







摘要
机器翻译一直是人工智能领域里的一个重要研究对象,本文应用神经机器翻译技术, 实现了从数据预处理到模型训练与模型部署的全流程,并实现了一个可以跨平台访问的翻译网站供需要的人使用。
在训练神经机器翻译模型时,首先对原始语料数据集进行清洗,去除长度占比不合理的句子与含有违法字符的语句,随后使用分词组件对语料进行第一轮分词,第一轮分词后使用 BPE(字节对编码)算法对词级别的语料进一步切分,并构建词典。在已有 BPE 处理过后的语料和词典文件后,将语料文件进行二进制化处理,从而压缩语料体积,方便模型读取。使用原生 Transformer 对预处理后的语料进行训练,同时使用 MASS 对单语语料库进行训练,并探索不同集束大小对结果的影响。本文在英-德语料库 IWSLT 中英语到德语BLEU4 最高得分为 32.49。
在网站的前端部分,使用了 Bootstrap 和 Vue 框架,实现了前后端分离、响应式的开发。在后端部分使用 Flask 框架与 Redis 缓存数据库搭建了通用的服务器后台。不同的用户可以在各种设备上以相同的体验使用本网站。后台对网站时间进行了优化,保证网站平均相应时间不超过 0.5S。
关键词:深度学习;神经机器翻译;网站开发
Abstract
Machine translation has been an important research hot spot in the field of artificial intelligence for a long time. This paper realizes a neural machine translation model from data preprocessing to model deployment. And a cross-platform translation website is implemented to demonstrate the model.
While preprocessing, the first step is to clean the raw corpora dataset by removing sentences with unreasonable length and illegal characters. Then we use segmentation tools to split the origin corpus. After that, we use BPE to divide the corpus into finer granularity. Along with the vocabulary generated by BPE, we write corpus data into binarized files to compress file volume. In the training step, we use Transformer-base to train the corpus and then use MASS to fine-tune. The highest score we achieved without fine-tune is 32.49 in IWSTL from English to German.
In the front part of the website, the Bootstrap and Vue framework is used to realize the separation of front and rear development. In the back-end part, the general server background is set up by the Flask framework and Redis cache database. Different users can use the website with the same experience on various devices. The average reaction time of the website is optimized into 0.5S.
Keywords: deep learning; neural machine translation; website development
目录
第 1 章 绪论 1
1.1系统研究的背景 1
1.2相关研究工作 2
1.3主要研究内容 2
1.4本文组织结构 3
第 2 章 系统相关分析 4
2.1可行性分析 4
2.1.1技术可行性 4
2.1.2经济可行性 4
2.1.3法律可行性 4
2.1.4时间可行性 4
2.2系统性能需求分析 5
2.2.1系统的安全性 5
2.2.2系统的运行时间 5
2.2.3系统的易用性 5
2.2.4系统的可靠性 5
2.2.5系统的准确性 5
2.3系统用例图 6
2.4系统流程分析 6
2.5本章小结 8
第 3 章 系统结构设计与实现 9
3.1系统架构设计 9
3.1.1B/S 架构 9
3.1.2前后端分离开发 9
3.1.3MVVM 架构 11
3.1.4Flask 框架的架构设计 12
3.2系统的设计模式与实现 12
3.2.1工厂模式 12
3.2.2代理模式 13
3.2.3UML 类图 13
3.3系统部署 14
3.4本章小结 15
第 4 章 神经机器翻译 16
4.1编码器-解码器架构 16
4.2引入注意力机制的编码器-解码器 17
4.3编码器-解码器模型:Transformer 18
4.3.1模型架构 18
4.3.2多头注意力机制 19
4.3.3掩码机制 19
4.3.4位置编码 20
4.3.5时间复杂度 20
4.4预训练语言模型:MASS 20
4.4.1预训练语言模型简介 20
4.4.2MASS 模型 21
4.5本章小结 21
第 5 章 神经机器翻译的实验与结果 22
5.1数据预处理 22
5.2评价指标 23
5.3模型训练 23
5.3.1模型结构 23
5.3.2实验环境 24
5.3.3混合精度训练 24
5.3.4参数共享 24
5.3.5正则化 24
5.3.6训练批次内排序 25
5.3.7优化器 25
5.4生成策略 25
5.5实验结果 26
第 6 章 结语 28
参考文献 29
致谢 31
第 1 章 绪论
1.1系统研究的背景
随着交通条件的进步与信息技术的发展,世界上各区域间的联系日益紧密。不同区域的人们使用的语言不同,给国际贸易与文化交流带来了很大的障碍。与此同时,语言作为民族的重要特征,也是珍贵的,急待保护的文化资源。根据民族志的数据[1],目前世界上大约有 7117 种不同的语言,其中有 23 种语言的使用者占世界半数以上的人口。40%的语言处于濒危状态,其使用者往往不超过千人。
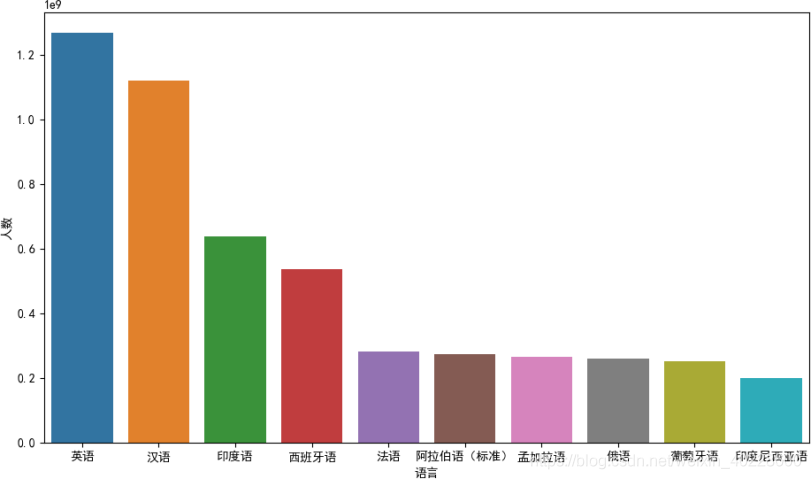
020 年全球使用人数最多的十种语言[2],其中英语汉语两种语言的使用人数最多,范围最广。法语,西班牙语,标准阿拉伯语与俄语也是联合国工作语言。还有一些语言虽然使用人数未排名进入前 10,但仍然有重大的影响力。如日语与标准德语, 在日本与德国本土的人几乎都使其作为第一母语。
面对如此繁多的语言,对语言的互译提出了很高的要求。经过训练的翻译官可以出色的完成国际谈判,贸易谈判等严肃场合的翻译任务,但是其价格高昂,且很多小语种的翻译官难以寻找。面对生活化的场景与轻量级的需求,机器翻译是解决问题的一个重要途径。随着深度学习技术的发展,神经机器翻译的效果近年来有着显著的提升,各大互联网公司都纷纷推出了自己的翻译系统,翻译的目标也从基本的翻译正确到运用各种预训练模型实现小规模语料上的高质量翻译以及摆脱机械式的翻译,对文本实现一定程度的理解。随着人工智能的热潮,机器翻译作为自然语言处理的重要部分,具有明显的现实意义与经济文化价值。
1.2相关研究工作
循环神经网络 RNN 一直广泛用于序列建模问题,但 RNN 梯度消失和梯度爆炸的弊病难以解决,非常难以训练。长短时神经网络 LSTM[3]和门神经网络 GRU[4]的提出缓解了这一问题。针对机器翻译这种多序列到多序列的问题,有着源语言和目标语言不定长的特点, 由 Google Brain 团队和 Yoshua Bengio 团队同时提出的编码器-解码器框架解决[5][6]。
编码器-解码器框架和 RNN 系列的神经网络组合,实现了由编码器将源语言映射到一个中间表示向量,由解码器将中间表示向量解码为目标语言的翻译框架,RNN 则作为主要的特征抽取工具。由于源语言的全部信息都压缩到中间表示向量的内容中,给解码器的解码造成了很大难度,又引入了注意力机制[7]进行进一步的改进。注意力机制通过对输入序列求加权值的方式得到中间向量,迫使模型在解码时学会关注输入序列的特定部分,进而提升翻译的效果。
使用循环神经网络作为特征提取的工具,符合序列的时序关系,在实践中却有很大的弊端。循环神经网络的每一步输出都依赖于前一步的输出,这使得大规模语料训练中计算难以并行化,也难以利用 GPU 高效的计算资源,从而使得机器翻译难以大规模训练。为了解决上述问题,在 ByteNet[8]和 ConvS2S[9]这两种模型结构中,采用了卷积核替代 RNN 结构从而获得并行计算的能力。与使用卷积神经网络不同的是,Transformer 模型[10]采用了自注意力机制的方法,仅仅利用自注意力机制就实现了特征的抽取,引起了极大的关注。Transformer 不仅在机器翻译任务上获得了当年的 SOTA,也促进了一系列的预训练语言模型,BERT[11]以及 GPT[12]分别采用 Transformer 中的编码器与解码器作为其基本组件。因为高质量的双语语料库很难获得,利用单语语料库进行非监督式学习的方法实现翻译逐渐成为当前研究的热点。
1.3主要研究内容
在本文中,主要基于 Python 语言和 Pytorch 框架开发神经机器翻译网站。通过对软件结构的设计,使网站尽可能的兼容不同的神经机器翻译模型。本次工作主要包含两部分内容,一个是翻译网站的前端后台设计,另一个则是翻译模型的预处理、训练以及评估的脚本。
在网站的部分,主要包括前端和后台两个模块。使用前后端分离的设计,在前端使用Vue 和 Bootstrap 框架完成页面搭建,在后端使用 Flask,Redis,gunicorn 等组件完成后端的搭建。
在翻译模型的部分,主要包括数据的预处理,翻译模型的实现与训练,翻译模型的评估等。其中数据的预处理部分还包括数据清洗、分词、BPE 等工作,各个组件之间的联系如下图所示。
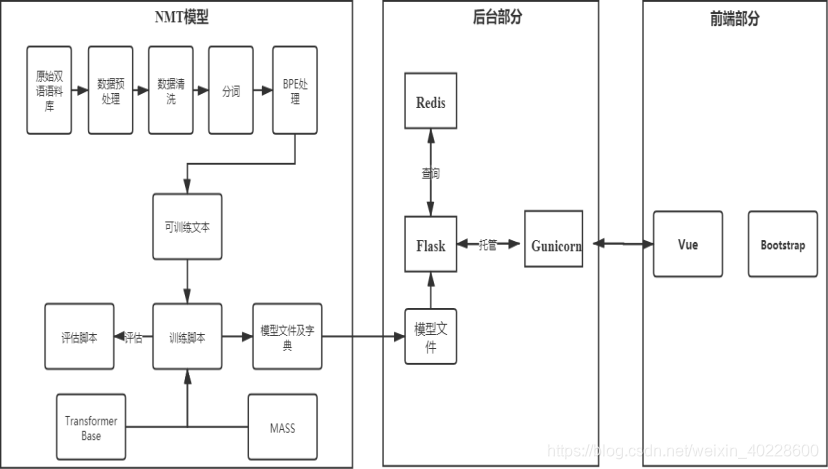
图 1.2 各个组件的关系
图 1.2 展示了系统涉及的各个组件之间的关系。在神经机器翻译模型的部分,原始的语料首先经过一系列预处理流程生成可以用于训练的语言对,在选择模型并使用训练脚本训练后,通过评估脚本对模型的质量进行评估,达到预期效果后保存模型文件与字典文件, 以供后台部分调用。在后台部分,使用 Flask 处理 HTTP 请求,使用内存数据库 Redis 缓存翻译结果以提升系统速度。Flask 由 Web 容器 Gunicorn 托管。在前端部分,利用 Bootstrap 构建响应式界面,由 Vue 处理 Http 请求等内容。各个模块的具体内容,将在对应章节中详细描述。
1.4本文组织结构
本文设计并实现一个神经机器翻译系统,并通过网站的形式对外提供服务,供需要的人使用。在本文中:
第一章为系统研究的背景,相关工作与主要研究内容。第二章为对网站系统进行需求分析。
第三章为网站的结构设计与实现。
第四章为神经机器翻译模型的解释与介绍。
第五章为神经机器翻译模型实验的过程与结果。第六章对本文进行总结。
第 2 章 系统相关分析
2.1可行性分析
可行性分析的目的是通过判断开发的效益与判断原定系统的规模和目标能否实现,来决定问题是否值得去解决,从而为后续的开发工作提供便利。
下面对系统进行可行性分析,主要包括技术可行性、经济可行性、法律可行性等方面。
2.1.1技术可行性
网站的前台部分采用 Vue 框架和 Bootstrap 一起完成前端部分的开发。采用前后端分离的开发模式和响应式的前端页面设计,可以使网页在 PC 端和移动端拥有相近的体验。以上框架的选用,可以提升开发速度,降低开发难度。
网站的后台主要采用 Python 技术栈的 Flask 框架和 gunicorn 作为容器,使用 Redis 作为内存数据库充当缓存的功能。这一套开发速度相比 Java 开发要更快,解决方案相对丰富, 且因为与神经机器翻译模型使用的框架 Pytorch 都是用 Python 开发,大大降低了跨语言的编程成本与难度。
在神经机器翻译部分,采用 Pytorch 框架和以 Pytorch 为基础二次开发的 fairseq 框架训练神经机器翻译模型。这些框架可以极大的提高神经网络的编写和调试效率,又因为均以 Python 实现为基础,可以与后台部分无缝的融合,不需要进行跨语言的编程,使得后台的开发变得简单易行。
综上所述,基于神经机器翻译技术的本平台在技术上完全可行。下面从经济的角度对系统进行可行性分析。
2.1.2经济可行性
从经济的角度分析,本系统的前端和后台部分开发并不需要额外的投入,在任何普通的电脑上即可完成开发工作。对于神经机器翻译模型来说,训练模型需要 GPU 资源,而模型推断阶段在普通的服务器 CPU 上即可完成推断,不再需要昂贵的 GPU。对于模型训练所需要的 GPU 资源,在开发前实验室已有两块 GPU 供调用,足够完成中型模型的开发。所以在经济上,本系统是可行的。
2.1.3法律可行性
从法律可行性的角度分析,训练翻译模型需要双语语料库。这些开源的语料库通常有一定的版权限制,因为本系统主要做展示用途,并没有任何盈利,满足这些开源语料库的使用需求,所以本系统的开发不会涉及到知识产权的纠纷,系统在法律上是可行的。
2.1.4时间可行性
本系统开发预留时间为两个月,且前后端平台已有一些前期的成果。主要的时间消耗在神经机器翻译模型上。在已有编程环境和前期积累的条件下,两个月足以完成模型的训练和调参,所以从交付时间的角度考虑,本系统是完全可行的。
2.2系统性能需求分析
系统性能分析旨在分析系统的各项性能指标需要达到的水平,从而为后续的系统结构设计与实现提供参考。
2.2.1系统的安全性
为了让系统安全稳定的运行,需要对调用翻译的接口进行设计,用来保障:
1)系统的用户只能通过限定的接口访问有限的服务,从而避免直接调用翻译模型引起服务器端大量的资源消耗
2)通过系统的结构设计,需要使翻译模块在设计上可以与网站提供的接口分离,降低后期的部署成本与潜在的网络安全风险。
2.2.2系统的运行时间
本系统的目标用户为普通需求的用户,对于系统的反应时间没有苛刻的要求,但考虑到神经机器翻译模型需要占用大量的内存空间和 CPU 资源,Python 自身的性能问题,为了用户可以从多种终端流畅地访问系统,系统设计时仍然需要重点对计算时间进行优化。网站的平均响应时间应该控制在 0.5S 之内。
2.2.3系统的易用性
本系统的核心功能是向用户提供翻译功能,因此在 UI 设计时应注重界面的简洁大方, 排除非必要的元素,并尽可能使得多种移动端的用户都可以得到相同的体验,保持操作的一致性。
2.2.4系统的可靠性
为了保障系统运行的可靠性,除了在服务器端设置防火墙等操作外,还需要为运行的服务器程序创建相应的容器进行管理,在服务意外中断时保障服务器可以自动重启,从而使得系统安全稳定的运行。
2.2.5系统的准确性
系统对外向用户提供翻译功能,尽可能保证翻译的准确性是核心需求。通过对神经机器翻译模型的设计和调参,应尽可能的保证所翻译语言的准确性,并提出相关的评价指标。
2.3系统用例图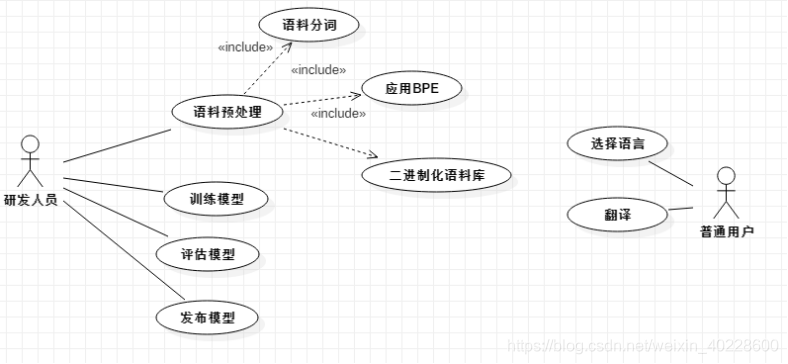
系统的用例图如图 2.1 所示。图 2.1 展示了不同身份的用户使用本系统时可使用的功能。对于模型的研发人员来说,使用的功能主要在处理语料、训练并评估模型上。因为模型的研发人员都默认为具有专业技能的开发人员,所以面对的工具集均为命令行脚本,使用相应的脚本完成工作。
对于使用本系统的普通用户,则主要在各种终端上通过友好的 UI 界面进行人机交互, 其可使用的功能是受限的,仅限于选择要翻译的语言并获得相应的翻译结果,翻译中间流程的数据仅供研发人员使用。
系统用例图描述了不同角色可以使用的功能,下面通过算法流程图对普通用户的翻译过程进行说明。神经机器翻译的实现流程在第四章进行详细说明。
2.4系统流程分析
下面通过算法流程图,描述普通用户执行翻译过程的流程。用户在前端的流程如下图所示。
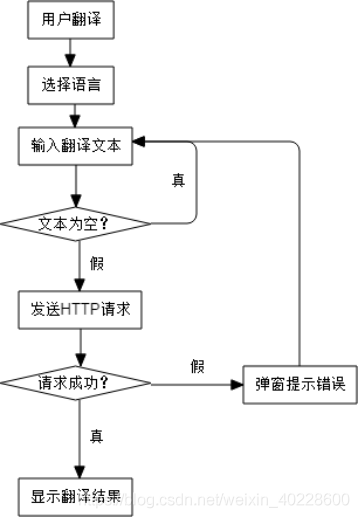
图 2.2 前端流程图
图 2.2 是普通用户在执行翻译功能时的流程图。用户首先在 UI 界面中选择要翻译的源语言与目标语言,随后执行翻译功能。前端首先对输入的文本进行简单的校验,通过校验后向服务器发送 HTTP 请求并等待回复。若请求成功,则显示翻译的结果,若请求失败, 则弹出相应的错误提示。
前端部分相较于后端部分逻辑相对简单,仅需要对输入进行简单校验即可,下面对后端部分的流程进行详细介绍,后端翻译过程的流程图如下图所示。
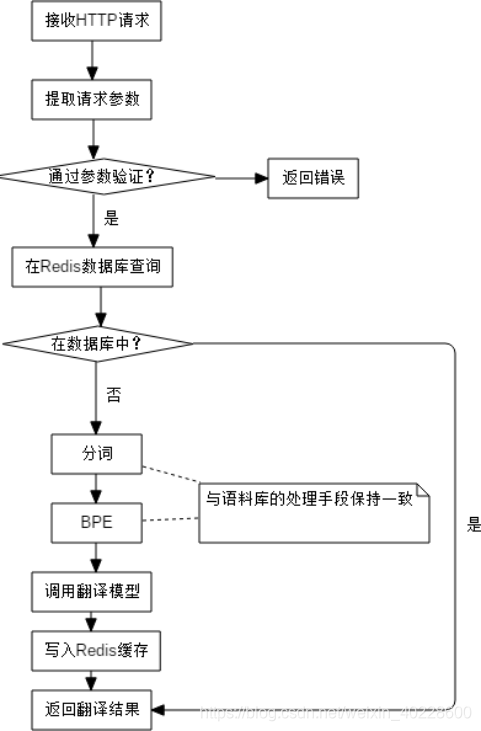
图 2.3 是系统后端部分的流程图。作为服务器程序,监听端口传来的 HTTP 请求,每当收到请求时,后端首先对请求的参数进行校验,如果参数的校验不合格,则直接返回错误,避免翻译接口被滥用以及潜在的程序错误风险。在通过参数验证后,首先在 Redis 缓存中查找有无历史的翻译结果,若有则直接将结果返回,从而大大提升系统的响应速度, 避免消耗服务器资源。若缓存中查找失败,则将输入的源语言序列分别通过分词和 BPE 组件,确保输入序列与预处理脚本的处理流程保持一致,之后调用翻译模型并通过词典反向查找生成翻译的结果。在将翻译结果存入缓存后,将翻译结果进行返回。
2.5本章小结
在本章节中,描述了神经机器翻译系统网站部分的需求分析与设计。通过可行性分析, 明确了本系统开发的可行性。通过系统性能需求分析,确立了系统应达成的开发目标。通过系统的用例图和系统流程图,明确了系统需要开发的各种功能和功能实现的流程,为具体的系统设计与实现奠定基础。在第三章,将对网站的结构设计和具体实现进行详细阐述。
第 3 章 系统结构设计与实现
在本章中,根据第二章系统分析的内容,主要描述系统的各种结构设计与其相关的实现细节,接下来首先讨论系统的架构设计。
3.1系统架构设计
3.1.1B/S 架构
本翻译平台主要采用 B/S 架构(Brower/Server)。客户端主要使用浏览器(无论是 PC端还是手机端),不需要额外安装软件就可以完成所需的功能。服务器端配置服务器程序与相应的数据库软件,与浏览器通过 HTTP 协议进行交互。与 C/S 架构(Client/Server)架构相对比,B/S 架构更加灵活轻便,开发相对简单,天然的可以实现系统的跨平台运行。因为本系统的功能相对单一简单,又对跨平台有一定的需求,因此选择 B/S 架构作为本次系统开发的架构。
3.1.2前后端分离开发
在 B/S 架构的基础上,本平台采用前后端分离的开发模型。在传统的前后端不分离的开发模型中,网页的渲染是由服务器完成的,重定向也需要服务器来进行处理。在这种开发模式下,前端和后端的耦合度很高,对于团队开发来说合作不便利。在移动互联网时代, 服务器不仅需要向 PC 端网页提供服务,同样的服务也需要向手机、平板等移动端提供。在这种情景下,如果前后端的开发不分离,将导致服务器的逻辑臃肿,出现问题时前后端团队也难以合作调试。这两种系统架构的区别如图 3.1,图 3.2 所示。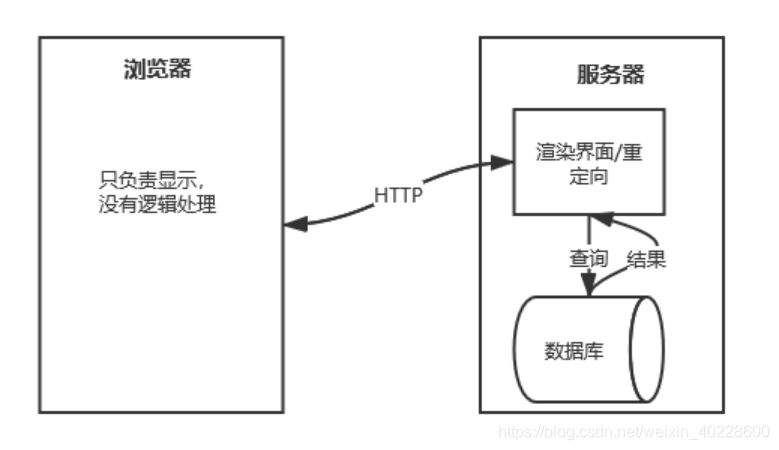
图 3.1 前后端不分离时的架构图
图 3.1 展示了前后端不分离时系统的架构情况。在只有浏览器访问需求时,该架构完全可以作为开发的选择项之一。但是从图中可以观察到,服务器程序接收到 HTTP 请求后,
需要对页面进行渲染,将页面生成后,可能还会根据相应需求对数据库进行查询,待结果返回后才能将完整的页面返回给调用者。这对前后端的开发人员都产生了一定的要求,后端开发人员需要兼顾一些前端的内容才能很好的完成开发,在页面逻辑逐渐复杂时开发的复杂性会随之上升。从功能开发的角度来说,如果有其他终端的访问需求,如小程序、移动端 APP 等,此时的后台服务器程序没有一个统一的数据提供服务,往往需要重新编写相关的程序,这使得系统开发难度大且不易维护。
针对上述提到的问题,本系统开发使用前后端分离架构,具体的架构图如下图所示。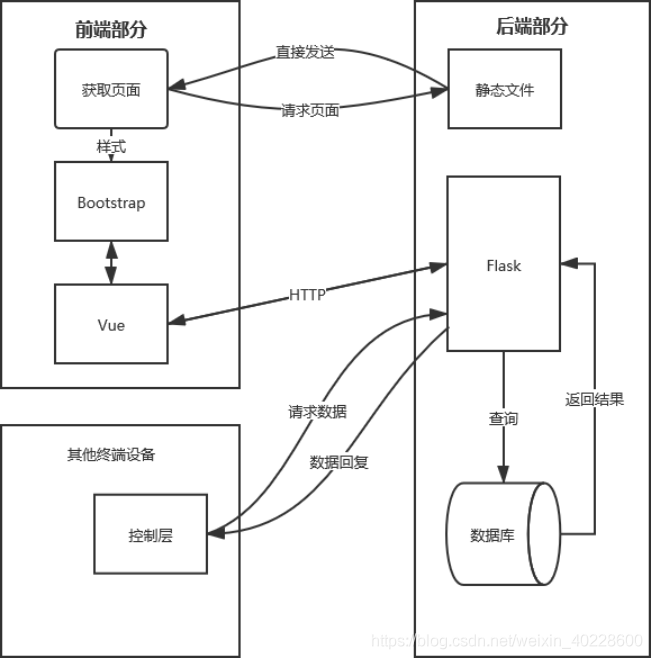
图 3.2 前后端分离时的架构图
图 3.2 展示了本系统网站部分的系统架构。从图中可知,采用了前后端分离架构的系统,页面文件为静态文件,不需要服务器的渲染,直接由服务器向浏览器传输即可。每当页面数据时,通过相应的框架发起 HTTP 请求,调用后端的数据接口,获得数据后在前端由浏览器完成数据的渲染工作。当有像小程序,手机端 APP 等其他需求数据的调用端时, 遵循同样的流程,统一向同一个接口发起请求,这使得后端的开发逻辑变得清晰明了,系统的耦合度降低,后端开发人员只负责提供数据,前端开发人员只负责显示,双方通过 API 接口约定需要提供的功能。这种程序架构可以轻松地使系统实现跨平台服务。图 3.2 展示了系统的逻辑上的架构,下面从其他角度来进一步描述系统的结构信息。
3.1.3MVVM 架构
分层设计是软件架构的主流设计思想,其中经典的代表有MVC 设计模式(Model-View- Controller)。在 MVC 中,模型主要负责数据的交互,视图主要负责显示,控制器则负责调度,往往从视图中读取数据,向模型中请求或写入数据。在前后端不分离的情境中,MVC 模式行之有效,可以使团队实现分工开发,并且让应用程序的测试更加容易。在前后端分离的场景,前端页面往往也需要完成以往服务器的一部分工作,即发送请求并渲染数据。由于前端开发的特殊性,开发人员需要频繁地根据数据的变化改变 DOM,操纵 DOM 树往往效率低下且容易出现错误。MVVM(Model-ViewModel-View)的出现极大地改善了这一问题。
MVVM 的视图层是用户界面,前端主要由 HTML 和 CSS 构建,在本系统中额外引入了 Bootstrap 框架用以实现响应式网页开发。为了更方便的展示数据,各个基于 MVVM 设计模式的前端框架往往会提供内置的模板语言来构建页面。模型层 Model 则主要指数据模型,在前端开发中,因为前后端分离的关系这部分内容完全由后台开发人员负责。视图模型层 ViewModel 则是 MVVM 的精髓所在。视图模型层由前端负责维护,最重要的功能是实现与视图层的双向绑定。通过双向绑定,使得一旦数据元素发生变化,页面视图会立即产生相应地变化。模型-视图模型-视图这三者之间的关系如下图所示。
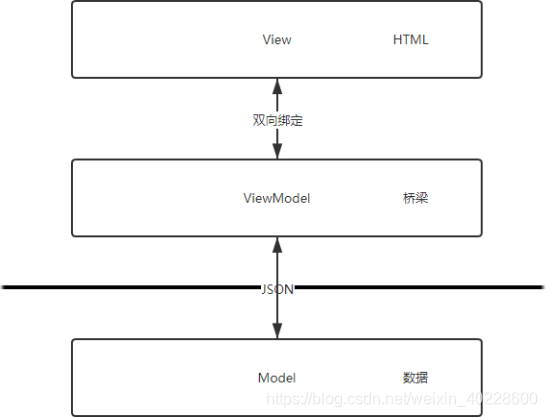
图 3.3 展示了采用 MVVM 架构下的前端架构图。图 3.2 中采用的 Vue 前端框架就是上图中的 MVVM 架构,提供了模板语言和数据双向绑定的功能,同时也负责在前端发送、接受、处理请求与数据的渲染工作。与服务器端的通信主要通过 JSON 格式进行,使用统一的 API 接口,大大降低了后端重复开发的工作量。
本系统在前端使用了 Vue 框架,其使用的 MVVM 架构在上文中进行了介绍,接下来对后端使用的 Flask 框架进行详细介绍。
3.1.4Flask 框架的架构设计
Flask 框架是用 Python 语言实现的 Web 开发微框架,其核心简单,易于扩展,只包含了开发的基本组件,并不绑定需要使用的数据库,不提供数据库抽象层和表单验证等功能。当需要这些功能时,可以用插件的形式进行安装。这种架构设计非常适合前后端分离开发, 后端的框架不必绑定渲染等功能,从而使得软件的整体占用体积小,逻辑简单。
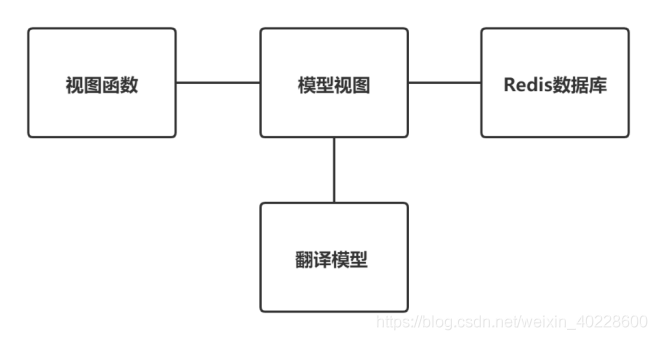
图 3.4 Flask 架构图
应用了 Flask 框架的系统后台架构如图 3.4 所示。相较于传统的 MVC,本系统在实现时根据自身特点进行了一定的改进。View 层因为前后端分离的缘故,渲染数据的工作已经交给前端部分完成,所以在后端移除了 View 层。图 3.4 中的视图函数为 MVC 中的控制器,负责处理到来的 HTTP 请求并调用相关模块。模型视图层相较于传统的模型层, 进行了一些改进,对不同数据源(模型层)得到的数据根据调用端(视图函数)的需
求,对数据进行一定的修饰后传递给视图函数。
本系统在架构上,总体采用前后端分离的架构,对前后端进行解耦,在前端部分使用Vue 的 MVVM 架构,实现了数据和视图的双向绑定,极大的减轻了前端的开发工作量。在后端部分使用 Flask 框架,对 MVC 结构进行一定的修改,使之更符合本系统的需求。接下来应用 UML 类图等工具,对后端部分的实现进行描述。
3.2系统的设计模式与实现
3.2.1工厂模式
工厂模式属于创建型的设计模式,是面向对象编程中常见的设计模式,主要用于组织创建对象的过程。在本系统中,使用的分词器,翻译模块等组件时,它们都有不同的来源, 但是在使用形式上表现一致,为了管理相同功能但属于不同类的对象,采用简单工厂模式对其进行处理。通过引入工厂模式,应用程序层面的编写者不必考虑翻译模型的细节,只需要在配置文件中编写配置文件即可更换系统的相关功能。
3.2.2代理模式
代理模式属于结构型的设计模式,主要指用一个类来代表另一个类的功能。在本系统中,调用翻译组件进行翻译前需对原始数据进行预处理,预处理的过程理应和翻译模型类分离。同时调用翻译组件时,需要考虑后期服务进行扩展,将翻译模型部署到高性能服务器中,需要调用远程的 API 来实现功能。从当前的现实和未来的发展考虑,为了使翻译组件和系统调用之间进行解耦,采用代理模式实现翻译功能。代理类代理真实的翻译类,在代理类中进行数据的预处理和调用真实翻译类,从而达到系统可扩展的目的。
3.2.3UML 类图
类图主要描述系统中的类及其之间的关系。上述的工厂模式和代理模式在 UML 类图中均有展示,它们之间的联系可见下图。

。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。。
论文下载地址:请点击》》》》
















 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











