





对抗性攻击
In this article, we will be talking about how Deep Neural Networks are not at their full potential yet, and they are vulnerable to some specially crafted inputs called adversarial examples, which poses security concerns in the physical world with advancement in applications of the deep neural network, like facial recognition, object detection, etc.
在本文中,我们将讨论深度神经网络还没有充分发挥其潜力,并且它们容易受到称为对抗性示例的一些特制输入的影响,随着深度神经网络应用的发展,这在物理世界中引起了安全问题。网络,例如面部识别,物体检测等。
有哪些对抗示例? (What are the Adversarial Examples?)
“They are the inputs to any machine learning models that an attacker intentionally designed to cause the model to mistake.” — Goodfellow et al.
“它们是攻击者故意设计成导致模型错误的任何机器学习模型的输入。” — Goodfellow等 。
One can think of it as an optical illusion for machine learning models. The basic idea is to introduce a small perturbation into the input which is invisible to humans but can fool the well-performing models, e.g. LeNet, Resnet, YOLO, etc.
可以将其视为机器学习模型的一种错觉。 基本思想是在输入中引入很小的扰动,这种扰动对于人类是不可见的,但是会欺骗性能良好的模型,例如LeNet,Resnet,YOLO等。
一些历史 (Some History)
Biggio et al. (2013), first to investigate the poison attacks on the Support Vector Machine (SVM), followed by Szegedy et al. (2014) first to introduce the adversarial examples against deep neural networks by using L-BFGS optimization method and generated “targeted” adversarial examples. The next was the Fast Gradient Sign Method (FGSM) by Goodfellow et al. , 2014b, a one-step method to fast generate adversarial examples (both non-targeted and targeted attacks). And following the trend, many algorithms came like Deepfool, JSMA, BIM/PGD, C&W, etc. Amongst all the attacks, C&W by Carlini and Wagner is the strongest till now with the 100% success rate (targeted attack) on benchmark model Inception V3 model using ImageNet dataset.
Biggio等。 (2013年) ,首先研究了对支持向量机(SVM)的毒药攻击,随后是Szegedy等人。 (2014年)首先通过使用L-BFGS优化方法介绍针对深度神经网络的对抗示例,并生成了“目标”对抗示例。 接下来是Goodfellow等人的快速梯度符号法(FGSM) 。 ,2014b ,这是一种快速生成对抗性示例(非针对性和针对性攻击)的一步方法。 并且随着趋势的发展,出现了Deepfool,JSMA,BIM / PGD,C&W等许多算法。在所有攻击中, Carlini和Wagner所进行的C&W是迄今为止最强的攻击,基准模型Inception的成功率为100%(针对性攻击)使用ImageNet数据集的V3模型。
But all the methods which came till 2016 were white-box based threat models, i.e. the attacker priorly know about the internal configuration, hyperparameters, datasets used, the architecture of the model. But on a practical basis, the attacker will only be available with the input samples, and the output classes/prediction scores (case to case basis), black-box based threat models. Papernot et al. (2017) were first to introduce the practical black-box attack algorithm, Substitute Model based strategy, which is based on the significant property of adversarial examples “Transferability”, it tells that if adversarial examples crafted to fool model A, then it can also fool model B which has similar structures to model A.
但是直到2016年,所有方法都是基于白盒的威胁模型,即攻击者事先知道了内部配置,超参数,使用的数据集以及模型的体系结构。 但实际上,攻击者只能使用输入样本,输出类别/预测分数(基于案例),基于黑盒的威胁模型。 Papernot等。 (2017)首先介绍了实用的黑盒攻击算法,即基于替代模型的策略,该策略基于对抗性示例“可传递性”的显着特性,它告诉我们,如果对抗性示例是针对傻瓜模型A精心制作的,那么它也可以傻瓜模型B,其结构与模型A类似。
Thus, the adversarial examples generation (attack) can be classified into White-Box Attacks, Black-Box Attacks, and in some cases Gray-Box Attacks (Semi-White). For gray box attacks, the best example is GAN based approaches as in that after crafting adversarial examples using white-box settings attacker don’t need the model.
因此,对抗性示例的生成(攻击)可以分为白盒攻击,黑盒攻击,在某些情况下还可以是灰盒攻击(半白色)。 对于灰箱攻击,最好的例子是基于GAN的方法,因为在使用白箱设置制作对抗性示例后,攻击者不需要模型。
白盒袭击 (White Box Attacks)
There have been many white-box attacks till now, but here we will discuss one of the most effective methods, Carlini and Wagner’s L2 metric based targeted attack.
到目前为止,已经有很多白盒攻击,但是在这里,我们将讨论最有效的方法之一,即基于Carlini和Wagner的L2指标的有针对性的攻击。
They formally define the problem of finding an adversarial instance for an image x as follows:
他们正式定义了为图像x查找对抗实例的问题,如下所示:
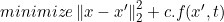
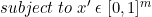
They defined seven objective functions f (.) and the below formulation gave the best experimental results and also gave the possible explanation for that, which is discussed below:
他们定义了七个目标函数f(。) ,下面的公式给出了最佳的实验结果,并给出了可能的解释,这将在下面讨论:
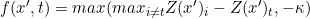
The function f(x,y) can also be viewed as the loss function for the given data (x,y) which penalises situation where there are some labels i with scores Z(x, i) larger than Z(x,y), this can also be viewed as the margin loss function. The benefit of using the margin loss function rather than cross-entropy is that if classifier classifies x’ to class t, then margin loss value goes zero which automatically tells the objective function to minimize the L2 distance between the input x and adversarial instance x’.
函数f(x,y)也可以看作是给定数据(x,y)的损失函数,这会惩罚某些标签i的得分Z(x,i)大于Z(x,y)的情况,这也可以看作是保证金损失函数。 使用裕度损失函数而不是交叉熵的好处是,如果分类器将x'分类为t类,则裕度损失值变为零,这自动告诉目标函数最小化输入x和对抗性实例x'之间的L2距离。
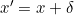
Now, to ensure that the image created is in the valid constraints on perturbation delta, we must have the image in box constraints [0,1]. There can be different methods to approach this problem like using directly the “box constraints” and use L-BFGS method to optimize. But, they investigated three different strategies for it, first was Projected Gradient Descent, i.e. using the one-step gradient descent and then clip all the coordinates in box domain; the second was to use Clipped Gradient Descent in this rather then clipping on each iteration it incorporates the clipping function in the objective function to be minimized; the third was the new strategy they introduced and called it the change of variables as they changed the domain range of x by introducing new variable w:
现在,要确保所创建的图像处于对扰动增量的有效约束中,我们必须在框约束[0,1]中具有该图像。 有多种方法可以解决此问题,例如直接使用“框约束”并使用L-BFGS方法进行优化。 但是,他们为此研究了三种不同的策略,首先是“ 投影梯度下降”,即使用单步梯度下降,然后将所有坐标裁剪到框域中。 第二种方法是在此方法中使用Clipped Gradient Descent ,而不是在每次迭代时进行裁剪,它将迭代功能合并到要最小化的目标函数中; 第三是他们引入的新策略,并称其为变量的变化,因为他们通过引入新变量w改变了x的域范围:
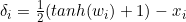
here as we know the range of tanh(.) is [-1,1] thus it follows x’ in range of [0,1]. This type of strategy bypasses the problem of getting stuck in corner cases / extreme regions. Thus, can be said as smooth clipped gradient descent also.
在这里我们知道tanh(。)的范围是[-1,1],因此它在[0,1]的范围内跟随x'。 这种策略可以避免陷入极端情况/极端地区的问题。 因此,也可以称为平滑削波梯度下降 。
Thus we can replace the f(x’) to f(w) then for the minimization of objective function the search becomes in the range of w which is unconstrained and thus standard optimization tools of DNN i.e. backpropagation can be used effectively to obtain the corresponding adversarial example x.
因此,我们可以将f(x')替换为f(w),然后为了使目标函数最小化,搜索变得不受限制的w范围内,因此可以有效地使用DNN的标准优化工具(即反向传播)来获得相应的对抗性示例x 。
The only unsolved mystery here remains now are constant c and K. To solve that problem for constant c the basic algorithm can be used i.e. binary search to find the optimal value of c to minimize the objective function. For the value of K i.e., nothing but confidence score here in margin loss function experimentally most appropriate used value is zero but it can change in the case to case basis.
现在剩下的唯一未解之谜是常数c和K。要解决常数c的问题,可以使用基本算法,即二进制搜索以找到c的最佳值以最小化目标函数。 对于K的值,即,在这里边际损失函数中的置信度得分,实验上最合适的使用值为零,但可以根据情况而改变。
The experimented results by proposed targeted L2 attack:
建议的针对性L2攻击的实验结果:

The C&W attack evaded gradient-based defense strategy, Defensive Distillation with 100% success rate.
C&W攻击规避了基于梯度的防御策略,即防御蒸馏 ,成功率为100%。
黑匣子袭击 (Black Box Attacks)
In the previous topic, we discussed how backpropagation algorithm can be used to generate our targeted adversarial examples but that is only possible if we have the model’s internal architecture to reproduce and use it to generate the examples but as in black box based threat model we can be only given with the prediction scores/labels for the testing set but no model’s architecture, weights, the simplest example is publically available API’s like Google Cloud Vision API, one can use it as an ideal black-box model.
在上一个主题中,我们讨论了如何使用反向传播算法来生成目标对抗示例,但这只有在我们拥有模型的内部体系结构来复制并使用它来生成示例的情况下才有可能,但是就像在基于黑盒的威胁模型中一样,我们可以仅给出测试集的预测分数/标签,而没有模型的架构,权重,最简单的示例是像Google Cloud Vision API这样的公开可用API,可以将其用作理想的黑盒模型。
So, as of now, there have been many black-box attacks since 2016, but we will discuss one of the fundamental black-box attacks i.e. also the first black box attack by Papernot et al. (2017), Substitute Model.
因此,到目前为止,自2016年以来,出现了许多黑盒攻击,但我们将讨论一种基本的黑盒攻击,即Papernot等人的第一个黑盒攻击。 (2017) , 替代模型。
So, first let us assume we have the target model, a multiclass DNN classifier (let us call it oracle model), it outputs the classified label. Thus, we have been given input and output label (as we know label tells us about the model much less than probability vectors).
因此,首先让我们假设我们有目标模型,一个多类DNN分类器(我们称它为oracle模型),它输出分类的标签。 因此,我们被赋予了输入和输出标签(我们知道标签告诉我们关于模型的信息远少于概率向量)。
Substitute Model Training: Training a model F approximating oracle model O, selecting a model F architecture to imitate the decision boundary of the model O so that if we create adversarial examples for model F then by property of transferability model O also gets fool with high success rate.
替代模型训练:训练近似于Oracle模型O的模型F,选择模型F架构来模仿模型O的决策边界,这样,如果我们为模型F创建对抗性示例,那么根据可传递性模型O的性质,也将非常成功。率。
Basic steps for the substitute model training:
替代模型训练的基本步骤:
- Synthesizing a substitute training dataset, by making an initial “replica” training set by manual handcraft data or random sample from the test set. 通过使用手工Craft.io数据或测试集中的随机样本制作初始的“副本”训练集来合成替代训练数据集。
- Feed the substitute model with the labels from the oracle model to train model F and get the corresponding parameters for the substitute model. 用oracle模型中的标签输入替代模型,以训练模型F并获取替代模型的相应参数。
Augment the data, Jacobian-based Dataset Augmentation, Adversary evaluates the sign of the Jacobian matrix dimension corresponding to the label assigned to the input x by oracle model, and add a new term lambda* sgn(J(x)[O(x)]) to the original point x.
增强数据, 基于雅可比的数据集增强,对手评估由oracle模型分配给输入x的标签所对应的雅可比矩阵维的正负号,并添加一个新项lambda * sgn(J(x)[O(x)) ])到原始点x。

4. Now, utilizing the knowledge model F has gathered using the Jacobian based dataset augmentation and a substitute model method of training we can use any gradient-based white-box attack with good transferability rate like FGSM, PGD, JSMA, etc.
4.现在,利用知识模型F使用基于Jacobian的数据集扩充和训练的替代模型方法收集的数据,我们可以使用具有良好传递率的任何基于梯度的白盒攻击,例如FGSM,PGD,JSMA等。
In the whole process, the main concern is the number of queries made to model O as that is limited and so in practical black box attack so, they try to minimize that query using the reservoir sampling which makes the reduction in the exponential complexity for data augmentation query. The other concern can be a step size (lambda) i.e. if the larger step size decrease in convergence stability while the smaller yields slow convergence thus, we can use a periodic step size:
在整个过程中,主要关注的是对模型O的查询数量有限,因此在实际的黑盒攻击中,他们尝试使用存储库采样来最小化该查询,从而降低了数据的指数复杂度扩充查询。 另一个问题可能是步长(lambda),即如果较大的步长会降低收敛稳定性,而较小的步长会导致收敛缓慢,那么我们可以使用周期性的步长:
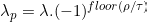
The proposed black-box attack misclassified the Google oracles with 97.17% with 6 epochs (rho) and Amazon oracles with 96.78%.
拟议的黑匣子攻击将Google oracle的错误分为6个历元(rho)的错误率为97.17%,将Amazon oracle的错误分类为96.78%。
结论 (Conclusion)
Thus, in this article, we discussed what are adversarial examples? the significant history of the adversarial attacks. The two elaborated White-box and Black-box attacks, which can tell significantly about how are the adversarial examples are getting created and can be used to fool the practical world classifiers.
因此,在本文中,我们讨论了什么是对抗性示例? 对抗攻击的重要历史。 精心设计的“白盒”和“黑盒”这两种攻击可以显着说明如何创建对抗示例,并可以用来欺骗实用的世界分类器。
翻译自: https://medium.com/swlh/deep-dive-into-adversarial-attacks-71f12885acf0
对抗性攻击














 1732
1732











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









