





人工智能图灵测试
I recently started a new newsletter focus on AI education. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:
我最近开始了一份有关AI教育的新时事通讯。 TheSequence是无BS(意味着没有炒作,没有新闻等),它是专注于AI的新闻通讯,需要5分钟的阅读时间。 目的是使您了解机器学习项目,研究论文和概念的最新动态。 请通过以下订阅尝试一下:
Every once in a while, you encounter a research paper that is so simple and yet profound and brilliant that makes you wish you would have written it yourself. That’s how I felt when I read François Chollet’s On the Measure of Intelligence. The paper resonated with me not only because it confronts some of the key philosophical and technical challenges about artificial intelligence(AI) systems that I have been spending some time on but also because it does so in such an elegant way that is hard to argue with. Mr. Collet’s thesis is remarkably simple: for AI systems to reach its potential, we need quantitative and actionable methods that measure intelligence in a way that shows similarities with human cognition.
每隔一段时间,您会遇到一份简单而又深刻而辉煌的研究论文,这使您希望自己撰写。 当我阅读弗朗索瓦·乔勒(FrançoisChollet)的《关于智力的度量》时,我就是这样。 这篇论文引起了我的共鸣,不仅因为它面对了我花了一些时间在人工智能(AI)系统上面临的一些关键的哲学和技术挑战,而且还因为它以一种如此优雅的方式进行了实践,很难与之抗衡。 。 Collet先生的论点非常简单:为了使AI系统发挥其潜力,我们需要定量和可操作的方法来以与人类认知相似的方式测量智力。
Mr. Collet’s thesis might seem contradictory given the recent achievements of AI systems. After all, it is unquestionable that we are producing intelligent algorithms that are achieving super human performances in games like Go, Poker or StarCraft or are capable of driving vehicles, boats and planes. However, how intelligent are those systems? Despite the tangible achievements of AI, we continue measuring “intelligence” by the effectiveness of accomplishing a single task but is that a real measure of intelligence? The ability of a system to play Go doesn’t mean that understand Shakespeare or reason through economic problems. As humans, we judge intelligence based on abilities such as analytical and abstract reasoning, memory, common sense and many others. In the history or science, there have been two fundamental schools of thought that marked specific definitions of intelligence.
鉴于AI系统的最新成就,Collet先生的论文似乎矛盾。 毕竟,毫无疑问,我们正在生产智能算法,这些算法可以在Go,Poker或StarCraft等游戏中实现超人的性能,或者能够驾驶车辆,船只和飞机。 但是,这些系统的智能程度如何? 尽管AI取得了明显的成就,我们仍然通过完成一项任务的有效性来衡量“智能”,但这是对智力的真正衡量吗? 系统玩围棋的能力并不意味着了解莎士比亚或通过经济问题来推理。 作为人类,我们根据诸如分析和抽象推理,记忆,常识和许多其他能力来判断智力。 在历史或科学中,有两种基本的思想流派标记了对智能的特定定义。

达尔文与图灵:智力的两个历史定义 (Darwin vs. Turing: Two Historical Definitions of Intelligence)
Throughout the history of science, there have two dominant views of intelligence: the Darwinist view of evolution and Turing’s view of machine intelligence. The Darwin’s theory of evolution, human cognition is the result of special-purpose adaptations that arose to solve specific problems encountered by humans throughout their evolution. One of the maximum expressions of this theory was captured by AI legend Marvin Minsky when he outlined a task-centric definition of AI:
在整个科学史上,有两种主要的智能观:达尔文主义的进化观和图灵的机器智能观。 达尔文的进化理论,人类认知是特殊用途改编的结果,这种改编是为了解决人类整个进化过程中遇到的特定问题。 AI传奇人物Marvin Minsky概述了以任务为中心的AI定义时,就抓住了这一理论的最大表达:
“AI is the science of making machines capable of performing tasks that would require intelligence if done by humans.”
“人工智能是使机器能够执行如果由人类完成就需要智能的任务的科学。”
The evolutionary view of intelligence is directly related to a vision of the mind as a wide collection of vertical, relatively static programs that collectively implement intelligence. For historical reasons, this vision of intelligence has become very influential in the field of AI creating systems that are extremely efficient on mastering individual tasks without showing any real signs of intelligence.
智力的进化观点与大脑的愿景直接相关,后者是广泛的垂直,相对静态的程序的集合,这些程序共同实现了智力。 由于历史原因,这种智能愿景已在AI创建系统领域变得非常有影响力,该系统在不显示任何实际智能迹象的情况下,能够非常高效地完成单个任务。
A contrasting and somewhat complementary perpsective of the Darwinist view of intelligence was pioneered by Alan Turing. It a paper from 1959, Turing stated some interesting remarks relative to the characteristics of intelligence :
艾伦·图灵(Alan Turing)率先提出了对达尔文主义的智力观进行对比和补充的观点。 图灵(Turing)在1959年发表的一篇论文中,就智力的特点发表了一些有趣的评论:
“If we are ever to make a machine that will speak, understand or translate human languages, solve mathematical problems with imagination, practice a profession or direct an organization, either we must reduce these activities to a science so exact that we can tell a machine precisely how to go about doing them or we must develop a machine that can do things without being told precisely how.”
“如果我们要制造一台能够说,理解或翻译人类语言,用想象力解决数学问题,从事某个专业或指导一个组织的机器,要么我们必须将这些活动简化为一门科学,以便我们可以告诉一台机器确切地讲如何去做,或者我们必须开发一台可以做事而又不知道如何做的机器。”
Turing’s vision of intelligence is inspired by British philosopher John Locke’s Tabular Rasa theory which sees the mind as a flexible, adaptable, highly general process that turns experience into behavior, knowledge, and skills.
图灵的智力观受到英国哲学家约翰·洛克(John Locke)的表格形式的Rasa理论的启发,该理论将思想视为灵活,适应性强,高度通用的过程,将经验转化为行为,知识和技能。
The evolution of AI has been deeply influenced by both Drawing’s and Turing’s theory of intelligence. The current generation of AI models are certainly focus on specific tasks but also accumulate knowledge based on the interactions with an environment and other agents. The combination of the two foundational theories of intelligence originated a key concept in modern AI.
人工智能的发展已受到绘画和图灵的智力理论的深刻影响。 当前一代的AI模型当然专注于特定任务,但也基于与环境和其他代理的交互来积累知识。 两种基本的智力理论的结合提出了现代AI的一个关键概念。
概括 (Generalization)
The notion of generalization is omnipresent in AI and, particularly, modern deep learning algorithms. Broadly speaking, generalization can be defined as
泛化的概念在AI尤其是现代深度学习算法中无处不在。 概括地说,泛化可以定义为
“the ability to handle situations (or tasks) that differ from previously encountered situations”.
“处理与先前遇到的情况不同的情况(或任务)的能力”。
In its simplest form, generalization applies to how AI models are able to apply knowledge acquired during training to the test dataset. In more ambitious forms, generation refers to the ability of AI models to apply knowledge acquired performing a specific task to a completely different task.
以最简单的形式,泛化适用于AI模型如何将训练期间获得的知识应用于测试数据集。 在更雄心勃勃的形式中,生成是指AI模型将执行特定任务所获得的知识应用于完全不同的任务的能力。
From a qualitative standpoint, there are several dimensions of generalization that are relevant in AI models:
从定性的角度来看,在AI模型中有几个相关的概括维度:

I. Absence of Generalization: The notion of generalization as we have informally defined above fundamentally relies on the related notions of novelty and uncertainty: a system can only generalize to novel information that could not be known in advance to either the system or its creator. AI systems in which there is no uncertainty do not display generalization.
I. 泛化的缺乏:上面我们非正式地定义的泛化概念从根本上依赖于新颖性和不确定性的相关概念:系统只能泛化为系统或其创建者无法预先知道的新颖信息。 没有不确定性的AI系统不会显示泛化。
II. Local Generalization, or “Robustness”: This is the ability of a system to handle new points from a known distribution for a single task or a well-scoped set of known tasks, given a sufficiently dense sampling of examples from the distribution (e.g. tolerance to anticipated perturbations within a fixed context).
二。 局部概括,即“稳健性 ”:这是系统处理已知任务中已知任务中的新点的能力,即已知任务中足够密集的示例样本(例如公差)在固定背景下的预期扰动)。
III. Broad Generalization, or “Flexibility”: This is the ability of a system to handle a broad category of tasks and environments without further human intervention. This includes the ability to handle situations that could not have been foreseen by the creators of the system. This could be considered to reflect human-level ability in a single broad activity domain.
三, 广泛的泛化或“灵活性”:这是系统在无需进一步人工干预的情况下处理各种任务和环境的能力。 这包括处理系统创建者无法预见的情况的能力。 可以认为这反映了一个广泛的活动领域中人的能力。
IV. Extreme Generalization: This describes open-ended systems with the ability to handle entirely new tasks that only share abstract commonalities with previously encountered situations, applicable to any task and domain within a wide scope. This could be characterized as “adaptation to unknown unknowns across an unknown range of tasks and domains”.
IV。 极端通用性:这描述了开放式系统,该系统具有处理全新任务的能力,这些新任务仅与先前遇到的情况共享抽象共性,适用于广泛范围内的任何任务和领域。 这可以被描述为“适应未知任务和领域范围内的未知未知”。
Interestingly enough, the different dimensions of generalization outlined above mirror the organization of humans cognitive abilities as laid out by theories of the structure of intelligence in cognitive psychology. Furthermore, we can use the previous taxonomy of generalization to create a hierarchical representation of intelligence as shown in the following figure:
有趣的是,上面概述的概括的不同维度反映了人类认知能力的组织,这是由认知心理学中的智力结构理论提出的。 此外,我们可以使用先前的一般分类法来创建智能的层次表示,如下图所示:
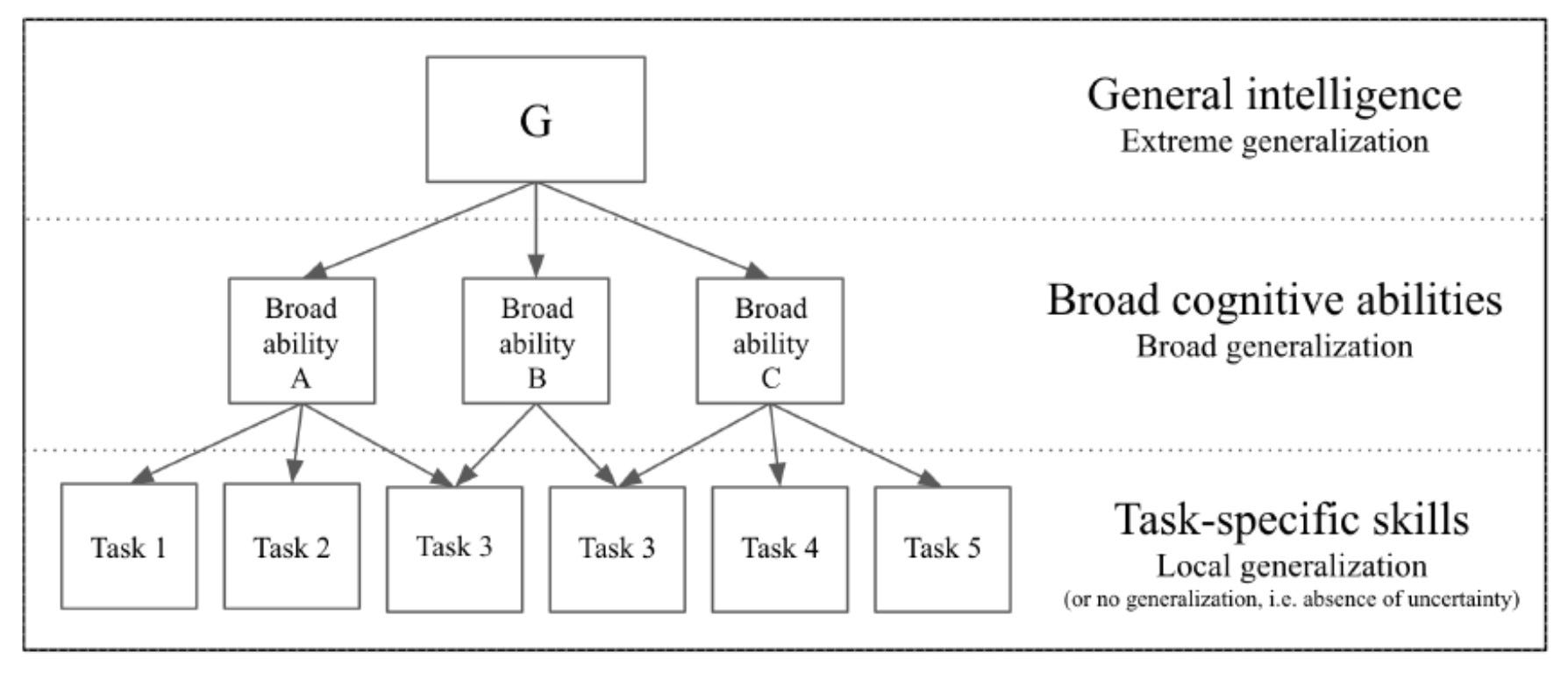
I think, we can all agree that the current generation of AI systems is focus on task and local intelligence but its also evolving rapidly. Using the previous outline hierarchy, we can start outlining a framework for measuring intelligence across broad skills and generally. This will be the subject of the second part of this article.
我认为,我们都可以同意,当前一代的AI系统不仅专注于任务和本地情报,而且也在Swift发展。 使用前面的大纲层次结构,我们可以开始概述用于衡量广泛技能以及一般情况下的智力的框架。 这将是本文第二部分的主题。
智力的心理学计量学观点 (A Psychometrics Perspective of Intelligence)
The field of psychometrics focus on studying the development of skills and knowledge in humans. A fundamental notion in psychometrics is that intelligence tests evaluate broad cognitive abilities as opposed to task-specific skills. Importantly, an ability is an abstract construct (based on theory and statistical phenomena) as opposed to a directly measurable, objective property of an individual mind, such as a score on a specific test. Broad abilities in AI, which are also constructs, fall into the exact same evaluation problematics as cognitive abilities from psychometrics. Psychometrics approaches the quantification of abilities by using broad batteries of test tasks rather than any single task, and by analyzing test results via probabilistic models.
心理学计量学的重点是研究人类技能和知识的发展。 心理计量学的一个基本概念是,智力测验评估广泛的认知能力,而不是特定于任务的技能。 重要的是,一种能力是一种抽象的构造(基于理论和统计现象),与个人心理的直接可测量的客观特性(例如特定测试的分数)相反。 AI的广泛能力(也是构成要素)与心理计量学的认知能力完全一样,属于评估问题。 心理计量学通过使用广泛的测试任务而不是任何单个任务,并通过概率模型分析测试结果来对能力进行量化。
Some of the concepts in the theory of psychometrics can be used to evaluate the intelligence capabilities of AI systems in the more quantifiable manner. Chollet’s paper outlines a few key ideas:
心理计量学理论中的某些概念可用于以更可量化的方式评估AI系统的智能能力。 Chollet的论文概述了一些关键思想:
1. Measuring abilities (representative of broad generalization and skill-acquisition efficiency), not skills. Abilities are distinct from skills in that they induce broad generalization.
1.测量能力(代表广泛的概括和技能获得效率),而不是技能。 能力与技能的不同之处在于,它们会引起广泛的概括。
2. Evaluate abilities via batteries of tasks rather than any single task, that should be previously unknown to both the test taking system and the system developers.
2.通过一系列任务而不是任何单个任务来评估能力,这是应试系统和系统开发人员以前都不应该知道的。
3. Having explicit standards regarding reliability, validity, standardization, and freedom from bias. In that context, reliability implies that the test results for a given system should be reproducible over time and across research groups. Validity refers to establish clear understanding of the objectives of a given test. Standardization implies adopting shared benchmarks across the subset of the research community. Finally, freedom from bias implies that the test should not be biased against groups of test-takers in ways that run orthogonal to the abilities being assessed.
3.制定有关可靠性,有效性,标准化和无偏见的明确标准。 在这种情况下,可靠性意味着给定系统的测试结果应随时间推移和跨研究组再现。 有效性是指对特定测试的目标建立清晰的了解。 标准化意味着在整个研究团体的子集之间采用共享基准。 最后,没有偏见意味着测试不应以与所评估能力正交的方式针对各组应试者产生偏见。
The idea that solving individual tasks is not an effective measure of intelligence was brilliantly captured by computer science pioneer Allen Newell in the 1970s using an analogy from chess which have become one of the canonical examples of AI:
1970年代,计算机科学先驱艾伦·纽厄尔(Allen Newell)巧妙地运用了象棋的类比方法,成功地解决了解决个人任务不是智力的有效方法的想法,而象棋已成为AI的典型范例之一:
“we know already from existing work [psychological studies on humans] that the task [chess] involves forms of reasoning and search and complex perceptual and memorial processes. For more general considerations we know that it also involves planning, evaluation, means-ends analysis and redefinition of the situation, as well as several varieties of learning — short-term, post-hoc analysis, preparatory analysis, study from books, etc.”
“我们已经从[人类心理学研究]的现有工作中知道[任务]涉及推理和搜索的形式以及复杂的感知和纪念过程。 对于更一般的考虑,我们知道它还涉及计划,评估,均值分析和情况的重新定义,以及几种学习类型-短期,事后分析,预备分析,从书本中学习等。 ”
What this statement is telling us is that chess itself does not involve specific cognitive abilities. However, possessing these general abilities makes it possible to solve chess (and many more problems), by going from the general to the specific, inversely, there is no clear path from the specific to the general. Absolutely brilliant!
这句话告诉我们的是,国际象棋本身并不涉及特定的认知能力。 但是,拥有这些通用能力可以通过从通用到特定的方式来解决国际象棋(以及更多的问题),相反,从特定到通用的路径并不明确。 绝对辉煌!
量化的智力测度 (A Quantifiable Measure of Intelligence)
Using some of the ideas from psychometrics, Chollet arrives to the following definition of intelligence:
通过使用心理计量学的一些想法,Chollet得出了以下关于智力的定义:
The intelligence of a system is a measure of its skill-acquisition efficiency over a scope of tasks, with respect to priors, experience, and generalization difficulty.
系统的智能性是衡量其在一定任务范围内的技能获取效率(相对于先验,经验和归纳难度)的一种度量。
This definition of intelligence includes concepts from meta-learning priors, memory, and fluid intelligence. From an AI perspective, if we take two systems that start from a similar set of knowledge priors, and that go through a similar amount of experience (e.g. practice time) with respect to a set of tasks not known in advance, the system with higher intelligence is the one that ends up with greater skills. Another way to think about it is that “higher intelligence” systems “covers more ground” in future situation space using the same information.
这种智能定义包括来自元学习先验,记忆和流动智能的概念。 从人工智能的角度来看,如果我们采用两个系统,它们从一组相似的先验知识开始,并且针对一组事先未知的任务经历了相似的经验(例如练习时间),则该系统具有更高的智力是最终拥有更高技能的一种。 另一种思考的方式是, “高智能”系统使用相同的信息在未来的情况空间中“覆盖更多地面” 。
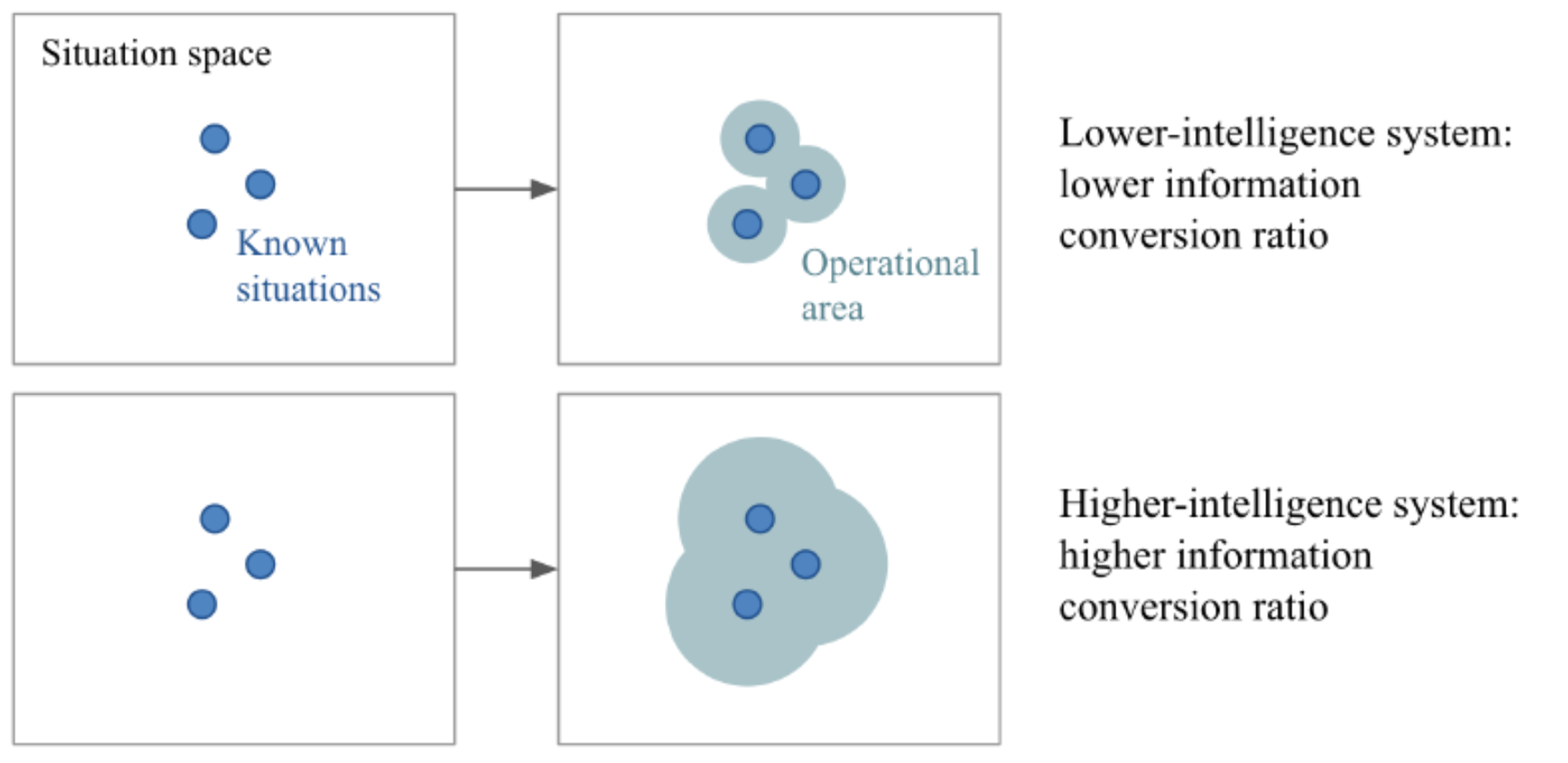
The previous definition of intelligence looks amazing from a theoretical standpoint but how can it be included in the architecture of AI systems?
从理论的角度来看,以前的智能定义看起来很惊人,但是如何将其包含在AI系统的体系结构中呢?
An intelligent system would be an AI program that generates a specific skill to interact with a task. For instance, a neural network generation and training algorithm for games would be an “intelligent system”, and the inference-mode game-specific network it would output at the end of a training run on one game would be a “skill program”. A program synthesis engine capable of looking at a task and outputting a solution program would be an “intelligent system”, and the resulting solution program capable of handling future input grids for this task would be a “skill program”.
智能系统将是一个AI程序,可以生成与任务交互的特定技能。 例如,用于游戏的神经网络生成和训练算法将是一个“智能系统”,而在一场游戏的训练结束时它将输出的推理模式特定于游戏的网络将是一个“技能程序”。 能够查看任务并输出解决方案程序的程序综合引擎将是“智能系统”,而能够处理此任务的将来输入网格的最终解决方案程序将是“技能程序”。

Now that we have a canonical definition of intelligence for AI systems, we need a way to measure it 😉
既然我们已经为AI系统定义了智能的规范定义,我们需要一种测量它的方法😉
弧 (ARC)
Abstraction and Reasoning Corpus(ARC) is a dataset proposed by Chollet intended to serve as a benchmark for the kind of intelligence defined in the previous sections. Conceptually, ARC can be seen as a psychometric test for AI systems that tries to evaluate a qualitatively form of generalization rather than the effectiveness on a specific task.
抽象和推理语料库(ARC)是Chollet提出的数据集,旨在作为前面各节中定义的那种情报的基准。 从概念上讲,ARC可以看作是AI系统的心理测试,它试图评估定性形式的泛化,而不是评估特定任务的有效性。
ARC comprises a training set and an evaluation set. The training set features 400 tasks, while the evaluation set features 600 tasks. The evaluation set is further split into a public evaluation set (400 tasks) and a private evaluation set (200 tasks). All tasks are unique, and the set of test tasks and the set of training tasks are disjoint. Given a specific task, the ARC test interface looks like the following figure.
ARC包括训练集和评估集。 训练集具有400个任务,而评估集具有600个任务。 评估集进一步分为公共评估集(400个任务)和私人评估集(200个任务)。 所有任务都是唯一的,测试任务集和培训任务集是不相交的。 在完成特定任务后,ARC测试界面如下图所示。
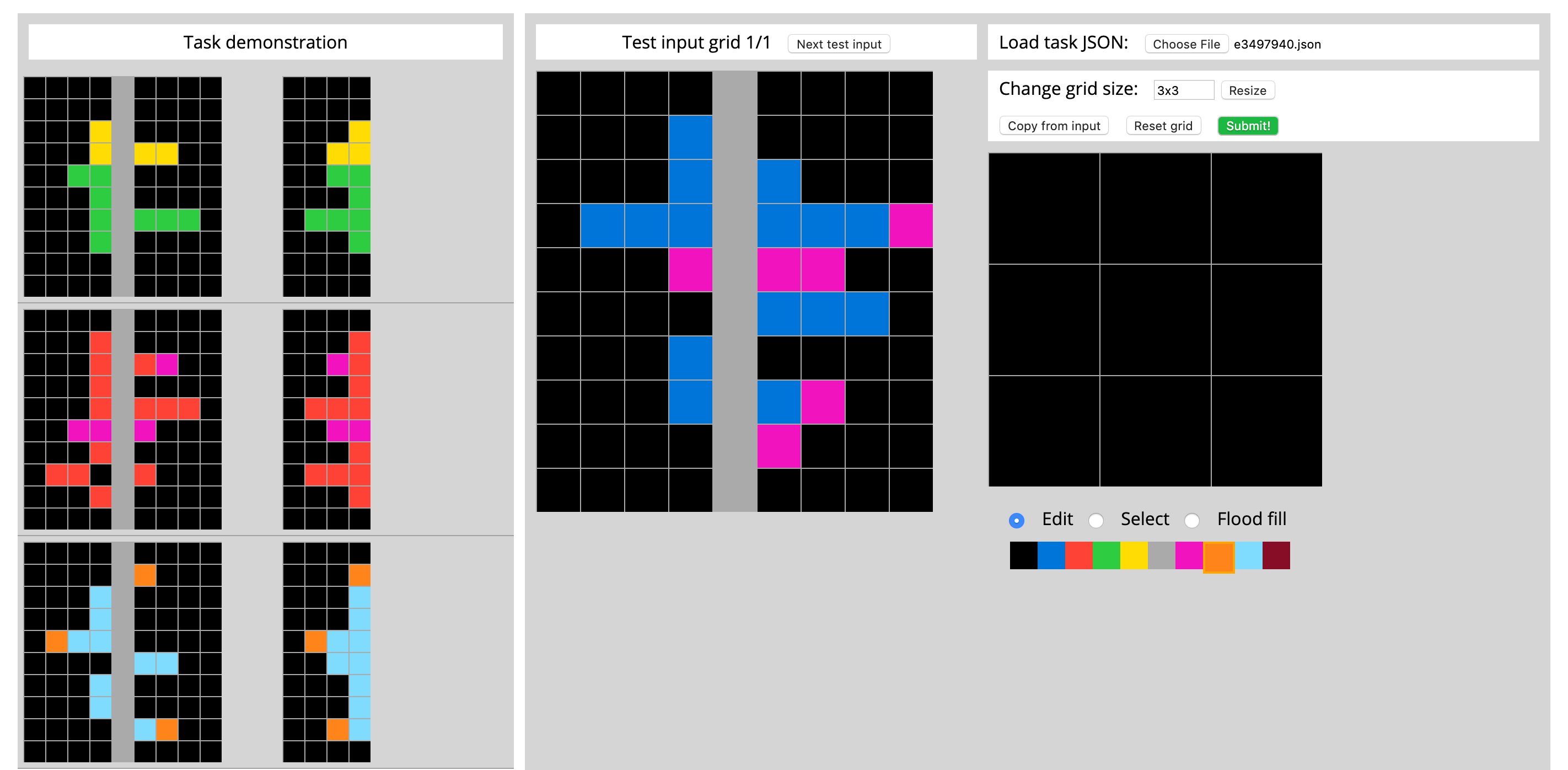
The initial release of ARC is available on GitHub.
ARC的初始版本可在GitHub上获得 。
I started the previous article by saying that Chollet’s On the Measure of Intelligence could be considered one of the most important papers of this year. Some of the ideas included in the paper or some variations of it can influence the design of AI systems in a way that they can achieve measurable and comparable levels of intelligence. Implementing Chollet’s paradigm is not an easy task but some of the ideas are definitely worth exploring.
在上一篇文章的开头,我说Chollet的“关于智能的度量”可以被认为是今年最重要的论文之一。 本文中包含的某些想法或其某些变体可能会以可实现可衡量和可比的智能水平的方式影响AI系统的设计。 实施Chollet的范例并非易事,但其中一些想法绝对值得探索。
人工智能图灵测试















 492
492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









