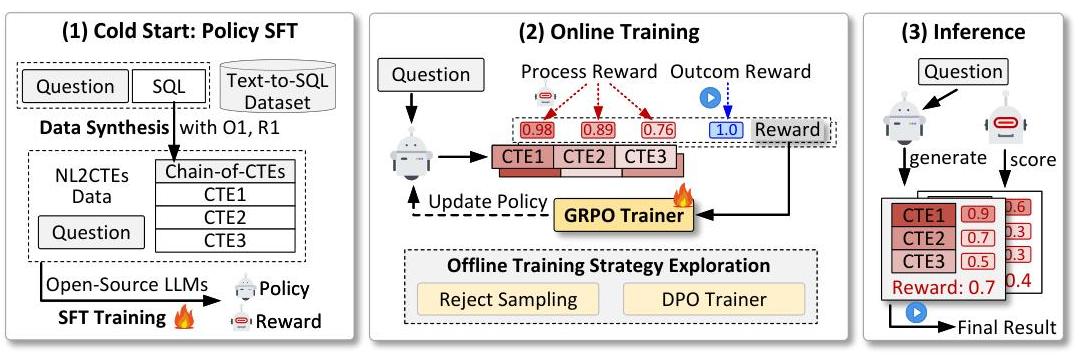
图2:REWARD-SQL框架概述。它包括三个主要阶段:1)冷启动,模型学习将SQL生成分解为结构化的Chain-of-CTEs;2)PRM监督后训练,使用PRM通过各种基于RL的方法(如GRPO、拒绝采样和DPO)引导策略模型;3)PRM辅助推理,使用PRM通过增加测试时间计算成本来提高推理质量。
通过定义的CoCTE,我们可以让模型以推理模式进行推理。为此,我们首先在准备好的CoCTE格式训练集上进行SFT作为“冷启动”[4]过程。然后,我们训练一个专用的PRM来评估CoCTE的中间步骤,为每个推理组件的正确性提供细粒度反馈。最后,为了设计在后训练阶段使用PRM的方式,我们系统地探索了四种代表性方法,通过奖励模型指导策略模型:两种离线方法(拒绝采样[24]和DPO[30])、一种在线方法(GRPO[4])和一种奖励增强推理方法(最佳选择之一[15])。
我们的实证结果有三点。1)在训练阶段使用PRM在线效果最好,因为它充分利用了所有带有适当权重的数据样本。2)对于离线方法,DPO通过有效利用负例超过了拒绝采样。3)在推理过程中结合PRM进行多样本选择显著提高了响应质量,展示了测试时模型扩展的巨大潜力。基于最佳方法(即使用PRM在线训练),采用Qwen2.5-Coder-7B-Instruct作为骨干,PRM监督优化的GRPO策略模型在基准数据集BIRD开发集上的执行准确率达到
68.9
%
68.9 \%
68.9%,为同类规模模型建立了新的最先进水平。
我们的贡献可以总结如下:
- 我们引入了Chain-of-CTEs(CoCTE)及其对应的PRM训练管道。提议的CoCTE是一种新颖的Text-to-SQL推理范式,将复杂的SQL查询分解为可解释的、逐步的公共表表达式。
-
- 我们系统地设计并探索了奖励模型在Text-to-SQL中的应用,发现在线方法始终优于离线方法。基于这些观察,我们提出了我们的REWARD-SQL框架,这是一种端到端的后训练框架,用于提高Text-to-SQL模型的推理能力。
-
- 我们的方法在BIRD开发集上达到 68.9 % 68.9 \% 68.9%的准确率,为7B参数模型建立了新的最先进水平。
2 相关工作
推理任务的奖励建模。最近,奖励模型被整合到各种推理任务中以监督输出质量,包括数学和代码生成[34, 40, 45]。从技术角度来看,奖励模型分为ORMs和PRMs。与ORMs的整体评估相比,PRMs提供细粒度的步骤级评估,这最近引起了广泛关注。自从[15]提出PRMs,并展示了它们在解决数学问题方面的优越性以来,PRM在推理和后训练阶段都被利用。在推理阶段,PRM被用来通过最佳选择[N][15, 42]指导推理路径。另一方面,PRMs也被用来监督后训练阶段[3, 32],而在此论文中提出类似过程用于Text-to-SQL的研究仍有待探索。
大语言模型推理用于Text-to-SQL。最近的Text-to-SQL进展出现了许多基于推理的方法[27, 44, 26]。这些方法的基本思想是将复杂的SQL生成任务分解为逐步推理子任务。这些方法可分为无需训练和基于训练的方法。
无需训练的方法利用了大语言模型的强大泛化能力[31],主要是通过提示技术以不同方式引出中间推理步骤。这些包括上下文学习方法[5, 9],设计提示模板[26]。此外,测试时扩展方法[16],如Alpha-SQL[10],通过蒙特卡洛树搜索(MCTS)[41]在推理过程中动态扩展推理步骤。这增强了模型的适应性,并实现了零样本能力,而无需额外的训练数据。另一方面,基于训练的方法专注于设计推理格式的数据集,其中大语言模型通过在精心策划的训练数据上进行微调来学习Text-to-SQL推理,使用标准的后训练方法。例如,这些包括DPO [17], GRPO [29], 和带自奖励模型的监督微调[21]。
尽管在奖励建模和Text-to-SQL推理方面取得了这些进展,但在Text-to-SQL任务中系统探索奖励模型的应用仍未得到充分研究。大多数现有方法要么不利用奖励模型,要么无法有效地在整个训练和推理阶段集成它们。我们的工作通过全面调查专为Text-to-SQL推理设计的各种奖励建模策略,填补了这一空白,探索它们在训练和推理阶段的应用,以最大限度地提高推理性能。
3 基础知识
3.1 问题公式化和语言模型
Text-to-SQL任务旨在将自然语言查询
x
=
{
q
,
d
b
}
x=\{q, d b\}
x={q,db}转换为相应的SQL查询
y
y
y,其中
q
q
q表示用户的查询,
d
b
d b
db是数据库模式。目标是生成能够根据给定的模式
d
b
d b
db正确回答用户查询
q
q
q的
y
y
y。
由于Text-to-SQL任务的结构,它适合由大型语言模型(LLMs)来解决,因为它们是自动回归序列生成器。具体来说,给定输入提示
x
x
x,参数化为
θ
\theta
θ的LLM模型
π
θ
\pi_{\theta}
πθ通过建模条件概率生成一系列令牌:
π θ ( y ∣ x ) = ∏ t = 1 T π θ ( y t ∣ x , y < t ) \pi_{\theta}(y \mid x)=\prod_{t=1}^{T} \pi_{\theta}\left(y_{t} \mid x, y_{<t}\right) πθ(y∣x)=t=1∏Tπθ(yt∣x,y<t)
其中
y
t
y_{t}
yt表示位置
t
t
t处的令牌,
y
<
t
y_{<t}
y<t表示在
t
t
t之前生成的令牌。因此在这种情况下,对于Text-to-SQL,查询
x
=
{
q
,
d
b
}
x=\{q, d b\}
x={q,db}是条件,而SQL是生成的序列。
思维链(CoT)[39]推理扩展了这个框架,通过将复杂任务分解为中间推理步骤。而不是直接生成最终答案
y
y
y,模型首先生成一个推理过程
C
=
{
c
1
,
c
2
,
…
,
c
k
}
C=\left\{c_{1}, c_{2}, \ldots, c_{k}\right\}
C={c1,c2,…,ck},其中每个
c
i
c_{i}
ci代表一个不同的推理步骤。然后从这个推理过程中得出最终答案:
π θ ( C , y ∣ x ) = π θ ( C ∣ x ) ⋅ π θ ( y ∣ x , C ) = ∏ i = 1 K π θ ( c i ∣ x , c < i ) ⋅ π θ ( y ∣ x , C ) \pi_{\theta}(C, y \mid x)=\pi_{\theta}(C \mid x) \cdot \pi_{\theta}(y \mid x, C)=\prod_{i=1}^{K} \pi_{\theta}\left(c_{i} \mid x, c_{<i}\right) \cdot \pi_{\theta}(y \mid x, C) πθ(C,y∣x)=πθ(C∣x)⋅πθ(y∣x,C)=i=1∏Kπθ(ci∣x,c<i)⋅πθ(y∣x,C)
这种方法允许模型将复杂问题分解为更简单的子问题,使推理过程明确并与人类解决问题的方法更加一致。
链式CTE(CoCTE)是我们为Text-to-SQL任务引入的一种专门的CoT格式,利用了通用表表达式(CTEs)[23]。CTE是由SQL查询定义的命名临时结果集,可以在后续SQL语句的范围内引用,从而实现结构化的逐步推理。
定义1(通用表表达式)一个通用表表达式(CTE)是由SQL查询 q i \mathrm{q}_{i} qi定义的名为临时结果集 c i c_{i} ci,可以在SQL语句的范围内引用:
c i A S ( q i ) c_{i} A S\left(\mathrm{q}_{i}\right) ciAS(qi)
其中
q
i
\mathrm{q}_{i}
qi可以引用数据库表和/或先前定义的CTEs
c
j
c_{j}
cj(对于
j
<
i
j<i
j<i)。关键词AS将CTE名称与其查询定义连接起来。
定义2(链式CTEs)链式CTEs(COCTE)是一系列相互连接的CTEs
C
=
{
c
1
,
c
2
,
…
,
c
k
}
C=\left\{c_{1}, c_{2}, \ldots, c_{k}\right\}
C={c1,c2,…,ck},后面跟着一个生成答案的最终查询
q
f
\mathrm{q}_{f}
qf:
WITH c 1 A S ( q 1 ) , c 2 A S ( q 2 ) , … , c K A S ( q K ) q f \text { WITH } c_{1} A S\left(\mathrm{q}_{1}\right), c_{2} A S\left(\mathrm{q}_{2}\right), \ldots, c_{K} A S\left(\mathrm{q}_{K}\right) \mathrm{q}_{f} WITH c1AS(q1),c2AS(q2),…,cKAS(qK)qf
这里,每个CTE c i c_{i} ci代表一个独立的推理步骤,最终的SQL查询 y y y从这个推理过程中得出,作为 f ( C ) f(C) f(C)。
COCTE的目标是确保用户查询 q q q的意图通过 C C C中的推理步骤准确捕捉。可以看出,使用COCTE进行推理提供了两个关键优势:
- 可解释性:每个CTE生成一个具体的、可执行的中间结果。
-
- 灵活性:COCTE形成一个有向无环图,其中每个步骤都可以引用任何前一步骤。
3.2 过程奖励建模推理
过程奖励建模(PRM)旨在评估COCTE格式的逐步推理过程。PRM被定义为从
x
×
C
x \times C
x×C到
[
0
,
1
]
[0,1]
[0,1]的映射,其中
x
=
{
q
,
d
b
}
x=\{q, d b\}
x={q,db}表示输入,
C
=
{
c
1
,
c
2
,
…
,
c
k
}
C=\left\{c_{1}, c_{2}, \ldots, c_{k}\right\}
C={c1,c2,…,ck}表示推理步骤序列。输出是一个概率得分,表示特定推理步骤正确的可能性。
在COCTE的背景下,PRM评估推理序列中的每个CTE步骤
c
i
c_{i}
ci,并分配一个概率得分
σ
i
\sigma_{i}
σi,以指示该特定步骤的正确性。此得分反映了CTE正确实现回答用户查询所需中间计算的可能性。这种步骤级评估提供了推理过程的详细反馈,使训练过程中的详细反馈和推理过程中的质量评估成为可能。
4 模型初始化
如前所述,为了解决Text-to-SQL问题,我们需要两个关键组件:一个生成COCTE格式SQL查询的策略模型和一个评估推理步骤质量的过程奖励模型(PRM)。由于缺乏现有的COCTE格式数据,我们的初始化过程包括两个步骤:1)策略模型冷启动,我们将标准SQL查询转换为COCTE格式;2)过程奖励模型训练,我们开发一个模型来评估每个推理步骤的正确性。
4.1 策略模型冷启动
具体来说,我们在基准数据集BIRD [13]的训练集上进行此操作。我们首先手动编写一些原始SQL的CoCTEs,并用它们作为示例,提示强大的推理LLMs将其他SQL语句转换为CoCTEs。对于推理LLMs,我们使用DeepSeek-R1-Distill-Qwen-32B进行多次采样,并从o1-mini收集数据以增加多样性。对于生成的CoCTEs,我们在数据库中执行它们,并保留与原始SQL匹配的那些。我们在附录A.2中提供了数据收集过程的详细统计信息。
语法树编辑距离。在我们的收集过程中,我们观察到来自LLMs的COCTE数据在单一问题下具有高相似性,这降低了模型的性能。为了保留结构多样化的CoCTEs并过滤语义相似的CoCTEs,我们提出了树编辑距离过滤器以去重类似的CoCTEs。具体来说,对于同一问题下的CoCTEs,我们使用sqlglot 4 { }^{4} 4包将每个CoCTE解析为语法树,然后计算彼此的先序遍历序列的编辑距离。我们使用归一化的编辑距离作为两个CoCTEs之间的相似度。然后我们为每个问题设置一个过滤阈值(例如,过滤比率)。通过迭代删除相似度总和最小的CoCTE,我们保留了结构最多样化的CoCTEs以供冷启动过程使用。
4.2 过程奖励模型训练
PRM训练数据生成。按照先前的工作OmegaPRM[20],我们采用蒙特卡洛(MC)估计方法生成用于训练过程奖励模型
4
{ }^{4}
4 https://github.com/tobymao/sqlglot
(PRM) 的步骤级标签。这涉及到识别CoCTE推理链中每个中间步骤的正确性。具体来说,对于BIRD训练集中每个问题,我们使用策略模型采样
n
n
n条推理路径,并采用带有PUCT(Predictor + Upper Confidence bound for Trees)的蒙特卡洛树搜索(MCTS)算法高效探索多种推理路径。PUCT在搜索过程中平衡了探索与利用,确保既考虑有希望的推理路径,也考虑不太可能但潜在正确的路径。
对于每次探索生成的CoCTE,我们在数据库中执行它,并将结果与从真实值得出的预期结果进行比较。在MCTS的搜索过程中,我们对每一步进行多次补全。如果所有的补全都是错误的,我们标记该步为错误并停止探索。否则,如果补全中有正确和错误的样本,我们会标记正确的补全并继续在错误的补全上进行探索。这一过程确保我们定位到了推理链中的第一个错误步骤。该过程的完整数据统计详见附录A.2。
使用步骤级损失训练PRM。经过冷启动后,我们训练了一个PRM并将其应用于CoCTE模型,以便进行后续的强化学习阶段。为此,我们过滤噪声注释并平衡数据集以获得高质量的步骤标记CoCTEs。这些数据用于训练PRM,使用步骤级硬标签目标,其中每个CTE
c
i
c_{i}
ci 在
CoCTE
C
=
{
c
j
}
\operatorname{CoCTE} C=\left\{c_{j}\right\}
CoCTEC={cj} 中通过二分类进行分类,由标签
ξ
i
\xi_{i}
ξi 表示(即,
ξ
i
=
1
\xi_{i}=1
ξi=1 表示正确,
ξ
i
=
0
\xi_{i}=0
ξi=0 表示错误)。值得注意的是,当
c
i
c_{i}
ci 能够到达与真实值匹配的SQL查询
y
y
y 时,它被视为正确的中间步骤。我们的PRM由一个模型初始化,该模型为每个步骤分配一个sigmoid分数
σ
i
\sigma_{i}
σi,表示正确性的概率。然后使用二元交叉熵损失来优化PRM,定义如下:
L P R M = min σ ∑ i = 1 k [ − ξ i log ( s i ) − ( 1 − ξ i ) log ( 1 − s i ) ] \mathcal{L}_{\mathrm{PRM}}=\min _{\sigma} \sum_{i=1}^{k}\left[-\xi_{i} \log \left(s_{i}\right)-\left(1-\xi_{i}\right) \log \left(1-s_{i}\right)\right] LPRM=σmini=1∑k[−ξilog(si)−(1−ξi)log(1−si)]
其中
k
k
k 是序列
C
C
C 中的推理步骤总数。
通过使用硬标签,PRM明确区分了正确步骤和错误步骤,简化了训练过程并确保清晰的决策边界。这种方法使PRM能够有效评估步骤的正确性,为推理细化和质量选择提供了可靠的基础。
5 奖励引导优化策略
在获得“冷启动”策略模型和PRM之后,我们准备系统地探索奖励引导优化策略的设计空间。我们的策略可以分为三大类,它们都是后训练阶段的标准方法:
- 离线训练,我们在数据收集过程中利用PRM评分候选CoCTEs,而不连续更新策略模型。这种方法在计算效率和稳定性方面优于在线方法。
-
- 在线训练,我们在rollouts过程中连续更新策略模型,从而实现更适应的学习。
-
- 奖励辅助推理,在推理过程中利用PRM从多个候选CoCTEs中选择最优CoCTE,从而提高最终SQL生成的质量。
对于每种方法,我们选择了在其他研究中广泛采用的代表性方法[30, 4, 42]。
- 奖励辅助推理,在推理过程中利用PRM从多个候选CoCTEs中选择最优CoCTE,从而提高最终SQL生成的质量。
5.1 奖励设计
我们的奖励框架结合了两个互补组件,以全面评估生成的CoCTEs的质量:
过程奖励(PR):此组件由我们的过程奖励模型(PRM)提供,它评估每个CTE步骤的质量。对于给定的包含
K
K
K个步骤的CoCTE,PRM为每个步骤分配得分
{
s
(
c
1
)
,
s
(
c
2
)
,
…
,
s
(
c
K
)
}
\left\{s\left(c_{1}\right), s\left(c_{2}\right), \ldots, s\left(c_{K}\right)\right\}
{s(c1),s(c2),…,s(cK)},反映推理质量。整体过程奖励计算为这些步骤级得分的平均值:
P R ( C ) = 1 K ∑ i = 1 K s ( c i ) P R(C)=\frac{1}{K} \sum_{i=1}^{K} s\left(c_{i}\right) PR(C)=K1i=1∑Ks(ci)
结果奖励(OR):此二进制组件评估最终SQL查询执行时是否产生正确结果。它定义为:
O R ( C ) = { 1 如果执行结果与真实值匹配 0 否则 O R(C)= \begin{cases}1 & \text { 如果执行结果与真实值匹配 } \\ 0 & \text { 否则 }\end{cases} OR(C)={10 如果执行结果与真实值匹配 否则
训练与推理奖励:在训练过程中,我们使用组合奖励提供全面反馈:
R
training
=
P
R
(
C
)
+
O
R
(
C
)
R_{\text {training }}=P R(C)+O R(C)
Rtraining =PR(C)+OR(C)
然而,在推理过程中,由于没有真实值无法确定执行正确性,我们仅依赖过程奖励进行候选选择:
R
inference
=
P
R
(
C
)
R_{\text {inference }}=P R(C)
Rinference =PR(C)
这种双重奖励设计确保我们的优化策略在训练过程中同时考虑推理过程的质量(PR)和最终结果的正确性(OR),并在推理时没有真实值的情况下提供实用的评估机制(仅PR)。
5.2 离线训练
拒绝采样(RS)。我们通过使用策略模型 π θ \pi_{\theta} πθ为每个问题生成多个CoCTEs,然后根据PR和OR得分进行过滤来实现拒绝采样[24]。具体来说,对于每个问题 q q q,我们采样 N N N个候选CoCTEs { C 1 , C 2 , … , C N } \left\{C_{1}, C_{2}, \ldots, C_{N}\right\} {C1,C2,…,CN}并计算它们的奖励得分 { R 1 , R 2 , … , R N } \left\{R_{1}, R_{2}, \ldots, R_{N}\right\} {R1,R2,…,RN}。我们只保留得分超过预定义阈值 τ \tau τ的候选者:
D filtered = { ( q , C i ) ∣ R i > τ , i ∈ { 1 , 2 , … , N } } \mathcal{D}_{\text {filtered }}=\left\{\left(q, C_{i}\right) \mid R_{i}>\tau, i \in\{1,2, \ldots, N\}\right\} Dfiltered ={(q,Ci)∣Ri>τ,i∈{1,2,…,N}}
然后使用标准最大似然估计对策略模型进行微调:
L R S = max θ E ( q , C ) ∼ D filtered [ log π θ ( C ∣ q ) ] \mathcal{L}_{\mathrm{RS}}=\max _{\theta} \mathbb{E}_{(q, C) \sim \mathcal{D}_{\text {filtered }}}\left[\log \pi_{\theta}(C \mid q)\right] LRS=θmaxE(q,C)∼Dfiltered [logπθ(C∣q)]
直接偏好优化(DPO)。DPO [30] 利用了CoCTEs之间的比较信息。对于每个问题 q q q,我们识别出一对CoCTEs ( C w , C l ) \left(C_{w}, C_{l}\right) (Cw,Cl),其中 C w C_{w} Cw的奖励得分高于 C l C_{l} Cl。基于Bradley-Terry (BT) [1]偏好模型,我们得到以下分类类型的DPO损失:
L D P O = min θ − E ( q , C w , C l ) ∼ D [ log σ ( β log π θ ( C w ∣ q ) π ref ( C w ∣ q ) − β log π θ ( C l ∣ q ) π ref ( C l ∣ q ) ) ] \mathcal{L}_{\mathrm{DPO}}=\min _{\theta}-\mathbb{E}_{\left(q, C_{w}, C_{l}\right) \sim \mathcal{D}}\left[\log \sigma\left(\beta \log \frac{\pi_{\theta}\left(C_{w} \mid q\right)}{\pi_{\text {ref }}\left(C_{w} \mid q\right)}-\beta \log \frac{\pi_{\theta}\left(C_{l} \mid q\right)}{\pi_{\text {ref }}\left(C_{l} \mid q\right)}\right)\right] LDPO=θmin−E(q,Cw,Cl)∼D[logσ(βlogπref (Cw∣q)πθ(Cw∣q)−βlogπref (Cl∣q)πθ(Cl∣q))]
其中 π ref \pi_{\text {ref }} πref 是参考策略模型(通常是初始策略模型), β \beta β是控制偏好信号强度的温度参数, σ \sigma σ是sigmoid函数。这种公式鼓励策略模型为奖励得分更高的CoCTEs分配更高的概率,同时保持接近参考模型分布。
5.3 在线训练
对于在线训练过程,我们重点关注最近提出的组相对策略优化(GRPO)[32],它有效地利用步骤级PRM得分来指导策略更新。
GRPO. 在GRPO中,我们使用当前策略模型
π
θ
\pi_{\theta}
πθ为每个问题
q
q
q生成一组CoCTEs
{
C
1
,
C
2
,
…
,
C
G
}
\left\{C_{1}, C_{2}, \ldots, C_{G}\right\}
{C1,C2,…,CG}。与需要单独价值函数模型的传统RL方法不同,GRPO使用组间相对优势来减少方差和计算负担。
在在线RL方法中,奖励模型对于训练模型的最终性能至关重要[25]。为进一步提高性能,我们结合PRM基础和规则基础奖励进行全面评估,如第5.1节所述。PRM为每个CoCTE提供步骤级得分,而规则基础组件根据执行结果是否与真实值匹配分配总体得分。每个CoCTE的最终奖励是这两个组件的总和,有效捕获了推理质量和执行正确性。
给定一个问题
q
q
q,对于每个
COCTE
C
i
=
{
c
i
1
⋯
c
i
K
i
}
\operatorname{COCTE} C_{i}=\left\{c_{i}^{1} \cdots c_{i}^{K_{i}}\right\}
COCTECi={ci1⋯ciKi},长度为
K
i
K_{i}
Ki,中间步骤为
c
i
j
c_{i}^{j}
cij,我们的奖励模型可以为每个CTE提供步骤级得分
{
s
(
c
i
j
)
}
j
=
1
K
i
\left\{s\left(c_{i}^{j}\right)\right\}_{j=1}^{K_{i}}
{s(cij)}j=1Ki。然后我们计算每个COCTE的代表性得分,并在组内进行归一化以获得相对优势:
s ˉ i = 1 K i ∑ j = 1 K i s ( c i j ) , A ^ i = s ˉ i − μ σ \bar{s}_{i}=\frac{1}{K_{i}} \sum_{j=1}^{K_{i}} s\left(c_{i}^{j}\right), \quad \hat{A}_{i}=\frac{\bar{s}_{i}-\mu}{\sigma} sˉi=Ki1j=1∑Kis(cij),A^i=σsˉi−μ
其中
μ
\mu
μ和
σ
\sigma
σ是
{
s
ˉ
i
}
i
=
1
G
\left\{\bar{s}_{i}\right\}_{i=1}^{G}
{sˉi}i=1G的均值和标准差。
为了获得细粒度的步骤级优势,考虑到每个COCTE的相对质量和其步骤内的质量变化,我们根据每个CTE的得分和整个COCTE的优势分配优势值:
A ^ i j = { A ^ i ⋅ s ( c i j ) if A ^ i > 0 A ^ i ⋅ ( 1 − s ( c i j ) ) if A ^ i < 0 \hat{A}_{i}^{j}= \begin{cases}\hat{A}_{i} \cdot s\left(c_{i}^{j}\right) & \text { if } \hat{A}_{i}>0 \\ \hat{A}_{i} \cdot\left(1-s\left(c_{i}^{j}\right)\right) & \text { if } \hat{A}_{i}<0\end{cases} A^ij=⎩ ⎨ ⎧A^i⋅s(cij)A^i⋅(1−s(cij)) if A^i>0 if A^i<0
这种公式确保在一个正优势的
COCTE
(
A
^
i
>
0
)
\operatorname{COCTE}\left(\hat{A}_{i}>0\right)
COCTE(A^i>0)中,得分较高的步骤获得更大的优势,而在一个负优势的
COCTE
(
A
^
i
<
0
)
\operatorname{COCTE}\left(\hat{A}_{i}<0\right)
COCTE(A^i<0)中,得分较低的步骤获得更大的负优势,有效地放大了学习信号。附录A.3.2展示了我们奖励设置的有效性,并揭示了[32]提出的方法中存在的潜在奖励欺骗问题。
GRPO目标函数定义如下:
L GRPO = E q ∼ D , { C i } i = 1 G ∼ π θ o l d ( ⋅ ∣ q ) [ 1 G ∑ i = 1 G 1 K i ∑ j = 1 K i min ( π θ ( c i j ∣ q , c i < j ) π θ o l d ( c i j ∣ q , c i < j ) A ^ i j , clip ( π θ ( c i j ∣ q , c i < j ) π θ o l d ( c i j ∣ q , c i < j ) , 1 − ϵ , 1 + ϵ ) A ^ i j ) ] − β D K L ( π θ ∥ π ref ) \begin{aligned} \mathcal{L}_{\text {GRPO }}= & \mathbb{E}_{q \sim \mathcal{D},\left\{C_{i}\right\}_{i=1}^{G} \sim \pi_{\theta_{\mathrm{old}}}(\cdot \mid q)}\left[\frac{1}{G} \sum_{i=1}^{G} \frac{1}{K_{i}} \sum_{j=1}^{K_{i}}\right. \\ & \left.\min \left(\frac{\pi_{\theta}\left(c_{i}^{j} \mid q, c_{i}^{<j}\right)}{\pi_{\theta_{\mathrm{old}}}\left(c_{i}^{j} \mid q, c_{i}^{<j}\right)} \hat{A}_{i}^{j}, \operatorname{clip}\left(\frac{\pi_{\theta}\left(c_{i}^{j} \mid q, c_{i}^{<j}\right)}{\pi_{\theta_{\mathrm{old}}}\left(c_{i}^{j} \mid q, c_{i}^{<j}\right)}, 1-\epsilon, 1+\epsilon\right) \hat{A}_{i}^{j}\right)\right]-\beta D_{K L}\left(\pi_{\theta} \| \pi_{\text {ref }}\right) \end{aligned} LGRPO =Eq∼D,{Ci}i=1G∼πθold(⋅∣q)[G1i=1∑GKi1j=1∑Kimin πθold(cij∣q,ci<j)πθ(cij∣q,ci<j)A^ij,clip πθold(cij∣q,ci<j)πθ(cij∣q,ci<j),1−ϵ,1+ϵ A^ij −βDKL(πθ∥πref )
其中 ϵ \epsilon ϵ是裁剪参数, β \beta β控制KL正则化的强度, π ref \pi_{\text {ref }} πref 是参考策略。我们像[25]中那样估计一个无偏的非负KL散度:
D K L ( π θ ∥ π ref ) = π ref ( c i j ∣ q , c i < j ) π θ ( c i j ∣ q , c i < j ) − log π ref ( c i j ∣ q , c i < j ) π θ ( c i j ∣ q , c i < j ) − 1 D_{K L}\left(\pi_{\theta} \| \pi_{\text {ref }}\right)=\frac{\pi_{\text {ref }}\left(c_{i}^{j} \mid q, c_{i}^{<j}\right)}{\pi_{\theta}\left(c_{i}^{j} \mid q, c_{i}^{<j}\right)}-\log \frac{\pi_{\text {ref }}\left(c_{i}^{j} \mid q, c_{i}^{<j}\right)}{\pi_{\theta}\left(c_{i}^{j} \mid q, c_{i}^{<j}\right)}-1 DKL(πθ∥πref )=πθ(cij∣q,ci<j)πref (cij∣q,ci<j)−logπθ(cij∣q,ci<j)πref (cij∣q,ci<j)−1
这种方法允许通过聚焦奖励识别的有希望的推理路径,更有效地探索COCTE空间,同时在步骤级别提供细粒度监督。
5.4 奖励辅助推理
对于奖励辅助推理,我们实现了Best of N采样[15],这是现代LLM应用中广泛采用的方法,可以有效地利用我们的PRM选择高质量输出。
Best of N。这种方法涉及使用策略模型
π
θ
\pi_{\theta}
πθ为给定的问题
q
q
q生成
N
N
N个候选COCTEs
{
C
1
,
C
2
,
…
,
C
N
}
\left\{C_{1}, C_{2}, \ldots, C_{N}\right\}
{C1,C2,…,CN},使用多样化的采样策略(例如,温度采样,核采样)。然后使用PRM评估每个候选对象以获得得分
{
P
R
(
C
1
)
,
P
R
(
C
2
)
,
…
,
P
R
(
C
N
)
}
\left\{P R\left(C_{1}\right), P R\left(C_{2}\right), \ldots, P R\left(C_{N}\right)\right\}
{PR(C1),PR(C2),…,PR(CN)}。得分最高的候选对象被选为最终输出。
这种方法可以形式化为选择最大化预期奖励的COCTE:
C ∗ = arg max C ∈ C q E [ P R ( C ∣ q ) ] C^{*}=\arg \max _{C \in \mathcal{C}_{q}} \mathbb{E}[P R(C \mid q)] C∗=argC∈CqmaxE[PR(C∣q)]
其中
C
q
\mathcal{C}_{q}
Cq是问题
q
q
q的潜在候选COCTE集合,
P
R
(
C
∣
q
)
P R(C \mid q)
PR(C∣q)是PRM评估的奖励函数。
可以看出,与前述方法相比,Best of N是无需训练的,并且与它们正交。
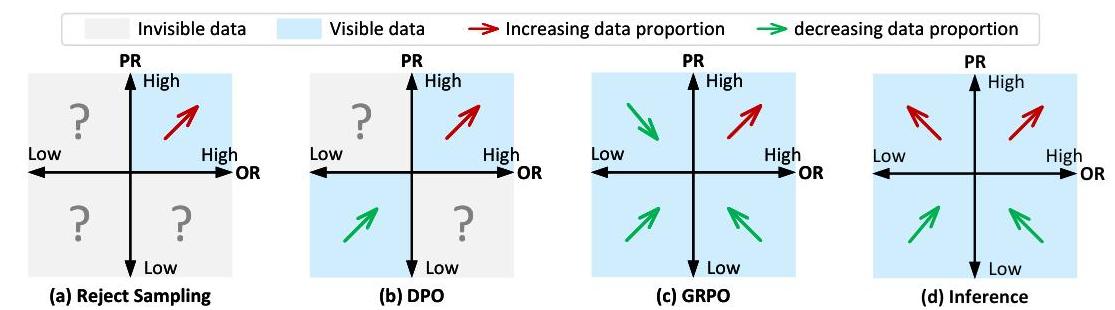
图3:不同方法在PR-OR空间中的优化模式。
5.5 PR-OR空间中优化方法的比较分析
由于前述的损失公式,四种数据利用方法应在PR-OR空间中产生不同分布的输出,如图3所示。接下来,让我们详细阐述这一点。
- Reject Sampling仅在PR高且OR正确的样本(右上象限)上进行训练,可能限制探索和从错误中学习的机会;2) DPO虽然是离线的,但它利用了最佳样本(右上象限)和次优样本(左下象限)之间的比较信息,使模型能够区分有效的推理模式。然而,其二元偏好结构可能会忽略混合表现区域中的有价值信号;3) GRPO结合了四个PR-OR象限的加权信号,捕捉了完整的推理模式。这种全面的方法能够在探索成功模式的同时进行有效利用,从而在各种查询类型中实现更稳健的优化,尽管其复杂的奖励加权机制可能会引入训练不稳定性;4) Best-of-N采样在推理时间运行,通过多个候选对象补充基于训练的方法,通过探索高PR区域并选择预测奖励最高的对象。这种方法有效地识别了在基本策略下以低概率发生但高质量的输出,尽管会增加推理计算成本。
综上所述,虽然所有前述方法都有潜力改进Text-to-SQL模型的推理过程,但也面临相应的缺点。因此,哪种方法在实践中表现最佳仍有待探索。接下来,我们将通过实验证实这些方法的输出是否如分析分布,并找出实际中最优的方法。
6 实验
在本节中,我们通过实验证实了在第5节中提出的奖励引导优化策略的最佳方案。然后,基于观察结果,我们提出了我们的REWARD-SQL方法,并将其与其他基线方法进行比较。
6.1 实验设置
数据集。我们的实验主要在BIRD [13]数据集上进行。BIRD是一个Text-to-SQL基准测试,包含9,428个训练对,1,534个开发对和1,789个测试对。它具有复杂的数据库和具有挑战性的问题,需要增强的推理能力。我们利用BIRD训练集进行模型训练,并使用开发集进行独立同分布(i.i.d.)评估。
指标:我们使用执行准确率(EX)来评估预测SQL查询相对于真实值的正确性。该指标在数据库中执行预测SQL和真实值,并比较执行结果是否匹配,有效验证了预测在真实数据库环境中的正确性。
对于推理,我们实施了两种策略以全面评估模型性能:贪婪解码和vote@n。在贪婪设置中,我们将温度设置为零并采样一次以获得最可能的结果。对于vote@n,例如Best of N,如前所述,它与基于训练的方法正交。因此,我们引入它以展示Text-to-SQL任务中的测试时间扩展能力。通过vote@n,模型生成n个不同的响应,并使用选择机制(例如奖励模型如PRM、自一致性或MCTS)来识别最佳响应。
6.2 奖励模型探索结果
我们首先系统地分析了第5.5节中提到的不同奖励引导方法的有效性。我们将样本分为四个象限,基于过程奖励(PR)和结果奖励(OR)。这些象限有助于评估不同方法如何导航PR-OR空间及其在最大化期望结果(高PR,正确OR)方面的有效性。符号" + “和”-“分别表示"高"和"低”,例如,+PR/+OR表示高PR和高OR,位于图 3 5 3^{5} 35的右上区域。
表1:不同方法在BIRD开发集上的选择有效性分析。
| 模型 | +PR/+OR
(
%
)
↑
(\%) \uparrow
(%)↑ | +PR/-OR
(
%
)
↓
(\%) \downarrow
(%)↓ | -PR/-OR
(
%
)
↓
(\%) \downarrow
(%)↓ | -PR/+OR
(
%
)
↓
(\%) \downarrow
(%)↓ | EX 准确率
(
%
)
↑
(\%) \uparrow
(%)↑ |
| :-- |
| 模型 | +PR/+OR ( % ) ↑ (\%) \uparrow (%)↑ | +PR/-OR ( % ) ↓ (\%) \downarrow (%)↓ | -PR/-OR ( % ) ↓ (\%) \downarrow (%)↓ | -PR/+OR ( % ) ↓ (\%) \downarrow (%)↓ | EX 准确率 ( % ) ↑ (\%) \uparrow (%)↑ |
|---|---|---|---|---|---|
| 贪婪解码 | |||||
| SFT | 51.8 | 24.8 | 20.8 | 2.7 | 54.4 |
| SFT + RS | 51.8 | 23.9 | 22.2 | 2.1 | 54.0 |
| SFT + DPO | 56.5 | 21.8 \mathbf{2 1 . 8} 21.8 | 18.6 | 3.1 | 59.6 |
| SFT + GRPO | 58.4 \mathbf{5 8 . 4} 58.4 | 28.2 | 12.1 \mathbf{1 2 . 1} 12.1 | 1.3 \mathbf{1 . 3} 1.3 | 59.7 \mathbf{5 9 . 7} 59.7 |
| Best-of-32 解码 | |||||
| SFT | 66.4 | 28.7 | 4.3 | 0.5 | 67.0 |
| SFT + RS | 66.9 | 28.0 | 4.7 | 0.4 | 67.3 |
| SFT + DPO | 66.8 | 28.4 | 4.2 | 0.6 | 67.4 |
| SFT + GRPO | 68.7 \mathbf{6 8 . 7} 68.7 | 27.8 \mathbf{2 7 . 8} 27.8 | 3.3 \mathbf{3 . 3} 3.3 | 0.2 \mathbf{0 . 2} 0.2 | 68.9 \mathbf{6 8 . 9} 68.9 |
训练时间的奖励模型引导。首先,让我们探索通过三种策略在训练过程中整合奖励模型信号:RS和DPO作为离线方法,GRPO作为在线方法。
表1揭示了比较这些训练时间引导方法时出现的有趣模式。1)在贪婪解码下,RS显示出+PR/+OR率的最小变化,对其他指标的影响有限,仅减少了+PR/-OR,导致执行准确率略有下降(
54.0
%
54.0 \%
54.0% vs.
54.4
%
54.4 \%
54.4% 对于SFT)。我们推测这源于RS只能看到+PR/+OR样本,并且对其他样本的辨别能力较差;2)与RS相比,DPO实现了显著的+PR/+OR改进和-PR/-OR减少,反映了其从高PR-OR样本对比低PR-OR样本中的有效学习;3)GRPO在所有指标上表现出最全面的改进,在贪婪解码下具有最高的+PR/+OR率、最低的-PR/-OR率和最低的-PR/+OR率,验证了其有效利用PR-OR空间所有象限数据的能力。
测试时间的奖励模型引导。如前所述,Best-of-N解码与基于训练的方法正交。我们的结合实证结果见表1。可以看出,使用PRM进行Best-of-N选择可以一致地提高所有模型变体的性能。对于基础SFT模型,PRM选择显著提高了执行准确率,带来了实质性的
12.6
%
12.6 \%
12.6%绝对提升。此外,以SFT为例,PRM显著将+PR/+OR率提高到
66.4
%
66.4 \%
66.4%(相对于贪婪解码下的
51.8
%
51.8 \%
51.8%),同时保持较低的-PR/+OR率仅为
0.5
%
0.5 \%
0.5%。这表明我们的奖励模型即使在没有额外训练基础模型的情况下,也能有效地区分有效和无效的推理过程。
此外,结合Best-of-N解码也显著提高了三种基于RL的方法,尤其是GRPO。我们推测这是因为GRPO训练模型的多样性(通过GRPO期间的探索捕捉到)增加了正确答案出现在生成的32个候选答案中的可能性。
基于这些发现,我们将SFT+GRPO+PRM管道作为我们的Reward-SQL框架(如图2所示)。这种集成方法结合了基础模型微调、在线奖励优化和测试时间奖励引导选择的优势,使我们能够在复杂SQL生成任务中实现卓越性能。
6.3 与其他基线的比较
基线。根据先前的研究,我们将当前方法分为两类:LLM上的提示和LLM上的后训练。包含的基线都是该领域内的标准方法。
我们在Qwen2.5-Coder-7B-Instruct模型下训练所提出的Reward-SQL方法,而基线方法则在不同模型下实现,遵循已报告的结果。如第6.2节所述,结合最佳N奖励辅助推理显著提高了我们的ReWard-SQL。我们也在此领域进行了比较,并将其标记为“vote@n”。对于基线,选择最佳答案的方法要么依赖于选择代理[26],要么依赖于MCTS [10, 21],具体取决于原始研究。此外,Reasoning-SQL [29]发现Gemini-Pro模式过滤器进一步提高了性能,因此我们也报告了我们的方法应用此技巧的结果。
表2:在BIRD数据集上我们的ReWARD-SQL与基线的比较。基线方法的结果来自原始研究论文。
| 模型/方法 | EX 准确率 (%) 贪婪 \underset{\text { 贪婪 }}{\text { EX 准确率 (\%) }} 贪婪 EX 准确率 (%) | 选择方法 | |
|---|---|---|---|
| vote@n | |||
| 在LLM上的提示 | |||
| DIN-SQL + GPT-4 [27] | 50.7 | - | - |
| DAIL-SQL + GPT-4 [7] | 54.8 | - | - |
| MAC-SQL + GPT-4 [37] | 59.4 | - | - |
| Chase-SQL + Gemini [26] | - | 73.0 | 选择代理 |
| Alpha-SQL + Qwen2.5-7B [10] | - | 66.8 | MCTS |
| 在LLM上的后训练 | |||
| CodeS + StarCoder-15B [12] | 57.0 | - | - |
| DTS-SQL + DeepSeek-7B [28] | 55.8 | - | - |
| SQL-ol + Qwen2.5-7B[21] | - | 66.7 | MCTS |
| Reasoning-SQL + Qwen2.5-7B [29] | 64.0 | 68.0 | 选择代理 |
| 我们的 | |||
| REWARD-SQL + Qwen2.5-7B | 59.7 | 68.9 | PRM |
| REWARD-SQL + Qwen2.5-7B + Schema Filter | 66.4 | 70.3 | PRM |
结果。BIRD开发集上的结果总结在表2中。从结果来看,我们有以下观察。
- 在相似的7B模型下,我们的Reward-SQL表现最佳,无论是贪婪解码还是vote@n解码。
-
- 即使使用简单的贪婪解码且不使用模式过滤器,我们的Reward-SQL仍优于一些强大的基线模型,例如GPT-4,即 59.7 % 59.7 \% 59.7%相较于DIN-SQL (50.7%)、DAIL-SQL (54.8%) 和MAC-SQL (59.4%)。
-
- 使用我们提出的PRM选择显著提高了我们的ReWard-SQL,尤其是在未使用模式过滤器的情况下(
59.7
%
59.7 \%
59.7%相较于
68.9
%
68.9 \%
68.9%),这进一步表明了我们PRM选择的有效性。
我们进一步进行了全面的消融研究和泛化分析,详细结果请参见附录。在附录B.2中,我们展示了我们的PRM选择方法比替代方法高出多达 12.6 % 12.6 \% 12.6%,并且结合PRM + 规则-OR奖励公式达到了最佳性能。附录B.3显示了我们的模型在Spider上的强大零样本泛化能力,使用PRM@32实现了 81.7 % 81.7 \% 81.7%的执行准确率,超过了更大的模型
像GPT-4o。这些发现确认了我们的方法不仅在分布内示例中表现出色,而且能有效推广到新领域。
- 使用我们提出的PRM选择显著提高了我们的ReWard-SQL,尤其是在未使用模式过滤器的情况下(
59.7
%
59.7 \%
59.7%相较于
68.9
%
68.9 \%
68.9%),这进一步表明了我们PRM选择的有效性。
7 结论
在本文中,我们提出了ReWARD-SQL,这是一个为Text-to-SQL任务构建PRM的框架,并系统地探索了奖励模型在模型训练和推理中的机制。我们对离线训练、在线训练和奖励辅助推理的探索表明,结合PRM推理选择的GRPO取得了最佳结果。实验结果表明,在BIRD数据集上的执行准确率有了显著提高,超过了当前最先进的方法,包括基于GPT-4的方法。ReWARD-SQL的成功突显了复杂SQL生成任务中结构化推理的重要性,并展示了逐步奖励模型如何有效地指导学习过程。
8 致谢
本工作部分由国家自然科学基金(62436010和62441230)以及阿里巴巴集团通过阿里巴巴研究实习生计划支持。
参考文献
[1] Ralph Allan Bradley和Milton E Terry。不完全区组设计的等级分析:I. 配对比较法。Biometrika, 39(3/4), 1952.
[2] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, 和 John Schulman。训练验证器解决数学文字问题。预印本arXiv:2110.14168, 2021.
[3] Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen等。通过隐式奖励的过程强化。预印本,2025.
[4] DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Qu, Hui Li, Jianzhong Guo, Jiashi Li, Jiawei Wang, Jingchang Chen, Jingyang Yuan, Junjie Qiu, Junlong Li, J. L. Cai, Jiaqi Ni, Jian Liang, Jin Chen, Kai Dong, Kai Hu, Kaige Gao, Kang Guan, Kexin Huang, Kuai Yu, Lean Wang, Lecong Zhang, Liang Zhao, Litong Wang, Liyue Zhang, Lei Xu, Leyi Xia, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Meng Li, Miaojun Wang, Mingming Li, Ning Tian, Panpan Huang, Peng Zhang, Qiancheng Wang, Qinyu Chen, Qiushi Du, Ruiqi Ge, Ruisong Zhang, Ruizhe Pan, Runji Wang, R. J. Chen, R. L. Jin, Ruyi Chen, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shengfeng Ye, Shiyu Wang, Shuiping Yu, Shunfeng Zhou, Shuting Pan, 和 S. S. Li。Deepseek-r1:通过强化学习激励LLM的推理能力。预印本arXiv:2501.12948, 2025.
[5] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Tianyu Liu等。关于上下文学习的调查。预印本,2022.
[6] Ju Fan, Zihui Gu, Songyue Zhang, Yuxin Zhang, Zui Chen, Lei Cao, Guoliang Li, Samuel Madden, Xiaoyong Du, 和 Nan Tang。结合小型语言模型和大型语言模型实现零样本NL2SQL。Proc. VLDB Endow., 17(11), 2024.
[7] Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, 和 Jingren Zhou。由大型语言模型赋能的Text-to-sql:基准评估。Proc. VLDB Endow., 17(5), 2024.
[8] Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion等。测量思维链推理的忠实度。预印本arXiv:2307.13702, 2023.
[9] Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, 和 Nan Tang。自然语言到SQL的曙光:我们准备好了吗?[实验、分析 & 基准]。Proc. VLDB Endow., 2024.
[10] Boyan Li, Jiayi Zhang, Ju Fan, Yanwei Xu, Chong Chen, Nan Tang, 和 Yuyu Luo。Alpha-sq1:使用蒙特卡洛树搜索的零样本文本到SQL。预印本arXiv:2502.17248, 2025.
[11] Haoyang Li, Shang Wu, Xiaokang Zhang, Xinmei Huang, Jing Zhang, Fuxin Jiang, Shuai Wang, Tieying Zhang, Jianjun Chen, Rui Shi, Hong Chen, 和 Cuiping Li。Omnisq1:大规模合成高质量文本到SQL数据。预印本arXiv:2503.02240, 2025.
[12] Haoyang Li, Jing Zhang, Hanbing Liu, Ju Fan, Xiaokang Zhang, Jun Zhu, Renjie Wei, Hongyan Pan, Cuiping Li, 和 Hong Chen。Codes:迈向开源文本到SQL的语言模型。Proc. ACM Manag. Data, 2(3), 2024.
[13] Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin Chen-Chuan Chang, Fei Huang, Reynold Cheng, 和 Yongbin Li。LLM是否已经可以作为数据库接口?
一个大规模数据库支持文本到SQL的大规模基准测试。In Advances in Neural Information Processing Systems 36, 2023.
[14] Ziming Li, Youhuan Li, Yuyu Luo, Guoliang Li, 和 Chuxu Zhang。数据库的图神经网络:综述。预印本arXiv:2502.12908, 2025.
[15] Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, 和 Karl Cobbe。让我们一步步验证。In The Twelfth International Conference on Learning Representations, 2023.
[16] Bang Liu, Xinfeng Li, Jiayi Zhang, Jinlin Wang, Tanjin He, Sirui Hong, Hongzhang Liu, Shaokun Zhang, Kaitao Song, Kunlun Zhu, Yuheng Cheng, Suyuchen Wang, Xiaoqiang Wang, Yuyu Luo, Haibo Jin, Peiyan Zhang, Ollie Liu, Jiaqi Chen, Huan Zhang, Zhaoyang Yu, Haochen Shi, Boyan Li, Dekun Wu, Fengwei Teng, Xiaojun Jia, Jiawei Xu, Jinyu Xiang, Yizhang Lin, Tianming Liu, Tongliang Liu, Yu Su, Huan Sun, Glen Berseth, Jianyun Nie, Ian Foster, Logan Ward, Qingyun Wu, Yu Gu, Mingchen Zhuge, Xiangru Tang, Haohan Wang, Jiaxuan You, Chi Wang, Jian Pei, Qiang Yang, Xiaoliang Qi, 和 Chenglin Wu。基础智能体的进步与挑战:从脑启发智能到进化、协作和安全系统。预印本arXiv:2504.01990, 2025.
[17] Hanbing Liu, Haoyang Li, Xiaokang Zhang, Ruotong Chen, Haiyong Xu, Tian Tian, Qi Qi, 和 Jing Zhang。揭示思维链推理对直接偏好优化影响:来自文本到SQL的经验教训。预印本,2025.
[18] Xinyu Liu, Shuyu Shen, Boyan Li, Peixian Ma, Runzhi Jiang, Yuxin Zhang, Ju Fan, Guoliang Li, Nan Tang, 和 Yuyu Luo。大语言模型的NL2SQL综述:我们在哪里,又将走向何方?预印本arXiv:2408.05109, 2024.
[19] Xinyu Liu, Shuyu Shen, Boyan Li, Nan Tang, 和 Yuyu Luo。NL2SQL-Bugs:检测NL2SQL翻译中语义错误的基准。预印本arXiv:2503.11984, 2025.
[20] Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng等。通过自动化过程监督提高语言模型中的数学推理能力。预印本arXiv:2406.06592, 2024.
[21] Shuai Lyu, Haoran Luo, Zhonghong Ou, Yifan Zhu, Xiaoran Shang, Yang Qin, 和 Meina Song。SQL-o1:一种用于文本到SQL的自奖励启发式动态搜索方法。预印本arXiv:2502.11741, 2025.
[22] Peixian Ma, Xialie Zhuang, Chengjin Xu, Xuhui Jiang, Ran Chen, 和 Jian Guo。SQLr1:通过强化学习训练自然语言到SQL推理模型。预印本arXiv:2504.08600, 2025.
[23] Steve Manik。使用公共表表达式在SQL Server 2005中处理临时视图,2005年。
[24] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, 和 John Schulman。Webgpt:带有真人反馈的浏览器辅助问答。预印本arXiv:2112.09332, 2021.
[25] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, 和 Ryan Lowe。通过人类反馈训练语言模型遵循指令。In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022.
[26] Mohammadreza Pourreza, Hailong Li, Ruoxi Sun, Yeounoh Chung, Shayan Talaei, Gaurav Tarlok Kakkar, Yu Gan, Amin Saberi, Fatma Ozcan, 和 Sercan Ö. Arik。CHASE-SQL:多路径推理和文本到SQL中的偏好优化候选选择。预印本arXiv:2410.01943, 2024.
[27] Mohammadreza Pourreza 和 Davood Rafiei。DIN-SQL:分解文本到SQL的上下文学习并自我纠正。In Advances in Neural Information Processing Systems 36, 2023.
[28] Mohammadreza Pourreza 和 Davood Rafiei。DTS-SQL:使用小型大语言模型分解文本到SQL。In Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 12-16, 2024, pages 8212-8220. Association for Computational Linguistics, 2024.
[29] Mohammadreza Pourreza, Shayan Talaei, Ruoxi Sun, Xingchen Wan, Hailong Li, Azalia Mirhoseini, Amin Saberi, 和 Sercan。Reasoning-sql:通过SQL定制的部分奖励进行强化学习以增强推理的文本到SQL。预印本arXiv:2503.23157, 2025.
[30] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, 和 Chelsea Finn。直接偏好优化:你的语言模型实际上是一个奖励模型。In Advances in Neural Information Processing Systems 36, 2023.
[31] Nitarshan Rajkumar, Raymond Li, 和 Dzmitry Bahdanau。评估大语言模型的文本到SQL能力。预印本,2022.
[32] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu等。Deepseekmath:推动开放语言模型中数学推理的极限。预印本arXiv:2402.03300, 2024.
[33] Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, 和 Chuan Wu。Hybridflow:灵活高效的RLHF框架。In Proceedings of the Twentieth European Conference on Computer Systems. ACM, 2025.
[34] Fengwei Teng, Zhaoyang Yu, Quan Shi, Jiayi Zhang, Chenglin Wu, 和 Yuyu Luo。Markov LLM测试时间扩展的思想原子。预印本arXiv:2502.12018, 2025.
[35] Miles Turpin, Julian Michael, Ethan Perez, 和 Samuel Bowman。语言模型并不总是说出它们的想法:思维链提示中的不可信解释。Advances in Neural Information Processing Systems, 36, 2023.
[36] Jonathan Uesato, Nate Kushman, Ramana Kumar, H. Francis Song, Noah Y. Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, 和 Irina Higgins。通过过程和结果反馈解决数学文字问题。预印本arXiv:2211.14275, 2022.
[37] Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, Linzheng Chai, Zhao Yan, Qian-Wen Zhang, Di Yin, Xing Sun, 和 Zhoujun Li。MAC-SQL:一种用于文本到SQL的多智能体协作框架。In International Conference on Computational Linguistics, 2025.
[38] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, 和 Denny Zhou。自一致性改进了语言模型中的思维链推理。In The Eleventh International Conference on Learning Representations, ICLR. OpenReview.net, 2023.
[39] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou等。思维链提示激发了大语言模型中的推理。Advances in neural information processing systems, 35, 2022.
[40] Jinyu Xiang, Jiayi Zhang, Zhaoyang Yu, Fengwei Teng, Jinhao Tu, Xinbing Liang, Sirui Hong, Chenglin Wu, 和 Yuyu Luo。自监督提示优化。预印本arXiv:2502.06855, 2025.
[41] Yupeng Xie, Yuyu Luo, Guoliang Li, 和 Nan Tang。Haichart:人类和AI配对可视化系统。Proc. VLDB Endow., 17(11):3178-3191, 2024.
[42] An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin等。Qwen2.5-math技术报告:通过自我改进实现数学专家模型。预印本arXiv:2409.12122, 2024.
[43] Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, 和 Dragomir R. Radev。Spider:一个大规模人工标注的数据集,用于复杂和跨域的语义解析和文本到SQL任务。In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3911-3921, 2018.
[44] Hanchong Zhang, Ruisheng Cao, Lu Chen, Hongshen Xu, 和 Kai Yu。ACT-SQL:文本到SQL的上下文学习,具有自动生成的思维链。In Findings of the Association for Computational Linguistics: EMNLP. Association for Computational Linguistics, 2023.
[45] Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, 和 Chenglin Wu。Aflow:自动化代理工作流生成。
I
C
L
R
,
2024
I C L R, 2024
ICLR,2024.
[46] Yizhang Zhu, Runzhi Jiang, Boyan Li, Nan Tang, 和 Yuyu Luo。Elliesql:具有复杂感知路由的成本高效文本到SQL。预印本arXiv:2503.22402, 2025.
A 训练细节
A. 1 实现细节
在本节中,我们提供了关于我们的训练设置和超参数的综合细节。对于我们的实验,我们使用了Qwen2.5-Coder-7B-Instruct模型作为基础。所有训练程序都在8块NVIDIA A800 GPU组成的集群上进行。
对于监督微调(SFT),我们采用了1e-5的学习率,并训练了3个epoch。这个初始阶段建立了模型在目标任务上的基本能力。在SFT之后,我们使用相同的学习率1e-5训练了我们的奖励模型(RS)3个epoch,以开发可靠的性能评估机制。
对于我们的强化学习方法,我们在verl平台上实施了不同的策略[33]。Direct Preference Optimization (DPO)是在SFT训练的模型上使用降低的学习率1e-6进行1个epoch的训练,以避免过拟合。对于Grouped Reinforcement Preference Optimization (GRPO),我们使用了1e-6的学习率并在训练数据集上训练了2个epoch。GRPO实现使用了每组包含8个样本的48批次大小,允许模型同时从多样化的解决方案变体中学习。
在其他训练过程中,我们保持了16的一致批次大小,以平衡计算效率和训练稳定性。这种设置使我们能够有效地微调模型,同时管理训练过程的计算需求。
A. 2 模型初始化细节
表3:不同训练阶段的数据集统计
| 阶段 | 数据大小 | 描述 |
|---|---|---|
| 初始CoCTE收集 | 36,103 | 使用DeepSeek-R1-Distill-Qwen-32B和o1-mini从BIRD训练集中生成;通过执行正确性过滤 |
| 语法树去重后 | 18,015 | 应用树编辑距离过滤去除结构相似的CoCTEs后保留的多样化CoCTEs |
| 原始PRM训练数据 | 181,665 | 通过在策略模型上进行MCTS探索生成的带正负CTE标签的CoCTEs |
| 过滤后的PRM训练数据 | 47,287 | 应用规则过滤和编辑距离去重技术后获得的高质量非冗余标签示例 |
数据收集过程 对于冷启动阶段,我们最初通过提示LLMs手动编写示例收集了36,103个CoCTEs。在应用我们的语法树编辑距离过滤器去除结构相似的CoCTEs后,我们保留了18,015个多样化的示例用于策略模型冷启动训练。另外,对于PRM训练,我们首先通过在策略模型上进行MCTS探索生成了181,665个带正负CTE标签的CoCTEs。然后,我们应用基于规则的过滤和编辑距离去重技术,获得了47,287个高质量的非冗余标记示例用于训练。这两个数据收集过程独立进行,以服务于各自的训练目标。
A. 3 GRPO训练中的奖励欺骗
在本节中,我们分析了DeepSeekMath的过程监督方法中的奖励设计,并识别出当将他们的方法应用于我们的设置时出现的奖励欺骗现象。
A.3.1 DeepSeekMath的过程奖励设计
DeepSeekMath [32] 在其GRPO框架中通过为每个推理步骤分配奖励来实现过程监督。对于给定的问题
q
q
q和采样的输出
{
C
1
,
C
2
,
…
,
C
G
}
\left\{C_{1}, C_{2}, \ldots, C_{G}\right\}
{C1,C2,…,CG},其过程奖励模型对输出的每个步骤进行评分,产生:
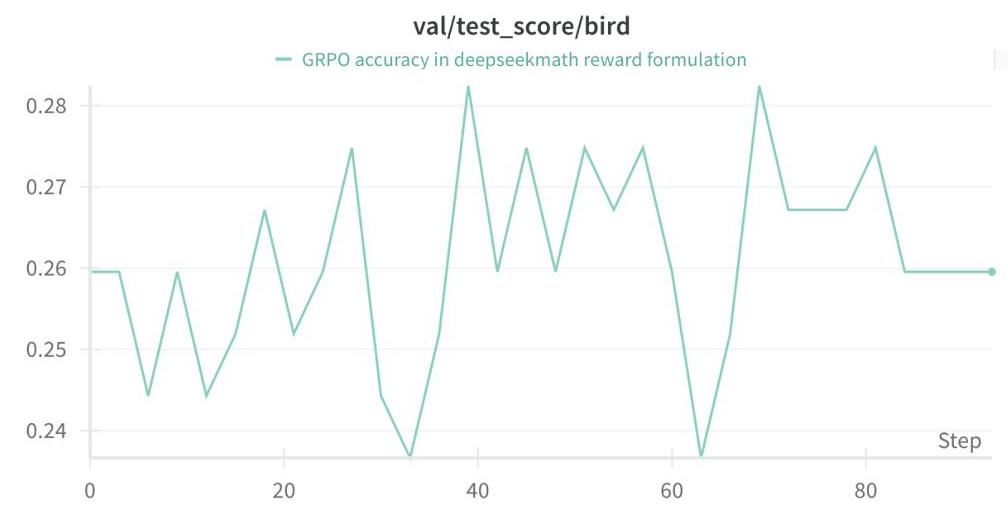
图4:使用DeepSeekMath的奖励公式进行GRPO训练时的性能波动。该模型在具有挑战性的测试集上表现出高度波动,而没有持续改进,这表明由于奖励欺骗而导致优化不稳定。
R = { { s ( c 1 1 ) , … , s ( c 1 K 1 ) } , … , { s ( c G 1 ) , … , s ( c G K G ) } } R=\left\{\left\{s\left(c_{1}^{1}\right), \ldots, s\left(c_{1}^{K_{1}}\right)\right\}, \ldots,\left\{s\left(c_{G}^{1}\right), \ldots, s\left(c_{G}^{K_{G}}\right)\right\}\right\} R={{s(c11),…,s(c1K1)},…,{s(cG1),…,s(cGKG)}}
其中 c i j c_{i}^{j} cij表示第 i i i个CoCTE的第 j j j步, K i K_{i} Ki是第 i i i个CoCTE的总步数。 s ( c i j ) s\left(c_{i}^{j}\right) s(cij)表示相应步骤的奖励得分。这些奖励通过所有步骤的均值和标准差进行归一化:
s ~ ( c i j ) = s ( c i j ) − mean ( R ) std ( R ) \tilde{s}\left(c_{i}^{j}\right)=\frac{s\left(c_{i}^{j}\right)-\operatorname{mean}(R)}{\operatorname{std}(R)} s~(cij)=std(R)s(cij)−mean(R)
然后将每个令牌的优势计算为后续所有步骤归一化奖励的总和:
A ^ i , t = ∑ j : index ( j ) ≥ t s ~ ( c i j ) \hat{A}_{i, t}=\sum_{j: \operatorname{index}(j) \geq t} \tilde{s}\left(c_{i}^{j}\right) A^i,t=j:index(j)≥t∑s~(cij)
A.3.2 奖励欺骗现象
当我们将在DeepSeekMath的奖励公式应用于我们的设置时,我们观察到了显著的奖励欺骗现象。我们的过程奖励模型(PRM)得分来自于完成正确率,这自然呈现出随着解决方案进展而递减的趋势。这是因为达到正确最终答案的概率随着每个步骤的推进而减少,因为解决方案空间缩小并且错误的可能性增加。
DeepSeekMath方法在我们上下文中的关键问题是它在归一化过程中平等地对待所有步骤奖励。当与我们固有的递减PRM得分相结合时,这会创建一个系统偏差:后期步骤相比于前期步骤始终获得更低的优势。结果,模型学会了优化较短的解决方案而不是正确的解决方案。
我们使用Qwen2.5-Coder-1.5B-Instruct模型对此现象进行了实证验证。如图4所示,当使用DeepSeekMath的奖励公式进行训练时,模型在具有挑战性的测试集上的表现表现出高度波动而没有持续改进。更明显的是,图5展示了训练时期间逐渐缩短的输出趋势,强烈证明了奖励欺骗的存在。
这一分析促使我们在第5.3节中提出了替代优势公式,该公式考虑了每个完整解决方案的相对质量和其内部的质量变化

图5:训练时期间的奖励欺骗行为示例。随着训练的进行,模型生成越来越短的解决方案以最大化奖励,牺牲了解决方案的质量和正确性。图中显示了相同的查询如何在训练过程中收到逐步简化的响应,最终无法正确解决问题。
步骤。我们的方法确保优势根据整体解决方案质量进行适当缩放,防止模型利用步骤级奖励的递减趋势。
A. 4 提示
我们的模式设计在提示中参考了M-Schema工作 6 { }^{6} 6,它清楚地定义了数据库结构并提供了样本值,使模型能够更好地理解数据库。我们感谢他们的贡献。
模型训练提示
你现在是一名sqlite数据分析员,给你一个数据库模式如下:
模式:
- DB_ID: retail_complains
-
- 表:reviews
- [
- (Date:DATE, 主键, 示例: [2013-02-04]),
- (Stars:INTEGER, 示例: [5, 1, 2]),
- (Reviews:TEXT)
- ]
-
- 表:client
- [
- (client_id:TEXT, 主键, 示例: [C00000001]),
- (age:INTEGER, 示例: [29, 54, 59]),
- (phone:TEXT, 示例: [367-171-6840])
- ]
-
- 表:events
- [
- (Product:TEXT, 示例: [Bank account or service]),
- (Issue:TEXT, 示例: [Deposits and withdrawals]),
- (Tags:TEXT, 示例: [Older American]),
- (Client_ID:TEXT, 主键, 示例: [C00003714])
- ]
-
- 外键:events.Client_ID=client.client_id
查询:
- 问题:列出Kaitlyn Eliza Elliott提交的所有投诉的问题。
-
- 证据:请仔细阅读并理解数据库模式,并根据用户的问题和证据生成可执行的SQL。
最终SQL:
-
WITH Kaitlyn_Elliott_Client AS (SELECT client_id FROM client WHERE first = ‘Kaitlyn’ AND middle = ‘Eliza’ AND last = ‘Elliott’),
-
- Kaitlyn_Elliott_Complaints AS (SELECT issue FROM events WHERE client_id IN (SELECT client_id FROM Kaitlyn_Elliott_Client))
-
- SELECT DISTINCT issue FROM Kaitlyn_Elliott_Complaints;
图6:模型训练提示。
6 { }^{6} 6 https://github.com/XGenerationLab/M-Schema
- SELECT DISTINCT issue FROM Kaitlyn_Elliott_Complaints;
CoCTE 转换提示
你的任务是使用CTE重写以下SQL查询并注释背后的决策理由。保持连贯的推理过程,确保其自然且无缝,并在理由部分反映这种连贯性。
示例 #1:
- 问题:请列出至少有3名全明星球员的团队名称。
-
- SQL: SELECT players_teams.tmid FROM players_teams INNER JOIN player_allstar ON players_teams.playerid = player_allstar.playerid GROUP BY players_teams.tmid HAVING count(DISTINCT players_teams.playerid) >= 3
-
- 查询
-
- “query1”: “WITH All_Star_Players AS (\n SELECT playerid\n FROM player_allstar\n)”
-
- “query2”: “All_Star_Team_Associations AS (\n SELECT pt.tmid, pt.playerid\n FROM players_teams AS pt\n INNER JOIN All_Star_Players AS asp ON pt.playerid = asp.playerid\n)”
-
- “query3”: “Teams_With_Three_All_Stars AS (\n SELECT at.tmid, COUNT(DISTINCT at.playerid) AS all_star_count\n FROM All_Star_Team_Associations AS at\n GROUP BY at.tmid\n HAVING COUNT(DISTINCT at.playerid) >= 3\n)”
-
- “query4”: “SELECT t.name\nFROM Teams_With_Three_All_Stars AS twa\nINNER JOIN teams AS t ON twa.tmid = t.tmid;”
示例 #2:
・.
- “query4”: “SELECT t.name\nFROM Teams_With_Three_All_Stars AS twa\nINNER JOIN teams AS t ON twa.tmid = t.tmid;”
示例 #3:
…
问题:
- 问题:列出Kaitlyn Eliza Elliott提交的所有投诉的问题。
-
- 模式:{db_schema}
SQL: SELECT DISTINCT EVENTS.issue FROM client INNER JOIN EVENTS ON client.client_id = EVENTS.client_id WHERE client.first = ‘Kaitlyn’ AND client.middle = ‘Eliza’ AND client.last = ‘Elliott’
- 模式:{db_schema}
图7:CoCTE转换提示。
模式过滤提示
评估数据库模式中的列与用户问题的相关性,选择最小必要列集。
模式分析步骤:
- 确定问题中的实体和计算指标
-
- 通过主/外键匹配相关表
-
- 过滤直接与查询条件相关的列
-
- 保留计算所需的数值字段
示例:
-
模式片段
-
- 表:employees
-
[emp_id, emp_name, hire_date, salary, dept_id]
-
- 表:departments
-
[dept_id, dept_name, location]
-
- 问题:计算每个部门的平均工资
-
- 选择结果
-
- “Tables”: [“employees”, “departments”],
-
- “Columns”: {
-
“employees”: [“salary”, “dept_id”],
-
“departments”: [“dept_id”, “dept_name”]
-
}
当前任务:{full database schema}
请选择必要的列以用于: -
问题:列出Kaitlyn Eliza Elliott提交的所有投诉的问题。
-
- 证据:{evidence}
图8:模式过滤提示。
- 证据:{evidence}
B 实验细节
B. 1 案例研究

图9:比较SQL生成方法的案例研究。我们的GRPO训练模型成功处理了一个需要多个约束条件的复杂查询(洛杉矶县测试人数在2,000到3,000之间的学校网站),而基线模型未能包含所有必要的过滤条件。
为了更直观地理解我们的方法如何改进SQL生成,我们在图9中展示了一个案例研究。这个例子展示了我们的方法在处理涉及多个表和过滤条件的复杂查询时的有效性。
查询要求找到洛杉矶县测试人数在2,000到3,000之间的学校的网站。这项任务涉及到连接表、应用数值范围过滤器和特定县的约束条件。基线模型在不同方面难以应对这种复杂性。
标准模型 SFT 在原始训练集上的表现是正确连接了表并应用了数值范围过滤器,但关键遗漏了县过滤条件。这导致了一个不完整的查询,将返回所有县的学校,而不仅仅是洛杉矶县的学校。
在我们转换后的CoCTE训练集上微调的模型也未能包含县过滤条件。虽然它正确识别了测试人数范围内的学校,但完全错过了地理约束。
相比之下,在应用我们的GRPO训练后,模型生成了一个全面的解决方案。它为洛杉矶的学校和测试人数范围内的学校分别创建了单独的CTEs,然后正确地将它们连接起来。这种方法展示了我们的方法如何使模型能够将复杂问题分解为可管理的子查询,保持对所有过滤条件的意识,并以清晰、逻辑的方式构建查询。
这个案例研究表明,我们的过程级奖励建模方法如何引导模型生成更完整和准确的SQL解决方案,特别是对于需要多个约束条件和表关系的查询。这种改进不仅体现在语法上,还反映了对底层数据库模式和查询需求的增强推理能力。
B. 2 消融研究
为了更好地理解我们方法中不同组件的贡献,我们进行了一项全面的消融研究。我们主要关注所提出方法的两个关键组件:1)不同测试时间指导方法的影响;2)GRPO训练中不同奖励公式的影响。
表4:SFT模型不同测试时间选择方法的比较
| 选择方法 | EX 准确率 (%) |
|---|---|
| 贪婪(无指导) | 54.4 |
| 自一致性 | 59.3 ( + 4.9 ) 59.3(+4.9) 59.3(+4.9) |
| ORM | 61.8 ( + 7.4 ) 61.8(+7.4) 61.8(+7.4) |
| PRM | 67.0 ( + 12.6 ) \mathbf{6 7 . 0 (+ 1 2 . 6 )} 67.0(+12.6) |
测试时间指导方法。表4比较了我们提出的PRM选择与其他选择方法ORM [36] 和自一致性 [38] 在BIRD开发集上的表现。可以看出,尽管所有选择方法相比纯贪婪解码提高了EX Acc,但我们提出的PRM选择显著优于其他选择方法。结果清楚地表明,我们的过程级奖励建模方法捕捉到了其他方法未能识别的关键中间推理步骤。
GRPO训练的奖励公式。如第5节所述,在GRPO训练过程中,我们提议结合PRM与基于规则的结果奖励(Rule-OR)。表5显示,尽管仅使用PRM实现了最高的贪婪解码准确率(59.9%),但在考虑两种解码方法,尤其是PRM @32时,结合PRM + Rule-OR的方法整体表现最佳(
68.9
%
68.9 \%
68.9%)。这证明了将基于规则的奖励结果指导与PRM的语义评估相结合,可以为GRPO训练创建更有效的奖励信号。
这些消融研究验证了我们的设计选择,并证明了我们方法的两个组成部分——测试时间的PRM选择和训练期间的混合奖励——对于实现最先进的性能至关重要。移除或替换任何组件都会导致性能显著下降。
B. 3 泛化分析
为了进一步分析我们提出的REWARD-SQL在其他分布上的泛化能力,我们在Spider数据集[43]上进行了实验。Spider是一个大规模、复杂的跨域语义解析和Text-to-SQL数据集,由11名大学生标注。它包含200个数据库覆盖138个不同领域的10,181个问题和5,693个独特的复杂SQL查询。数据集分为8,659个训练样本,1,034个开发样本和2,147个测试样本。
由于我们的模型在训练阶段未接触过Spider的任何数据,因此在该数据集上的评估展示了模型处理不同Text-to-SQL场景的能力。我们将我们的模型与其他LLM在零样本设置下进行比较。
表6:Spider上的性能比较(EX)。
| 模型 | Spider EX (%) |
|---|---|
| GPT-4o | 77.3 |
| o3-mini | 74.7 |
| Gemini-2.5-pro | 83.8 \mathbf{8 3 . 8} 83.8 |
| Qwen2.5-7B | 75.6 |
| Qwen2.5-7B+Reward SQL+Greedy | 77.0 |
| Qwen2.5-7B+Reward SQL+PRM@32 | 81.7 |
如表6所示,我们的模型在Spider基准测试上表现出强大的泛化能力。使用Qwen2.5-7B和我们提出的ReWARD-SQL框架,我们的方法取得了令人印象深刻的
81.7
%
81.7 \%
81.7%执行准确率,超过了甚至更大的模型如GPT-4o(77.3%)和推理模型如o3-mini(
74.7
%
74.7 \%
74.7%)。这证明了我们过程级奖励建模方法在零样本设置下的有效性。
值得注意的是,从贪婪解码(77.0%)到PRM@32(81.7%)的显著提升突显了我们的PRM在推理过程中增强模型性能的关键作用。
4.7
%
4.7 \%
4.7%的绝对提升强调了通过我们的过程级奖励机制探索多个解决方案候选的价值。这些结果确认了我们的方法不仅在训练分布上表现良好,而且能有效地推广到未见过的数据集如Spider,验证了我们的方法在不同SQL生成场景中的稳健性。
B. 4 测试时间计算分析
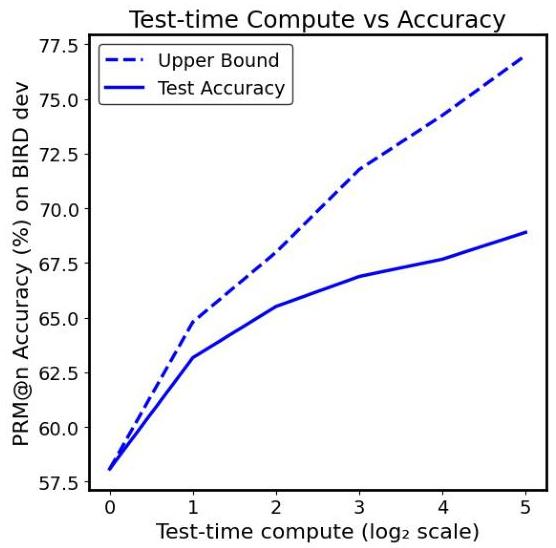
图10:BIRD开发集上的测试时间计算与准确性对比。上限代表理论上的最大性能,即完美选择可实现的性能,而测试准确性显示了使用PRM@n选择的实际模型性能。
测试时间扩展已被验证为一种有效提高各种任务推理能力的方法。在本节中,我们考察了我们的框架如何响应增加的测试时间计算资源。
图10说明了测试时间计算(以 log 2 \log _{2} log2样本数表示)与BIRD开发集上的准确性的关系。结果表明,随着推理时分配更多的计算资源,性能呈现出明显的扩展模式。上限(Pass@n)显示,随着测试时间计算的增加,几乎呈线性增长,从最低计算水平的 58 % 58 \% 58%上升到最高计算水平的 77 % 77 \% 77%。这里,Pass@n表示至少一个生成样本包含正确答案的概率,有效衡量了模型在多次尝试时的能力上限。
我们的PRM@n准确性遵循类似的向上轨迹,从一个样本时的 58.1 % 58.1 \% 58.1%开始,到32个样本时达到 68.9 % 68.9 \% 68.9%。然而,我们观察到,随着计算量的增加,理论上限与实际PRM@n性能之间的差距逐渐扩大。在较低计算水平下,我们的模型性能紧密跟踪上限,但这种差异在较高计算水平下表明仍有未开发的潜力。这种差距扩大表明,尽管我们的方法有效地利用了额外的测试时间计算,但通过额外训练或改进我们的选择机制仍存在显著的提升空间。一致的扩展行为证实了我们的框架可以从测试时间计算扩展策略中受益,与文献中其他推理任务的发现一致。
C 局限性
尽管我们的方法展示了有希望的结果,我们承认存在一些局限性,这些为未来的研究提供了机会:
GRPO训练中的计算开销。我们的GRPO训练方法需要在线执行由不断演变的策略生成的SQL查询。这与离线方法相比引入了巨大的计算开销,因为每个生成的SQL都必须在训练期间与数据库进行验证。实时执行的需求显著延长了训练时间和资源需求,可能限制了其在更大数据集或更复杂数据库环境中的可扩展性。
策略与奖励模型之间的分布偏移。在在线训练期间,策略模型持续更新,可能导致其输出分布偏离奖励模型训练时的分布。这种分布偏移可能会随着训练的进行导致次优的奖励信号。开发稳健、适应性强的奖励模型,能够在不需要频繁重新训练的情况下有效评估不断演变的策略,是一个重大挑战。未来的工可以探索动态更新奖励模型的方法或设计更具分布不变性的评估机制。
这些局限性指出了过程监督SQL生成中未来研究的重要方向。解决这些挑战可以进一步增强我们方法在真实世界数据库环境和复杂查询场景中的实际适用性。
参考论文:https://arxiv.org/pdf/2505.04671


















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











