





The underlying architecture of the cloud is shared-nothing. A shared-nothing architecture is that one where a single component or node has its own CPU, memory, network, storage unit, etc. In a cloud environment, this is achieved thanks to Linux namespaces. Basically, Linux namespaces are the key features of containers, and containers are essential elements in a cloud environment.
云的基础架构是无共享的 。 无共享架构是指单个组件或节点具有自己的CPU,内存,网络,存储单元等的架构。在云环境中,这要归功于Linux命名空间。 基本上,Linux名称空间是容器的关键功能,而容器是云环境中的基本元素。
Recently, many authors have advised that every node or micro-service should have its own database, maybe because in a shared-nothing architecture every node might have its own storage unit, but storage unit doesn’t necessarily mean database.
最近,许多作者建议每个节点或微服务都应具有自己的数据库,这也许是因为在无共享架构中,每个节点都可能具有自己的存储单元,但是存储单元不一定表示数据库。
If you want to see some benchmarks and how shared-nothing behaves, you should see these articles.
如果您想查看一些基准以及无共享行为的表现,则应参阅这些文章。
还有谁不使用共享内容? (Who else uses shared-nothing?)
Most commonly, technologies which implement shared-nothing architecture are those ones which are able to process large amounts of data with a great throughput. One of these is Ab Initio. Ab Initio is a company founded in 1995, which core product is the Co>Operating System. The underlying architecture of the Co>Op system is shared-nothing, and this is the key feature of Ab Initio to scale so well and to process large amounts of data with awesome throughput. Literally, Ab Initio is able to run a single job 600 times parallel across 600 CPU in a local or distributed environment having an effective CPU usage of ~95%.
最常见的是,实现无共享架构的技术是那些能够以高吞吐量处理大量数据的技术。 其中的一个是Ab Initio。 Ab Initio是一家成立于1995年的公司,其核心产品是Co> Operating System 。 Co> Op系统的底层体系结构是无共享的,这是Ab Initio的关键功能,可以很好地扩展并以惊人的吞吐量处理大量数据。 从字面上看,Ab Initio能够在本地或分布式环境中的600个CPU上并行运行600次600倍的有效CPU利用率。
Other technology which uses shared-nothing architecture is ScyllaDB. ScyllaDB is a NoSQL real time database, and have better performance than Apache Cassandra DB. This database is able to store data at the same rate as Apache Kafka, and there is a connector to send data directly from a Kafka topic to ScyllaDB.
其他不使用共享架构的技术是ScyllaDB 。 ScyllaDB是NoSQL实时数据库,并且比Apache Cassandra DB具有更好的性能 。 该数据库能够以与Apache Kafka相同的速率存储数据,并且有一个连接器可以将数据直接从Kafka主题发送到ScyllaDB。
数据管道 (Data pipeline)
So, the first concept we should know when we are doing cloud computing is “data pipeline”. As the name suggests, a data pipeline is a data flow where data is processed along several jobs, and each job might do different operations over data — data validation, data transformation, data partitioning, data filtering, etc.
因此,我们在进行云计算时应该知道的第一个概念是“数据管道”。 顾名思义,数据流水线是一个数据流,其中数据沿着多个作业进行处理,每个作业可能对数据执行不同的操作-数据验证,数据转换,数据分区,数据过滤等。
Usually, a micro-service will receive a message, process it, and push a response to a different micro-service. In this way, we can create a data pipeline.
通常,微服务会收到一条消息,对其进行处理,然后将响应推送到其他微服务。 这样,我们可以创建一个数据管道。
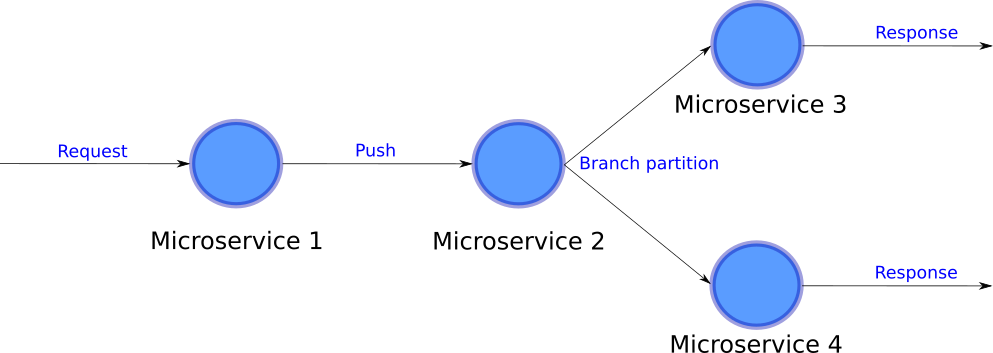
A micro-service system operates more like a network, or as a DAG (Directed Acyclic Graph), so in this article I will refer to a micro-service system as DAG or network. Since a micro-service network behaves as a DAG, it also has some interesting mathematical properties. If you want to dive a little bit more into this feature, you should read this other article:
微服务系统的运行方式更像网络或DAG(有向无环图),因此在本文中,我将微服务系统称为DAG或网络。 由于微服务网络的行为就像DAG,因此它也具有一些有趣的数学特性。 如果您想进一步研究此功能,则应阅读另一篇文章:
There is other scenario, where a component receives a message, and produces a response to the one who sent the request. This is a typical request/response design, and actually, this kind of implementation looks more like an API and less like a micro-service network, because an API operates under a request/response approach.
在其他情况下,组件会收到一条消息,并对发送请求的组件产生响应。 这是典型的请求/响应设计,实际上, 这种实现看起来更像API,而不像微服务网络 ,因为API在请求/响应方法下运行。
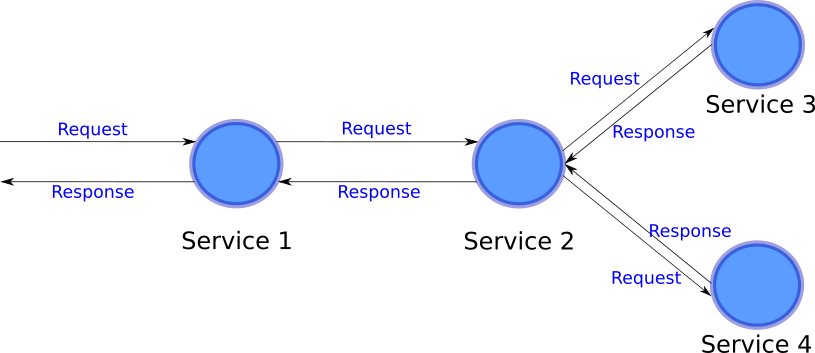
As you can see, under this second scenario you don’t have a pipeline, because essentially, a message goes to a service and a response is handled and returned by the same service which received the request, and you might have nested requests/responses, but this is not a pipeline.
如您所见,在第二种情况下,您没有管道,因为从本质上讲,一条消息进入服务,并且响应由接收请求的同一服务处理并返回,并且您可能嵌套了请求/响应,但这不是管道。
So, what are the implications of having a data pipeline and not having one? I will advance that there are very important performance implications between one approach and another; I will explain this in detail in next sections.
那么,拥有一个数据管道却没有一个管道意味着什么呢? 我将提出一种方法与另一种方法之间非常重要的性能影响; 我将在下一部分中详细解释。
微服务吞吐量 (Micro-service throughput)
Each micro-service has its own throughput, it means that we will have different processing capacity depending on data format, data types and business logic. So, a micro-service with complex data and complex business logic, will also have a lower throughput; but a micro-service with simple data and simple business logic we will expect to see a higher throughput.
每个微服务都有自己的吞吐量,这意味着我们将根据数据格式,数据类型和业务逻辑而具有不同的处理能力。 因此,具有复杂数据和复杂业务逻辑的微服务也将具有较低的吞吐量。 但是具有简单数据和简单业务逻辑的微服务,我们期望看到更高的吞吐量。
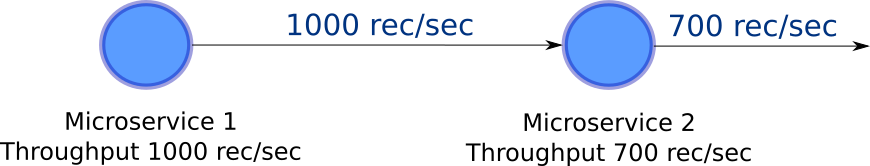
Clearly we have a trouble in this DAG. While one micro-service is sending 1000 records per second, the other one can only process 700 records per second. So, if the system reaches maximum capacity this will be a point of failure.
显然,我们在此DAG中遇到了麻烦。 一个微服务每秒发送1000条记录,而另一种微服务每秒只能处理700条记录。 因此,如果系统达到最大容量,这将是故障点。
平行性 (Parallelism)
There are three types of parallelism in cloud computing: Process parallelism, Component parallelism, Pipeline parallelism. All three forms can occur in the same DAG, and in combination.
云计算中有三种并行性:进程并行性,组件并行性,管道并行性。 所有这三种形式可以在同一DAG中组合使用。
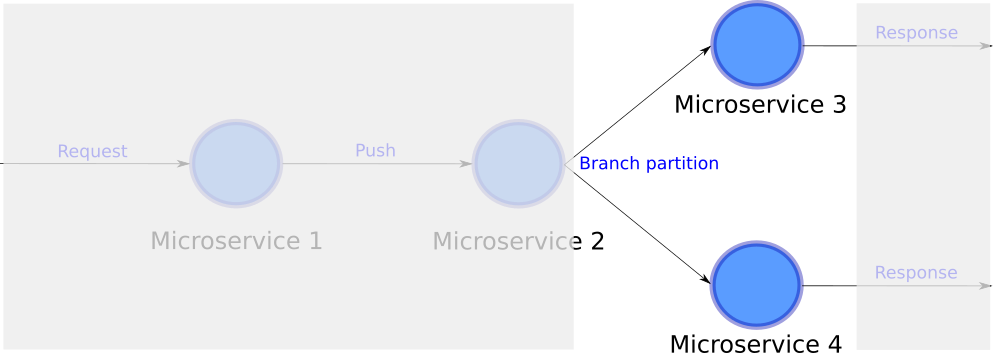
Component parallelism occurs across different branches of a DAG. Here you can see two micro-services running at the same time. Because the branches are independent, each micro-service has also independent CPU assigned. Component parallelism is a de facto feature of expressing your application as a data pipeline.
组件并行发生在DAG的不同分支之间。 在这里,您可以看到两个微服务同时运行。 因为分支是独立的,所以每个微服务也分配有独立的CPU。 组件并行性是将应用程序表示为数据管道的事实特征。
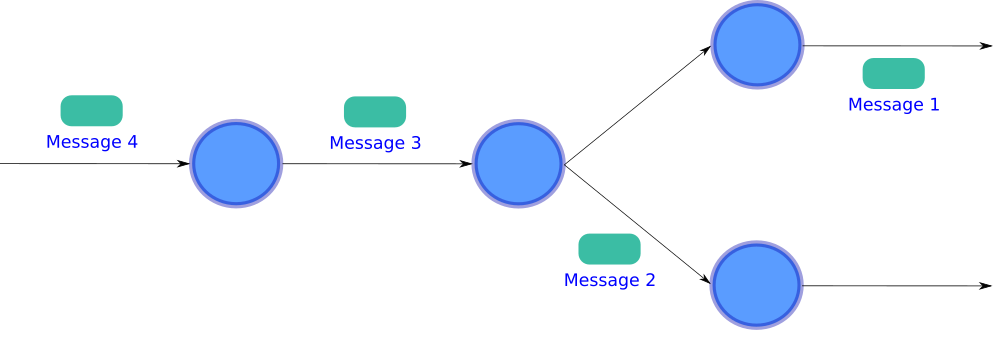
Pipeline parallelism occurs when you use micro-services that can push output messages before consuming all the input messages. The micro-service after a pipelined component can get started almost immediately. For this particular DAG, we can process four different messages at the same time along our pipeline.
当您使用微服务可以在消耗所有输入消息之前推送输出消息时,就会发生管道并行性 。 流水线组件之后的微服务几乎可以立即启动。 对于这个特定的DAG,我们可以沿着管道同时处理四个不同的消息。
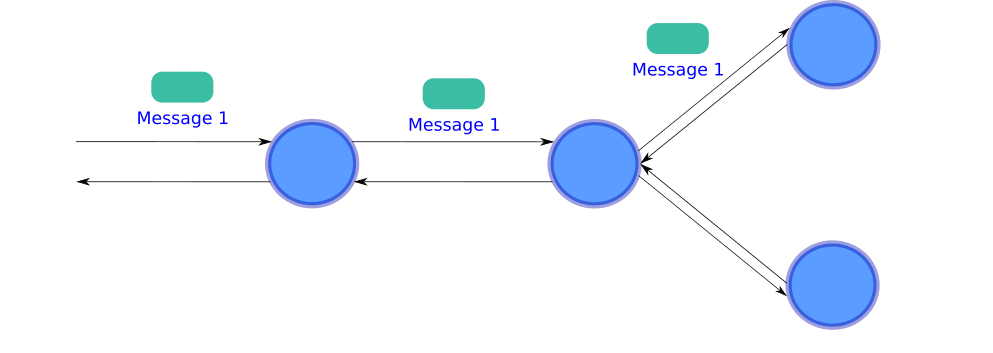
In contrast, when we implement a request response approach, the service will be locked until all nested requests are fulfill for a single message, and while a service is locked you cannot have pipeline parallelism, because your CPU will be idle during the time the service is waiting for a response.
相反,当我们实施请求响应方法时,该服务将被锁定,直到所有嵌套请求都满足一条消息为止;而在锁定服务时,您将无法具有管道并行性,因为在服务期间您的CPU将处于空闲状态正在等待回应。
Process parallelism, also known as Data parallelism, occurs when container orchestratior implements a reactive pattern to scale a micro-service. This means that container orchestratior will reactivelly create replicas of the same micro-service in order to balance message load.
流程并行性 ,也称为数据并行性 ,发生在容器管家实现React式模式以扩展微服务时。 这意味着容器管弦乐队将React性地创建同一微服务的副本,以平衡消息负载。
Process parallelism is also known as Data parallelism because the performance in this scenario depends on how data partitioning strategy is defined.
进程并行性也称为数据并行性,因为这种情况下的性能取决于如何定义数据分区策略。
资料分割 (Data partitioning)
This lead us to the next concept: Data partitioning. To explain this concept, let’s suppose we have two replicas of the same micro-service, and also we have a mechanism to partition data by ID.
这将我们引向下一个概念: 数据分区 。 为了解释这个概念,让我们假设我们有一个相同的微服务的两个副本,并且我们有一个按ID对数据进行分区的机制。
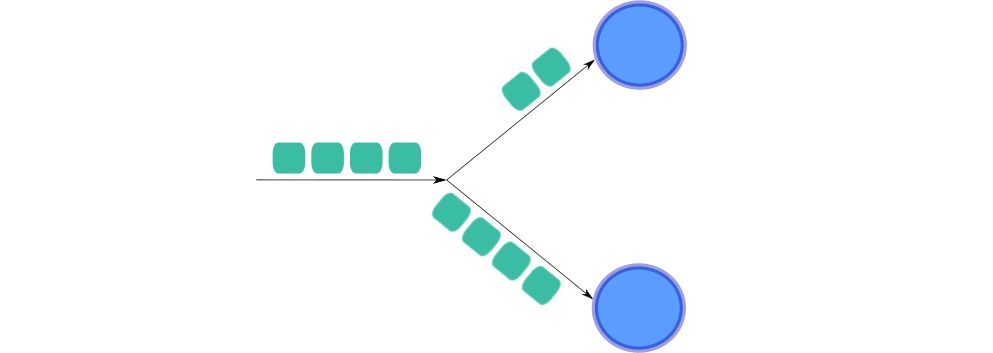
For some reason, our data partitioner is sending less packets to the top micro-service than to the bottom one. This means that data distribution is imbalanced, and for that reason, the top micro-service will use less CPU than the one at the bottom. We also can say, that the first partition has a lower size than second partition, and as we already mentioned, this also means that CPU usage in the first component is less. So, even when we have two instances of the same micro-service, this process is not really two times parallel; as per data distribution the job is maximum 1.5 times parallel.
由于某种原因,我们的数据分区程序向顶部微服务发送的数据包比向底部微服务发送的数据包要少。 这意味着数据分配不平衡,因此,顶部的微服务将比底部的微服务使用更少的CPU。 我们也可以说,第一个分区的大小小于第二个分区的大小,并且正如我们已经提到的,这也意味着第一个组件中的CPU使用率更低。 因此,即使我们有两个相同的微服务实例,该过程实际上也不是两次并行。 根据数据分发,作业最多并行1.5倍。
As you can see, the imbalance of data affects Process parallelism, for this reason, this kind of parallelism is also known as Data parallelism.
如您所见,数据的不平衡会影响流程并行性,因此,这种并行性也称为数据并行性。
In parallel processing, the skew is a measure of the relative imbalance in the sizes of the partitions of a data flow, or in the amounts of CPU time used by a process.
在并行处理中, 时滞是数据流分区大小或进程使用的CPU时间量相对不平衡的度量。
翻译自: https://medium.com/dataseries/cloud-computing-basic-design-concepts-3f47d5f085ec















 535
535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









