





机器学习和深度学习简介
机器学习的偏见 (Bias in Machine Learning)
Bias takes many different forms and impact all groups of people. It can range from implicit to explicit and is often very difficult to detect. In the field of machine learning bias is often subtle and hard to identify, let alone solve. Why is this a problem? Implicit bias in machine learning has very real consequences including denial of a loan, a lengthier prison sentence, and many other harmful outcomes for underprivileged groups. The data scientists designing models and the computers running them may not be explicitly biased against a particular group, so how does bias enter the picture? Whether it is along lines of race, gender, religion, sexual orientation, or other forms of identification there are correlations between groups and factors contributing to unfavorable outcomes. This is the classic correlation vs. causation issue and has real-world consequences for the groups of people who fall victim to this paradigm. MLFairnessPipeline serves two purposes:
偏见采取多种不同形式,并影响所有人群。 它的范围从隐式到显式,通常很难检测。 在机器学习领域, 偏见通常是微妙且难以识别的,更不用说解决了。 为什么这是个问题? 机器学习中的隐含偏见具有非常实际的后果,包括拒绝贷款,延长徒刑以及对弱势群体的许多其他有害后果。 设计模型的数据科学家和运行模型的计算机可能不会明确地偏向特定的群体,那么偏见如何进入画面呢? 无论是沿着种族,性别,宗教,性取向还是其他形式的认同,群体和造成不利结果的因素之间都有相关性 。 这是经典的因果关系与因果关系问题,对受此范式影响的人群具有现实意义。 MLFairnessPipeline有两个用途:
1. Detect bias against underprivileged groups
1.发现对弱势群体的偏见
2. Mitigate bias against underprivileged groups and provide more equitable and fair predictions without sacrificing performance and classification accuracy
2.减轻对弱势群体的偏见,并在不影响绩效和分类准确性的情况下提供更公平和公正的预测
什么是MLFairnessPipeline? (What is MLFairnessPipeline?)
MLFairnessPipeline is an end-to-end machine learning pipeline with the three following stages:
MLFairnessPipeline是一个端到端的机器学习管道,包括以下三个阶段:
1. Pre-processing — Factor re-weighting
1.预处理-因素重新加权
2. In-processing — Adversarial debiasing neural network
2.处理中-对抗性去偏神经网络
3. Post-processing — Reject Option Based Classification
3.后处理-基于拒绝选项的分类

MLFairnessPipeline roots out bias in each of the three stages above. A protected attribute is used to split data into privileged and underprivileged groups. This attribute can be essentially any feature but most common use cases are for race and gender. The pipeline maintains accuracy and performance while at the same time mitigating bias.
MLFairnessPipeline消除了以上三个阶段中每个阶段的偏见。 受保护的属性用于将数据分为特权组和特权组。 该属性基本上可以是任何功能,但最常见的用例是种族和性别。 管道在保持准确性和性能的同时,减少了偏差。
A good example use case of this split would be to design models determining prison sentence length. When determining the length of a prison sentence the individual’s likelihood of re-committing a crime is calculated and weighed very heavily. Due to systemic racial bias, minorities are often predicted to be more likely to re-commit a crime so if we were to try to mitigate bias in this case we would use “race” as our protected attribute and identify African Americans and Hispanics as the underprivileged group and Caucasians as the privileged group because they often receive more favorable outcomes and preferential treatment.
这种划分的一个很好的示例用例是设计确定监狱刑期长度的模型。 在确定刑期的长短时,会计算出个人重犯的可能性,并且权衡非常重。 由于系统的种族偏见,通常预计少数群体会更可能再次犯罪,因此,如果我们要在这种情况下减轻偏见,我们将使用“种族”作为我们的受保护属性,并将非裔美国人和西班牙裔人确定为弱势群体,而高加索人则是特权群体,因为他们通常会得到更有利的结果和优惠待遇。
前处理 (Pre-processing)
Before the model is trained and after our protected attribute and groups are selected, features are re-weighted in favor of the underprivileged group to give them a boost before training a model even begins. In the use case above, Caucasians are about 10–15% more likely to receive a favorable outcome than minorities when being assessed on likelihood of re-committing a crime. After re-weighting, this 10–15% difference in favorable outcomes is reduced to 0.
在训练模型之前以及选择我们受保护的属性和组之后,将对特征进行加权,以支持弱势群体,以在训练模型甚至开始之前就对它们进行增强。 在上面的用例中,在对重犯的可能性进行评估时,高加索人比少数群体获得有利结果的可能性高出约10-15%。 重新加权后,有利结果的这种10-15%的差异将减小为0。

进行中 (In-processing)
After pre-processing, we move on to the in-processing stage where the learning takes place and we build our model. MLFairnessPipeline then builds a neural network using TensorFlow and leverages adversarial debiasing. This actually entails two models: one specified by the user to try to predict a specified outcome from a set of features and a second adversarial model to try and predict the protected attribute based on the outcome of the trained model. What this does is ensure a one-way relationship between the protected attribute and the outcome, ensuring that the protected attribute cannot be guessed based on the outcome. By breaking the link between the protected attribute and outcome we are ensuring a more equal set of outcomes across both favorable and unfavorable groups.
进行预处理之后,我们进入进行学习的过程中阶段,然后构建模型。 然后,MLFairnessPipeline使用TensorFlow构建神经网络,并利用对抗性反偏。 实际上,这需要两个模型:一个由用户指定以尝试从一组功能中预测指定结果的模型,另一个由对抗模型基于已训练模型的结果尝试预测受保护的属性。 这是为了确保受保护属性与结果之间存在单向关系,从而确保不能基于结果来猜测受保护属性。 通过打破受保护的属性和结果之间的联系,我们可以确保在有利和不利的群体中获得更平等的结果集。

Using adversarial debiasing, we aim to make it difficult for our adversary model to predict the protected attribute based on the final prediction
使用对抗性去偏置,我们旨在使我们的对手模型难以根据最终预测来预测受保护的属性
后期处理 (Post-processing)
The third and final stage in our pipeline is post-processing. Now that we have a trained model and a set of predictions, the post-processing stage leverages reject option based classification to swap outcomes between privileged and underprivileged groups near the decision boundary. With a defined decision boundary the user can specify a threshold for which to swap results. If a member of a privileged group is within the threshold above the decision boundary, meaning a favorable outcome was provided, they are swapped with a member of the underprivileged group who received an unfavorable outcome but is still within the threshold below the boundary. This swapping of predictions adds an additional boost in favor of the underprivileged group to provide a more equitable set of predictions.
我们管道中的第三个也是最后一个阶段是后处理。 现在,我们有了训练有素的模型和一组预测,后处理阶段将利用基于拒绝选项的分类在决策边界附近的特权组和特权级组之间交换结果。 使用定义的决策边界,用户可以指定交换结果的阈值。 如果特权组的成员在决策边界之上的阈值之内,这意味着提供了有利的结果,则将其交换给贫困群体的成员,该成员收到不利的结果,但仍在边界之下的阈值之内。 这种预测的互换为贫困群体提供了更多的动力,以提供更加公平的预测。

MLFairnessPipeline如何衡量成功? (How does MLFairnessPipeline measure success?)
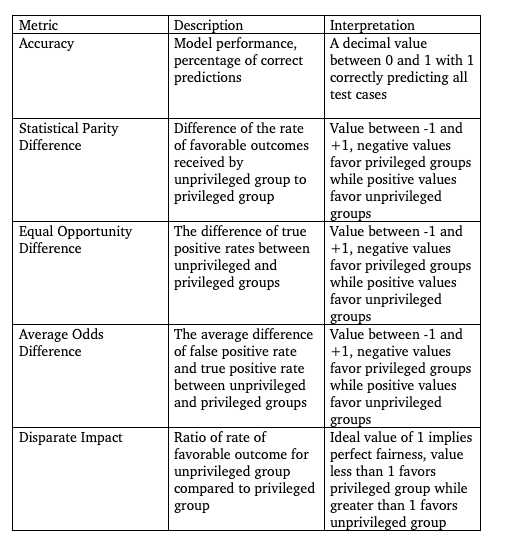
To judge performance from a fairness standpoint, MLFairnessPipeline provides measurements of key fairness metrics and compares model performance to a control group consisting of several popular machine learning classification algorithms. The selected measurements are as follows:
为了从公平的角度判断性能,MLFairnessPipeline提供关键公平度量的度量,并将模型的性能与由几种流行的机器学习分类算法组成的控制组进行比较。 所选的度量如下:
Current supported classifiers in the control group are XGBoost Classifier, KNeighbors Classifier, Random Forests, AdaBoost Classifier, and GradientBoost Classifier. Below is a sample set of graphs comparing performance between our control group and fair classifier for the sample use case described above.
对照组中当前支持的分类器是XGBoost分类器,KNeighbors分类器,随机森林,AdaBoost分类器和GradientBoost分类器。 以下是一组样本图,用于比较上述样本用例的对照组和公平分类器之间的性能。

This graph compares accuracy in the sample use case above pertaining to likelihood of re-committing a crime. We see that all models have similar performance
该图比较了上述示例用例中与再次犯罪的可能性有关的准确性。 我们看到所有型号都有相似的性能

This figure compares statistical parity difference against our control group and our fair classifier. We see that there is a very heavy preference for the privileged group in our control group but a near perfectly equal split in our fair classifier
此图将统计均等差异与我们的对照组和我们的公平分类器进行了比较。 我们看到,控制组对特权组的偏好非常强烈,但公平分类器对特权组的划分几乎完全相等

We see a wide disparity in equal opportunity difference with bias towards the privileged group in our control group but our fair classifier actually shows bias for the underprivileged group
我们发现,机会均等的差异很大,我们的对照组中偏向于特权群体,但是我们的公平分类器实际上显示了弱势群体的偏见。
结论 (Conclusion)
In conclusion, MLFairnessPipeline gives data scientists the opportunity to detect and mitigate many forms of bias in their models while maintaining the same degree of accuracy and performance
总之,MLFairnessPipeline使数据科学家有机会检测和减轻模型中的多种形式的偏差,同时保持相同程度的准确性和性能。
机器学习和深度学习简介















 1771
1771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









