





 本文介绍了如何使用Python3在60行代码内实现实现任意两种语言之间的翻译,主要针对数据科学领域的工作者。虽然未提及具体库或方法,但可以推测可能涉及到了自然语言处理和API调用技术。
本文介绍了如何使用Python3在60行代码内实现实现任意两种语言之间的翻译,主要针对数据科学领域的工作者。虽然未提及具体库或方法,但可以推测可能涉及到了自然语言处理和API调用技术。
python3语言翻译
介绍 (Introduction)
I remember when I built my first seq2seq translation system back in 2015. It was a ton of work from processing the data to designing and implementing the model architecture. All that was to translate one language to one other language. Now the models are so much better and the tooling around these models leagues better as well. HuggingFace recently incorporated over 1,000 translation models from the University of Helsinki into their transformer model zoo and they are good. I almost feel bad making this tutorial because building a translation system is just about as simple as copying the documentation from the transformers library.
我记得当我在2015年构建我的第一个seq2seq转换系统时,这是从处理数据到设计和实现模型体系结构的大量工作。 所有这些就是将一种语言翻译成另一种语言。 现在,模型变得更好了,围绕这些模型联盟的工具也变得更好了。 HuggingFace最近将赫尔辛基大学的 1,000多种翻译模型整合到了他们的变压器模型动物园中,效果很好。 在编写本教程时,我几乎感到难过,因为构建翻译系统就像从转换器库复制文档一样简单。
Anyway, in this tutorial, we’ll make a transformer that will automatically detect the language used in text and translate it into English. This is useful because sometimes you’ll be working in a domain where there is textual data from many different languages. If you build a model in just English your performance will suffer, but if you can normalize all the text to one language you’ll probably do better.
无论如何,在本教程中,我们将制作一个转换器,该转换器将自动检测文本中使用的语言并将其翻译成英语。 这很有用,因为有时您将在一个域中工作,那里有来自许多不同语言的文本数据。 如果仅用英语构建模型,则性能会受到影响,但是如果将所有文本规范化为一种语言,则可能会做得更好。
💾数据💾 (💾 Data 💾)
To explore how effective this approach is I needed a dataset of small text spans in many different languages. The Jigsaw Multilingual Toxic Comment Classification challenge from Kaggle is perfect for this. It has a training set of over 223k comments labeled as toxic or not in English and 8k comments from other languages in a validation set. We can train a simple model on the English training set. Then use our translation transformer to convert all other texts to English and make our predictions using the English model.
为了探索这种方法的有效性,我需要使用许多不同语言的小文本跨度的数据集。 来自Kaggle的Jigsaw多语言有毒评论分类挑战非常适合此任务。 它的训练集包含超过223k条用英语标记为有毒或无毒的注释以及8k条来自其他语言的验证集。 我们可以在英语训练集上训练一个简单的模型。 然后,使用我们的翻译转换器将所有其他文本转换为英语,并使用英语模型进行预测。
Taking a look at the training data we see that there are about 220K English* example texts labeled in each of six categories.
查看培训数据,我们发现在六个类别中的每个类别中都标记了约220K个英语*示例文本。

The place where things get interesting is the validation data. The validation data contains no English and has examples from Italian, Spanish, and Turkish.
验证数据是有趣的地方。 验证数据不包含英语,并且包含来自意大利语,西班牙语和土耳其语的示例。

I️♀️识别语言🕵️♀️ (🕵️♀️ Identify the Language 🕵️♀️)
Naturally, the first step toward normalizing any language to English is to identify what our unknown language is. To do that we turn to the excellent Fasttext library from Facebook. This library has tons of amazing stuff in it. The library is true to its name. It really is fast. Today we’re only going to use its language prediction capabilities.
自然地,将任何一种语言标准化为英语的第一步就是要确定我们未知的语言。 为此,我们转向来自Facebook的出色的Fasttext库 。 这个图书馆里面藏着许多令人惊奇的东西。 该库名副其实。 真的很快。 今天,我们仅使用其语言预测功能。
It’s that simple to identify which language an arbitrary string is. I ran this over the validation set to get a sense of how well the model did. I was, quite frankly, astonished at its performance out of the box. Of the 8,000 examples, Fasttext only misclassified 43. It also only took 300ms to run on my MacbookPro. On both accounts, that’s pretty bananas 🍌. If you look closer you’ll notice that in some of the Spanish mispredictions it predicted Galician or Occitan. These are languages spoken in and around Spain and have Spanish roots. So the mispredictions in some cases aren’t as bad as we might think.
识别任意字符串是哪种语言就这么简单。 我在验证集上进行了测试,以了解模型的效果。 坦率地说,我对它开箱即用的性能感到惊讶。 在8,000个示例中,Fasttext仅将错误分类为43。在MacbookPro上运行仅花费了300毫秒。 在两个方面,那都是漂亮的香蕉。 如果您仔细观察,您会发现在一些西班牙的错误预测中,它预测的是加利西亚语或奥克西唐语。 这些是西班牙及周边地区使用的语言,并具有西班牙文血统。 因此,在某些情况下的错误预测并没有我们想象的那么糟糕。

🤗变形金刚🤗 (🤗 Transformers 🤗)
Now that we can predict which language a given text is, let’s see about translating it. The transformers library from HuggingFace never ceases to amaze me. They recently added over a thousand translation models to their model zoo and every one of them can be used to perform a translation on arbitrary texts in about five lines of code. I’m stealing this almost directly from the documentation.
现在我们可以预测给定文本是哪种语言,让我们来看看翻译它。 来自HuggingFace的变形金刚库从未停止让我惊叹 。 他们最近在其模型动物园中添加了1000多个翻译模型 ,并且每个模型都可以用大约五行代码对任意文本进行翻译。 我几乎直接从文档中窃取了这个。
lang = "fr"
target_lang = "enmodel_name = f'Helsinki-NLP/opus-mt-{lang}-{target_lang}'# Download the model and the tokenizer
model = MarianMTModel.from_pretrained(model_name)
tokenizer = MarianTokenizer.from_pretrained(model_name)
# Tokenize the text
batch = tokenizer.prepare_translation_batch(src_texts=[text])
# Make sure that the tokenized text does not exceed the maximum
# allowed size of 512
batch["input_ids"] = batch["input_ids"][:, :512]
batch["attention_mask"] = batch["attention_mask"][:, :512]# Perform the translation and decode the output
translation = model.generate(**batch)
tokenizer.batch_decode(translation, skip_special_tokens=True)Basically, for any given language code pair you can download a model with the name Helsinki-NLP/optus-mt-{lang}-{target_lang} where lang is the language code for the source language and target_lang is the language code for the target language we want to translate to. If you want to translate Korean to German download the Helsinki-NLP/optus-mt-ko-de model. It’s that simple 🤯!
基本上,对于任何给定的语言代码对,您都可以下载名称为Helsinki-NLP/optus-mt-{lang}-{target_lang} ,其中lang是源语言的语言代码,而target_lang是目标语言的语言代码我们要翻译成的语言。 如果您想将韩语翻译成德语,请下载Helsinki-NLP/optus-mt-ko-de模型。 就这么简单🤯!
I make a slight modification from the documentation where I window the input_ids and the attention_mask to only be 512 tokens long. This is convenient because most of these transformer models can only handle inputs up to 512 tokens. This prevents us from erroring out for longer texts. It will cause problems though if you’re trying to translate very long texts, so please keep this modification in mind if you’re using this code.
我对文档进行了一些修改,在该文档中,将input_ids和tention_mask的窗口设置为仅512个令牌长。 这很方便,因为这些转换器模型中的大多数只能处理多达512个令牌的输入。 这可以防止我们将较长的文本错误列出来。 但是,如果您要翻译很长的文本,则会引起问题,因此,如果您使用此代码,请记住此修改。
SciKit学习管道 (SciKit-Learn Pipelines)
With the model downloaded let’s make it easy to incorporate this into a sklearn pipeline. If you’ve read any of my previous posts you’re probably aware that I love SciKit Pipelines. They are such a nice tool for composing featurization and model training. So with that in mind let’s create a simple transformer that will take in any textual data, predict its language, and translate it. Our goal is to be able to construct a model which is language-agnostic by running:
下载模型后,我们可以轻松地将其合并到sklearn管道中。 如果您阅读过我以前的任何文章,您可能会知道我喜欢SciKit Pipelines。 它们是组成特征化和模型训练的好工具。 因此,考虑到这一点,让我们创建一个简单的转换器,它将接收任何文本数据,预测其语言并进行翻译。 我们的目标是通过运行以下命令来构建一个与语言无关的模型:
from sklearn import svm
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipelineclassifier = svm.LinearSVC(C=1.0, class_weight="balanced")
model = Pipeline([
('translate', EnglishTransformer()),
('tfidf', TfidfVectorizer()),
("classifier", classifier)
])This pipeline will translate each datapoint in any text to English, then create TF-IDF features, and then train a classifier. This solution keeps our featurization in line with our model and makes deployment easier. It also helps prevent features from getting out of sync with your model by doing the featurizing, training, and predicting all in one pipeline.
该管道会将任何文本中的每个数据点翻译为英语,然后创建TF-IDF功能,然后训练分类器。 该解决方案使我们的功能与模型保持一致,并使部署更加容易。 通过功能化,训练和预测全部过程,它还有助于防止功能与模型不同步。
Now that we know what we are working toward let’s build this EnglishTransformer! Most of this code you will have already seen above we’re just stitching it together. 😄
现在我们知道了我们要做什么,让我们来构建这个EnglishTransformer! 您已经在上面看到了大部分代码,我们只是将它们拼接在一起。 😄
Lines 13–17 — Make sure the fasttext model is downloaded and ready to use. If it isn’t it downloads it to temp
/tmp/lid.176.bin.第13–17行—确保已下载fasttext模型并可以使用。 如果不是,它将下载到temp
/tmp/lid.176.bin。Line 22 — Establishes the language codes that are translatable with the Helsinki ROMANCE model. That model handles a bunch of languages really well and will save us a bunch of disk space because we don’t have to download a separate model for each of those languages.
第22行-建立可与赫尔辛基ROMANCE模型进行翻译的语言代码。 该模型可以很好地处理多种语言,并且可以节省大量磁盘空间,因为我们不必为每种语言下载单独的模型。
Lines 25–28 — Define which languages we will translate. We want to create an allowed list of languages because each of these models is about 300MB so if we downloaded a hundred different models we’d end up with 30GB of models! This limits the set of languages so that we don’t run our system out of disk space. You can add ISO-639–1 codes to this list if you want to translate them.
第25–28行-定义我们将翻译的语言。 我们想创建一个允许的语言列表,因为这些模型中的每一个大约300MB,所以如果我们下载一百种不同的模型,最终将获得30GB的模型! 这限制了语言集,因此我们不会在磁盘空间不足的情况下运行系统。 如果要翻译它们,可以将ISO-639–1代码添加到此列表中。
Lines 30–36 — Define a function to perform the fasttext language prediction like we discussed above. You’ll notice we also filter out the
\ncharacter. This is because Fasttext automatically assumes this is a different data point and will throw an error if they are present.第30–36行-定义一个函数来执行快速文本语言预测,就像我们上面讨论的那样。 您会注意到我们还过滤了
\n字符。 这是因为Fasttext会自动假定这是一个不同的数据点,如果存在则将引发错误。- Line 39 — Defines the transformation and is where the magic happens. This function will convert a List of strings in any language to a List of strings in English. 第39行-定义转换并在其中发生魔术。 此功能会将任何语言的字符串列表转换为英语的字符串列表。
- Lines 46–48 — Check to see if the current string is from our target language. If it is we add it to our translations as is because it is already the correct language. 第46–48行-检查当前字符串是否来自我们的目标语言。 如果是这样,我们将其按原样添加到我们的翻译中,因为它已经是正确的语言。
- Lines 51–52 — Check to see if the predicted language can be handled by the Romance model. This helps us avoid downloading a bunch of extra language models. 第51–52行-检查Romance模型是否可以处理预测的语言。 这有助于我们避免下载大量额外的语言模型。
- Lines 53–62 — Should look familiar they are just the translation code from the hugging face documentation. This section downloads the correct model and then performs translation on the input text. 第53–62行-应该看起来很熟悉,它们只是拥抱面文档中的翻译代码。 本部分将下载正确的模型,然后对输入的文本进行翻译。
That’s it! Super straightforward and it can handle anything. Something to be aware of this code was written to be as readable as possible and is VERY slow. At the end of this post, I include a much faster version that batch predicts different languages instead of downloading a model for each data point.
而已! 超级简单,它可以处理任何事情。 需要注意的一点是,此代码被编写为尽可能可读,而且速度很慢。 在本文的结尾,我提供了一个更快的版本,该版本可以批量预测不同的语言,而不是为每个数据点下载模型。
🤑结果🤑 (🤑Results 🤑)
We can now train and test our model using:
现在,我们可以使用以下方法训练和测试模型:
from sklearn import svm
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipelineclassifier = svm.LinearSVC(C=1.0, class_weight="balanced")
model = Pipeline([
('translate', EnglishTransformer()),
('tfidf', TfidfVectorizer()),
("classifier", classifier)
])
model.fit(train_df["comment_text"].tolist(), train_df["toxic"])
preds = model.predict(val_df["comment_text"])Training a simple TF-IDF model on the English training set and testing on the validation set gives us an F1 score for toxic comments of .15! That’s terrible! Predicting every class as toxic yields an F1 of .26. Using our new translation system to preprocess all input and translate it to English our F1 becomes .51. That’s almost a 4x improvement!
在英语训练集上训练一个简单的TF-IDF模型并在验证集上进行测试,使我们获得0.1分的F1分数! 这太可怕了! 预测每类毒物的F1为0.26。 使用我们新的翻译系统预处理所有输入并将其翻译成英语,我们的F1变为0.51。 几乎提高了4倍!
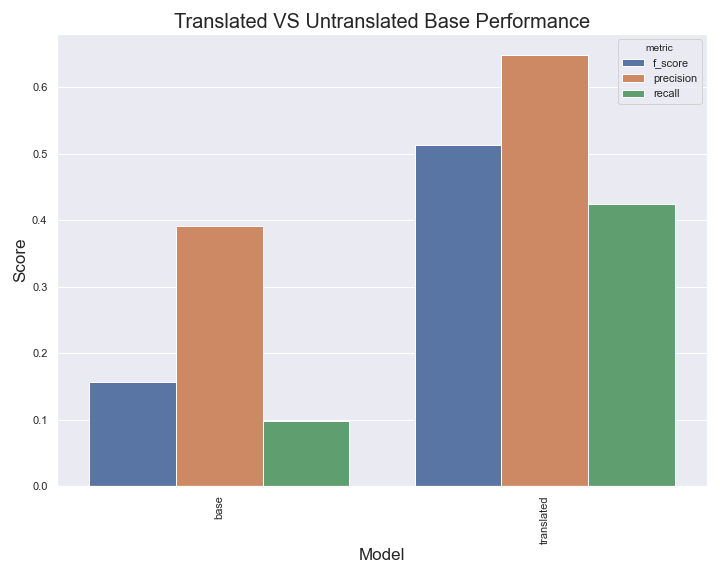
Keep in mind the goal here was simple translation not necessarily SOTA performance on this task. If you actually want to train a toxic comment classification model that gets good performance to fine-tune a deep transformer model like BERT.
请记住,这里的目标是简单翻译,而不一定是该任务的SOTA性能。 如果您实际上想训练一个有毒评论分类模型,该模型具有良好的性能,可以对诸如BERT的深层变压器模型进行微调。
If you enjoyed this post check out one of my other posts on working with text and SciKit-Learn. Thanks for reading! : )
如果您喜欢这篇文章,请查看我的其他一篇有关使用文本和SciKit-Learn的文章。 谢谢阅读! :)
更快的变压器 (Faster Transformer)
As promised here is the code for a faster version of the English Transformer. Here we sort the corpus by predicted language and only load a model in once for each language. It could be made even faster by batch processing input using the transformer on top of this.
如此处所承诺的,是更快版本的English Transformer的代码。 在这里,我们根据预测语言对语料库进行排序,并且每种语言仅一次加载一个模型。 使用此顶部的变压器,通过批处理输入可以使速度更快。
from typing import List, Optional, Set
from sklearn.base import BaseEstimator, TransformerMixin
import fasttext
from transformers import MarianTokenizer, MarianMTModel
import os
import requests
class LanguageTransformerFast(BaseEstimator, TransformerMixin):
def __init__(
self,
fasttext_model_path: str = "/tmp/lid.176.bin",
allowed_langs: Optional[Set[str]] = None,
target_lang: str = "en",
):
self.fasttext_model_path = fasttext_model_path
self.allowed_langs = allowed_langs
self.target_lang = target_lang
self.romance_langs = {
"it",
"es",
"fr",
"pt",
"oc",
"ca",
"rm",
"wa",
"lld",
"fur",
"lij",
"lmo",
"gl",
"lad",
"an",
"mwl",
}
if allowed_langs is None:
self.allowed_langs = self.romance_langs.union(
{self.target_lang, "tr", "ar", "de"}
)
else:
self.allowed_langs = allowed_langs
def get_language(self, texts: List[str]) -> List[str]:
# If the model doesn't exist download it
if not os.path.isfile(self.fasttext_model_path):
url = (
"https://dl.fbaipublicfiles.com/fasttext/supervised-models/lid.176.bin"
)
r = requests.get(url, allow_redirects=True)
open("/tmp/lid.176.bin", "wb").write(r.content)
lang_model = fasttext.load_model(self.fasttext_model_path)
# Predict the language code for each text in texts
langs, _ = lang_model.predict([x.replace("\n", " ") for x in texts])
# Extract the two character language code from the predictions.
return [x[0].split("__")[-1] for x in langs]
def fit(self, X, y):
return self
def transform(self, texts: str) -> List[str]:
# Get the language codes for each text in texts
langs = self.get_language(texts)
# Zip the texts, languages, and their indecies
# sort on the language so that all languages appear together
text_lang_pairs = sorted(
zip(texts, langs, range(len(langs))), key=lambda x: x[1]
)
model = None
translations = []
prev_lang = text_lang_pairs[0]
for text, lang, idx in text_lang_pairs:
if lang == self.target_lang or lang not in self.allowed_langs:
translations.append((idx, text))
else:
# Use the romance model if it is a romance language to avoid
# downloading a model for every language
if lang in self.romance_langs and self.target_lang == "en":
lang = "ROMANCE"
if model is None or lang != prev_lang:
translation_model_name = (
f"Helsinki-NLP/opus-mt-{lang}-{self.target_lang}"
)
# Download the model and tokenizer
model = MarianMTModel.from_pretrained(translation_model_name)
tokenizer = MarianTokenizer.from_pretrained(translation_model_name)
# Tokenize the text
batch = tokenizer.prepare_translation_batch(src_texts=[text])
# Make sure that the tokenized text does not exceed the maximum
# allowed size of 512
batch["input_ids"] = batch["input_ids"][:, :512]
batch["attention_mask"] = batch["attention_mask"][:, :512]
gen = model.generate(**batch)
translations.append(
(idx, tokenizer.batch_decode(gen, skip_special_tokens=True)[0])
)
prev_lang = lang
# Reorganize the translations to match the original ordering
return [x[1] for x in sorted(translations, key=lambda x: x[0])]翻译自: https://towardsdatascience.com/translate-any-two-languages-in-60-lines-of-python-b54dc4a9e739
python3语言翻译















 2793
2793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









