





I recently started a new newsletter focus on AI education. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:
我最近开始了一份有关AI教育的新时事通讯。 TheSequence是无BS(意味着没有炒作,没有新闻等),它是专注于AI的新闻通讯,需要5分钟的阅读时间。 目标是让您了解机器学习项目,研究论文和概念的最新动态。 请通过以下订阅尝试一下:
Graphs are one of the fundamental data structures in machine learning applications. Specifically, graph-embedding methods are a form of unsupervised learning, in that they learn representations of nodes using the native graph structure. Training data in mainstream scenarios such as social media predictions, internet of things(IOT) pattern detection or drug-sequence modeling are naturally represented using graph structures. Any one of those scenarios can easily produce graphs with billions of interconnected nodes. While the richness and intrinsic navigation capabilities of graph structures is a great playground for machine learning models, their complexity posses massive scalability challenges. Not surprisingly, the support for large-scale graph data structures in modern deep learning frameworks is still quite limited. Recently, Facebook unveiled PyTorch BigGraph, a new framework that makes it much faster and easier to produce graph embeddings for extremely large graphs in PyTorch models.
图是机器学习应用程序中的基本数据结构之一。 具体而言,图嵌入方法是无监督学习的一种形式,因为它们使用本机图结构学习节点的表示形式。 社交媒体预测,物联网(IOT)模式检测或药物序列建模等主流场景中的训练数据自然使用图结构表示。 这些方案中的任何一种都可以轻松生成具有数十亿个互连节点的图。 虽然图结构的丰富性和内在的导航功能是机器学习模型的绝佳选择,但其复杂性却带来了巨大的可扩展性挑战。 毫不奇怪,现代深度学习框架中对大规模图形数据结构的支持仍然非常有限。 最近,Facebook推出了PyTorch BigGraph ,这是一个新框架,它可以更快,更轻松地为PyTorch模型中的超大图形生成图形嵌入。
To some extent, graph structures can be seen as an alternative to labeled training dataset as the connections between the nodes can be used to infer specific relationships. This is the approach followed by unsupervised graph embedding methods which learn a vector representation of each node in a graph by optimizing the objective that the embeddings for pairs of nodes with edges between them are closer together than pairs of nodes without a shared edge. This is similar to how word embeddings like word2vec are trained on text.
在某种程度上,图结构可以看作是标记的训练数据集的替代,因为节点之间的连接可以用来推断特定的关系。 这是无监督图嵌入方法所遵循的方法,该方法通过优化以下目标来学习图中每个节点的向量表示:目标之间具有边的节点对的嵌入比没有共享边的节点对更靠近。 这类似于如何在文本上训练像word2vec这样的词嵌入。
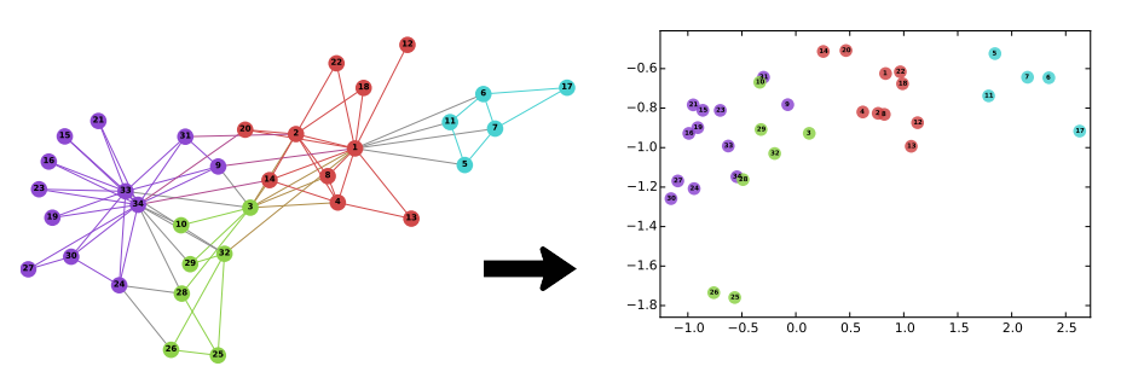
Most graph embedding methods result quite constrained when applied to large graph structures. To give a example, a model with two billion nodes and 100 embedding parameters per node (expressed as floats) would require 800GB of memory just to store its parameters, thus many standard methods exceed the memory capacity of typical commodity servers. To represents a major challenge for deep learning models and is the genesis of Facebook’s BigGraph framework.
当应用于大型图结构时,大多数图嵌入方法的结果受到很大限制。 举个例子,一个具有20亿个节点和每个节点100个嵌入参数的模型(表示为float)将仅需要800GB内存来存储其参数,因此许多标准方法超出了典型商用服务器的内存容量。 代表深度学习模型面临的主要挑战,这是Facebook BigGraph框架的起源。
PyTorch大图 (PyTorch BigGraph)
The goal of PyTorch BigGraph(PBG) is to enable graph embedding models to scale to graphs with billions of nodes and trillions of edges. PBG achieves that by enabling four fundamental building blocks:
PyTorch BigGraph(PBG)的目标是使图嵌入模型能够缩放到具有数十亿个节点和数万亿条边的图。 PBG通过启用四个基本构建块来实现这一目标:
graph partitioning, so that the model does not have to be fully loaded into memory
图形分区 ,从而不必将模型完全加载到内存中
multi-threaded computation on each machine
每台机器上的多线程计算
distributed execution across multiple machines (optional), all simultaneously operating on disjoint parts of the graph
在多台计算机上分布执行 (可选),所有这些操作同时在图的不连续部分上运行
batched negative sampling, allowing for processing >1 million edges/sec/machine with 100 negatives per edge
批量负片采样 ,可处理> 1百万个边缘/秒/机器,每个边缘100个负片
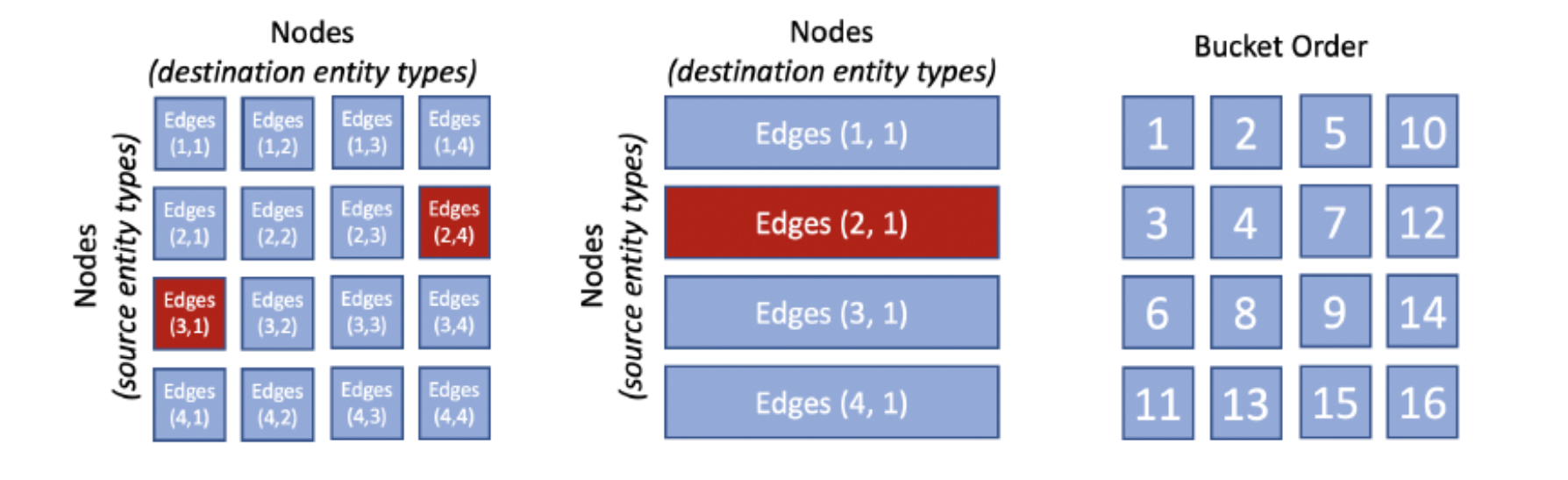
PBG addresses some of the shortcomings of traditional graph embedding methods by partitioning the graph structure into randomly divided into P partitions that are sized so that two partitions can fit in memory. For example, if an edge has a source in partition p1 and destination in partition p2 then it is placed into bucket (p1, p2). In the same model, the graph edges are then divided into P2 buckets based on their source and destination node. Once the nodes and edges are partitioned, training can be performed on one bucket at a time. The training of bucket (p1, p2) only requires the embeddings for partitions p1 and p2 to be stored in memory. The PBG structure guarantees that buckets have at least one previously-trained embedding partition.
PBG通过将图结构划分为随机划分的P个分区来解决传统图形嵌入方法的一些缺点,P个分区的大小使得两个分区可以容纳在内存中。 例如,如果边在分区p1中具有源,而在分区p2中具有目的地,则将其放入存储桶(p1,p2)中。 在同一模型中,然后根据图边缘的源节点和目标节点将其划分为P2个存储桶。 一旦节点和边缘被分区,就可以一次对一个存储桶进行训练。 训练存储桶(p1,p2)仅需要将分区p1和p2的嵌入存储在内存中。 PBG结构可确保存储桶具有至少一个先前训练的嵌入分区。
Another area in which PBG really innovates is the parallelization and distribution of the training mechanics. PBG uses PyTorch parallelization primitives to implement a distributed training model that leverages the block partition structure illustrated previously. In this model, individual machines coordinate to train on disjoint buckets using a lock server which parcels out buckets to the workers in order to minimize communication between the different machines. Each machine can train the model in parallel using different buckets.
PBG真正创新的另一个领域是训练机制的并行化和分布。 PBG使用PyTorch 并行化原语来实现分布式训练模型,该模型利用了先前说明的块分区结构。 在此模型中,单个机器使用锁服务器协调以在不相交的铲斗上进行训练,该服务器将铲斗分包给工人,以最大程度地减少不同机器之间的通信。 每台机器可以使用不同的铲斗并行训练模型。
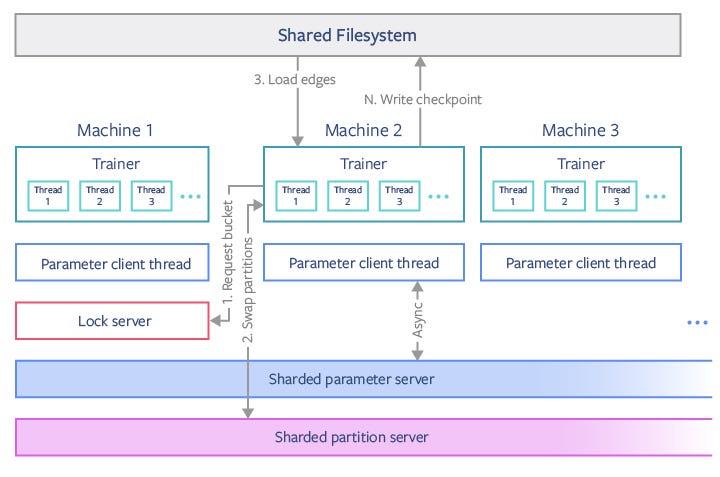
In the previous figure, the Trainer module in machine 2 requests a bucket from the lock server on machine 1, which locks that bucket’s partitions. The trainer then saves any partitions that it is no longer using and loads new partitions that it needs to and from the sharded partition servers, at which point it can release its old partitions on the lock server. Edges are then loaded from a shared filesystem, and training occurs on multiple threads without inter-thread synchronization. In a separate thread, a small number of shared parameters are continuously synchronized with a sharded parameter server. Model checkpoints are occasionally written to the shared filesystem from the trainers. This model allows a set of P buckets to be parallelized using up to P/2 machines.
在上图中,机器2中的Trainer模块从机器1上的锁定服务器请求存储桶,该存储桶锁定该存储桶的分区。 然后,训练器将保存它不再使用的所有分区,并将其需要的新分区加载到分片分区服务器,或从分片分区服务器加载新分区,这时可以在锁定服务器上释放其旧分区。 然后从共享文件系统加载边缘,并且在没有线程间同步的情况下在多个线程上进行训练。 在单独的线程中,少量共享参数与分片参数服务器连续同步。 模型检查点有时会从培训人员写入共享文件系统。 该模型允许使用最多P / 2台机器并行处理一组P桶。
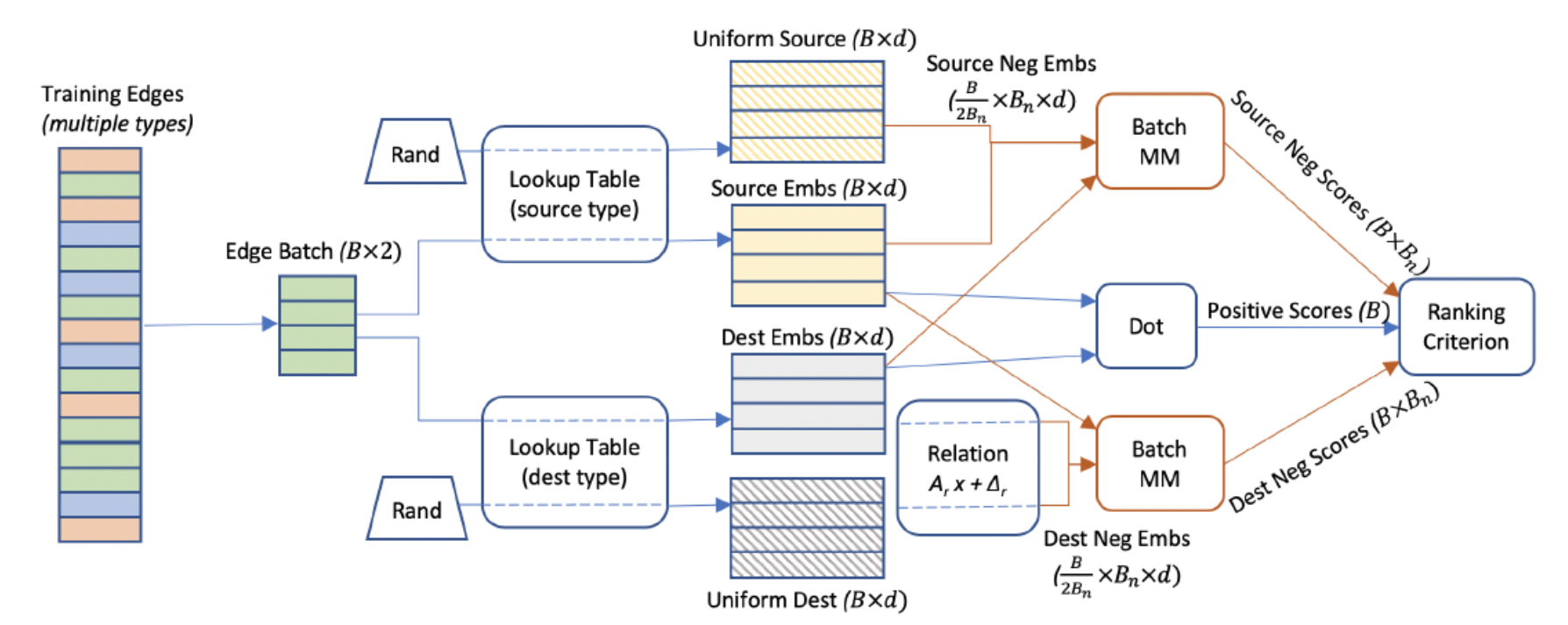
One of the indirect innovations of PBG is the use of batched negative sampling techniques. Traditional graph embedding models, construct random “false” edges as negative training examples along with the true positive edges. This significantly speeds training because only a small percentage of weights must be updated with each new sample. However, the negative samples end up introducing a performance overhead in the processing of the graph and end up “corrupting” true edges with random source or destination nodes. PBG introduces a method that reuses a single batch of N random nodes to produce corrupted negative samples for N training edges. In comparison to other embedding methods, this technique allows us to train on many negative examples per true edge at little computational cost.
PBG的间接创新之一是使用分批负采样技术。 传统的图形嵌入模型将随机的“假”边缘与真实的正边缘一起构造为负训练示例。 这大大加快了训练速度,因为每个新样本仅需更新一小部分的权重。 但是,负样本最终会在图形处理过程中引入性能开销,并最终导致随机源或目标节点“破坏”真实边缘。 PBG引入了一种方法,该方法可以重用N个随机节点的单批来为N个训练边缘生成损坏的负样本。 与其他嵌入方法相比,该技术使我们能够以很少的计算成本在每个真实边缘上训练许多否定样本。
To increase memory efficiency and computational resources on large graphs, PBG leverages a single batch of Bn sampled source or destination nodes to construct multiple negative examples.In a typical setup, PBG takes a batch of B = 1000 positive edges from the training set, and breaks it into chunks of 50 edges. The destination (equivalently, source) embeddings from each chunk is concatenated with 50 embeddings sampled uniformly from the tail entity type. The outer product of the 50 positives with the 200 sampled nodes equates to 9900 negative examples.
为了提高大图上的内存效率和计算资源,PBG利用单批Bn采样的源节点或目标节点来构造多个负样本。将其分成50个边缘的块。 每个块的目标(等效于源)嵌入与从尾部实体类型统一采样的50个嵌入串联在一起。 50个阳性样本与200个采样节点的外部乘积等于9900个阴性样本。
The batched negative sampling approach has a direct impact in the speed of the training of the models. Without batching, the speed of training is inversely proportional to the number of negative samples. Batched training improves that equation achieving constant training speed.
批处理负采样方法直接影响模型训练的速度。 如果不分批处理,则训练速度与阴性样本的数量成反比。 批量训练可改善方程式,实现恒定的训练速度。
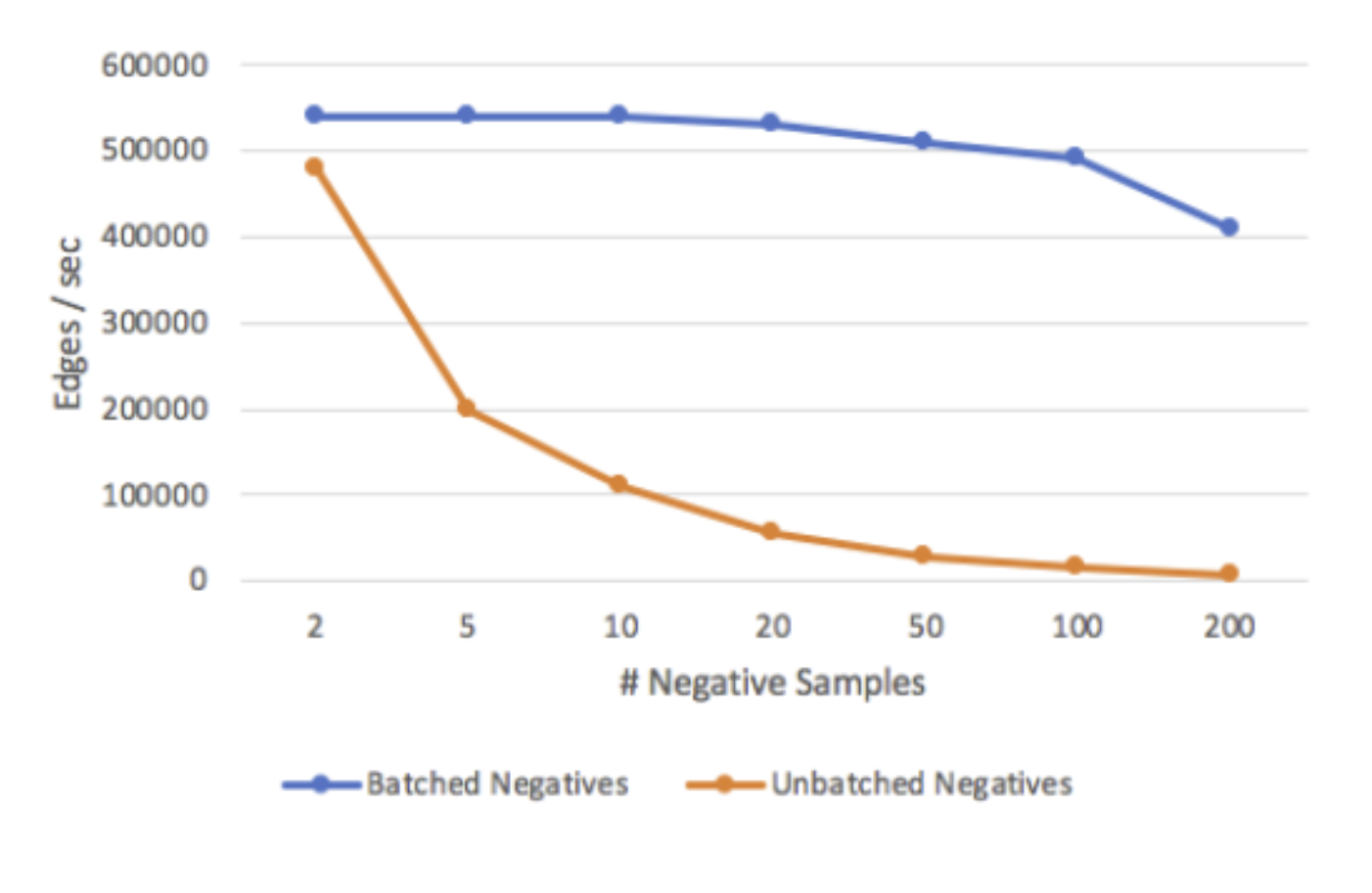
Facebook evaluated PGB using different graph datasets such as LiveJournal, Twitter data and YouTube user interaction data. Additionally, PBG was benchmarked using the Freebase knowledge graph, which contains more than 120 million nodes and 2.7 billion edges as well as a smaller subset of the Freebase graph, known as FB15k, which contains 15,000 nodes and 600,000 edges and is commonly used as a benchmark for multi-relation embedding methods. The FB15k experiments showed PBG performing similarly to state of the art graph embedding models. However, when evaluated against the full Freebase dataset, PBG show memory consumptions improves by over 88%.
Facebook使用不同的图形数据集(例如LiveJournal,Twitter数据和YouTube用户交互数据)评估了PGB。 此外,PBG还使用Freebase知识图进行了基准测试,该知识图包含超过1.2亿个节点和27亿条边以及Freebase图的较小子集,称为FB15k,其中包含15,000个节点和600,000边,通常用作多关系嵌入方法的基准。 FB15k实验表明PBG的性能类似于最新的图形嵌入模型。 但是,当对整个Freebase数据集进行评估时,PBG显示内存消耗提高了88%以上。
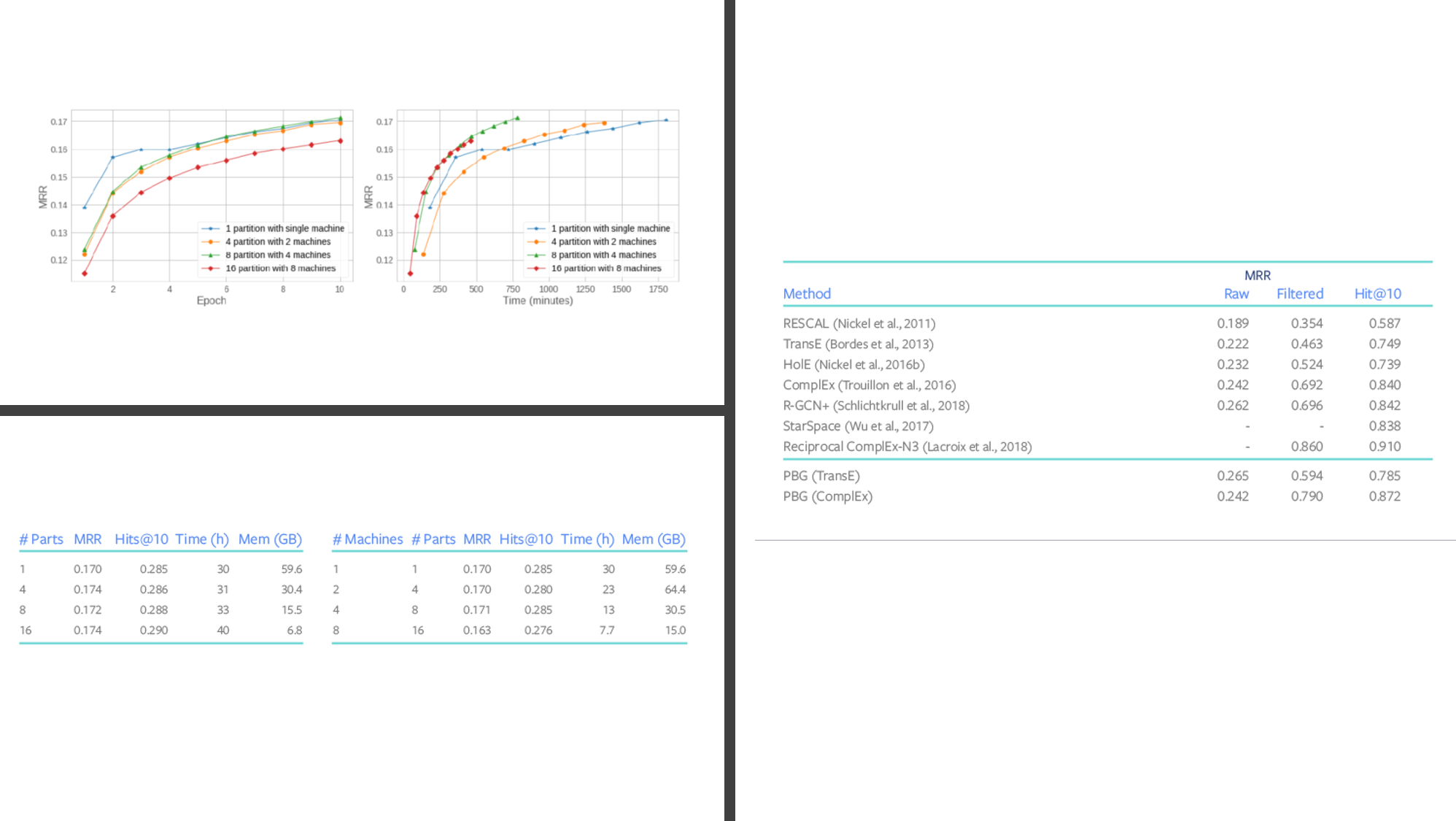
PBG is one of the first methods that can scale and the training and processing of graph data to structures with billions of nodes and trillions of edges. The first implementation of PBG has been open sourced in GitHub and we should expect interesting contributions in the near future.
PBG是最早的方法之一,它可以缩放图形数据并将其训练和处理为具有数十亿个节点和数万亿条边的结构。 PBG的第一个实现已在GitHub上开源 ,我们希望在不久的将来会做出有趣的贡献。















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









