





抽象语法树ast
Sometimes as you go about your business of being a software engineer, a problem crops up that is unusually interesting, potentially really useful, and also seems like it should be relatively easy to do, given the age of your chosen programming language and the tools already available.
有时候,当您从事软件工程师业务时,出现一个异常有趣,可能真正有用的问题,并且鉴于您选择的编程语言和工具的年代久远,似乎也应该比较容易做到。可用。
Such a situation happened recently with the introduction of a new “item indexer” project at Flipp. This was an attempt to replace a patchwork of existing systems that fetched item information from retailer websites with a single microservice that could do it for all requests.
最近在Flipp引入了一个新的“项目索引器”项目,就发生了这种情况。 这是尝试用单个微服务替换可以从零售商网站中获取商品信息的现有系统的修补程序,该微服务可以满足所有请求。
So far, so groovy — but if we were going to create a unified service, we had to figure out what to do with all the existing indexers we had written in a variety of ways. Every retailer website is different. Some are well-designed, and contain common information in easy-to-read OpenGraph headers or itemprop properties. Many others, though, don’t provide readily available information in nicely semantic tags, and instead we need to rely on xpaths that look like .//div[@class='col-right']/div[@class='product-desc']/h1 .
到目前为止,还很繁琐-但是,如果我们要创建一个统一的服务,我们必须弄清楚该如何处理我们以各种方式编写的所有现有索引器。 每个零售商的网站都是不同的。 其中一些经过精心设计,并在易于阅读的OpenGraph标头或itemprop属性中包含公共信息。 但是,还有许多其他人并没有在语义标记中提供随时可用的信息,相反,我们需要依赖看起来像.//div[@class='col-right']/div[@class='product-desc']/h1 。
By the time we were ready to start the unified indexer project, the count of patchwork indexers was in the hundreds.
当我们准备开始统一索引器项目时,拼凑索引器的数量已达数百个。
The new indexer service had a slightly different format than the old one, largely because we’d moved from the (now out-of-date) Watir gem to Capybara. So… either we spent days manually rewriting each indexer to adhere to the new format, or we tried doing something a bit smarter.
新的索引器服务与旧的索引器服务格式略有不同,主要是因为我们已经将(已经过时的) Watir gem移到了Capybara 。 因此,我们要么花了几天的时间手动重写每个索引器以遵循新格式,要么尝试做一些更聪明的事情。
变化 (The Changes)
Here are some of the major changes we were trying to achieve:
以下是我们正在尝试实现的一些主要更改:
# Module nesting
module ContentAggregation -> module Indexers
module JSParsers class MyRetailer < Base
class MyRetailer < Base ...
... end
end end
end
end# Method renaming
def supplemental_info_price -> def base_price
... ...
end end# Rename browser methods
page.at_xpath("an_xpath") -> page.find("an_xpath")
page.xpath("an_xpath") -> page.all("an_xpath")
div.inner_text -> div.text# Replace unnecessary blank checks, handled by new framework
a.blank? ? a : nil -> a尝试1:gsub! (Attempt 1: gsub!)

The first attempt at translating the indexers was just to use good old gsub and regular expressions. This can actually get us pretty far! It’s pretty good at replacing the top part of each file (the module declaration). However, it relies heavily on every item indexer being written exactly the same way, including spacing, which may or may not be true.
转换索引器的第一个尝试只是使用良好的旧gsub和正则表达式。 这实际上可以使我们走得更远! 替换每个文件的顶部(模块声明)非常好。 但是,它严重依赖于每个项目索引器的编写方式都完全相同,包括间距,该间距可能正确也可能不正确。
One of the big shortcomings is how we’re replacing all instances of end sandwiched by newlines with nothing, and assuming that the only case of that would be the one that ends the module (since we’re reducing nesting by one level). That’s pretty dangerous!
最大的缺点之一是我们如何用空行替换换行符夹在中间的end所有实例,并假定唯一的情况就是终止模块的情况(因为我们将嵌套减少了一层)。 太危险了!
Also note that we didn’t even attempt to do things like replacing the blank check with nil, because of the different variations on spacing and things like that. We could try to spend a lot more time making it more robust, but we’d still have a hard time (e.g.) matching the start of methods to their ends.
还要注意,由于间距和类似的变化,我们甚至都没有尝试过用nil代替空白支票。 我们可以尝试花费更多的时间使它更健壮,但是我们仍然很难(例如)将方法的开始与方法的末尾进行匹配。
尝试2-爬树 (Attempt 2 — Climb the Tree)

Instead of trying to blindly change the text of the Ruby file, I thought it would be much more powerful if we could instead parse and understand the Ruby code itself, and output changes to it. I knew that Rubocop, the Ruby linter and formatter, does that with its auto-correct (where e.g. it can change find to select or vice versa), so it has to be possible somehow, right?
我认为,与其尝试盲目地更改Ruby文件的文本,不如尝试解析和理解Ruby代码本身并输出更改,它会更加强大。 我知道Ruby linter和formatter Rubocop是否可以通过其自动更正功能(例如,它可以更改find以select ,反之亦然),因此必须以某种方式实现,对吧?
An Abstract Syntax Tree (AST) is an internal representation of a piece of code. It’s not specific to Ruby; every language has its own AST as an important step on the way to turn text into machine code. I figured the best way to be sure that I was changing things correctly would be to have some way to key into the AST of the code and make changes at the tree level.
抽象语法树 (AST)是一段代码的内部表示。 它不是特定于Ruby的。 每种语言都有自己的AST,这是将文本转化为机器代码的重要一步。 我想出最好的方法来确保自己正确地更改了某些内容,即可以通过某种方式键入代码的AST并在树级别进行更改。
选项 (The Options)
The first result on Google for “ruby parse code” is the parser gem, a well-maintained library for parsing Ruby code. It even comes with rewriting capability! However, I found the documentation difficult to get through, and there didn’t seem to be a simple example for reading a file, changing it, and writing it back out.
在Google上,“Ruby解析代码”的第一个结果是解析器 gem,这是一个维护良好的用于解析Ruby代码的库。 它甚至具有重写功能! 但是,我发现文档难以理解,似乎没有一个简单的示例来读取文件,更改文件并写回。
I figured I’d try to find something maybe a bit more high-level to work with. The next candidate I found was synvert, which provides the ability to create “snippets” to transform code. This powers transpec, a great tool that converts RSpec 2 syntax into RSpec 3.
我想我会尝试找到一些更高级的东西来使用。 我发现的下一个候选对象是synvert ,它提供了创建“片段”以转换代码的功能。 transpec是一个强大的工具,可以将RSpec 2语法转换为RSpec 3。
Unfortunately, after playing around with this, it turned out it was a little too high-level. When working with very simple replacements, the DSL seems like it would be a great match, but once you go past straightforward insertions or replacements, it becomes unwieldy fast.
不幸的是,在玩了这个之后,事实证明它有点太高级了。 当使用非常简单的替换项时, DSL似乎是一个很好的选择,但是一旦您经过简单的插入或替换,它就会变得难以操作。

After taking a step back, I thought about the original inspiration for this idea, which was Rubocop. How does Rubocop actually do all of its (very complex, at times) rewriting? There are hundreds of “cops” which auto-correct, with dozens of contributors, so there must be an understandable way to write this code! Turns out, it uses good old parser under the hood, but with some additions that make it much sweeter.
退后一步,我想到了这个想法的最初灵感,即Rubocop。 Rubocop实际上如何进行所有(有时非常复杂)的重写? 有几十个贡献者,有成百上千个可以自动更正的“警察”,因此必须有一种可以理解的方式来编写此代码! 事实证明,它在引擎盖下使用了很好的旧parser ,但是添加了一些使其更甜美的parser 。
In fact, the Rubocop project made so many enhancements to parser that they extracted them to a separate gem, rubocop-ast. To understand why it’s so much easier to work with, let’s dive into how parser represents some simple Ruby code:
实际上,Rubocop项目对parser进行了许多改进,以至于将它们提取到单独的gem rubocop-ast中 。 要了解为什么使用它这么容易,让我们深入parser如何表示一些简单的Ruby代码:
def increment(x=1)
x + 1
end->(def :increment
(args
(optarg :x
(int 1)))
(send
(lvar :x) :+
(int 1)))The indented syntax is compact but hard to read, so here’s what a tree version might look like:
缩进的语法紧凑但难以阅读,因此树形版本如下所示:
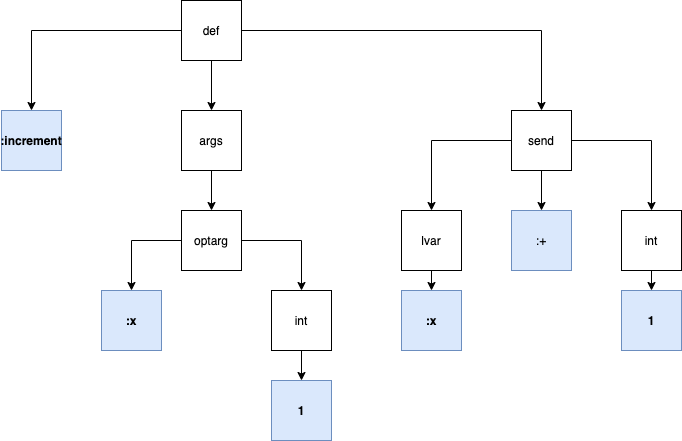
The blue boxes with bold text represent literals (symbols, integers) while the rest represent nodes.
带有粗体文本的蓝色框表示文字(符号,整数),其余部分表示节点。
When I started looking at this, I was kind of overwhelmed. What is an lvar? (Answer: Left-hand-side variable in an assignment.) Where’s the block representing the actual method definition? (Answer: Since it’s a single line, it doesn’t have one.) Where are the symbols like ( and =? (Answer: They aren’t represented in the tree at all.) Digging deeper — if I only want to trigger a change on . and not &. null-safe nodes, how do I ensure that? (Answer: They are separate node types, send and csend.)
当我开始看这个的时候,我有点不知所措。 什么是lvar ? ( 答案:赋值中的左侧变量。 )代表实际方法定义的块在哪里? ( 答案:因为它是单行,所以没有一行。 )符号(和= ?在哪里)( 答案:它们根本不在树中表示。 )深入研究—如果我只想触发在.而不是&. csend安全节点上进行更改时,如何确保呢?( 答案:它们是单独的节点类型,分别是 send 和 csend 。)
More of a problem is that the number of node types in parser are staggering. Node types are defined semantically rather than syntactically, meaning that the if node could represent an actual if statement, or a ternary ( foo ? 1 : 0 ), and only by inspecting the node children could you figure out which one it was.
问题更多的是parser中的节点类型数量惊人。 节点类型是在语义上而不是在语法上定义的,这意味着if节点可以表示实际的if语句或三元( foo ? 1 : 0 ),并且仅通过检查节点子节点才能知道它是哪一个。
rubocop-ast builds on top of the parser gem in two major ways. One is the introduction of specialized Node classes, with a huge number of semantic methods that allow you to more naturally deal with nodes when you have them. For example, the IfNode comes with a ternary? expression, which tells you by inspecting its children whether it’s a ternary or not; the class or module nodes have parent_class methods letting you reference the parent of the declaration.
rubocop-ast通过两种主要方式在parser gem之上构建。 一种是引入专门的Node类,它具有大量的语义方法,使您可以在拥有节点时更自然地处理它们。 例如, IfNode带有ternary? 表达式,通过检查其子项是否为三元来告诉您; class或module节点具有parent_class方法,可让您引用声明的父级。
The second addition is the NodePattern DSL, which is an XPath-like syntax allowing you to match a particular node against a pattern. Both of these are extensively used in Rubocop cops. I didn’t find NodePattern very comfortable, as it reminded me too much of regular expressions, which I find more difficult to reason about than actual code.
第二个添加是NodePattern DSL,它是一种类似于XPath的语法,使您可以将特定节点与模式进行匹配。 两者都被广泛用于Rubocop警察。 我觉得NodePattern不太舒服,因为它让我想起了太多的正则表达式,与实际代码相比,我发现更难以推理。
Although rubocop-ast is a great tool, its documentation was somewhat lacking. In particular, I still couldn’t find a good example of how to rewrite a file. Thankfully, the code itself was understandable enough for me to piece together the right way to do it. In addition, the amount of time I spent poring over the parser docs led me to create a new exhaustive documentation page for rubocop-ast listing the nodes by type (rather than mapping Ruby features to nodes as in the parser docs).
尽管rubocop-ast是一个很好的工具,但它的文档还是有些缺乏。 特别是,我仍然找不到如何重写文件的好例子。 值得庆幸的是,代码本身足以让我理解以正确的方式组合起来。 另外,我花费大量时间研究parser文档,这使我为rubocop-ast创建了一个详尽的文档页面 ,按类型列出了节点(而不是像parser文档中那样将Ruby功能映射到节点)。
改写代码 (Rewriting Code)
With all that said, how do you actually use rubocop-ast to rewrite code? There are two important parts to the parser gem that are critical to this: TreeRewriter and Source::Map .
rubocop-ast ,您实际上如何使用rubocop-ast重写代码? parser gem的两个重要部分对此至关重要: TreeRewriter和Source::Map 。
Each node has a Source::Map you can access by calling node.location (or node.loc). This object is a mapping of AST nodes to actual source code. For example, taking the above example of Ruby code:
每个节点都有一个Source::Map您可以通过调用node.location (或node.loc )进行访问。 该对象是AST节点到实际源代码的映射。 例如,以上面的Ruby代码示例为例:
def increment(x=1)
x + 1
endThe send node representing the single statement in the function would have the following source map:
表示函数中单个语句的send节点将具有以下源映射:
expression:21..26, source:x + 1expression:21..26,来源:x + 1selector:23..24, source:+selector:23..24,来源:+
Each node type will have different location keys depending on what it is (so for example, an if node might have question and colon keys for ternaries). Note that e.g. the expression key includes child nodes as well. Having this information gives us a lot of power by being able to insert, delete or replace content around any individual part of this particular node.
每个节点类型都有不同的位置键取决于它是什么(所以例如, if节点可能有question和colon的ternaries键)。 注意,例如, expression键也包括子节点。 拥有此信息后,我们便能够在该特定节点的任何单个部分周围插入,删除或替换内容,从而为我们提供了强大的功能。
That’s what TreeRewriter is for — once you have one set up, you can use its methods to change the source code by giving it a rangethat references the source. The cool thing about TreeRewriter is that it’s incredibly smart about how to change the code. Each change is put into a queue, and the changes are executed bit by bit, ensuring that the intention of the change isn’t modified.
这就是TreeRewriter目的-一旦设置好,就可以使用它的方法通过给它提供一个引用源的range来更改源代码。 关于TreeRewriter的很酷的事情是,它对如何更改代码非常聪明。 每个更改都放入一个队列中,并逐位执行更改,以确保更改意图不被更改。
For example, you could replace the + with a plus method, and then also add a space before the 1. Here’s a bad way to do that which only records the indexes where you want the changes to happen:
例如,您可以用plus方法替换+ ,然后在1之前添加一个空格。 这是一种不好的方法,它只记录您希望更改发生的位置的索引:
123456789
x + 1 (the 1 is at char 5)
x plus 1
x pl us 1 <<- OOPSIEWith TreeRewriter, all changes happen relatively, and are replayed correctly:
使用TreeRewriter ,所有更改都是相对发生的,并且可以正确重放:
123456789
x + 1
x plus 1
x plus 1解决方案 (The Solution)
Without further ado, here’s what I landed on for my rewriting project. I created a number of processors called Rules, one for each change I wanted to do. I left it up to the TreeRewriter to process them and make sure they didn’t clobber each other. This is just three of the rules I made, but the great thing about this design is that I can make as many as I like and it’ll keep on truckin’!
事不宜迟,这就是我为重写项目着想的内容。 我创建了许多名为“规则”的处理器,每个想要做的更改都一个。 我把它留给TreeRewriter处理,并确保它们不会互相破坏。 这只是我制定的三个规则,但这种设计的妙处在于,我可以根据自己的喜好做出尽可能多的事情,而且它还会继续努力下去!
I felt like this combination of tools gave me the power I needed with the ease of use so that other people could look at the code and not be incredibly confused. I’m happy with what I landed on and hope people find it useful!
我觉得这种工具的组合给了我强大的功能,并且易于使用,以便其他人可以查看代码而不会感到困惑。 我对着陆感到满意,并希望人们发现它有用!
抽象语法树ast















 2061
2061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









