







一、pandas的数据结构
Pandas中一共有三种数据结构,分别为:Series、DataFrame和MultiIndex(老版本中叫Panel )。
其中Series是一维数据结构,DataFrame是二维的表格型数据结构,MultiIndex是三维的数据结构。
1、Series
Series是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两部分构成。
①Series的创建
pd.Series(data=None, index=None, dtype=None)
data:传入的数据,可以是字典、list等
index:索引,必须是唯一的,且与数据的长度相等。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
dtype:数据的类型
pd.Series(np.arange(3))
# 输出
0 0
1 1
2 2
dtype: int32
pd.Series([1, 2, 3], index=[1,2,3])
# 输出
1 1
2 2
3 3
dtype: int64
a3 = pd.Series({'red':100, 'blue':200, 'green': 500})
# 输出
red 100
blue 200
green 500
dtype: int64
②series的属性
为了更方便地操作Series对象中的索引和数据,Series中提供了两个属性index和values
a3.index
# 输出
Index(['red', 'blue', 'green'], dtype='object')
a3.values
# 输出
array([100, 200, 500], dtype=int64)
2、DataFrame
DataFrame是一个类似于 二维数组或表格(如excel) 的对象,既有行索引,又有列索引
行索引,表明不同行,叫index,0轴,axis=0
列索引,表明不同列,叫columns,1轴,axis=1
① DataFrame的创建
pd.DataFrame(data=None, index=None, columns=None)
index:行标签。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
columns:列标签。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
pd.DataFrame(np.linspace(1, 150, 16).reshape((4, 4)))
# 输出,行列标签从0开始
0 1 2 3
0 1.000000 10.933333 20.866667 30.800000
1 40.733333 50.666667 60.600000 70.533333
2 80.466667 90.400000 100.333333 110.266667
3 120.200000 130.133333 140.066667 150.000000
data = pd.DataFrame(np.arange(0, 11, 2).reshape((2, 3)), [3, 4], ['first', 'second', 'third'])
#输出,行标签从3开始,列标签自定义
first second third
3 0 2 4
4 6 8 10
② DataFrame的属性
shape
获得DataFrame的形状(行数、列数)
data.shape # data定义如上
# 结果
(2, 3)
index
获得DataFrame的行标签(索引)
data.index
# 输出
Int64Index([3, 4], dtype='int64')
columns
获得DataFrame的列标签
data.columns
# 输出
Index(['first', 'second', 'third'], dtype='object')
values
获得DataFrame的所有值
data.values
# 输出
array([[ 0, 2, 4],
[ 6, 8, 10]])
T
将DataFrame的转置
data.T
# 输出
3 4
first 0 6
second 2 8
third 4 10
head()
输出DataFrame的前几条数据,默认为5
data.head(1)
# 输出
first second third
3 0 2 4
tail()
输出DataFrame的后几条数据,默认为5
data.tail(1)
# 输出
first second third
4 6 8 10
③DatatFrame索引的修改
datatframe.reset_index(drop=False)
设置新的下标索引,drop默认为False,意为不删除原来索引;如果为True,则删除原来的索引
data.reset_index()
# 输出
index first second third
0 3 0 2 4
1 4 6 8 10
data.reset_index(drop = True)
# 输出
first second third
0 0 2 4
1 6 8 10
datatframe.set_index(keys, drop=True)
以现有的某列值将其设置为新的索引
keys:列索引名或者列表
drop:布尔类型,默认为真,删除原来的索引
data.set_index(['first'])
# 输出
second third
first
0 2 4
6 8 10
二、dataframe的基本操作
1、df的loc与iloc用法详解
- loc函数:第一个参数取行,第二个参数取列。取行用行索引值,取列用列名,都是前闭后闭
- iloc函数:第一个参数取行,第二个参数取列。取行用行索号,取列用列名的下标,都是前闭后开
注:loc是location的意思,iloc中的i是integer的意思,仅接受整数作为参数。
data.loc[:3, :'second'] # 此时行索引为3,则是第一行
# 输出
first second
3 0 2
data.iloc[:1, :] # 此时的第一行,对应的是行索引为3
# 输出
first second third
3 0 2 4
2、赋值操作
data['first'] = 10
# 输出
first second third
3 10 2 4
4 10 8 10
data.second = 20
# 输出
first second third
3 10 20 4
4 10 20 10
3、排序
排序有两种形式,一种对于索引排序,一种对于内容排序
①内容排序
df.sort_values(by=, ascending=)
对单个键或者多个键进行排序
by:指定排序参考的键
ascending:默认为True,升序;若为False,则降序
data.sort_values(by = ['first'], ascending = False)
# 输出
first second third
4 6 8 10
3 0 2 4
②索引排序
data.sort_index(ascending=)
data.sort_index(ascending = False)
# 输出
first second third
4 6 8 10
3 0 2 4
4、df.query
它是个逻辑运算函数
x = pd.DataFrame(np.arange(1, 7, 1).reshape((2, 3)), columns = ['first', 'second', 'sthird'])
print(x)
print(x.query('first > 0 & first < 2')) # 该条语句和下面一条语句等效
print(x[(x['first'] > 0) & (x['first'] < 2)])
# 输出
first second sthird
0 1 2 3
1 4 5 6
first second sthird
0 1 2 3
first second sthird
0 1 2 3
5、df.isin
判断某列里面是否有某些值,注意isin里面的参数是列表类型
x = pd.DataFrame(np.arange(1, 7, 1).reshape((2, 3)), columns = ['first', 'second', 'sthird'])
print(x)
print(x['second'].isin([1]))
# 输出
first second sthird
0 1 2 3
1 4 5 6
0 False # 这是他的返回值
1 False
Name: second, dtype: bool
6、df.describe、max、min、std、var、median、idxmax、idxmin
| df.~ | 解释 |
|---|---|
| describe | 综合分析 |
| max | 最大值 |
| min | 最小值 |
| std | 标准差 |
| var | 方差 |
| median | 中位数 |
| idxmax | 获得最大值的位置 |
| idxmin | 获得最小值的位置 |
三、pd读取文件
我们的数据大部分存在于文件当中,所以pandas会支持复杂的IO操作,pandas的API支持众多的文件格式,如CSV、SQL、XLS、JSON、HDF5。
1、CSV
pandas.read_csv(filepath_or_buffer, sep =‘,’, usecols, names=, header= )
filepath_or_buffer:文件路径
sep :分隔符,默认用","隔开
usecols:指定读取的列名,列表形式
names:当names没被赋值时,header会变成0;当 names 被赋值,header 没被赋值时,那么header会变成None。如果都赋值,就会实现两个参数的组合功能。
header:设置导入 DataFrame 的列名称,header为0代表先把第一行当做表头
names与header的关系主要体现为:
- csv文件有表头并且是第一行,那么names和header都无需指定;
- csv文件有表头、但表头不是第一行,可能从下面几行开始才是真正的表头和数据,这个时候指定header即可;
- csv文件没有表头,全部是纯数据,那么我们可以通过names手动生成表头;
- csv文件有表头、但是这个表头你不想用,这个时候同时指定names和header。先用header选出表头和数据,然后再用names将表头替换掉,就等价于将数据读取进来之后再对列名进行rename;
2、hdf
pandas.read_hdf(path_or_buf,key =None,** kwargs)
从h5文件当中读取数据,HDF5文件的读取和存储需要指定一个键,值为要存储的DataFrame
path_or_buffer:文件路径
key:读取的键
3、json
pandas.read_json(path_or_buf=None, orient=None, typ=‘frame’, lines=False)
将JSON格式准换成默认的Pandas DataFrame格式
path_or_buffer:文件路径
orient :
- ‘split’:将索引总结到索引,列名到列名,数据到数据。将三部分都分开了
- ‘records’:以 columns:values 的形式输出
- ‘index’ : 以 index:{columns:values} 的形式输出
- ‘columns’ : 以 columns:{index:values} 的形式输出
- ‘values’ : 直接输出值
typ:指定转换成的对象类型series或者dataframe
lines:按照每行读取json对象
四、缺失值处理
对nan值的处理
①判断数据中是否包含NaN
pd.isnull(df)
pd.notnull(df)
②删除存在的缺失值
df.dropna(axis=‘rows’)
注意:这里不会修改原数据,需要接收返回值
# 可以定义新的变量接受或者用原来的变量名
data = data.dropna()
③替换缺失值
df.fillna(value, inplace=True)
value:替换成的值
inplace:True则会修改原数据,False则不替换修改原数据,生成新的对象
for i in movie.columns:
if np.all(pd.notnull(movie[i])) == False:
print(i)
movie[i].fillna(movie[i].mean(), inplace=True)
五、数据离散化
数据离散化在处理数据中是重要的一步,有效的离散化能减小算法的时间和空间开销,提高系统对样本的分类聚类能力和抗噪声能力。
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值。
而数据离散化要分组和one-hot搭配使用
1、分组
pd.qcut(data, q)
对数据列进行分组,一般会与value_counts()(统计分组个数)搭配使用,返回分好组的数据
data:待分组的列
q:需要分组的个数
x = pd.DataFrame(np.arange(1, 101, 1).reshape((25, 4)), columns = ['first', 'second', 'sthird', 'fourth'])
m = pd.qcut(x['first'], 10) # 分组
m.value_counts() # 计算分到每个组数据个数
# 输出
(0.999, 10.6] 3
(20.2, 29.8] 3
(39.4, 49.0] 3
(68.2, 77.8] 3
(87.4, 97.0] 3
(10.6, 20.2] 2
(29.8, 39.4] 2
(49.0, 58.6] 2
(58.6, 68.2] 2
(77.8, 87.4] 2
Name: first, dtype: int64
pd.cut(data, bins)
data:待分组的列
bins:自定义的分组类型,可以是整型(意思同qcut),或列表类型(表中数据间隔则为分组范围)
x = pd.DataFrame(np.arange(1, 101, 1).reshape((25, 4)), columns = ['first', 'second', 'sthird', 'fourth'])
print(x)
m = pd.cut(x['first'], [0, 50, 100])
m.value_counts()
# 输出
(0.904, 49.0] 13
(49.0, 97.0] 12
Name: first, dtype: int64
2、one-hot
把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1。其又被称为独热编码。
pandas.get_dummies(data, prefix=None)
data:分组后的列数据
prefix:分组名字的前缀
dummies = pd.get_dummies(m, prefix="rise")
print(dummies)
输出
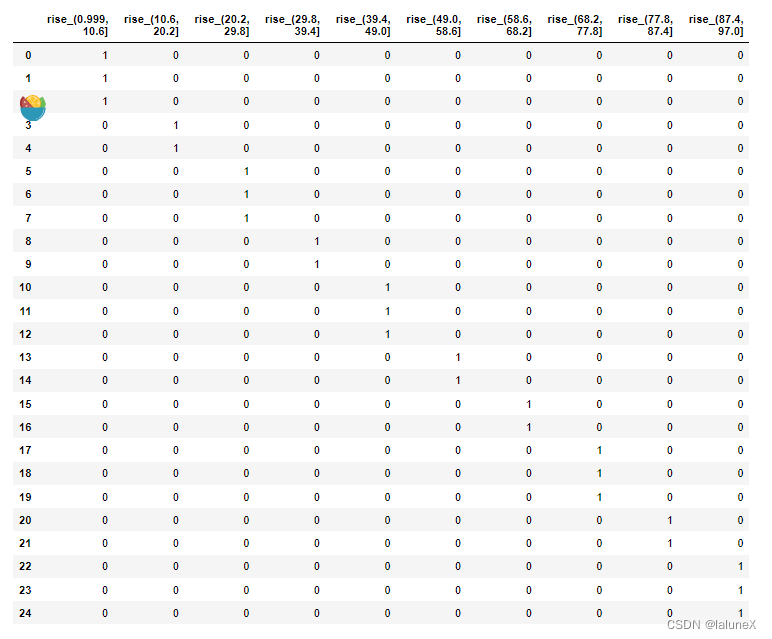
六、合并
如果数据由多张表组成,那么则需要将这些表合并成一张表
1、 pd.concat
pd.concat([data1, data2], axis=1)
按照行或列进行合并,axis=0为扩展行,axis=1为扩展列
# 比如我们将刚才处理好的one-hot编码与原数据合并
pd.concat([x, dummies], axis = 1)
输出
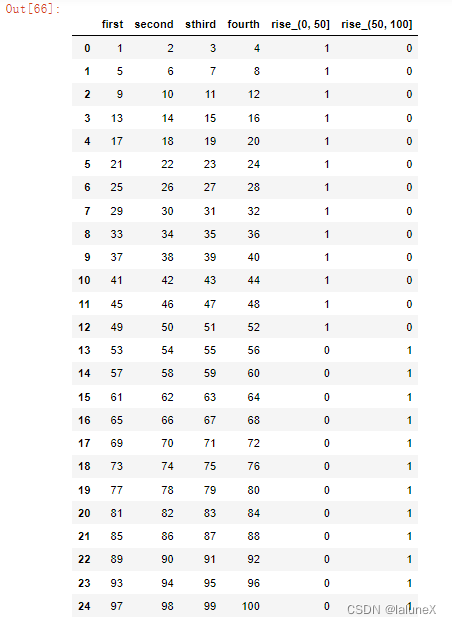
七、分组与聚合
1、分组
DataFrame.groupby(key, as_index=True)
key:分组的列数据,可以多个
as_index:若为True则不保留原来的索引,若为False则保留原来的索引
2、聚合
一般是指对分组中的数据执行某些操作,比如求平均值、最大值等,并且会得到一个结果集。
代码
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56
,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
print(col)
print(col.groupby(['color'], as_index = False)['price1'].min())
col.groupby(['color'])['price1'].mean()
# 输出
color object price1 price2 # 第一个print
0 white pen 5.56 4.75
1 red pencil 4.20 4.12
2 green pencil 1.30 1.60
3 red ashtray 0.56 0.75
4 green pen 2.75 3.15
color price1 # 第二个print,最小值
0 green 1.30
1 red 0.56
2 white 5.56
color # 输出平均值
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
其他
本文只用于个人学习与记录,侵权立删















 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









