





deep dive

Deep Dive into Azure Cosmos PartitionKey and Partitions
深入了解Azure Cosmos PartitionKey和分区
How to Effectively Model Azure Cosmos
如何有效地建模Azure Cosmos
Do you want to build an application with these features?
您要构建具有这些功能的应用程序吗?
- Highly scalable (read and write throughput) 高度可扩展(读写吞吐量)
- Maintainable data consistency 可维护的数据一致性
- Consistent business continuity during regional outages/disaster recovery 在区域中断/灾难恢复期间保持业务连续性
Then Cosmos DB is a perfect fit for your application. But you need a deep-dive understanding of how Cosmos works so you can model your application accordingly, and then you can achieve the desired throughput.
然后,Cosmos DB非常适合您的应用程序。 但是您需要深入了解Cosmos的工作原理,以便可以对应用程序进行相应的建模,然后才能实现所需的吞吐量。
Partition Key Pre-requisites
分区键先决条件
A partition key is a unique dataset that has high cardinality, or a wide range of values possible values.
分区键是唯一的数据集,具有高基数或宽范围的值(可能的值)。
It is important to choose the right partition key during design. Once you select the partition key and ingest the data, it is not possible to change it unless you move data to a new container with a changed partition key. Typically for a heavy, read-intensive applications you can choose partition key based on the majority of the read calls pattern/filter.
在设计过程中选择正确的分区键很重要。 选择分区键并提取数据后,将无法更改它,除非您使用更改的分区键将数据移动到新容器中。 通常,对于繁重的读取密集型应用程序,您可以根据大多数读取调用模式/过滤器选择分区键。
For example, let’s say you’re building an application to host an organization’s user base. For that, you can use userId as the partition key. All the documents or data related to a user will be mapped to the userId partition key.
例如,假设您正在构建一个应用程序来托管组织的用户群。 为此,您可以使用userId作为分区键。 与用户有关的所有文档或数据都将映射到userId分区键。
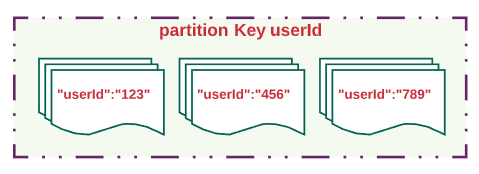
What is a Synthetic Partition Key
什么是合成分区密钥
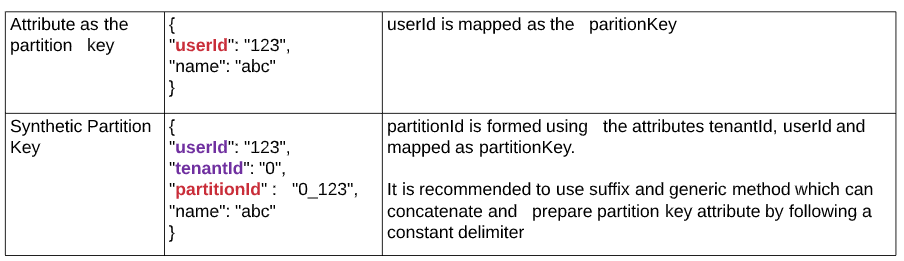
Typically, a partition key can be a JSON (Java Script Object Notation) attribute within your document used to distribute you data across multiple partitions. However, scenarios may happen where you will need to model the partition key using two or more attributes in your document. This is called a Synthetic Partition key.
通常,分区键可以是文档中的JSON(Java脚本对象表示法)属性,用于在多个分区之间分配数据。 但是,在某些情况下,可能需要使用文档中的两个或多个属性来对分区键进行建模。 这称为合成分区密钥 。
For example, if you’re modelling multi tenant application, it is recommended to use tenant-Id as part of the partition key and use a synthetic partition key. You can also have alternative usecases where two or more attributes derive the unique data.
例如,如果要为多租户应用程序建模,建议使用tenant-Id作为分区键的一部分,并使用合成分区键。 您还可以使用两个或多个属性派生唯一数据的替代用例。
Cosmos DB Partition
Cosmos DB分区
Now that we have a detailed understanding of the partition key and various scenarios to model, let’s have a deep dive on how Cosmos does partitioning.
既然我们对分区键和要建模的各种场景有了详细的了解,让我们深入了解Cosmos如何进行分区。
Cosmos scales each individual container by storing data into partitions, and this approach lets you scale and perform your throughput. There are two types of Cosmos Partition
Cosmos通过将数据存储到分区来扩展每个单独的容器,这种方法使您可以扩展和执行吞吐量。 Cosmos分区有两种类型
- Logical Partition 逻辑分区
- Physical Partition 物理分区
The following covers the significance and usage of each of these partitions.
下面介绍了每个分区的重要性和用法。
Logical Partition
逻辑分区
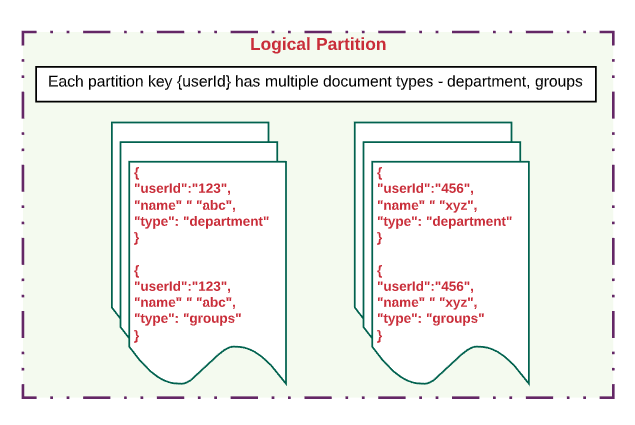
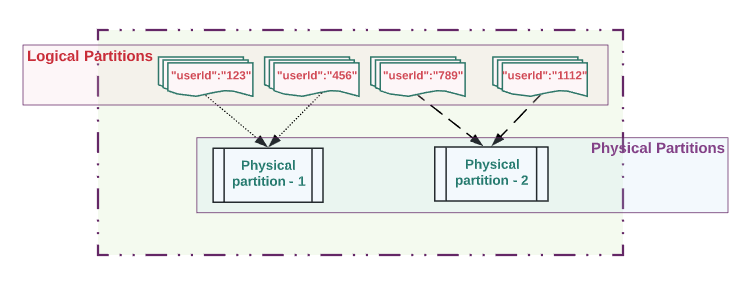
A Logical Partition contains a set of documents that belongs to same partition key. A logical partition can have a 20GB limit. Be sure to model your partition key so that you can manage all related documents using the same partition key. In the use case above (we used userId as the partitionKey), multiple documents related a single user can be grouped in a logical partition.
逻辑分区包含一组属于同一分区键的文档。 逻辑分区可以有20GB的限制 。 确保对分区键建模,以便您可以使用相同的分区键来管理所有相关文档。 在上面的用例中(我们使用userId作为partitionKey),可以将与单个用户相关的多个文档分组到一个逻辑分区中。
Physical Partition
物理分区
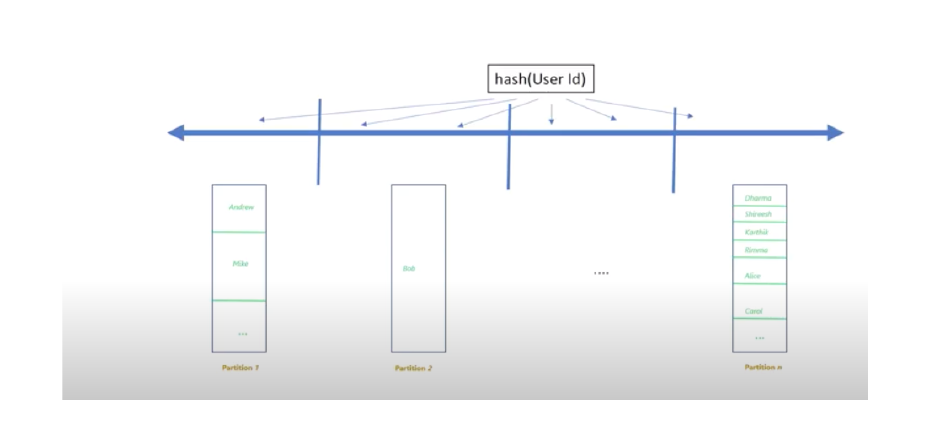
A Physical Partition is the actual storage of the document. To start, your container may have one physical partition created. Each partition can store up to 50GB of data and can provide throughput up to 10,000 request units per second (RU/s). One or more logical partitions map to one physical partition. Cosmos automatically creates a new physical partition as your data size grows beyond 50GB. The partition key’s values is hashed so that it can go to a particular physical partition. Splits to the existing physical partition may happen so that system can hash partition keys across all available physical partitions. Data belonging to the single logical partition will be mapped/stored on to new/same physical partition. Adding a new physical partition should not have an impact on your application’s availability.
物理分区是文档的实际存储。 首先,您的容器可能创建了一个物理分区。 每个分区最多可以存储50GB的数据,并且可以提供每秒 10,000个 请求单位 ( RU / s)的吞吐量。 一个或多个逻辑分区映射到一个物理分区。 当您的数据大小超过50GB时,Cosmos会自动创建一个新的物理分区。 分区键的值被散列,以便可以转到特定的物理分区。 可能会拆分为现有物理分区,以便系统可以在所有可用物理分区上哈希分区键。 属于单个逻辑分区的数据将被映射/存储到新的/相同的物理分区上。 添加新的物理分区应该不会影响应用程序的可用性。
Throughput considerations
吞吐量注意事项
Cosmos scales the container throughput across the physical partitions. A request unit (RU) is the measure of the throughput. You can provision RUs (required by your expected throughput) either at the database or container level. Provisioned RUs equally divide among physical partitions
Cosmos扩展了跨物理分区的容器吞吐量。 请求单位(RU)是吞吐量的度量。 您可以在数据库或容器级别上设置RU(由您的预期吞吐量要求)。 设置的RU在物理分区之间平均分配
How Database Throughput Provision Works
数据库吞吐量提供如何工作
Throughput provisioned at the database shares across all of the containers created in the database. Think of it as a pool shared across all containers. Cosmos limits usage to 25 containers when you provision a database throughput. The minimum throughput required for a shared database is 1,000 RUs.
数据库中配置的吞吐量在数据库中创建的所有容器之间共享。 可以将其视为所有容器之间共享的池。 当您配置数据库吞吐量时,Cosmos会将使用限制为25个容器 。 共享数据库所需的最小吞吐量为1,000 RUs 。
Once the database creates x number of physical partitions (based on the provisioned RUs) and containers are created, the system shares and allocates every container across x number of physical partitions at the database level.
一旦数据库创建了x个物理分区(基于预配置的RU)并创建了容器,系统就会在数据库级别跨x个物理分区共享和分配每个容器。
For example., let’s say there are three physical partitions and five containers. All five containers will share these three partitions. Now, let’s say two containers end up growing and require more throughput. In that case, the system creates a new set of three physical partitions, and only these two containers will have additional partitions allocated. Now each container will be mapped to different physical partitions created at the database level. So, if one container needs full throughput, then it can use the provisioned RUs completely, and the other container may end up having rate limit/throttling.
例如,假设有三个物理分区和五个容器。 所有五个容器将共享这三个分区。 现在,假设两个容器最终增长并且需要更多的吞吐量。 在这种情况下,系统将创建一组新的三个物理分区,并且只有这两个容器将分配其他分区。 现在,每个容器都将映射到在数据库级别创建的不同物理分区。 因此,如果一个容器需要完整的吞吐量,则它可以完全使用预配置的RU,而另一个容器可能最终会受到速率限制/限制。

How Container Throughput Provision Works
集装箱吞吐量的提供方式
Throughput provisioned at the container level is dedicated or exclusively reserved for that container. This means you will always receive and be charged for the provisioned throughput if you’ve used it or not. The minimum throughput required for a container is 400 RUs. It’s important to use or have fewer RUs set and increase it only when you need to scale your throughput.
在容器级别提供的吞吐量专用于或专用于该容器。 这意味着,无论您是否使用过,都会始终收到预配的吞吐量并向其收费。 容器所需的最小吞吐量为400 RUs。 仅在需要扩展吞吐量时使用或设置较少的RU并增加它是很重要的。
The container-provisioned throughput always distributes across the physical partitions. Let’s say you have five physical partitions and a setup throughput at around 10,000 ; in this case, each physical partition will get 2,500 RUs allocated. If you see more calls related to partition key data mapped to one partition, then you can expect rate limiting (if 2,500 RUs are consumed) even though you have enough RUs (10,000) allocated at container.
容器提供的吞吐量始终分布在物理分区之间。 假设您有五个物理分区,设置吞吐量约为10,000; 在这种情况下,每个物理分区将分配2500个RU。 如果看到与映射到一个分区的分区键数据有关的更多调用,那么即使在容器中分配了足够的RU(10,000),也可以预期速率限制(如果消耗了2500 RU)。
Note: Once you have a provisioned throughput, you cannot move between a shared database to a dedicated container throughput and vice versa. The only way to do that is to create a new container/database and move your data.
注意:一旦具有预配置的吞吐量,就不能在共享数据库和专用容器的吞吐量之间移动,反之亦然。 唯一的方法是创建一个新的容器/数据库并移动数据。
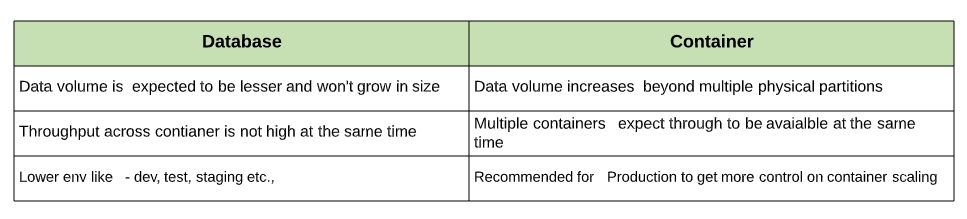
Considerations when Choosing between Database versus Container Throughput
在数据库吞吐量与容器吞吐量之间进行选择时的注意事项
翻译自: https://medium.com/walmartglobaltech/deep-dive-azure-cosmos-partitions-and-partitionkey-14e898f371cd
deep dive















 1472
1472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









