





aurora数据库
抽象 (Abstract)
Aurora Database is Amazon’s cloud-native database. It can hold up to 64TB of data and is much faster than MySQL database. Many companies have adopted Aurora Database.
Aurora数据库是Amazon的云原生数据库。 它可以存储多达64TB的数据,并且比MySQL数据库快得多。 许多公司都采用了Aurora数据库。
In this article, we will introduce the architecture of Amazons’ Aurora Database. We will start with the architecture of a traditional relational database system, such as MySQL database and discuss their limitations. We will then discuss how Aurora Database extends the functionalities of a traditional database to improve the availability, reliability and scalability.
在本文中,我们将介绍亚马逊的Aurora数据库的体系结构。 我们将从传统的关系数据库系统(例如MySQL数据库)的体系结构开始,并讨论它们的局限性。 然后,我们将讨论Aurora数据库如何扩展传统数据库的功能以提高可用性,可靠性和可伸缩性。
If you are interested in the architecture of DynamoDB, another featured database from AWS, you can read it from my other blog [Click here].
如果您对DynamoDB(AWS的另一个特色数据库)的体系结构感兴趣,则可以 从我的其他博客中 读取它 [单击此处] 。
传统数据库的体系结构 (Architecture of a traditional database)
A database is a collection of data, typically describing entities and activities of an organization. An e-commerce database, for example, may contain information about the customers, products and sales.
数据库是数据的集合,通常描述组织的实体和活动。 例如,电子商务数据库可能包含有关客户,产品和销售的信息。
A database management system (DBMS) is designed to maintain and utilize those data. Specifically, a DBMS normally provides the following functionalities.
数据库管理系统(DBMS)旨在维护和利用这些数据。 具体而言,DBMS通常提供以下功能。
- A reliable storage of the data. 可靠的数据存储。
- A simple interface to create, update, remove and query the data. 创建,更新,删除和查询数据的简单界面。
- Transaction support. 交易支持。
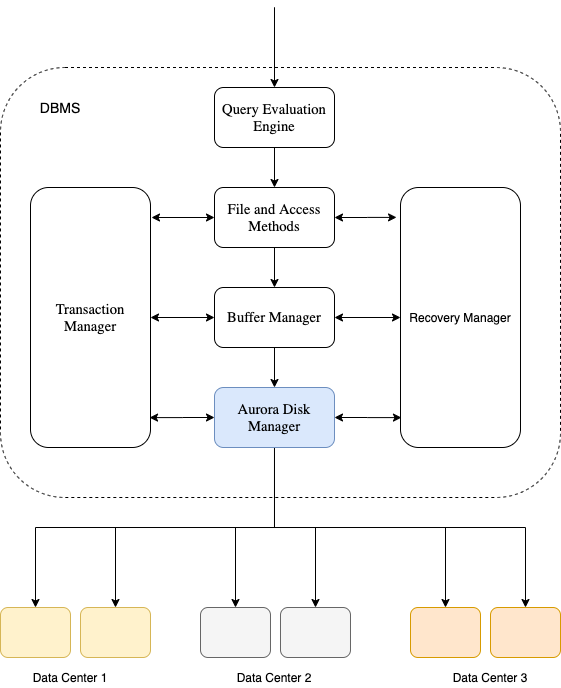
A DBMS normally consists of Query Evaluation Engine, Transaction Manager, File and Access Methods, Buffer Manager and Disk Space Manager, as illustrated in the following figure. We will use two simple examples to illustrate how different components work together.
DBMS通常由查询评估引擎,事务管理器,文件和访问方法,缓冲区管理器和磁盘空间管理器组成,如下图所示。 我们将使用两个简单的示例来说明不同组件如何协同工作。
- Example 1: Write To Database 示例1:写入数据库
Imagine a case that we want to insert two rows into a database table. We would issue the following command to the database:
假设有一种情况,我们想在数据库表中插入两行。 我们将向数据库发出以下命令:
INSERT INTO task(title, priority) VALUES (“DBMS”, 1), (“Aurora”, 2);
插入任务(标题,优先级)值(“ DBMS”,1),(“ Aurora”,2);
The request is first forwarded to the Query Evaluation Engine. Query Evaluation Engine parses the SQL command and understands that the command is to insert two rows into the task table. 3 layers that are below the engine, File and Access Methods, Buffer Manager and Disk Space Manager work together to persist data into the disk.
该请求首先被转发到查询评估引擎。 查询评估引擎分析SQL命令,并了解该命令将在任务表中插入两行。 引擎下面的3层,文件和访问方法,缓冲区管理器和磁盘空间管理器一起工作,以将数据持久存储到磁盘中。
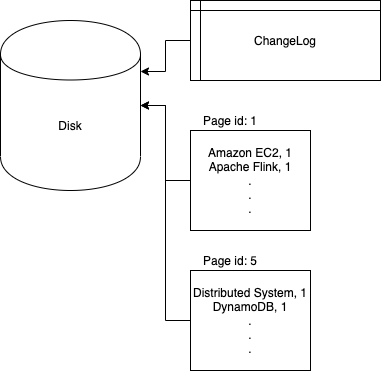
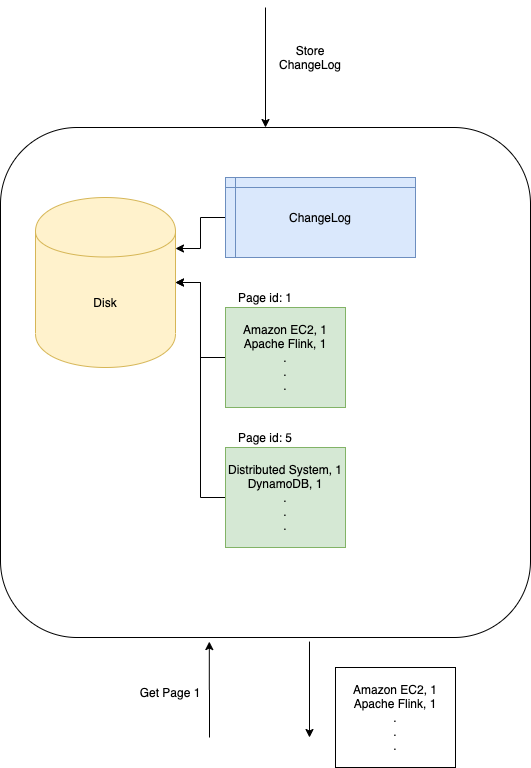
DBMS reads data from or writes data into the disk in fixed size, called a page. A page is normally 4KB or 8KB and is a configurable parameter of a DBMS. Each page is associated with a unique id, page id. The data inside each database table are stored in a few pages. To make search faster, data in different pages are sorted. Page 1 for example contains the rows with keys in the range [a, c]. Page 2 is for keys in the range [d, f]. Beside the pages, a DBMS stores a changelog inside the disk as well. The reason we need a changelog is that some operations need to modify different pages and we can’t flush different pages into the disk atomically. DBMS may crash after the first page is flushed to the disk and leaving the DBMS in an inconsistent state. We therefore first log the change we want to make which can be flushed to the disk atomically. If the DBMS crashes, we can reconstruct the state based on the changelog. See next paragraph for an example.
DBMS以称为页面的固定大小从磁盘读取数据或将数据写入磁盘。 页面通常为4KB或8KB,是DBMS的可配置参数。 每个页面都有一个唯一的ID,即页面ID 。 每个数据库表中的数据存储在几页中。 为了使搜索更快,对不同页面中的数据进行了排序。 例如,第1页包含键范围为[a,c]的行。 第2页用于[d,f]范围内的键。 在页面旁边,DBMS还将更改日志存储在磁盘内。 我们需要更改日志的原因是某些操作需要修改不同的页面,并且我们不能自动将不同的页面刷新到磁盘中。 在将第一页刷新到磁盘并使DBMS处于不一致状态之后,DBMS可能会崩溃。 因此,我们首先记录要进行的更改,该更改可以自动刷新到磁盘。 如果DBMS崩溃,我们可以基于变更日志来重建状态。 有关示例,请参见下一段。
In our example, the DMBS would identify that we need to insert row (“Aurora”, 1) to page 1 and row (“DBMS”, 2) to page 5. Before modifying the data in page 1 and 5, the DBMS first writes an entry to changelog and flushes it to the disk.
在我们的示例中,DMBS将识别出我们需要在第1页上插入行(“ Aurora”,1),并在第5页上插入行(“ DBMS”,2)在第5页。在修改第1和5页中的数据之前,DBMS首先将一个条目写入changelog并将其刷新到磁盘。
Table: task
表:任务
Operation: insertion
操作方式:插入
Data: (“Aurora”, 1), (“DBMS”, 2)
数据:(“ Aurora”,1),(“ DBMS”,2)
If the DBMS crashes after partially updating the database, Recovery Manager would read the changelog and continue to update the database and make sure both rows are inserted.
如果在部分更新数据库后DBMS崩溃,则Recovery Manager将读取更改日志并继续更新数据库,并确保插入了两行。
After the changelog is flushed to the disk, the DBMS inserts (“Aurora”,1) to page 1 and flushes the page to the disk. It then inserts the row (“DBMS”, 2) to page 5 and flushes it to the disk.
将变更日志刷新到磁盘后,DBMS将(“ Aurora”,1)插入页面1并将页面刷新到磁盘。 然后,将行(“ DBMS”,2)插入第5页,并将其刷新到磁盘。
Now the write operation has completed successfully and the DBMS can return to the client application.
现在,写入操作已成功完成,并且DBMS可以返回到客户端应用程序。
- Example 2: Query Database 示例2:查询数据库
The steps to query database is similar. Consider the following command
查询数据库的步骤相似。 考虑以下命令
SELECT * FROM tasks WHERE title=”Apache Flink”;
SELECT * FROM task where WHERE title =“ Apache Flink”;
The Query Execution Engine first parses the command. The DBMS would then identify which page might contain the data. In our case, page 1 could possibly have the data we want. Disk Space Manager then reads that page into memory if it is not present in the buffer. The DBMS then searches through the page for the data and returns the result to the client application.
查询执行引擎首先解析命令。 然后,DBMS将确定哪个页面可能包含数据。 在我们的例子中,第1页可能有我们想要的数据。 然后,如果缓冲区中不存在该页面,则磁盘空间管理器会将其读入内存。 然后,DBMS在页面中搜索数据,并将结果返回到客户端应用程序。
传统DBMS的局限性 (Limitations of traditional DBMS)
Traditional DBMS has worked well for decades and is a critical component of almost all the software applications. However with the emergence of the Cloud and higher requirement on scalability, reliability and availability, traditional DBMS gradually fails to keep up with the expectations.
传统的DBMS已经运行了数十年,并且是几乎所有软件应用程序的关键组件。 但是,随着云的出现以及对可伸缩性,可靠性和可用性的更高要求,传统的DBMS逐渐无法满足期望。
- Scalability 可扩展性
A traditional DBMS runs only on a single machine. We can only scale it by using more powerful computers. This approach is expensive and not so scalable. The number of IO operations per second (IOPS) a disk supports can quickly become the bottleneck of the system.
传统的DBMS仅在单台计算机上运行。 我们只能通过使用功能更强大的计算机来扩展它。 这种方法很昂贵,而且扩展性不强。 磁盘支持的每秒IO操作数(IOPS)可能很快成为系统的瓶颈。
- Reliability 可靠性
Though the traditional DBMS employs techniques such as changelogs to make it more reliable, it is not so reliable. If the disk corrupts, the DBMS may lose all the data.
尽管传统的DBMS使用诸如changelogs之类的技术来使其更可靠,但它并不是那么可靠。 如果磁盘损坏,则DBMS可能会丢失所有数据。
- Availability 可用性
The traditional DBMS is not very available as well. If the machine crashes, the DBMS won’t be able to serve user requests until the machine is fixed and all the DBMS recovery completes.
传统的DBMS也不太可用。 如果计算机崩溃,则在修复计算机并完成所有DBMS恢复之前,DBMS将无法满足用户请求。
Aurora如何改进传统数据库 (How Aurora improves a traditional database)
Aurora Database is built on top of the traditional DBMS. It reuses the majority of components inside the traditional DBMS, such Query Execution Engine, Transaction Manager and Recovery Manager. (And that’s why we spend some time on the architecture on traditional DBMS in the previous section.) It, however, makes several improvements to the traditional DBMS to improve its availability, reliability and scalability. Those changes are
Aurora数据库是建立在传统DBMS之上的。 它重用了传统DBMS内部的大多数组件,例如查询执行引擎,事务管理器和恢复管理器。 (这就是为什么我们在上一节中花了一些时间在传统DBMS的体系结构上的原因。)但是,它对传统DBMS进行了一些改进,以提高其可用性,可靠性和可伸缩性。 这些变化是
- Replicating the data to remote storage 将数据复制到远程存储
- Storing only changelog to the remote disk 仅将更改日志存储到远程磁盘
- Employing a primary-replica setup 使用主副本设置
复写 (Replication)
The first thing Aurora did is to store the data remotely instead of on the local disk. As shown in the figure below, Aurora Database extends the Disk Manager to make it compatible with remote storages.
Aurora所做的第一件事是将数据远程存储,而不是存储在本地磁盘上。 如下图所示,Aurora数据库扩展了磁盘管理器以使其与远程存储兼容。
To improve reliability, Aurora Database replicates the data. It normally replicates the data 6 times in 3 different data centers. It is very unlikely that user data is lost with this number of replications.
为了提高可靠性,Aurora数据库复制了数据。 它通常在3个不同的数据中心中将数据复制6次。 通过这种复制次数,用户数据丢失的可能性很小。
Aurora Database uses 1 virtual machine (Amazon EC2) to manage 1 copy of data. The data is stored in the local disk of the EC2 instance. In our case, Aurora Database uses 6 EC2s in 3 different data centers to manage the replicated data.
Aurora数据库使用1个虚拟机(Amazon EC2)管理1个数据副本。 数据存储在EC2实例的本地磁盘中。 在我们的案例中,Aurora数据库在3个不同的数据中心中使用6个EC2来管理复制的数据。
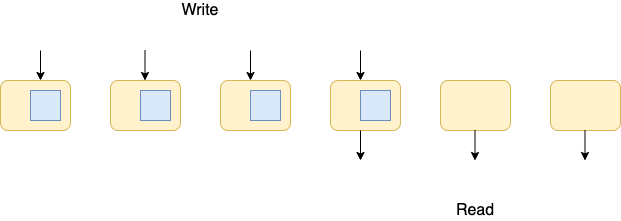
However one possible issue with this setup is that the disk manager needs to make sure data is successfully sent to 6 different EC2s. The latency can increase if any of the EC2 is slow or busy handling other requests. With 6 instances, it is more likely that one of the instance is slow and therefore the latency is more likely to increase. To deal with this, Aurora database only requires receiving responses from a subset of EC2s before it returns to the user application. We denote this as Vw number of EC2s. Same for the read operations, Aurora database only fetches data from a subset of EC2s, Vr. As long as Vw + Vr > total number of replications, we can guarantee that read operations will see the results of the previous write operations. As shown in the figure below, it is guaranteed that there is at least one machine that has seen the write and serves the read. Vw =4; Vr = 3. This is the quorum-based replication mechanism used in Aurora Database, interested users can refer to this paper for more information. [Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases. In SIGMOD 2017]
但是,此设置的一个可能问题是磁盘管理器需要确保将数据成功发送到6个不同的EC2。 如果任何EC2缓慢或忙于处理其他请求,则延迟可能会增加。 对于6个实例,实例之一很可能很慢,因此延迟很可能增加。 为了解决这个问题,Aurora数据库仅需要在返回用户应用程序之前从一部分EC2接收响应。 我们将其表示为EC2的Vw数量。 与读取操作相同,Aurora数据库仅从一部分EC2 Vr中获取数据。 只要Vw + Vr>复制总数,我们就可以保证读取操作将看到先前写入操作的结果。 如下图所示,可以确保至少有一台机器已看到写入并为读取提供服务。 Vw = 4; Vr =3。这是Aurora数据库中使用的基于仲裁的复制机制,有兴趣的用户可以参考本文以获取更多信息。 [ Amazon Aurora:高吞吐量云原生关系数据库的设计注意事项 。 在SIGMOD 2017中]
To make the system more efficient, Aurora Database only reads data from 1 replica since it knows which replica has the data. These are the EC2 instances from which it has received the response.
为了使系统更高效,Aurora数据库仅从1个副本中读取数据,因为它知道哪个副本具有该数据。 这些是其已收到响应的EC2实例。
- Changelog as the data 将变更日志作为数据
Aurora Database takes one more step to make the system even more efficient. It only stores the changelog to the remote storage. In our write example, Aurora Database only saves the changelog to 6 EC2 instances. As shown in the figure below, when EC2 instance receives a request to persist a changelog, it first saves it to the changelog in the disk. Then it applies the changelog to the pages. This can greatly save network bandwidth.
Aurora数据库又迈出了一步,以使系统更加高效。 它仅将更改日志存储到远程存储。 在我们的写入示例中,Aurora数据库仅将更改日志保存到6个EC2实例。 如下图所示,当EC2实例收到持久化更改日志的请求时,它将首先将其保存到磁盘中的更改日志中。 然后将更改日志应用于页面。 这样可以大大节省网络带宽。
For the read operations, it behaves the same as the traditional DBMS. If the page is not available in the buffer, disk manager sends a request to the EC2 and the EC2 returns the page to the disk manager.
对于读取操作,它的行为与传统DBMS相同。 如果该页面在缓冲区中不可用,则磁盘管理器将请求发送到EC2,然后EC2将页面返回给磁盘管理器。
- Primary-replica configuration 主副本配置
So far, Aurora Database has made the data more reliable. However the performance of the database is still limited by a single machine.
到目前为止,Aurora数据库已经使数据更加可靠。 但是,数据库的性能仍然受一台计算机的限制。
To make the system more scalable, Aurora database supports a primary-replica configuration, as shown in the figure below. [The figure below is from Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases. In SIGMOD 2017]
为了使系统更具可伸缩性,Aurora数据库支持主副本配置,如下图所示。 [下图来自Amazon Aurora:高吞吐量云原生关系数据库的设计注意事项 。 在SIGMOD 2017中]
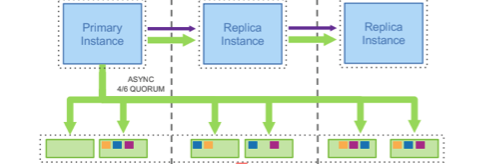
The primary instance can serve both the read and write requests. The changelog is sent to all 6 EC2 instances in 3 different data centers.
主实例可以满足读取和写入请求。 变更日志将发送到3个不同数据中心中的所有6个EC2实例。
Replica instance serves only read requests. When there is an update to a page, the primary instance sends a notification to replica instance, informing it that page is stale. If that page is inside replica instance’s buffer, it will evict the page from the buffer. When replica instance receives a read request, it will send a request to the EC2 instance to fetch the page if that page is not present in the buffer.
副本实例仅服务于读取请求。 当页面有更新时,主实例会向副本实例发送通知,以通知该页面已过时。 如果该页面在副本实例的缓冲区内,它将从缓冲区中逐出该页面。 当副本实例收到读取请求时,如果该页面不存在于缓冲区中,它将向EC2实例发送请求以获取该页面。
With remote storage, Aurora Database supports multiple instances running in parallel without the need of much coordination between them. With primary-replica setup, Aurora database is able to support a higher throughput than the traditional DBMS.
通过远程存储,Aurora数据库支持并行运行的多个实例,而无需它们之间的大量协调。 通过主副本设置,Aurora数据库能够支持比传统DBMS更高的吞吐量。
翻译自: https://medium.com/swlh/aurora-database-explained-ece9db93f6b8
aurora数据库















 1421
1421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









