





pandas 机器学习
Pandas is one of the tools in Machine Learning which is used for data cleaning and analysis. It has features which are used for exploring, cleaning, transforming and visualizing from data.
Pandas是机器学习中用于数据清理和分析的工具之一。 它具有用于根据数据进行探索,清理,转换和可视化的功能。

Now let us understand and learn more about Pandas-
现在,让我们了解并了解有关Pandas的更多信息-
1.Introduction to Pandas
1,熊猫简介
Pandas is an open-source python package built on top of Numpy developed by Wes McKinney. It is used as one of the most important data cleaning and analysis tool. It provides fast, flexible, and expressive data structures.
Pandas是一个由Wes McKinney开发的基于Numpy的开源python软件包。 它被用作最重要的数据清理和分析工具之一。 它提供了快速,灵活和富有表现力的数据结构。
Pandas is derived from the term “Panel-data-s” an econometrics term for data sets include observations over multiple time periods for the same individuals. -source Wikipedia
大熊猫从术语“ 泛 EL- DA TA- 的 ”计量经济学术语用于数据集包括在用于同一个体多个时间段的观察而得。 源维基百科
2. How to install Pandas?
2.如何安装熊猫?
You can install Pandas by using the following commands:
您可以使用以下命令安装Pandas:
# to install pandas in terminal or command line use one of the commands
pip install pandas
# or
conda install pandas
# To install pandas in jupyter notebook use this command
!pip install pandas3. How to import Pandas?
3.如何进口大熊猫?
import pandas as pdBy using the above command you can easily import pandas library.
通过使用以上命令,您可以轻松导入pandas库。
4.Pandas Data Structures
4,熊猫数据结构
Pandas deals with three types of data structures :
熊猫处理三种类型的数据结构:
- Series 系列
- DataFrame 数据框
- Panel 面板
a)Series is a one-dimensional array-like structure with homogeneous data. The size of the series is immutable(cannot be changed) but its values are mutable.
a)系列是具有同类数据的一维数组状结构。 系列的大小是不可变的(无法更改),但是其值是可变的。

b) DataFrame is a two-dimensional array-like structure with heterogeneous data. Data is aligned in a tabular manner(Rows &Columns form). The size and values of DataFrame are mutable.
b)DataFrame是具有异类数据的二维数组状结构。 数据以表格形式对齐(行和列形式)。 DataFrame的大小和值是可变的。

c) The panel is a three-dimensional data structure with heterogeneous data. It is hard to represent the panel in graphical representation. But it can be illustrated as a container of DataFrame. The size and values of a Panel are mutable.
c)面板是具有异构数据的三维数据结构。 很难用图形表示面板。 但这可以说明为DataFrame的容器。 面板的大小和值是可变的。
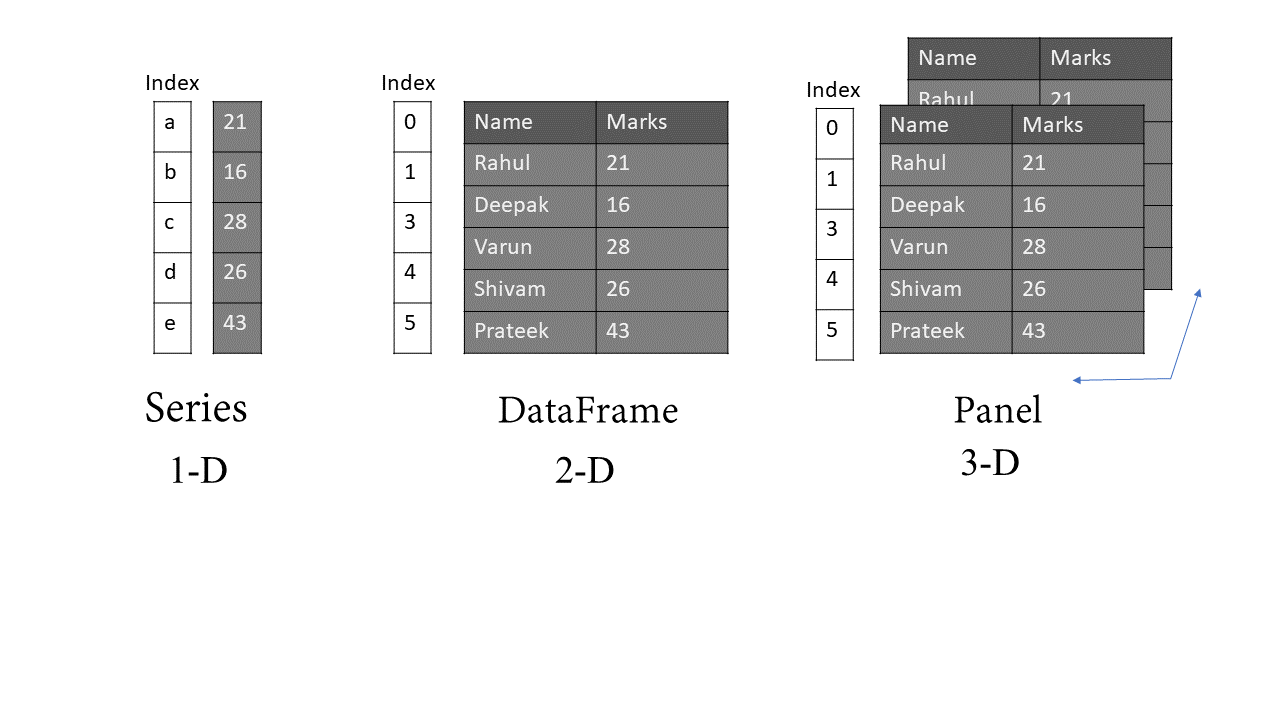
Note: Series and DataFrame are the most widely used data structure in pandas. Therefore, I will only discuss these two data structures later.
注意:Series和DataFrame是熊猫中使用最广泛的数据结构。 因此,我将仅在稍后讨论这两个数据结构。
5.Creating Series and Data Frames
5,创建系列和数据框
Series :
系列:
pandas.Series(data=None , index=None , dtype=None,copy = false)
pandas.Series(数据=无,索引=无,dtype =无,复制=假)
parameters:
参数:
data: data takes various forms like ndarray, list, constants
数据:数据采用各种形式,例如ndarray,list,常量
index: index values must be unique and hashable, the same length as data. Default np.arrange(n) if no index is passed.
index:索引值必须是唯一且可哈希的,且长度与数据相同。 如果未传递索引,则默认为np.arrange(n)。
dtype: dtype is for data type. If None, the data type will be inferred
dtype:dtype用于数据类型。 如果为None,则将推断数据类型
copy: Copy input data. default false
复制:复制输入数据。 默认为假
a)Creating Series from ndarray
a)从ndarray创建系列
#import the pandas library and aliasing as pdimport pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
example_1 = pd.Series(data,index=[0,1,2,3)
print example_1
out[1]: 0 a
1 b
2 c
3 db)Creating Series from Dictionary
b)从字典创建系列
import pandas as pd
import numpy as np
data = {'a' : 0., 'b' : 1., 'c' : 2.}
s = pd.Series(data)
print s
out:
a 0.0
b 1.0
c 2.0
dtype: float64Note:Dictionary keys are used to construct index here.c)Creating Series from scalar
c)从标量创建系列
import pandas as pd
import numpy as np
s = pd.Series(5, index=[0, 1, 2, 3])
print s
out:
0 5
1 5
2 5
3 5
dtype: int64Dataframe:
数据框:
pandas.DataFrame(data=None , index=None , dtype=None,copy = false)
pandas.DataFrame(data = None,index = None,dtype = None,copy = false)
parameters:
参数:
data: data takes various forms like ndarray, list, constants
数据:数据采用各种形式,例如ndarray,列表,常量
index-: index values must be unique and hashable, the same length as data. Default np.arrange(n) if no index is passed.
index-:索引值必须是唯一的且可哈希的,与数据的长度相同。 如果未传递索引,则默认为np.arrange(n) 。
dtype: dtype is for data type. If None, the data type will be inferred
dtype:dtype用于数据类型。 如果为None,则将推断数据类型
copy: Copy input data. default false
复制:复制输入数据。 默认为假
a)Creating DataFrame from List
a)从列表创建DataFrame
Example-1:import pandas as pd
data = [1,2,3,4,5]
df = pd.DataFrame(data)
print df
out:
0
0 1
1 2
2 3
3 4
4 5Example-2-
import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'],dtype=float)
print df
out:
Name Age
0 Alex 10.0
1 Bob 12.0
2 Clarke 13.0Note: the dtype parameter changes the type of Age column to floating point.b)Create a DataFrame from Dict of ndarrays / Lists
b)从ndarrays / Lists的Dict创建一个DataFrame
All the ndarrays must be of the same length. If the index is passed, then the length of the index should equal to the length of the arrays.
所有ndarray的长度必须相同。 如果传递了索引,则索引的长度应等于数组的长度。
If no index is passed, then by default, the index will be range(n), where n is the array length.
如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
Example-1
import pandas as pd
data ={'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age',[28,34,29,42]}
df = pd.DataFrame(data)
print df
out:
Age Name
0 28 Tom
1 34 Jack
2 29 Steve
3 42 RickyNote: Here,0,1,2,3 are the default index assinged each using the function range(n).Example-2
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data, index=['rank1','rank2','rank3','rank4'])
print df
out:
Age Name
rank1 28 Tom
rank2 34 Jack
rank3 29 Steve
rank4 42 Ricky6.Pandas: How to read and write files?
6.Pandas:如何读写文件?
Pandas can read and write any types of files such as Excel, CSV and many other files, it is one of its crucial features. Methods like df.read_*() and df.to_*() helps you to work with all types of files effectively.
熊猫可以读写任何类型的文件,例如Excel,CSV和许多其他文件,这是其重要功能之一。 诸如df.read _ *()和df.to _ *()之类的方法可帮助您有效地处理所有类型的文件。
I will use Iris-dataset for the explanation.
我将使用虹膜数据集进行解释。
a)Reading .csv file
a)读取.csv文件
In [1]:import pandas as pd
In [2]:data = pd.read_csv("Iris_dataset.csv")
In [3]:data.head()
out[3]:
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
1 5.1 3.5 1.4 0.2 Iris-setosa
2 4.9 3.0 1.4 0.2 Iris-setosa
3 4.7 3.2 1.3 0.2 Iris-setosa
4 4.6 3.1 1.5 0.2 Iris-setosa
5 5.0 3.6 1.4 0.2 Iris-setosab)Writing file in .xlsx format
b)以.xlsx格式写入文件
In [4]:import pandas as pd
In [5]:data= pd.read_csv("Iris_dataset.csv")
In [6]:type(data)
out[6]:pandas.core.frame.DataFrame
In [7]:data_csv = data.to_excel('iris_data.xlsx')Similarly, you can read and write other files also.
同样,您也可以读取和写入其他文件。

7. DataFrame columns and rows(.shape) & Number of dimensions.
7. DataFrame的列和行(.shape)&维数。
a)df.shape function in pandas returns the output as (m,n) where m is a number of rows and n is the number of columns in the data frame.
a) pandas中的df.shape函数以(m,n)返回输出,其中m是数据帧中的行数,n是数据帧中的列数。
b)df.ndim return an int representing the number of axes/array dimensions. It will return 1 for Series and 2 for DataFrame.
b) df.ndim返回一个表示轴/数组维数的整数。 对于Series,它将返回1,对于DataFrame,它将返回2。
In [8]:data.shape
out[8]:(150,6)
In [9]:data.ndim
out[9]: 28. Preview DataFrame with .head()& .tail()
8.使用.head()和.tail()预览DataFrame
a)df.head(n=no. of rows to be returned) returns the first n rows from the DataFrame.
a) df.head(n =要返回的行数)返回DataFrame的前n行。
b)df.tail(n=no. of rows to be returned) returns the last n rows from the DataFrame.
b) df.tail(n =要返回的行数)返回DataFrame的最后n行。
#df.head()
In [3]:data.head(4)
out[3]:
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
1 5.1 3.5 1.4 0.2 Iris-setosa
2 4.9 3.0 1.4 0.2 Iris-setosa
3 4.7 3.2 1.3 0.2 Iris-setosa
4 4.6 3.1 1.5 0.2 Iris-setosa
Note:in head(n) you can cange value of n which shows n no. of rows in output#df.tail()
In [4]:data.tail()
out[4]:
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
146 6.7 3.0 5.2 2.3 Iris_virginica
147 6.3 2.5 5.0 1.9 Iris-virginica
148 6.5 3.0 5.2 2.0 Iris-virginica
149 6.2 3.4 5.4 2.3 Iris-virginica
150 5.9 3.0 5.1 1.8 Iris-virginica9.High-level statistics with pandas
9,大熊猫统计
a)Pandas DataFrame.describe()
a)熊猫DataFrame.describe()
The describe() method is used for calculating some statistical data like percentile, mean and std of the numerical values of the Series or DataFrame. It analyzes both numeric and object series and also the DataFrame column sets of mixed data types.
describe()方法用于计算一些统计数据,例如Series或DataFrame的数值的百分位数,均值和标准差。 它分析数字和对象系列以及混合数据类型的DataFrame列集。
In [5]data.describe()
out[5]:
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 150.000000 150.000000 150.000000 150.000000 150.000000
mean 75.500000 5.843333 3.054000 3.758667 1.198667
std 43.445368 0.828066 0.433594 1.764420 0.763161
min 1.000000 4.300000 2.000000 1.000000 0.100000
25% 38.250000 5.100000 2.800000 1.600000 0.300000
50% 75.500000 5.800000 3.000000 4.350000 1.300000
75% 112.750000 6.400000 3.300000 5.100000 1.800000
max 150.000000 7.900000 4.400000 6.900000 2.500000#for one column
In [8]:data['SepalLengthCm'].describe()
out[8]:
count 150.000000
mean 5.843333
std 0.828066
min 4.300000
25% 5.100000
50% 5.800000
75% 6.400000
max 7.900000
Name: SepalLengthCm, dtype: float6410. .dtypes and .astype() functions in Pandas
10. Pandas中的.dtypes和.astype()函数
To check the data types of columns of the data frame .dtypes function is used. Series have only one type of data types but in a data frame, there can be mixed data types.
检查数据框列的数据类型.dtypes函数 用来。 系列只有一种类型的数据类型,但是在一个数据帧中,可以有多种数据类型。
#for iris_dataset
In [1]:data.dtypes
out[1]:Id int64
SepalLengthCm float64
SepalWidthCm float64
PetalLengthCm float64
PetalWidthCm float64
Species object
dtype: objectNote: Any column in the data frame having character/string appear as ‘object’ datatypes.
注意:数据框中具有字符/字符串的任何列均显示为“对象”数据类型。
If you to change the data type of a specific column in the data frame, use the .astype() function.
如果要更改数据框中特定列的数据类型,请使用.astype()函数。
For example, to see the ‘SepalLengthCm’ column as a string
例如,以字符串形式查看“ SepalLengthCm”列
In [2]: data['SepalLengthCm'].astype(str)
out[2]: 0 5.1
1 4.9
2 4.7
3 4.6
4 5.0
...
145 6.7
146 6.3
147 6.5
148 6.2
149 5.9
Name: SepalLengthCm, Length: 150, dtype: object11. Selection of columns and rows in Pandas DataFrame
11.在Pandas DataFrame中选择列和行
i)Three primary methods for selecting columns from data frames in pandas.
i)从熊猫数据框中选择列的三种主要方法。
a)df.column_name (Dot notation)
a)df.column_name(点表示法)
In [3]:data.Species.head()
out[3]:0 Iris-setosa
1 Iris-setosa
2 Iris-setosa
3 Iris-setosa
4 Iris-setosa
Name: Species, dtype: objectb)df[‘column_name’] (using square braces and the name of the column as a string)
b)df ['column_name'](使用方括号和列名作为字符串)
In [3]:data['Species'].head()
out[3]:0 Iris-setosa
1 Iris-setosa
2 Iris-setosa
3 Iris-setosa
4 Iris-setosa
Name: Species, dtype: objectc)data.iloc[0:0, <column_number>](using numeric indexing and the iloc selector)
c)data.iloc [0:0,<column_number>](使用数字索引和iloc选择器)
In [3]:data.iloc[0:,5].head()
out[3]:0 Iris-setosa
1 Iris-setosa
2 Iris-setosa
3 Iris-setosa
4 Iris-setosa
Name: Species, dtype: objectii)Selecting rows
ii)选择行
Rows in a DataFrame are selected, typically, using the iloc/loc selection methods, or using logical selectors (selecting based on the value of another column or variable).
通常使用iloc / loc选择方法或使用逻辑选择器(基于另一列或变量的值进行选择)来选择DataFrame中的行。
#selecting rows using iloc/locExample-1In [7]:data.iloc[0:5,].head()
out[7]:
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
1 5.1 3.5 1.4 0.2 Iris-setosa
2 4.9 3.0 1.4 0.2 Iris-setosa
3 4.7 3.2 1.3 0.2 Iris-setosa
4 4.6 3.1 1.5 0.2 Iris-setosa
5 5.0 3.6 1.4 0.2 Iris-setosaExample-2In [8]:data.iloc[4, : ]
out[8]:Id 5
SepalLengthCm 5
SepalWidthCm 3.6
PetalLengthCm 1.4
PetalWidthCm 0.2
Species Iris-setosa
Name: 4, dtype: objectiii)Selecting both rows and columns at a time
iii)一次选择行和列
#selecting column number 1 and five number of row's values of that column
Method-1In [9]:data.iloc[0:5,1].head()
out[9]:0 5.1
1 4.9
2 4.7
3 4.6
4 5.0
Name: SepalLengthCm, dtype: float64Method-2In [10]:data.loc[0:5, ['SepalLengthCm']].head()
out[10]: SepalLengthCm
0 5.1
1 4.9
2 4.7
3 4.6
4 5.012.Filtering
12,过滤
In [11]:data[data['Species']=='Iris-virginica'].head()
out[11]:
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
101 6.3 3.3 6.0 2.5 Iris-virginica 102 5.8 2.7 5.1 1.9 Iris-virginica
103 7.1 3.0 5.9 2.1 Iris-virginica
104 6.3 2.9 5.6 1.8 Iris-virginica
105 6.5 3.0 5.8 2.2 Iris-virginicaIn [12]:data[data['SepalLengthCm']>6.3].head()
out[12]:
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
51 7.0 3.2 4.7 1.4 Iris-versicolor
52 6.4 3.2 4.5 1.5 Iris-versicolor
53 6.9 3.1 4.9 1.5 Iris-versicolor
55 6.5 2.8 4.6 1.5 Iris-versicolor
59 6.6 2.9 4.6 1.3 Iris-versicolorIn [12]:data[data['SepalLengthCm']<6.3].head()
out[12]:
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
1 5.1 3.5 1.4 0.2 Iris-setosa
2 4.9 3.0 1.4 0.2 Iris-setosa
3 4.7 3.2 1.3 0.2 Iris-setosa
4 4.6 3.1 1.5 0.2 Iris-setosa
5 5.0 3.6 1.4 0.2 Iris-setosa13. Manipulating DataFrames in Pandas
13.在熊猫中操作数据框
a)Renaming Columns in a data frame
a)重命名数据框中的列
Column renames can be achieved easily in Pandas using the DataFrame rename( ) function.
使用DataFrame named ()函数可以在Pandas中轻松实现列重命名 。
df.rename(columns = {“old_column_name”: “new_column_name”})
df.rename(columns = {“ old_column_name”:“ new_column_name”})
#Renaming one column
In [13]:data.rename(columns={'SepalLengthCm':'Sepal_Length'})
out[13]:
Id Sepal_Length SepalWidthCm PetalLengthCm PetalWidthCm Species
1 5.1 3.5 1.4 0.2 Iris-setosa
2 4.9 3.0 1.4 0.2 Iris-setosa
3 4.7 3.2 1.3 0.2 Iris-setosa
4 4.6 3.1 1.5 0.2 Iris-setosa
5 5.0 3.6 1.4 0.2 Iris-setosa#Renaming multi-columns
In [14]:data.rename(columns={'SepalLengthCm':'Sepal_Length','SepalWidthCm':'Sepal_Width', 'PetalLengthCm':'Petal_Length','PetalWidthCm':'Petal_Width'})
out[13]:
Id Sepal_Length Sepal_Width Petal_Length Petal_Width Species
1 5.1 3.5 1.4 0.2 Iris-setosa
2 4.9 3.0 1.4 0.2 Iris-setosa
3 4.7 3.2 1.3 0.2 Iris-setosa
4 4.6 3.1 1.5 0.2 Iris-setosa
5 5.0 3.6 1.4 0.2 Iris-setosab)Deleting rows and columns in a data frame
b)删除数据框中的行和列
Pandas use the “drop( )” function to delete rows and columns from DataFrames
熊猫使用“ drop ()”功能从DataFrames中删除行和列
df.drop(name _or _names ,axis= ‘columns’/1 OR ‘rows’ /0)
df.drop(name或_names,axis ='columns'/ 1 OR'rows'/ 0)
i) Deleting columns from Data Frame.
i)从数据框中删除列。
#delete the 'Id' column from the dataframe
In [15]:data.drop('Id',axis= 1).head()#other method data.drop(columns="Id").head()out[15]:
SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
5.1 3.5 1.4 0.2 Iris-setosa
4.9 3.0 1.4 0.2 Iris-setosa
4.7 3.2 1.3 0.2 Iris-setosa
4.6 3.1 1.5 0.2 Iris-setosa
5.0 3.6 1.4 0.2 Iris-setosa#Delete multiple columns from the dataframeIn [16]:data.drop(["Id","SepalWidthCm"],axis= 1).head()
out[16]:SepalLengthCm PetalLengthCm PetalWidthCm Species
5.1 1.4 0.2 Iris-setosa
4.9 1.4 0.2 Iris-setosa
4.7 1.3 0.2 Iris-setosa
4.6 1.5 0.2 Iris-setosa
5.0 1.4 0.2 Iris-setosaii) To delete rows from a DataFrame using drop () function set axis to 0.
ii)要使用drop()函数从DataFrame删除行,请将轴设置为0。
# Delete the rows with labels 0,1
In [17]:data.drop([0,1],axis=0).head(3)
out[17]:
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
3 4.7 3.2 1.3 0.2 Iris-setosa
4 4.6 3.1 1.5 0.2 Iris-setosa
5 5.0 3.6 1.4 0.2 Iris-setosa# Delete the first two rows using iloc selector
In[18]:data.iloc[2:,].head(3)
out[18]:
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
3 4.7 3.2 1.3 0.2 Iris-setosa
4 4.6 3.1 1.5 0.2 Iris-setosa
5 5.0 3.6 1.4 0.2 Iris-setosac) Dealing with Missing Values
c)处理缺失的价值观
Many datasets have missing values, pandas provide multiple ways to deal with it.
许多数据集缺少值,熊猫提供了多种处理方法。
i) Finding missing values
i)寻找缺失的价值
To detect any missing values in a data frame, provide functions like isnull(), isna(). Both of them do the same thing.
要检测数据帧中的任何缺失值,请提供isull(),isna()之类的函数。 他们俩都做同样的事情。
In [19]:data.isna().head(3)
out[19]:
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
False False False False False False
False False False False False False
False False False False False False#df.isna() returns the dataframe with boolean values indicating missing values.(True=missing value is present ,False= missing value is not present.)Note: You can also choose to use notna() which is just the opposite of isna().
注意:您也可以选择使用notna(),这是ISNA正好相反()。
Using df.isna().sum() you can get the number of missing values in each column.
使用df.isna()。sum()可以获取每列中缺失值的数量。
In [20]:data.isna().sum()
out[20]:Id 0
SepalLengthCm 0
SepalWidthCm 0
PetalLengthCm 0
PetalWidthCm 0
Species 0
dtype: int64ii) Drop missing values.
ii)删除缺失值。
To drop a row or column with missing values, pandas provide dropna() function.
要删除缺少值的行或列,pandas提供dropna()函数。
df.dropna(axis=0 or 1,how = ‘any’ or ‘all’)
df.dropna(axis = 0或1,how ='any'或'all')
- ‘any’: drop if there is any missing value 'any':如果缺少任何值,则丢弃
- ‘all’: drop if all values are missing 'all':如果所有值都缺失,则删除
iii)Replacing missing values
iii)替换缺失值
To replace any missing value from the data frame, pandas provide fillna() function.
为了替换数据框中的所有缺失值,熊猫提供了fillna()函数。
14. Computation with pandas DataFrame
14.用pandas DataFrame计算
a) Element-By-Element Mathematical Operations in DataFrame
a)DataFrame中的逐元素数学运算
Many operations such as addition, subtraction, multiplication, division e.t.c can be done elementwise in any data frame by the following ways:
可以通过以下方法在任何数据帧中逐元素完成许多操作,例如加,减,乘,除等。
df+ λ (addition where λ is any scalar value)
df +λ (其中λ是任何标量值的加法)
Similarly, df — λ is for subtraction & df*λ is for multiplication
类似地,df-λ用于减法,df *λ用于乘法
Example:
#adding 1 element-by-element in Column ="SepalLengthCm"
In [21]:data["SepalLengthCm"] + 1
out[21]:0 6.1
1 5.9
2 5.7
3 5.6
4 6.0
...
145 7.7
146 7.3
147 7.5
148 7.2
149 6.9
Name: SepalLengthCm, Length: 150, dtype: float64
#similarly you can do other operatio
b)Statistical operations in DataFrame
b)DataFrame中的统计操作
i) count( ) : Number of non-null observations
i)count():非空观察数
Example:
In [23]:data["SepalLengthCm"].count()
out[23]:150ii) sum( ): Sum of values
ii)sum():值的总和
Example:
In [24]:data["SepalLengthCm"].sum()
out[24]:876.5iii) mean(): Mean of values
iii)mean():均值
Example:
In [25]:data["SepalLengthCm"].mean()
out[25]:5.843333333333334Other important satistical functions in pandas are:-
熊猫的其他重要的讽刺功能是:
mad( ): Mean absolute deviation
mad():平均绝对偏差
median( ):Arithmetic median of values
中位数():数值的算术中位数
min( ): Minimum
min():最小值
max( ): Maximum
max():最大值
mode( ): Mode
模式():模式
prod( ): Product of values
prod():价值的乘积
std( ): Bessel-corrected sample standard deviation
std():贝塞尔校正的样本标准偏差
var( ): Unbiased variance
var():无偏方差
sem( ): Standard error of the mean
sem():平均值的标准误
skew( ): Sample skewness (3rd moment)
偏斜度():样本偏斜度(第3瞬间)
Kurt( ): Sample kurtosis (4th moment)
Kurt():峰度样本(第4刻)
quantile( ): Sample quantile (Value at %)
分位数():样本分位数(%值)
value_counts( ):Count of unique values
value_counts():唯一值的计数
15. Additional useful functions in Pandas
15.熊猫的其他有用功能
a) groupby()-this function is used for grouping data in pandas
a)groupby()-此函数用于对熊猫中的数据进行分组

Example:
In [26]:data.groupby("Species").count()
out[26]: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm
Species
Iris-setosa 50 50 50 50 50
Iris-versicolor 50 50 50 50 50
Iris-virginica 50 50 50 50 50These are some important functions that are widely used in Machine Learning. You can overwhelm by the number of pandas functions, so stick to the most used pandas functions for better understanding of this beautiful library and get most out of it.
这些是机器学习中广泛使用的一些重要功能。 您可能会因熊猫函数的数量而感到不知所措,因此请坚持使用最常用的熊猫函数,以便更好地了解这个漂亮的库并充分利用它。
Happy coding 😃
快乐编码😃
翻译自: https://medium.com/mlpoint/pandas-for-machine-learning-53846bc9a98b
pandas 机器学习















 350
350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









