





A web-based solution to control a swarm of Raspberry Pis, featuring a real-time dashboard, a deep learning inference engine, 1-click Cloud deployment, and dataset labeling tools.
基于Web的解决方案,用于控制大量的Raspberry Pi,具有实时仪表板,深度学习推理引擎,一键式Cloud部署和数据集标签工具。
This is the third article of the three-part SorterBot series.
这是分三部分的SorterBot系列的第三篇文章。
Part 1 — General project description and the Web Application
- Part 3 — Transfer Learning and Cloud Deployment 第3部分-转移学习和云部署
Source code on GitHub:
GitHub上的源代码:
Control Panel: Django backend and React frontend, running on EC2
控制面板 :在EC2上运行的Django后端和React前端
Inference Engine: Object Recognition with PyTorch, running on ECS
推理引擎 :使用PyTorch进行对象识别,在ECS上运行
Raspberry: Python script to control the Robotic Arm
Raspberry :控制机器人手臂的Python脚本
Installer: AWS CDK, GitHub Actions and a bash script to deploy the solution
安装程序 :AWS CDK,GitHub Actions和bash脚本以部署解决方案
LabelTools: Dataset labeling tools with Python and OpenCV
LabelTools :使用Python和OpenCV数据集标签工具
推理引擎的转移学习 (Transfer Learning for the Inference Engine)
All the Detectron2 models are trained on ImageNet, which includes categories like humans, dogs, trees, etc, but not small metal objects, so I needed to custom train the model to recognize the objects that I wanted to use. To save time on training and reduce the necessary dataset size, I started with pre-trained weights (transfer learning).
所有Detectron2模型都在ImageNet上进行了训练,其中包括人,狗,树木等类别,但不是小型金属物体,因此我需要自定义训练模型以识别要使用的物体。 为了节省训练时间并减少必要的数据集大小,我从预先训练的权重开始(转移学习)。
创建数据集 (Creating the Dataset)
For my use case, I needed a few thousands of labeled training pictures. While creating the training set, I applied 2 strategies to reduce the effort spent. My first idea was that instead of taking pictures, I will record a video, and grab frames from that. First I tried to move the arm relatively fast, but that way most of the images ended up being blurry since the Pi Camera can provide only 30 fps at maximum resolution. To overcome this, I tried to move the arm slower, but that resulted in uneven, jerky movements due to the poor build quality of the arm. The solution was to move the arm, wait a second until it is steady, then move it further. The resulting video was used as the input to my dataset creation tool.
对于我的用例,我需要几千张带有标签的培训图片。 在创建训练集时,我应用了两种策略来减少花费的精力。 我的第一个想法是,我不会录制照片,而是录制视频并从中抓取帧。 首先,我试图相对较快地移动手臂,但是那样一来,由于Pi相机在最大分辨率下只能提供30 fps,因此大多数图像最终变得模糊。 为了克服这个问题,我尝试将手臂的移动速度减慢,但是由于手臂的制作质量较差,导致动作不平稳,抖动。 解决的办法是移动手臂,等待一秒钟直到它稳定,然后再进一步移动。 生成的视频用作我的数据集创建工具的输入。
To reduce the number of bounding boxes that the user has to draw, I calculated the trajectory of a point as it appears on the video.
为了减少用户必须绘制的边界框的数量,我计算了一个点在视频中出现的轨迹。

Initially, the bounding boxes are defined in a Cartesian coordinate system, with its origin at the top-left corner of the image. The goal of this calculation was to retrieve the new coordinates of a point, after the arm rotated by Δγ. To help with that, I defined 2 additional coordinate systems: a polar and another Cartesian system. Both of their origins are defined as the arm’s base axis, and in both of them, the image’s center point has the coordinate of (0, rc), where rc is the arm-specific radius constant.
最初,边界框是在笛卡尔坐标系中定义的,其原点位于图像的左上角。 该计算的目的是在手臂旋转Δγ之后检索点的新坐标。 为了解决这个问题,我定义了两个附加的坐标系:一个极坐标系和另一个笛卡尔坐标系。 它们的两个原点都被定义为手臂的基轴,并且在它们两个中,图像的中心点都具有(0,rc)的坐标,其中rc是特定于手臂的半径常数。
To do the calculation, first I express the old point in the new Cartesian system (point 1 on the drawing), then convert it to polar coordinates (point 2). After I have the old point’s polar coordinates, I simply add the rotation of the arm to it (point 3), then convert it back to the original Cartesian system (point 4). Using this method, I could calculate the apparent trajectory of items as they move through the viewport of the camera. The benefit of this method is that instead of grabbing each frame and manually drawing bounding boxes on it, I could draw a bounding box once per video, then calculate it’s position for the rest of the frames. This reduced the time spent on labeling the dataset by at least a factor of 10.
为了进行计算,首先在新的笛卡尔系统中表示旧点(图形上的点1),然后将其转换为极坐标(点2)。 有了旧点的极坐标后,我只需向其添加手臂的旋转(点3),然后将其转换回原始的笛卡尔系统(点4)。 使用这种方法,我可以计算出物品在相机视口中移动时的视在轨迹。 这种方法的好处是,我不必抓住每个帧并在其上手动绘制边框,而是可以为每个视频绘制一个边框,然后计算其余帧的位置。 这样可将花费在标记数据集上的时间减少至少10倍。
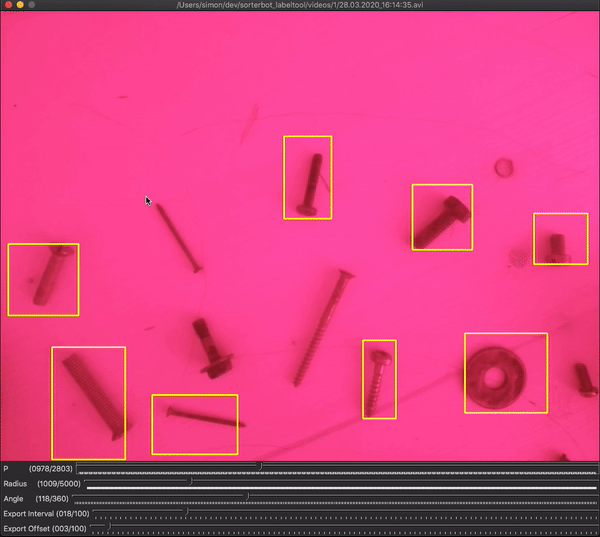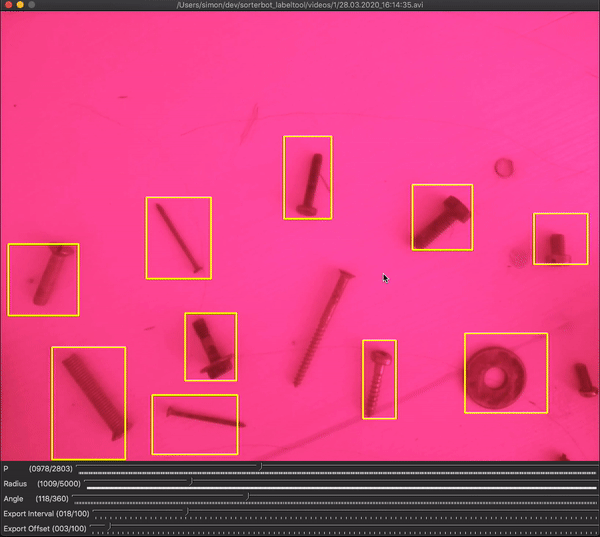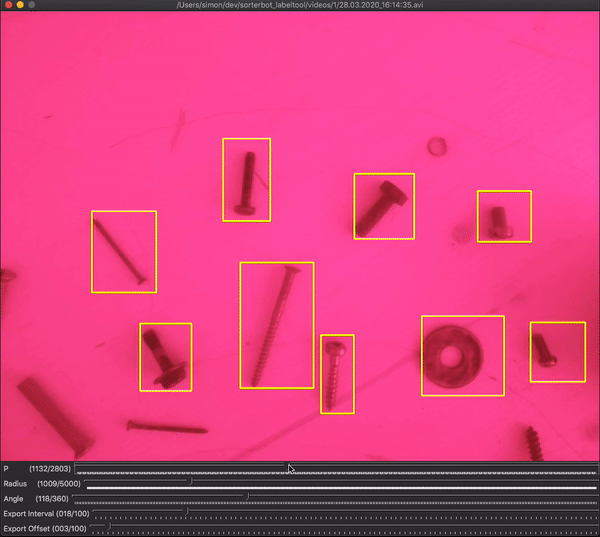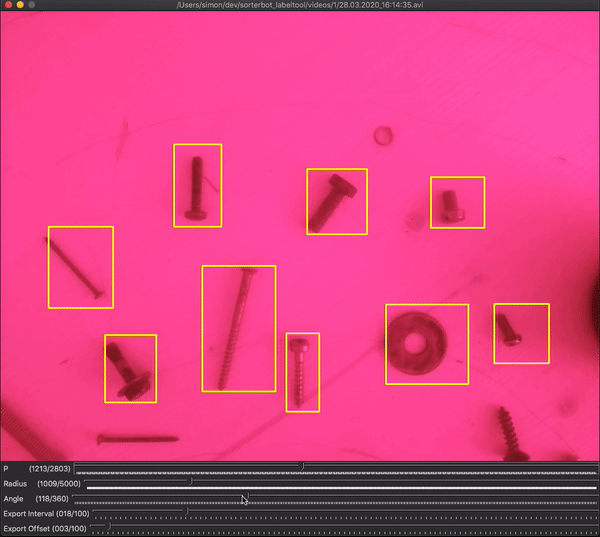
In the dataset creation tool, there are two sliders that define the trajectory of the bounding boxes: radius (in pixels) and angle (in degrees). Radius represents the distance between the robot’s base axis and the center of the camera’s viewport. While the angle represents the angle between the most counter-clockwise and the most clockwise positions. Setting these sliders define the positions of the bounding boxes, so the user should find the values where the bounding boxes are fitting the actual objects. First, the value for the radius slider should be approximated, then the angle slider should be moved until the bounding boxes are in the right positions.
在数据集创建工具中,有两个滑块定义边界框的轨迹:半径(以像素为单位)和角度(以度为单位)。 半径表示机器人的基本轴与摄像机视口中心之间的距离。 而该角度表示最逆时针位置和最顺时针位置之间的角度。 设置这些滑块可定义边界框的位置,因此用户应在边界框适合实际对象的位置找到值。 首先,应近似估计半径滑块的值,然后移动角度滑块,直到边界框位于正确的位置。

An additional 2 sliders are there to define which frames should be grabbed: interval and offset. The user should set them in a way that ensures grabbing the frames in the short pauses when the arm is not moving. To make this easier, the bounding box colors are changing to white when the current frame is set to be grabbed.
还有另外两个滑块可定义应抓取的帧:间隔和偏移。 使用者应以确保手臂不动时在短暂停片中抓取帧的方式进行设置。 为了使此操作更容易,将当前帧设置为抓取时,边框颜色将变为白色。
Even after all of the software tricks I could come up with, a few pictures were still blurred or the bounding boxes misplaced. To avoid these ending up in the dataset, I created another simple tool, which allowed me to go through the whole dataset, and keep or delete the images with a keystroke. This added a bit more time for dataset creation but also increased the resulting quality. After verification, the created dataset was uploaded by the labeling tool to an AWS S3 bucket, to be easily accessible for training.
即使经过我能想到的所有软件技巧,仍然有些照片仍然模糊或边界框放错了位置。 为了避免这些结果出现在数据集中,我创建了另一个简单的工具,使我可以遍历整个数据集,并通过按键保留或删除图像。 这增加了创建数据集的时间,但同时也提高了质量。 验证后,创建的数据集通过标签工具上传到AWS S3存储桶,以方便进行培训。
训练网络 (Training the network)
The training was done on DeepNote, using this notebook. I mostly followed the standard training procedure described in the Detectron2 documentation. As my first attempt, with a learning rate of 2.5e-4 and batch size of 512, the training took approximately 5 minutes, stopping after 600 iterations. This resulted in Average Precision (AP) of 33.4, which is significantly lower than the benchmark AP of the same network measured on ImageNet (40.2), but I tested the application with these weights and it worked perfectly, even with objects not present in the training dataset. The reason for this is probably that grabbing an item with a magnet doesn’t require great precision, basically, if the magnet touches the item anywhere, it can pick it up. That means even if the bounding box is off a significant amount, the magnet still can do its job. Most likely I could significantly increase the precision with longer training, more data, and hyperparameter tuning, but in order to avoid the mistake of trying to fix something that is not broken, I decided to focus my efforts elsewhere.
使用此笔记本在DeepNote上进行了培训。 我主要遵循Detectron2文档中描述的标准培训过程。 作为我的第一次尝试,学习速度为2.5e-4,批处理大小为512,训练大约花费5分钟,在600次迭代后停止。 这样得出的平均精度(AP)为33.4,大大低于ImageNet(40.2)上测量的同一网络的基准AP,但是我使用这些权重测试了该应用程序,即使在对象中不存在任何对象的情况下,它也可以正常工作训练数据集。 原因可能是用磁铁抓取一件物品并不需要很高的精度,基本上,如果磁铁在任何地方接触到该物品,它都可以捡起它。 这意味着即使边界框偏离了很大的量,磁体仍然可以完成其工作。 我很可能可以通过更长的训练,更多的数据和超参数调整来显着提高精度,但是为了避免尝试修复未损坏的错误,我决定将精力集中在其他地方。
When the training finished, I set the network to inference mode and used a few pictures from the validation set to visualize how the network performs.
训练结束后,我将网络设置为推理模式,并使用了验证集中的一些图片来可视化网络的运行情况。

As you can see on the picture above, all the items and containers are recognized with a relatively high confidence (87–94%), which is much higher than the 70% threshold I defined. The screw on the bottom left corner is not recognized, as its bounding box would be outside of the picture. This is intentional, I removed every bounding box like that from the training set to avoid displacing the center of the bounding box as it gets clipped to fit the picture. You can also notice that there is some padding left around the screws, this is intentional as well. I decided to draw slightly bigger bounding boxes around the objects to accommodate small deviations caused by the imperfect hardware. Since the magnet is moved to the middle of the bounding boxes, this will not prevent the arm from picking up objects as long as the padding is evenly spread around the object.
如上图所示,所有物品和容器的识别率都相对较高(87-94%),远高于我定义的70%阈值。 无法识别左下角的螺钉,因为其边界框将位于图片的外部。 这是有意的,我从训练集中删除了所有类似的边界框,以避免在修剪边界框以适合图片时移动边界框的中心。 您还可以注意到,螺钉周围还留有一些填充物,这也是故意的。 我决定在对象周围绘制稍大的边界框,以适应由不完善的硬件引起的微小偏差。 由于磁铁移动到包围盒的中间,因此只要填充物均匀地分布在对象周围,这就不会阻止手臂拾取对象。
Lastly, the trained weights are getting uploaded to another AWS S3 bucket, where the GitHub Actions CI pipeline can conveniently access them.
最后,训练有素的权重将被上传到另一个AWS S3存储桶,GitHub Actions CI管道可以在其中方便地访问它们。
部署到Amazon Web Services (Deploying to Amazon Web Services)
To deploy the whole solution to AWS, 43 resources have to be created and configured. First, I did it manually using the AWS Console, and also wrote a step-by-step guide to follow along. The guide has 100 steps and it takes approximately 3 hours to complete doing all the steps manually, leaving plenty of room for error. To make sure nobody (including me) has to go through this procedure ever again, I decided to automate the deployment utilizing AWS CDK and a lengthy bash script. The CDK (Cloud Development Kit) allows the user to define, configure, and deploy AWS resources using a conventional programming language. Right now Javascript, Python, C#, and Java are supported, I choose to go with Python. The bash script was used to orchestrate the process, and also to manage secrets, as that functionality is not supported by the CDK.
要将整个解决方案部署到AWS,必须创建和配置43个资源。 首先,我使用AWS控制台手动完成了该任务,还编写了一份循序渐进的指南 。 该指南有100个步骤,大约需要3个小时才能完成手动执行的所有步骤,因此有很大的出错空间。 为了确保没有人(包括我在内)必须再次执行此过程,我决定使用AWS CDK和冗长的bash脚本使部署自动化。 CDK(云开发工具包)允许用户使用常规编程语言定义,配置和部署AWS资源。 现在支持Javascript,Python,C#和Java,我选择使用Python。 由于CDK不支持该功能,因此bash脚本用于协调流程并管理机密。
自动部署 (Automated Deployment)
In the sorterbot_installer repository there are two CDK stacks: one for development and one for production. The development stack is a subset of the production, it provides S3 buckets and a PostgreSQL instance, so the full functionality of the solution can be accessed in development mode as well. Besides these, the production stack includes an EC2 t2.micro instance (included in the Free Tier) to run the SorterBot control panel, an ECR repository to store Docker images for the inference engine, an ECS FarGate cluster to deploy the inference engine, and some additional infrastructure that is required for these components to work together, such as a VPC, Security Groups, and IAM roles/policies. There are scripts included for both deploying and destroying the development and production versions as well. The development scripts are mostly subsets of the production scripts, so I will not get into the details of describing them here. When deploying to production, the script executes the following steps:
在sorterbot_installer存储库中,有两个CDK堆栈:一个用于开发,一个用于生产。 开发堆栈是产品的子集,它提供S3存储桶和PostgreSQL实例,因此该解决方案的全部功能也可以在开发模式下访问。 除此之外,生产堆栈还包括一个EC2 t2.micro实例(包含在Free Tier中),用于运行SorterBot控制面板,一个用于存储推理引擎的Docker映像的ECR存储库,一个用于部署推理引擎的ECS FarGate集群,以及这些组件协同工作所需的一些其他基础结构,例如VPC,安全组和IAM角色/策略。 还包括用于部署和销毁开发和生产版本的脚本。 开发脚本大部分是生产脚本的子集,因此在此我将不介绍它们的详细信息。 部署到生产环境时,脚本将执行以下步骤:
- Environment variables are loaded from the .env file and a few other variables are set explicitly. The environment variables that have to be set by the user are the following: AWS account ID, GitHub username, GitHub Personal Access Token, S3 URL to the trained model weights, and a user/password combination for logging in to the control panel (also used as Django Admin credentials). Other than that, the AWS region where the solution will be deployed is retrieved from the default profile of the local system, which can be set with the `aws configure` command. 环境变量是从.env文件加载的,其他一些变量是显式设置的。 用户必须设置的环境变量如下:AWS账户ID,GitHub用户名,GitHub个人访问令牌,经过训练的模型权重的S3 URL,以及用于登录控制面板的用户/密码组合(也用作Django Admin凭据)。 除此之外,将从本地系统的默认配置文件检索将部署解决方案的AWS区域,可以使用“ aws configure”命令进行设置。
- To store the secrets, AWS Simple Systems Manager’s (SSM) Parameter Store is used. This is a free option (as opposed to AWS Secrets Manager, which costs $0.40 per secret per month), and the secrets are stored encrypted if the SecureString option is chosen. 为了存储机密,使用了AWS Simple Systems Manager(SSM)的参数存储。 这是一个免费选项(与AWS Secrets Manager相对,后者每个月每个密钥$ 0.40的费用),并且如果选择了SecureString选项,则会以加密方式存储秘密。
- The AWS CLI is used to create an SSH keypair that later on can be used to access the deployed EC2 instance. AWS CLI用于创建SSH密钥对,以后可用于访问已部署的EC2实例。
- Access to the AWS account is granted for the GitHub Actions workflow. To do that, first, an AWS IAM user is created, then a policy is attached to it which provides the necessary privileges. Lastly, an access key is created to this user, which is saved to the sorterbot_cloud repository as a GitHub Secret, using the GitHub API. 授予GitHub Actions工作流程对AWS账户的访问权限。 为此,首先创建一个AWS IAM用户,然后将一个附加必要策略的策略附加到该用户。 最后,为此用户创建一个访问密钥,使用GitHub API将其作为GitHub Secret保存到sorterbot_cloud存储库。
- The CDK deploys the production stack, which provisions and configures all the resources mentioned above. CDK部署生产堆栈,该堆栈配置并配置上述所有资源。
- The host of the newly created EC2 instance is retrieved, and a bash script is executed on it over SSH to install the dependencies needed to run the control panel: Git LFS, Python, Docker, Docker Compose, etc. 检索新创建的EC2实例的主机,并通过SSH在其上执行bash脚本,以安装运行控制面板所需的依赖项:Git LFS,Python,Docker,Docker Compose等。
- After the dependencies are installed, the Docker image of the control panel is built. 安装依赖项后,将构建控制面板的Docker映像。
- In order to avoid security issues that arise when passwords are used as Docker build arguments, Django migrations and user creation are executed outside Docker. To do this, the pip packages listed in requirements.txt are installed outside of the Docker container as well. 为了避免在将密码用作Docker构建参数时出现安全问题,在Docker外部执行Django迁移和用户创建。 为此,requirements.txt中列出的pip软件包也安装在Docker容器之外。
- When the control panel is set up, a new release is created in the sorterbot_cloud repo, which triggers the GitHub Actions workflow that deploys the inference engine’s Docker image to ECS. 设置控制面板后,将在sorterbot_cloud存储库中创建一个新版本,该版本会触发GitHub Actions工作流,该工作流会将推理引擎的Docker映像部署到ECS。
- Finally, after the release was created, the control panel gets started using Docker Compose. The DNS address is printed to the logs, where the user can log in using the username and password specified in the .env file before deployment. 最后,在创建发行版之后,控制面板开始使用Docker Compose。 DNS地址将打印到日志中,用户可以在其中使用.env文件中指定的用户名和密码在部署之前登录。
CI工作流以部署推理引擎 (CI workflow to deploy the Inference Engine)
The CI workflow that deploys the inference engine to AWS ECS is defined as a GitHub Action. It can be triggered by creating a new release in the GitHub repo, which is done automatically when the production deploy script runs. The workflow first checks out the master branch, lints it using flake8, installs dependencies (or loads them from cache if the requirements.txt file didn’t change), then runs the tests using pytest. If all the tests are passing, the deployment starts.
将推理引擎部署到AWS ECS的CI工作流被定义为GitHub Action。 可以通过在GitHub存储库中创建新版本来触发它,该新版本在生产部署脚本运行时自动完成。 该工作流程首先检出master分支,使用flake8对其进行归类,安装依赖项(或在require.txt文件未更改的情况下从缓存中加载依赖项),然后使用pytest运行测试。 如果所有测试均通过,则部署开始。
First, the master branch gets checked out with Git LFS, so in case no model weights URL is provided, the default sample weights can be used, which are committed to the repository. Then the next action configures AWS credentials, which are used to log in to ECR. After that, the Docker image is built, tagged, and pushed to ECR. Next, a new version of the task definition is created, then finally, the task definition is deployed. Using this workflow makes it effortless to replace the model weights. After new weights are uploaded to the appropriate S3 bucket, only a new release has to be created, and Github Actions deploys it automatically without any further input from the user.
首先,使用Git LFS检出master分支,因此,如果未提供模型权重URL,则可以使用默认的样本权重,这些权重将提交给存储库。 然后,下一个操作将配置用于登录ECR的AWS凭证。 之后,将构建,标记Docker映像并将其推送到ECR。 接下来,创建任务定义的新版本,然后最后部署任务定义。 使用此工作流程可以轻松替换模型权重。 将新的权重上传到适当的S3存储桶后,只需创建一个新版本,Github Actions便会自动部署它,而无需用户进一步输入。
结论与未来工作 (Conclusion and Future Work)
In this project, I built a web application that is easy to deploy and manage. It can control an arbitrary number of robotic arms. The current architecture could probably handle a few arms that are operating at the same time, but much more than that would most likely lead to serious delays due to the lack of proper multiprocessing. Since in this project, it wasn’t my goal to handle many arms, and I didn’t want to spend money on more powerful ECS instances that have more than 1 core, I didn’t focus much on scaling up the inference engine. Since it is deployed to ECS, by setting up auto-scaling or by moving image processing to a separate process for each image and purchasing instances with multiple cores could enable scalability with minimal effort.
在这个项目中,我构建了一个易于部署和管理的Web应用程序。 它可以控制任意数量的机械臂。 当前的体系结构可能会处理几个同时运行的分支,但是由于缺乏适当的多处理功能,这可能会导致严重的延迟。 自从在这个项目中以来,我的目标并不是要拥有很多武器,而且我也不想花钱在功能更强大的ECS实例上,这些实例具有1个以上的内核,因此我并没有专注于扩展推理引擎。 由于已将其部署到ECS,因此通过为每个图像设置自动缩放或将图像处理移至单独的过程,然后购买具有多个内核的实例,可以以最小的努力实现可伸缩性。
The biggest issue by far was the low quality of the robotic arm. To circumvent its shortcomings, I implemented some extra logic in the software, which could be omitted if a good quality arm would be used. Also, the accuracy of the neural network could be still improved, but since the hardware’s accuracy is severely limited, working on improving the model probably wouldn’t lead to much overall improvement, if any.
迄今为止最大的问题是机械臂的质量低下。 为了避免它的缺点,我在软件中实现了一些额外的逻辑,如果使用高质量的手臂,则可以省略这些逻辑。 同样,神经网络的精度仍可以提高,但是由于硬件的精度受到严重限制,因此改进模型的工作可能不会带来太多的总体改进(如果有的话)。
As a next step, I plan to build a robotic arm on my own using 3D printing. High accuracy 3D printing became extremely affordable, the Elegoo Mars resin printer costs under $400 and offers accuracy less than 50 microns. Combining that with generative design, like the one provided by Autodesk, an accurate, lightweight, and organic-looking robotic arm could be built.
下一步,我计划使用3D打印自行构建机械臂。 高精度3D打印变得极为负担得起, Elegoo Mars树脂打印机的价格在400美元以下,精度不到50微米。 将其与诸如Autodesk提供的生成设计相结合,可以构建出精确,轻巧且外观有机的机械臂。
The other limitation is gripping: using the magnet limits the arm to grip metallic objects. To get around that, another gripping mechanism could be used, like this one from Festo (inspired by chameleon’s tongue as it grabs its prey).
另一个限制是抓地力:使用磁铁限制手臂抓握金属物体。 要解决这个问题,另一个把持机构可以使用,像这样一个从费斯托(由它抓住猎物变色龙的舌头启发)。
Thank you for reading, and if you have any questions, comments, or suggestions, please let me know!
感谢您的阅读,如果您有任何疑问,意见或建议,请告诉我!















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









