





aerospike删除数据
In continuation of my previous article where I’ve detailed on the limitations of goroutines, in this article, I would like to share how we achieved 70 million sets to Aerospike Database in 30 minutes by leveraging the entire system Cores with the help of Go Worker Pool Pattern.
在上一篇文章继续详细介绍goroutine的局限性时,我想在本文的后续内容中,分享在Go Worker的帮助下,如何利用整个系统内核在30分钟内达到Aerospike数据库7000万套的方法。游泳池模式。
Usecase Insights
用例见解
- Currently, at GoIbibo we had close to 70 million users and we had a set of categories that each user belongs to. The categories describe if the user is new | fraud |regular transacting user | user who didn’t transact in last year etc and so on … 目前,在GoIbibo,我们有近7000万用户,并且每个用户都拥有一组类别。 类别描述用户是否是新用户| 欺诈|常规交易用户| 去年未进行交易等的用户...
- User Categories change dynamically based on their behaviour and we have a generation task where we gather the data from multiple sources and save to our Database with Key as UserID and Value as List of Categories and the generation has to happen for all 70 million users every day. 用户类别根据其行为动态变化,我们有一个生成任务,我们从多个来源收集数据,并以键作为UserID和值作为类别列表保存到我们的数据库中,并且每天必须为所有7000万用户进行生成。
Database Insights
数据库见解
- For those who are not aware of Aerospike, it’s a multi-threaded and distributed Key-Value store with storage based out of SSD. 对于那些不了解Aerospike的人来说,这是一个多线程和分布式键值存储,其存储基于SSD。
- We have 3 instances of Aerospike where keys get split and stored across instances with the desired replication factor. 我们有3个Aerospike实例,其中密钥被拆分并以所需的复制因子跨实例存储。
Advantages over Redis
与Redis相比的优势
- This being a multi-threaded Key-Value Store doesn’t block all the requests in case if there is any slow query unlike Redis, that blocks all the requests if 1 request gets slowed down 这是一个多线程的键值存储,不会阻止所有请求,以防万一发生与Redis不同的慢查询,如果1个请求变慢则阻止所有请求
- SSD being cheaper than RAM and being a distributed database we always have a chance to horizontally scale, unlike Redis where we need to scale vertically with growing data. SSD比RAM便宜,而且作为分布式数据库,我们总是有机会进行水平扩展,与Redis不同,我们需要随着数据的增长而垂直扩展。
Drawbacks
缺点
- This doesn’t support batch set which means if we need to insert 70 million key-value, we need to make 1 call to DB per key which equals 70 million DB Calls. 这不支持批处理集,这意味着如果我们需要插入7,000万个键值,则需要每个键对DB进行一次调用,这等于7,000万次DB调用。
Approaches, Pitfalls and TakeOver’s
方法,陷阱和接管
We aggregate data from multiple sources and aggregate all the data in memory in a map data structure with the key being userID and value being the list of categories. We initially started with a synchronous approach by iterating through the map wherein we are setting one record to the database at a time. When we tried to benchmark the above solution it resulted to be the worst possible way. Why?
我们汇总来自多个来源的数据,并将汇总在内存中的所有数据汇总到map数据结构中,其键为userID,值为类别列表。 最初,我们通过遍历地图的同步方法开始,其中我们一次将一个记录设置到数据库。 当我们尝试对上述解决方案进行基准测试时,结果可能是最糟糕的方法。 为什么?
We are running on 8 Core CPU and a Database that supports multi-threading and distributed but with sequential processing, I am not either utilizing the system cores neither the DB Resources. Let’s calculate the total time taken for a sequential generation.
我们在8核CPU和一个支持多线程和分布式但具有顺序处理能力的数据库上运行,我既没有利用系统核心,也没有利用数据库资源。 让我们计算连续生成所花费的总时间。
70,00,00,000 keys * 2 ms(average set speed) = 140,00,00,000 ms = 39 hours
70,00,000,000键* 2毫秒(平均设定速度)= 140,00,00,000毫秒= 39小时

What the hell did I just saw? A task that has to be generated twice every day is taking a whopping 40 hours which is close to 2 days. Is this feasible? Hell no.
我刚刚看到了什么? 每天必须生成两次的任务要花费多达40个小时的时间,接近2天。 这可行吗? 一定不行。
This is where we analysed that sequential processing doesn’t work and we have to parallelise the task by using the entire system & DB Resources and that is when we came across the Go Worker Pool Pattern.
在这里,我们分析了顺序处理不起作用的情况,并且我们不得不使用整个系统和数据库资源来并行化任务,也就是当我们遇到Go Worker Pool Pattern时 。
Let’s first get to have a touch base on the code and I will get you through each line and also provide a detailed explanation on how context switching happens.
首先,让我们对代码有所了解,然后我将指导您完成每一行,并提供有关上下文切换如何发生的详细说明。
Now let’s get through each line of code.
现在,让我们遍历每一行代码。
First, we get the aggregated data with keys as userIDs and values as a slice of categories.
首先,我们获得聚合数据,其中键作为用户ID,值作为类别。
Worker Pool Pattern (Pseudo Code)
工人池模式(伪代码)
- First, we advertise saying at any given point of time we will have a maximum of 100 jobs via a buffered job channel. 首先,我们做广告说,在任何给定的时间点,通过缓冲的作业通道最多可以有100个作业。
- We then recruit 60 workers who keep waiting for jobs. 然后,我们招募60名不断等待工作的工人。
- Once we’ve fed the workers with all the jobs with nothing left in our plate, we can successfully terminate the workers. 一旦我们为工人提供了所有工作,而盘子里没有东西,我们就可以成功解雇工人。
In-depth understanding of code.
深入了解代码。
When we made a call to createWorkers fn, it internally spawned 60 workers a.k.a goroutines uniformly over 8 core CPU. Every worker that we spawned keeps listening to an event from the jobs channel and until it receives an event the code inside the for loop (AerospikeWrapper.Set) doesn’t get executed.
当我们调用createWorkers fn时,它在内部产生了8个核心CPU上的60个工人(又称goroutine)。 我们产生的每个工作程序都会继续监听作业通道中的事件,直到接收到事件为止,for循环(AerospikeWrapper.Set)中的代码都不会执行。
Now that we’ve had enough workers in the pool, it’s time for us to feed the workers with some work. In our case, the feed to the worker should contain an userID, categories (passed via userData struct) of a particular user which can then be sent to DB.
现在我们已经有足够的工人在游泳池中了,是时候让我们为工人提供一些工作了。 在我们的例子中,提供给工作程序的提要应该包含一个用户ID,一个特定用户的类别(通过userData结构传递),然后可以将其发送到数据库。
To represent the scenario in a picture, it looks like below.
为了在图片中表示场景,如下所示。
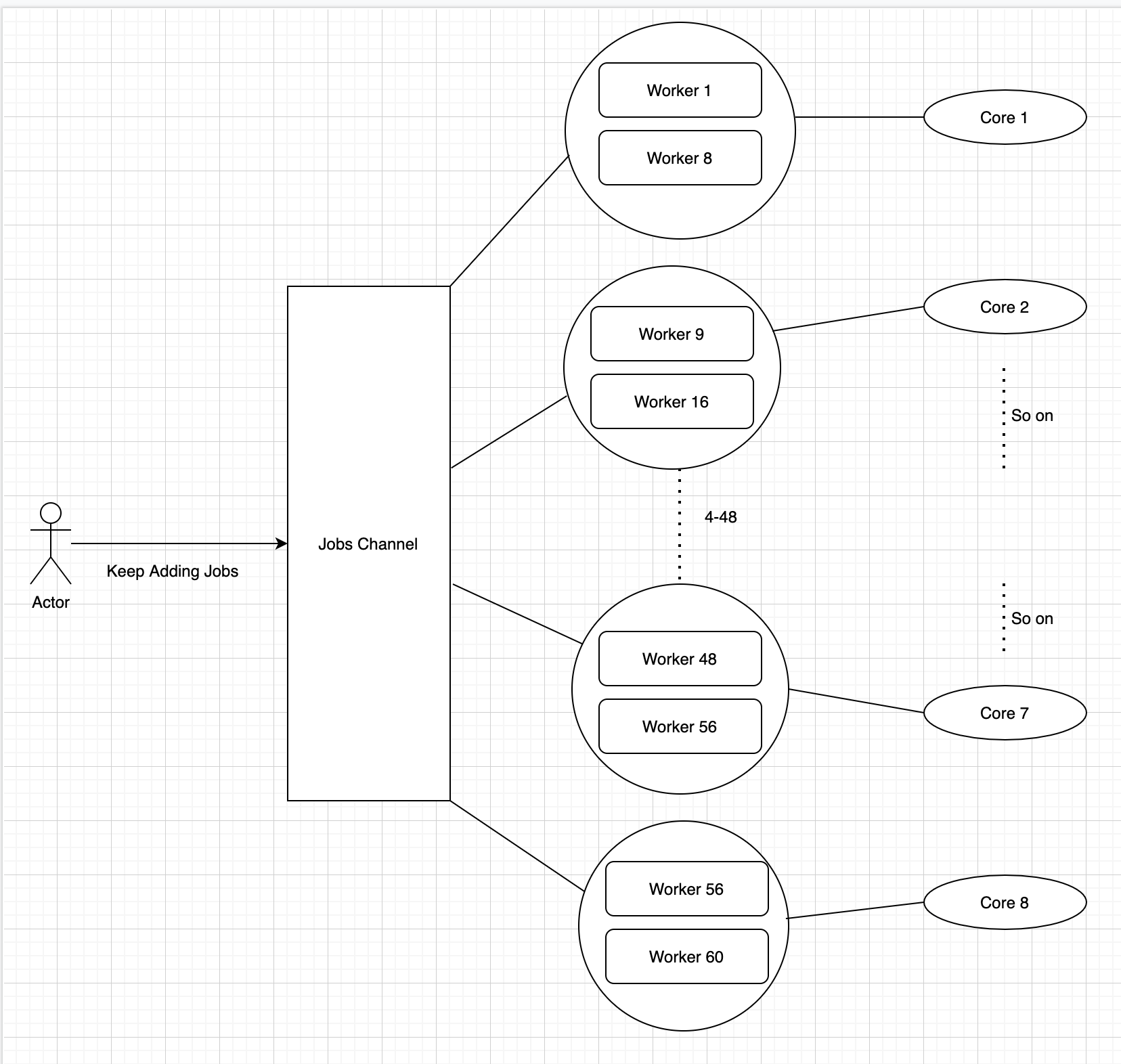
As we spawned 60 workers across 8 cores, each core is responsible to handle close to an average of 7–8 goroutines. Each of these goroutines keeps listening to the jobs channel for a new job and as soon as it got a job, it then performs the database set sequentially. But here is a catch.
当我们在8个核心中产生60名工人时,每个核心负责平均处理近7-8个goroutine。 这些goroutine中的每一个都会继续监听作业通道以查找新作业,并且一旦获得作业,它就会依次执行数据库设置。 但是这里有一个陷阱 。
We all know that a CPU core can almost execute only one instruction at a time, does that mean we can parallelise the process to only * no of CPU cores? Hell no…
我们都知道,一个CPU内核几乎一次只能执行一条指令,这是否意味着我们可以将进程并行化为仅*没有CPU内核? 一定不行…
This is where the Context Switching comes into the picture.
这是上下文切换进入画面的地方。
The first goroutine handled by the first core gets an event and as soon as we start a database call inside the goroutine, it will be pushed to the process queue as database call being asynchronous and the next goroutine will start listening to the jobs channel and this cycle repeats until one of the items in process queue is done executing.
由第一个内核处理的第一个goroutine会获得一个事件,并且一旦我们在goroutine中启动数据库调用,由于数据库调用是异步的,它将被推送到进程队列,而下一个goroutine将开始侦听Jobs通道,并且重复循环,直到完成处理队列中的一项为止。
Once the item in the process queue is done executing the synchronous network | I/O operation, the CPU Core will again pick this item in process queue and execute this until it hits an I/O or Network Call again. If it doesn’t it will be done executing that job and move on to the next.
一旦处理队列中的项目完成,就执行同步网络。 I / O操作,CPU核心将再次在进程队列中选择此项目并执行,直到再次遇到I / O或网络调用。 如果没有,将执行该作业并继续执行下一个作业。
If you look at the sequence of actions that we did, at any given point of time we are making around 60 DB calls in parallel which is directly proportional to the number of workers that we had in the pool.
如果看一下我们执行的操作顺序,那么在任何给定时间点,我们都会并行进行约60个DB调用,这与池中的工作人员数量成正比。
Though the process of context switching is way too complex than what I say, I just wanna give a top-level overview of how it happens and how each core is responsible for handling a set of goroutines.
尽管上下文切换的过程比我说的要复杂得多,但是我只想概述一下它是如何发生的,以及每个内核如何负责处理一组goroutine。
With this, we achieved close to 10000 Database Sets per Second to Aerospike/Instance and we have 3 DB instances.
这样,我们达到了每秒接近10000个Aerospike / Instance数据库集,并且我们有3个数据库实例。
So 7,00,00,000 / 30,000 = 35 minutes.
所以7,00,00,000 / 30,000 = 35分钟。
Hope I’ve conveyed what I intended to. In case of any question do post a comment and I will surely try to reply.
希望我已经传达了我的意图。 如有任何疑问,请发表评论,我一定会尝试答复。
In the next article, I will detail on visualising the CPU Utilisation using HTOP.
在下一篇文章中,我将详细介绍如何使用HTOP可视化CPU利用率。
Stay Tuned
敬请关注
aerospike删除数据















 1489
1489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









