





c程序中使用simd
SIMD. Single instruction multi data. You may not have heard of these four words before, but they have the power to make software run at lightning speed. They can accelerate actions like copying or searching data 10x, 20x or more times faster than with traditionally written code. The CPUs that power our computers today possess a special set of instructions that can process data simultaneously, and in parallel. In fact, the sets of these instructions have been around for a number of years. They are seldom explored or discussed, but have the potential to provide unparalleled performance in a world of ever growing software capacity.
SIMD。 单指令多数据。 您可能以前没有听说过这四个词,但是它们可以使软件以闪电般的速度运行。 与传统编写的代码相比,它们可以加快10倍,20倍或更多倍的复制或搜索数据速度。 今天,为我们的计算机供电的CPU具有一组特殊的指令,可以同时,并行地处理数据。 实际上,这些指令集已经存在很多年了。 很少探讨或讨论它们,但是在软件容量不断增长的世界中,它们有可能提供无与伦比的性能。
Using them though, is a bit easier sad than done. Most technologies or techniques in programming run code written in a programming language and automate a task. That code is either compiled to instructions that run on a virtual machine, or in the case of languages like C or C++, it’s compiled down to assembly along with a few more steps to form an executable. A programmers role is writing programs in the programming language, leaving the process of transforming code into instructions, to a compiler. Many high level languages like Ruby or Python also provide wrappers for cross platform system level functions, so the programmer may not even be aware of what operating system their code runs on.
尽管使用它们,比做起来容易难过。 编程中的大多数技术都运行以编程语言编写的代码并使任务自动化。 将该代码编译为在虚拟机上运行的指令,或者对于C或C ++之类的语言,将其编译为可汇编代码以及一些其他步骤以形成可执行文件。 程序员的作用在写入编程语言编写的程序,使转换成代码的指令,在编译的过程。 许多高级语言(如Ruby或Python)也提供了跨平台系统级功能的包装器,因此程序员甚至可能不知道其代码在什么操作系统上运行。
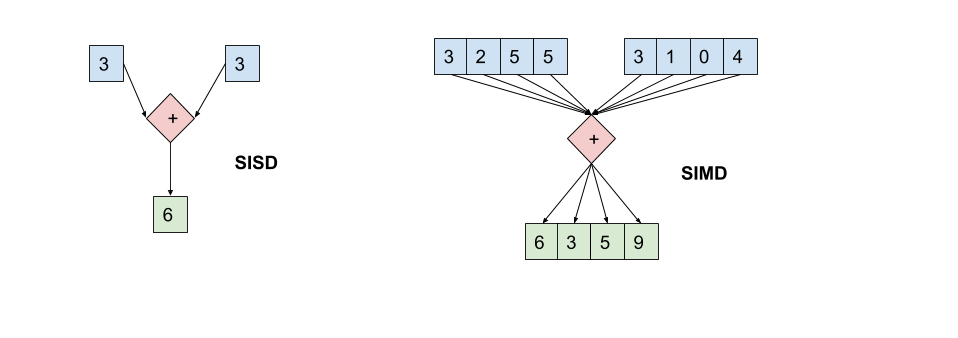
SIMD is not a feature of programming languages in any traditional sense. It dives far below the comforting layers of compilers, virtual machines, and even operating systems. SIMD functions and runs at the processor level. SIMD is a paradigm of assembly instructions that can be executed on a CPU which has special registers that handle vectors. The normal assembly instructions generated by compilers are called SISD, standing for single instruction single data. One instruction, such as addition, operates on one designated data value at a time. SIMD, on the other hand, operates on fixed sized groups of data called vectors. Each pair of values at each position in both vectors undergo the same operation, but simultaneously. The diagram below illustrates the comparison.
SIMD不是任何传统意义上的编程语言的功能。 它潜入的深度远远低于编译器,虚拟机甚至操作系统的舒适层。 SIMD在处理器级别运行并运行。 SIMD是汇编指令的范例,可以在具有处理向量的特殊寄存器的CPU上执行。 编译器生成的常规汇编指令称为SISD,代表单指令单数据。 一条指令(例如加法)一次对一个指定的数据值进行运算。 另一方面,SIMD在固定大小的称为向量的数据组上运行。 两个向量中每个位置的每对值都经过相同的运算,但同时进行。 下图说明了比较。
Fortunately, you don’t need to write assembly in order to use SIMD instructions. In fact, several C++ compilers like Clang or GCC offer intrinsics, that allow a compiler to replace programming language syntax with SIMD instructions.
幸运的是,您无需编写汇编即可使用SIMD指令。 实际上,一些C ++编译器(例如Clang或GCC)提供了内在函数,使编译器可以用SIMD指令替换编程语言语法。
向量化,它是自动的吗? (Vectorization, is it automatic ?)
One question is: can compilers just use SIMD instructions in place of SISD instructions? The answer is complicated. Automatic use of SIMD instructions in compilers is an area of academic research called Automatic Vectorization . Here, “automatic” means that the compiler would know what SIMD instructions to generate for the code you write in a programming language. In some cases, this is possible, such as looping through an array of integers and summing them or applying an identical action. However, there are quite a number of limitations to this if the loop has many conditional statements or control flows. A method of processing data in single values does not always translate to a method of processing data in vectors, in the same way some languages have phrases which do not translate well or at all to others.
一个问题是:编译器可以仅使用SIMD指令代替SISD指令吗? 答案很复杂。 在编译器中自动使用SIMD指令是学术研究领域,称为自动向量化。 在这里,“自动”意味着编译器将知道要为您用编程语言编写的代码生成哪些SIMD指令。 在某些情况下,这是可能的,例如循环遍历整数数组并对它们求和或应用相同的操作。 但是,如果循环具有许多条件语句或控制流,则对此有很多限制。 以单个值处理数据的方法并不总是转换为以向量处理数据的方法,就像某些语言具有无法很好地转换或完全无法转换为其他语言的短语一样。
Programming with SIMD means switching the way you think to using vectors and groups of data. This article demonstrates how you can rethink a problem to be solved with vectors, and take the performance of your code to levels you never thought possible.
使用SIMD进行编程意味着将您的思维方式切换为使用向量和数据组。 本文演示了如何重新思考要使用向量解决的问题,以及如何将代码的性能提升到您从未想到的水平。
数据,字符串和计数 (Data, Strings, and Counting)
Big data processing and searching often deals with text contained in string objects. One problem we can use for a test run is counting the characters in strings. Usually, a string is composed of bytes, with some encoding, like UTF-8. A very simple task to perform on a string is to count the number of times some character appears in a string. A traditional approach to such a problem would involve a loop over each character, comparing it to the target character that’s being counted, and if it matches, incrementing a counter.
大数据处理和搜索通常处理包含在字符串对象中的文本。 我们可以用于测试运行的一个问题是对字符串中的字符进行计数。 通常,字符串由字节组成,并带有某种编码,例如UTF-8。 对字符串执行的一个非常简单的任务是计算某个字符出现在字符串中的次数。 解决此问题的传统方法是在每个字符上循环,将其与要计数的目标字符进行比较,如果匹配,则增加一个计数器。
The difference is, SIMD does not have control flow that’s at all related to if { ... } else { ... } style of statements in programming languages. Primarily because such conditional statements are designed for single data flows. SIMD, instead uses masks, vectors whose bits represent boolean results of comparison operations. For example, the following diagram represents an equality operation, where the 8-bit unsigned integers between two vectors are compared.
区别在于,SIMD根本没有与编程语言中的if { ... } else { ... }语句样式相关的控制流。 主要是因为此类条件语句是为单个数据流设计的。 SIMD改为使用masks (向量),其位表示比较操作的布尔结果。 例如,下图表示一个相等运算,其中比较两个向量之间的8位无符号整数。
口罩 (Masks)
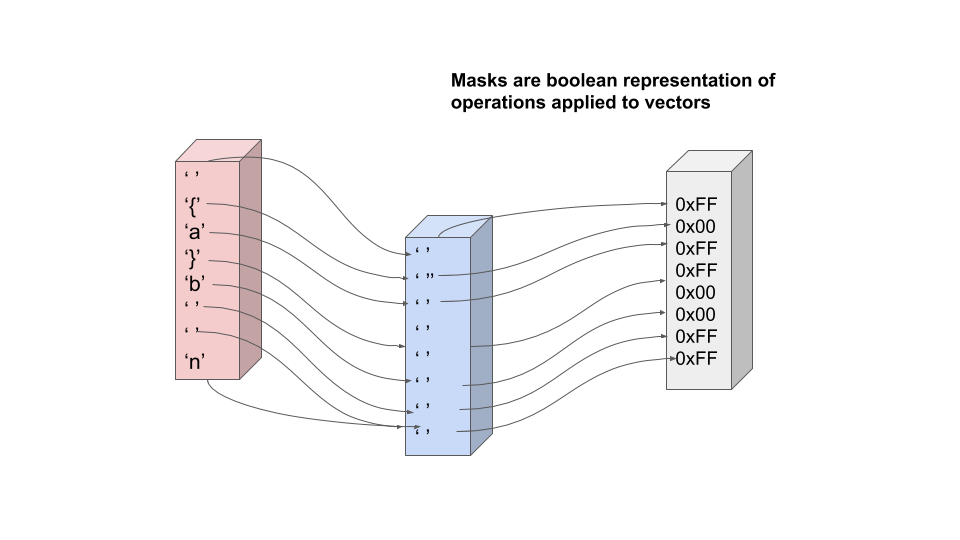
The result is stored in the grey vector. For positions where the values were equal , all the bits of that position in the result vector are set. If the two values in the position of the operand vectors were not equal, all the bits in the result vector are unset. Think of this as saying, “true means 1” and “false means zero”. The mask vectors can be used in other SIMD operations to control the flow of data from one vector to another.
结果存储在灰色向量中。 对于值相等的位置,将设置结果向量中该位置的所有位。 如果操作数向量位置中的两个值不相等,则结果向量中的所有位均未设置。 可以这样说:“ true表示1”,“ false表示零”。 掩码向量可用于其他SIMD操作中,以控制数据从一个向量流向另一个向量。
For this problem, we aren’t really interested in data flow specifically. We want to determine the count of a specific character within a string. We need a way to take the mask vector from the comparison operation, and produce a count of the set integers. We will use two instructions from a more basic instruction set called SSE2. This is an instruction set which operates on 128-bit vectors and is based off the x86 architecture, found in Intel or AMD processors. This means that for the case of strings and characters, SSE2 vectors can process 16 characters in each operation. There are instruction sets capable of processing much more than just 16 characters at a time, but those are beyond the scope of this article.
对于这个问题,我们对数据流并不特别感兴趣。 我们要确定字符串中特定字符的计数。 我们需要一种方法来从比较操作中提取掩码向量,并生成设置整数的计数。 我们将使用来自更基本的指令集SSE2的两条指令。 这是一个基于128位矢量的指令集,基于Intel或AMD处理器中的x86架构。 这意味着对于字符串和字符,SSE2向量在每个操作中可以处理16个字符。 有些指令集一次只能处理16个以上的字符,但这超出了本文的范围。
The next two instructions needed for our solution will convert the 128-bit mask into a 16-bit mask, and count the number of set bits in the 16-bit mask. These are commonly referred to as “move mask” and “pop count” instructions, respectively . In the diagram below, the first row of boxes represent 8-bit integers within a 128-bit vector. The value FF is the hexadecimal value for 255, indicating all bits are set. Conversely, the value 00 indicates no bits are set.
解决方案所需的下两条指令将把128位掩码转换为16位掩码,并计算16位掩码中设置的位数。 这些指令通常分别称为“移动蒙版”和“弹出计数”指令。 在下图中,第一行方框表示128位向量中的8位整数。 值FF是255的十六进制值,表示已设置所有位。 相反,值00表示未设置任何位。
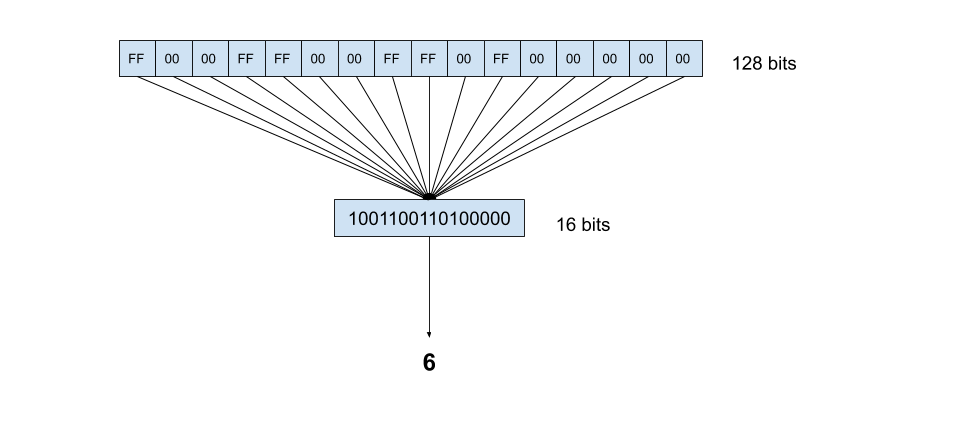
Now that the sequence of steps in the SIMD solution is visualized and understand, let’s look at the code involved for both the normal and the SIMD approach.
既然已经可视化并理解了SIMD解决方案中的步骤顺序,那么让我们看一下常规方法和SIMD方法所涉及的代码。
代码 (The Code)
First, the typical, C approach to counting characters in a string. The intention here is to make the two functions as similar as possible, except for the use of regular counting code and the SIMD intrinsics. In any software performance test, it’s vital to control other variables as tightly as possible.
首先,使用典型的C方法对字符串中的字符进行计数。 这里的目的是使两个函数尽可能相似,除了使用常规计数代码和SIMD内部函数。 在任何软件性能测试中,至关重要的是要尽可能严格地控制其他变量。
Here, a while loop is used, which a termination condition of reading all the characters in the C-string. If the character matches the target character, increase the characters matched count by 1. In any case, increase the characters consumed counter as well as incrementing the pointer.
这里,使用了while循环,这是读取C字符串中所有字符的终止条件。 如果该字符与目标字符相匹配,则将匹配的字符数增加1。在任何情况下,都应增加消耗字符的计数器以及递增指针。
Now, for the SIMD function.
现在,用于SIMD功能。
This might look a bit complicated, as there are some components I didn’t yet explain. First, __m128i is a data type that’s meant to embody a register within the context of a language like C. In reality, an x86 CPU has specific, named registers for 128-bit SIMD operations, but the compiler in this case will pick and choose which registers to use on it’s own. The function call expressions beginning with _mm_* are compiler intrinsics for the x86 SIMD instructions. They permit the compiler to inline specific instructions to perform, in this scenario, 128-bit vector operations. They are not true function calls, they make no use of the stack pointer or base pointer registers.
这看起来有些复杂,因为有些组件我还没有解释。 首先, __m128i是一种数据类型,旨在在诸如C之类的语言上下文中体现一个寄存器。实际上,x86 CPU具有用于128位SIMD操作的特定的命名寄存器,但是在这种情况下,编译器会选择自己使用哪个注册。 以_mm_*开头的函数调用表达式是x86 SIMD指令的编译器固有函数。 它们允许编译器内联特定指令以在这种情况下执行128位向量运算。 它们不是真正的函数调用,它们不使用堆栈指针或基址指针寄存器。
The intrinsic _mm_set1_epi8 sets all 16, 8-bit integers within a vector to a specific value. This step only needs to be done once before the loop because we will always be comparing against the same character for all operations during the course of the loop. _mm_load_si128 loads 128-bits of data from memory into a 128-bit register. In order for any data to undergo SIMD operations of any size or variety, it must be explicitly loaded from memory into such a register. The next two intrinsics, _mm_cmpgt_epi8 and _mm_movemask_epi8, compare against the vector of all the same character, and convert the mask into 16 bits of a 32 bit integer type int, respectively.
固有的_mm_set1_epi8将向量内的所有16个8位整数设置为特定值。 该步骤仅需要在循环之前完成一次,因为在循环过程中,我们将始终将相同字符与所有操作进行比较。 _mm_load_si128将内存中的128位数据加载到128位寄存器中。 为了使任何数据经受任何大小或种类的SIMD操作,必须将其从内存中显式加载到此类寄存器中。 接下来的两个内在函数_mm_cmpgt_epi8和_mm_movemask_epi8与所有相同字符的向量进行比较,并将掩码分别转换为32位整数类型int 16位。
The _popcnt32 intrinsic is responsible for counting the number of set bits in an integer. It does not have the _mm_ prefix, because it does not operate on 128-bit registers, it just operates on standard 64-bit registers.
_popcnt32内部函数负责计算整数中设置的位数。 它没有_mm_前缀,因为它不能在128位寄存器上运行,而只能在标准64位寄存器上运行。
For reference, you can view a list of Intel’s x86 intrinsics here.
作为参考,您可以在此处查看Intel x86内部函数的列表。
To measure the performance of these two functions, I will use the more precise timing library specific to the unix operating system. The timing function uses code from the <sys/time.h> header and will measure performance in microseconds, as follows:
为了衡量这两个功能的性能,我将使用特定于unix操作系统的更精确的时序库。 计时功能使用来自<sys/time.h>标头的代码,并将以微秒为单位测量性能,如下所示:
考试 (The Test)
The test for each function will be to count the number of lines in a CSV document that is exactly 1.6 GB, or 16,000,000,000 bytes long. Since we only want to measure the counting portion of each function, the CSV document will exist as a string in memory, to avoid variability in reading from disk. The number of lines in a CSV document corresponds to the number of newline characters, '\n' , minus one.
每个功能的测试将是计算CSV文档中的行数,该行数正好为1.6 GB或16,000,000,000字节长。 由于我们只想测量每个函数的计数部分,因此CSV文档将以字符串形式存在于内存中,以避免从磁盘读取时出现变化。 CSV文档中的行数对应于换行字符'\n'减一。
For this test, I am using a 2.7 GHz Quad-Core Intel Core I7 processor. Performance tests of any kind, but especially for SIMD are highly sensitive to changes in the environment, such as the processor, the other applications running on the computer, and more. After running the same code 50 times, my average result was the following:
对于此测试,我使用的是2.7 GHz四核Intel Core I7处理器。 任何类型的性能测试(尤其是针对SIMD的性能测试)都对环境的变化高度敏感,例如处理器,计算机上运行的其他应用程序等。 在运行相同的代码50次之后,我的平均结果如下:
sse2 csv perf test
Using data size: 1600000000 bytes
Running: 'csv_count_norm' took 3922641 u/s
Running: 'csv_count_simd128' took 702249 u/sMy best result was:
我最好的结果是:
sse2 csv perf test
Using data size: 1600000000 bytes
Running: 'csv_count_norm' took 3810724 u/s
Running: 'csv_count_simd128' took 658831 u/sThat means at best, the SIMD solution processed 2.4 GB of data per second, while the regular solution processed only 0.4 GB of data per second. That’s around a 600% increase in performance. That’s also only using a single core, no additional threads needed.
这意味着,SIMD解决方案最多每秒处理2.4 GB数据,而常规解决方案每秒仅处理0.4 GB数据。 性能大约提高了600% 。 那也只使用一个核心,不需要额外的线程。
In the end, SIMD can be shown to make an incredible improvement in the performance of programs with process and search big data. Using just the processor available to me on my mac, and a more basic set of SIMD instructions, I was able to achieve a six fold increase in performance over a traditionally written C function.
最后,可以证明SIMD在处理和搜索大数据的程序性能方面取得了令人难以置信的改进。 仅使用Mac上可用的处理器以及一组更基本的SIMD指令,我的性能就比传统编写的C函数提高了六倍。
However, it doesn’t end there. There are SIMD instruction sets on other processors which can process 256-bits, or even 512-bits of data at a time. Meaning, in the basic example problem tested here, it might be possible to achieve a 1200% or 2400% increase in performance over the default approach. Using SIMD instruction sets in software truly puts the sky as the limit for maximum performance.
但是,它并没有就此结束。 其他处理器上有SIMD指令集,它们可以一次处理256位甚至512位数据。 意思是,在此处测试的基本示例问题中,与默认方法相比,可能会实现1200%或2400%的性能提升。 在软件中使用SIMD指令集确实使天空成为最大性能的极限。
翻译自: https://medium.com/swlh/searching-gigabytes-of-data-per-second-with-simd-f8ab111a5f9c
c程序中使用simd














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









