





端到端循环视频对象分割
by Justin Wong
贾斯汀·黄
For a company that revolves around video calling, it is beneficial to find the difference in video quality of a publisher, someone who sends out a video, versus a subscriber. This is beneficial for not only testing purposes but to potentially optimize video quality under different constraints, such as limited network bandwidth.
对于一家围绕视频通话的公司而言,发现发布者(发送视频的人)与订阅者的视频质量的差异是有益的。 这不仅有益于测试目的,而且有利于在不同的限制(例如有限的网络带宽)下优化视频质量。
弗雷斯诺 (Fresno)
So what defines “video quality”, and how can we evaluate it? To best evaluate video quality, we try to replicate a user’s experience and perception of quality. This is called objective video quality analysis. At Airtime, we want to perform full-reference objective quality analysis, which means that the entire reference image is known. The previous intern at Airtime, Caitlin, researched, and implemented a source analysis tool called Fresno. Fresno is a tool that is capable of taking in 2 frames, a reference frame, and a distorted frame. Fresno will then pass both of these frames into VMAF (Video Multi-method Assessment Fusion), an open-source software package developed by Netflix. VMAF calculates a quality score on a scale of 0 to 100, where a higher score represents a higher video quality. VMAF’s analysis considers the human visual system, as well as display resolution and viewing distance. More about Caitlin’s work can be found here: https://blog.airtime.com/objective-video-quality-analysis-at-airtime-6543dac7bc1b
那么,什么定义了“视频质量”,我们如何评估呢? 为了最好地评估视频质量,我们尝试复制用户的体验和质量感知。 这称为客观视频质量分析。 在Airtime,我们要执行全参考客观质量分析,这意味着整个参考图像都是已知的。 之前在Airtime的实习生Caitlin研究并实现了名为Fresno的源分析工具。 弗雷斯诺(Fresno)是一种工具,它可以获取2个帧,一个参考帧和一个扭曲的帧。 然后,弗雷斯诺将这两个框架都传递给Netflix开发的开源软件包VMAF(视频多方法评估融合)。 VMAF计算质量分数的范围为0到100,其中较高的分数表示较高的视频质量。 VMAF的分析考虑了人的视觉系统以及显示分辨率和观看距离。 有关Caitlin的工作的更多信息,请参见: https : //blog.airtime.com/objective-video-quality-analysis-at-airtime-6543dac7bc1b
克洛维斯 (Clovis)
However, a source quality analysis tool is not sufficient to conduct video quality analysis at Airtime. If Airtime only had 1-to-1 video calls, source analysis would be sufficient. However, Airtime is a multi-party real-time video chatting app where each subscriber gets a unique video. Thus, we need to implement end-to-end analysis to understand the experience each user is getting.
但是,源质量分析工具不足以在通话时间进行视频质量分析。 如果Airtime仅进行一对一视频通话,则源分析就足够了。 但是,Airtime是一个多方实时视频聊天应用程序,每个订户都能获得一个独特的视频。 因此,我们需要实施端到端分析,以了解每个用户所获得的体验。
There are several challenges for Fresno to be used in end-to-end analysis. To embark on my journey of solving these challenges, I created Clovis, an application that would take in a reference video file, and a distorted video file. Clovis would produce an overall quality score from 0 to 100 that would represent the objective video quality of the distorted video relative to the reference video.
在端到端分析中使用Fresno面临一些挑战。 为了着手解决这些挑战,我创建了Clovis,这是一个可以接收参考视频文件和失真视频文件的应用程序。 Clovis将产生0到100的总体质量得分,该得分表示失真视频相对于参考视频的客观视频质量。
How can Clovis use Fresno to analyze the quality of these two video files? Since Fresno takes in individual video frames, the first challenge would be to break down both video files into individual frames. To do this, Clovis needed to be designed such that breaking down the video files into individual frames and analyzing them were done efficiently.
Clovis如何使用Fresno分析这两个视频文件的质量? 由于Fresno接收单个视频帧,因此第一个挑战是将两个视频文件分解为单个帧。 为此,需要设计Clovis,以便将视频文件分解为单独的帧并进行有效分析。
Clovis工作流程 (Clovis Workflow)
Clovis needed to be broken down into separate modules to simultaneously break down the input files into individual frames, and send frames through Fresno to generate a VMAF score for each frame pair.
需要将Clovis分解为单独的模块,以同时将输入文件分解为单独的帧,并通过Fresno发送帧以为每个帧对生成VMAF分数。
After careful consideration, Clovis was designed as shown in the diagram above. The Clovis App would take in the file paths for both the reference and distorted video file, and send them both to the frame controller. The frame controller would create two FFmpegFrameSources (one for each video file), and an analyzer class. FFmpegFrameSource was a class that was designed to use the library FFmpeg to break down the video into separate frames. For each frame, FfmpegFrameSource would send an on_frame signal to the FrameController. The Analyzer class would receive these signals, and store the frame in a queue. When there exist a matching reference and distorted frame, the analyzer would feed them into VMAF to generate a score. Since Fresno expects frames of the same resolution, the Analyzer was also responsible for scaling the distorted frames to match the resolution of the original video if the resolutions differed. With this design, Clovis will be able to simultaneously decode video files into individual frames as well as analyzing existing frames. Once an FFmpegFrameSource has finished sending frames, it will send a signal to the FrameController. Once the frame controller has received a finished signal from both FFmpegFrameSources, it will signal to the analyzer that there are no more incoming frames. The analyzer will then return a score, which is an average of all VMAF scores of frame pairs. The frame controller will then report the returned score, and signal to the main Clovis App that it has finished executing.
经过仔细考虑,克洛维斯的设计如上图所示。 Clovis应用程序将同时获取参考视频文件和失真视频文件的文件路径,并将它们都发送到帧控制器。 帧控制器将创建两个FFmpegFrameSources(每个视频文件一个)和一个分析器类。 FFmpegFrameSource是一个类,旨在使用FFmpeg库将视频分解为单独的帧。 对于每个帧,FfmpegFrameSource都会向框架控制器发送on_frame信号。 Analyzer类将接收这些信号,并将帧存储在队列中。 当存在匹配的参考帧和扭曲的帧时,分析器会将其馈入VMAF以生成得分。 由于Fresno期望帧具有相同的分辨率,因此,如果分辨率不同,则分析器还负责缩放失真的帧以匹配原始视频的分辨率。 通过这种设计,Clovis将能够将视频文件同时解码为单独的帧并分析现有的帧。 FFmpegFrameSource发送完帧后,它将向FrameController发送信号。 一旦帧控制器从两个FFmpegFrameSources接收到完成的信号,它将向分析器发出信号,通知没有更多的传入帧。 然后,分析器将返回一个分数,该分数是所有帧对的所有VMAF分数的平均值。 然后,帧控制器将报告返回的分数,并向主Clovis应用发出信号,表明其已完成执行。
Now that we’re able to perform objective video quality analysis on any two video files, what else needs to be done? To make Clovis work in practice, we would need to be able to generate a video file for both a publisher and a subscriber.
现在,我们可以对任意两个视频文件执行客观的视频质量分析了,还需要做什么? 为了使Clovis切实可行,我们需要能够为发布者和订阅者生成视频文件。
伊士活 (Eastwood)
Eastwood simulates Airtime’s experience. It is capable of both publishing videos, and subscribing to them. Eastwood sends the publisher’s video to Airtime’s media server, which is responsible for receiving videos from the publisher, as well as sending the respective video to the subscriber. Before sending the publisher’s video to the subscriber, the media server will do one of three actions.
Eastwood模拟了Airtime的体验。 它既可以发布视频,也可以订阅视频。 Eastwood将发布者的视频发送到Airtime的媒体服务器,该服务器负责从发布者接收视频,并将各自的视频发送给订阅者。 在将发布者的视频发送给订阅者之前,媒体服务器将执行以下三个操作之一。
- Forward the video untouched to the subscriber. 将未修改的视频转发给订户。
- Forward video frames untouched to the subscriber, but reduce the frame rate. 将未触摸的视频帧转发给订户,但会降低帧速率。
- Re-encode the video and then send it to the subscriber. 重新编码视频,然后将其发送给订户。
The re-encoding of the video that the media server performs is dependent on the network constraints of the subscriber. Since the media server may further reduce video quality, being able to analyze the difference in the quality of the video before and after it goes through Airtime’s media server is the focal point of the project. To do this, Eastwood was modified to write to a video file before, and after the video was sent through the media server.
媒体服务器执行的视频的重新编码取决于订户的网络限制。 由于媒体服务器可能会进一步降低视频质量,因此能够分析通过Airtime媒体服务器之前和之后的视频质量差异是该项目的重点。 为此,将Eastwood修改为在通过媒体服务器发送视频之前和之后写入视频文件。
After implementing this feature, wouldn’t we have a complete end-to-end video quality analysis system? There was one more thing to consider. The media server’s re-encoding could drop frames in scenarios where the subscriber has restrictive network constraints, or when the subscriber doesn’t subscribe for the entire duration of the publisher’s video. This would lead to a difference in the number of frames between the reference video and the distorted video, so how would we know which reference frame each distorted frame corresponds to?
实施此功能后,我们是否将没有一个完整的端到端视频质量分析系统? 还有一件事要考虑。 在订户具有限制性网络限制的情况下,或者订户没有订阅发布者视频的整个持续时间的情况下,媒体服务器的重新编码可能会丢帧。 这将导致参考视频和失真视频之间的帧数不同,那么我们如何知道每个失真帧对应于哪个参考帧?
帧相关 (Frame Correlation)
Imagine that we have a reference video of 100 seconds and 10 frames per second. The duration of our distorted video after going through the media server is also 100 seconds, but only 5 frames per second. This would leave us a total of 1000 frames in the reference video, but only 500 frames in the distorted video. How would we find out which 500 of the 1000 reference frames correspond to the 500 distorted frames? Would it be the first 500 frames, the first 250 and last 250 frames, or somewhere in between? To find out which reference frame each distorted frame corresponds to, we would need a way to consistently pass the frame number (or something that represents the frame number) through the media server’s re-encoding process.
想象一下,我们有一个100秒每秒10帧的参考视频。 通过媒体服务器后,失真的视频的持续时间也是100秒,但每秒只有5帧。 这将使我们在参考视频中总共留下1000帧,而在失真视频中只有500帧。 我们如何找出1000个参考帧中的500个对应于500个失真帧? 是前500帧,前250帧和后250帧,还是介于两者之间? 为了找出每个失真帧对应于哪个参考帧,我们需要一种方法来通过媒体服务器的重新编码过程一致地传递帧号(或代表帧号的东西)。
潜在解决方案 (Potential Solutions)
After conducting sufficient research, I discovered potential solutions for our tricky frame correlation problem.
经过充分的研究,我发现了棘手的帧相关问题的潜在解决方案。
- Encoding the frame number into the encoder’s header or payload. This method would provide a simple and efficient method to retrieve the frame number. The drawback is that there are multiple encoder formats (VP8, VP9). We would need to consider all possibilities, and ensure that there is a suitable way to store the frame number in each encoder format. 将帧号编码到编码器的标头或有效载荷中。 该方法将提供一种简单有效的方法来检索帧号。 缺点是存在多种编码器格式(VP8,VP9)。 我们将需要考虑所有可能性,并确保存在一种合适的方式来以每种编码器格式存储帧号。
- Each frame has an RTP header, so a possibility would be to store a 16-bit value that represents the frame number in the RTP header’s padding. This method would be troublesome to forward the frame number through to the distorted video. We would have to change code in the media server, making this feature reliant on any changes to the media server. We would also need to edit WebRTC code to include this field. WebRTC is an open-source project that provides web browsers and mobile applications with real-time communication. 每个帧都有一个RTP头,因此可能会在RTP头的填充中存储一个代表帧号的16位值。 这种方法将帧号转发到失真的视频会很麻烦。 我们将不得不更改媒体服务器中的代码,从而使此功能依赖于对媒体服务器的任何更改。 我们还需要编辑WebRTC代码以包括此字段。 WebRTC是一个开源项目,为Web浏览器和移动应用程序提供实时通信。
- Stamping on a barcode on each reference frame, and then reading the barcode from each distorted frame to map it to an original frame. The disadvantage of using a barcode is that there is no guarantee that it will survive the media server’s encoding unlike options one and two. However, there would be less modification of existing code, and functionality should not be impacted if the media server code is modified. A barcode should be able to survive some degree of re-encoding, as a barcode is still readable even if the frame undergoes quality loss. 在每个参考框架上的条形码上盖章,然后从每个变形的框架读取条形码以将其映射到原始框架。 使用条形码的缺点是,与选项一和选项二不同,无法保证条形码将在媒体服务器的编码中保留下来。 但是,对现有代码的修改会更少,并且如果修改了媒体服务器代码,功能不应受到影响。 条形码应该能够在某种程度上重新编码,因为即使帧遭受质量损失,条形码仍然可以读取。
条码 (Barcodes)
After serious consideration, I decided that going with the barcode option was optimal. I did some further research on barcodes to investigate different ways to implement them for our use case.
经过认真考虑,我认为使用条形码选项是最佳选择。 我对条形码进行了进一步的研究,以研究针对我们的用例实现条形码的不同方法。
- Using a 1D Barcode. 使用一维条形码。
This is likely not a viable option, because it most likely will not be able to survive the distortion in all scenarios, due to the lines being very thin. This was tested with a sample image with a 1D barcode stamped onto it. FFmpeg was then used to convert it to a significantly lower resolution and then scaled back to the original resolution. The original and distorted images were fed into a simple online barcode reader (it is assumed that the barcode reader has a similar capability of a C++ library that can decode 1D barcodes), and only the original image was recognized. The distorted image was compressed by a factor of 25. In the images below, 1dout.jpeg is the distorted image.
这可能不是一个可行的选择,因为由于线很细,它很可能无法在所有情况下都能承受失真。 使用带有一维条形码的样本图像对其进行测试。 然后使用FFmpeg将其转换为低得多的分辨率,然后再缩放回原始分辨率。 将原始图像和变形后的图像送入一个简单的在线条形码读取器(假定条形码读取器具有可以解码一维条形码的C ++库的类似功能),并且仅识别原始图像。 扭曲的图像被压缩了25倍。在下面的图像中,1dout.jpeg是扭曲的图像。
As you can see, the image quality of the distorted image is still decent, but the barcode is not decodable.
如您所见,失真图像的图像质量仍然不错,但是条形码无法解码。
2. Using a QR Code
2.使用QR码
A Quick Response (QR) code seems like a more viable option than a 1D barcode because there isn’t the issue of struggling to read extremely thin lines, since it is 2 dimensional. Additionally, there are open source C++ libraries that can successfully read QR codes from images. The drawback of this method is that the minimum size for a QR code is 21x21, which is unnecessarily large for indexing the frames. Having a 21x21 QR code will make it less resistant to scaling than a smaller counterpart. For example, if our “code” takes up a constant percentage of the frame, a barcode with fewer bits (such as 10x10) will make the code easier to read, and more resistant to scaling.
与一维条形码相比,快速响应(QR)代码似乎是一种更可行的选择,因为二维是二维代码,因此不会出现读取超细线条的麻烦。 此外,还有开放源代码的C ++库,可以成功从图像中读取QR码。 该方法的缺点是QR码的最小大小为21x21,对于索引帧而言,该大小不必要地大。 拥有21x21的QR码将使其比较小的QR码更具抗缩放性。 例如,如果我们的“代码”占据了帧的恒定百分比,那么具有更少位(例如10x10)的条形码将使代码更易于阅读,并且更易于缩放。
3. Using a Data Matrix
3.使用数据矩阵
A data matrix is an alternative and similar option to a QR code. The difference is that the minimum size for a data matrix is 10x10. A data matrix also has a larger margin for error correction than a QR code. The implementation of surviving scaling was tested by running a data matrix through scaling resolution down by a factor of 25(same as the 1D) barcode. The reader was still successfully able to decode the distorted image, unlike the 1D barcode. In the images below, dataout.jpeg is the distorted image.
数据矩阵是QR码的替代和类似选项。 区别在于,数据矩阵的最小大小为10x10。 数据矩阵的纠错裕度也比QR码大。 通过将数据分辨率缩小25倍(与1D条形码)相同,通过运行数据矩阵来测试生存缩放的实现。 与一维条形码不同,阅读器仍然能够成功解码失真的图像。 在下面的图像中,dataout.jpeg是变形的图像。
Comparing Data Matrices to QR Codes
将数据矩阵与QR码进行比较


The first image shows a data matrix, and the second image shows a QR code. As you can see, the individual bits for the data matrix are significantly larger than the QR code bits, meaning that it will be able to survive the media server’s re-encoding process more easily. Below is a table comparing Data Matrices to QR codes.
第一幅图像显示数据矩阵,第二幅图像显示QR码。 如您所见,数据矩阵的各个位明显大于QR码位,这意味着它将能够更轻松地经受住媒体服务器的重新编码过程。 下表是将数据矩阵与QR码进行比较的表格。
Although the QR code can encode a large range of data, a Data Matrix is more than sufficient for our use case, as we are simply encoding the frame number in the matrix. After some more research on data matrices, I was able to find a suitable C++ library that is capable of encoding and decoding data matrices. Therefore, I decided to use data matrices in encoding frame numbers into the reference video frames.
尽管QR码可以编码大量数据,但对于我们的用例而言,数据矩阵已绰绰有余,因为我们只是在矩阵中对帧号进行编码。 在对数据矩阵进行了更多研究之后,我能够找到一个合适的C ++ 库 ,该库能够对数据矩阵进行编码和解码。 因此,我决定使用数据矩阵将帧号编码为参考视频帧。
数据矩阵 (Data Matrices)
The frame that is passed through the media server is in YUV format (specifically I420 format), so we would need to write a data matrix that encodes the frame number using this video frame format.
通过媒体服务器传递的帧是YUV格式(特别是I420格式),因此我们需要编写一个数据矩阵,使用该视频帧格式对帧号进行编码。
In a YUV frame, the Y-plane represents the luminance (brightness) component of the frame, and the U and V plane represent the chrominance (color) component of the frame. When Fresno conducts its analysis on a video frame pair, it only uses the Y-plane to generate its score. The images below show what a frame would look like with, and without values in the UV planes.
在YUV帧中,Y平面表示帧的亮度(亮度)分量,而U和V平面表示帧的色度(颜色)分量。 当弗雷斯诺对视频帧对进行分析时,它仅使用Y平面生成其得分。 下图显示了在UV平面中没有值的情况下框架的外观。
Initially, I implemented encoding and decoding the data matrix in Fresno. Eastwood would use Fresno to encode a data matrix onto reference videos before sending it to Airtime’s media server. Clovis would then use Fresno to decode the matrix values. This implementation proved successful for basic use cases, however, when the severe resolution or bitrate restrictions were put on the distorted video, the decoder failed reading several barcodes. Optimizations were needed to be made for both the matrix encoder and decoder to account for more restrictive scenarios.
最初,我在Fresno中实现了对数据矩阵的编码和解码。 Eastwood将使用Fresno将数据矩阵编码到参考视频上,然后再将其发送到Airtime的媒体服务器。 然后,Clovis将使用Fresno解码矩阵值。 这种实现方式在基本用例中被证明是成功的,但是,当对失真的视频施加严格的分辨率或比特率限制时,解码器将无法读取多个条形码。 需要针对矩阵编码器和解码器进行优化,以解决更多限制性情况。
One thing that I noticed was that the barcodes were always 70px by 70px. For larger resolutions, this meant that the barcode was often less than 1% of the total frame. If we were to increase the barcode size before passing it through the media server, it would likely survive the re-encoding process more easily. However, we would not want to increase the barcode size so much that it took over a significant portion of the frame. After careful consideration, I decided to increase the barcode size until the barcode’s width and height reach ⅓ of the smallest dimension of the frame. The barcode size can only be increased in multiples, such that the only possible dimensions are multiples of itself (ex. 70x70, 140x140, 210x210). For example, a 1280x720 video frame would have a barcode size of 210x210. This is because If we divide the minimum dimension of the video frame (720) by 3, we would have 240. The highest multiple of 70 that is less than 240 is 210, so our barcode size would be 210x210.
我注意到的一件事是,条形码始终是70px x 70px。 对于较大的分辨率,这意味着条形码通常小于总帧的1%。 如果我们要在通过媒体服务器之前增加条形码的大小,它可能会在重新编码过程中更轻松地生存下来。 但是,我们不想增加条形码的大小,以至于占用了框架的很大一部分。 经过仔细考虑,我决定增加条形码尺寸,直到条形码的宽度和高度达到框架最小尺寸的1/3。 条形码的大小只能以倍数增加,以使唯一可能的尺寸是其自身的倍数(例如70x70、140x140、210x210)。 例如,一个1280x720的视频帧的条形码尺寸为210x210。 这是因为,如果将视频帧的最小尺寸(720)除以3,我们将得到240。70的最大倍数小于240是210,因此条形码尺寸将为210x210。
Additionally, neutralizing the UV planes of the data matrix makes it more resilient against the types of distortions introduced by the video encoding process by the media server. Below are examples of video frames with and without a neutralized barcode.
此外,中和数据矩阵的UV平面使其可以抵御媒体服务器的视频编码过程所引入的失真类型。 以下是带有和不带有中和条形码的视频帧的示例。


After performing these optimizations, you may be curious about how well the barcode survives distortion, as well as its effect on our final VMAF score.
执行完这些优化后,您可能会对条码在失真中的承受能力以及其对我们最终VMAF得分的影响感到好奇。
Limitations of Data Matrices
数据矩阵的局限性
2 main factors impact how well data matrices survive distortion.
有2个主要因素影响数据矩阵抵抗失真的能力。
- The change in resolution. 分辨率的变化。
- The bitrate constraint 比特率限制
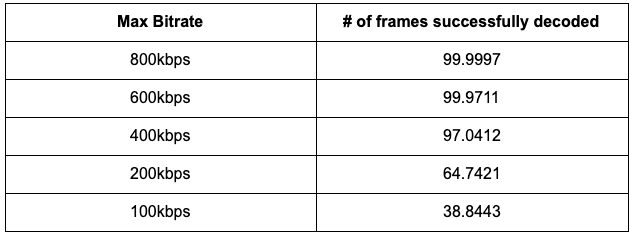
I ran some tests to see how many barcodes would be undecodable given resolution and bitrate constraints. I used a sample 720x720 video file with 256 frames generated by Eastwood, the tables below show the independent effect on barcode decoding of resolution and bitrate constraints.
我进行了一些测试,以查看在给定的分辨率和比特率限制下,有多少条形码无法解码。 我使用了由Eastwood生成的具有256帧的720x720样本视频文件,下表显示了分辨率和比特率限制对条形码解码的独立影响。
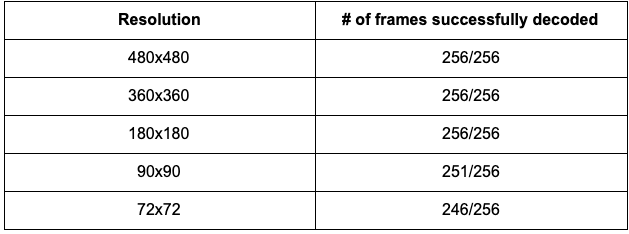
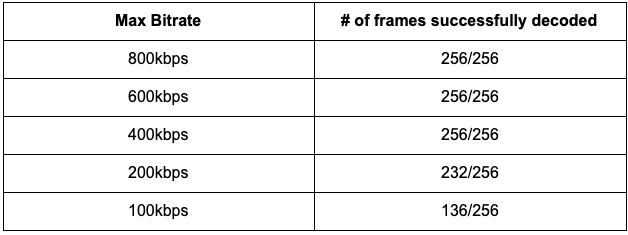
Below are frames from the video file that were used to generate the data sets above. The reference frame, 100kbps frame, and 90x90 are shown respectively.
以下是视频文件中用于生成上述数据集的帧。 分别显示了参考帧,100kbps帧和90x90。



We can see that decoding the barcode region in our frame is more resistant to changes in resolution than bitrate. Even when we shrink the distorted video to approximately 1% of the reference video’s size, we are still able to decode about 90% of the frames. In the scenario of limiting bitrate, more frames are unable to be decoded for some extreme scenarios. However, even if several frames are unable to be decoded, the rest of the frames would still get passed into VMAF, generating a score that is likely very similar to the score that would’ve been generated if all frames were analyzed by VMAF.
我们可以看到,对帧中的条形码区域进行解码比对比特率更能抵抗分辨率的变化。 即使将失真的视频缩小到参考视频大小的大约1%,我们仍然能够解码大约90%的帧。 在限制比特率的情况下,在某些极端情况下无法解码更多帧。 但是,即使无法解码几个帧,其余帧仍将传递到VMAF中,生成的分数可能与如果通过VMAF分析所有帧而生成的分数非常相似。
It’s also important to note the impact the actual barcode has on the VMAF score as well. Since we are writing the barcode region in the Y-plane of the frame, it’s only natural for this to affect the VMAF score, which also depends on the Y-plane of the frame. To investigate this, I ran 2 sets of frame pairs (one without and one with the barcode) that were both scaled from 720x720 to 360x360, each with 100 frames through Fresno. The table below shows the VMAF score of every tenth frame pair.
同样重要的是,还要注意实际条形码对VMAF分数的影响。 由于我们将条形码区域写在框架的Y平面中,因此影响VMAF得分是很自然的,这也取决于框架的Y平面。 为了对此进行研究,我运行了两组帧对(一组不带条形码,一组带条形码),它们从720x720缩放到360x360,每组通过Fresno拥有100帧。 下表显示了每十分之一帧对的VMAF得分。
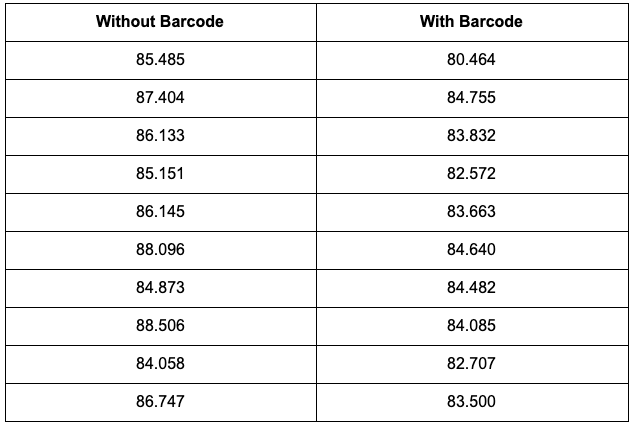
结果 (Results)
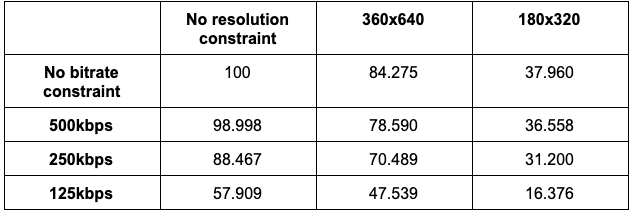
To simulate the effect of the media server’s re-encoding process on the VMAF, more tests were run to find the independent effects of bitrate and resolution on VMAF scores. Using the same reference video as the test above, the tables below illustrate how the VMAF score changes under resolution and bitrate constraints respectively.
为了模拟媒体服务器的重新编码过程对VMAF的影响,运行了更多测试以找到比特率和分辨率对VMAF分数的独立影响。 使用与上述测试相同的参考视频,以下表格分别说明了在分辨率和比特率限制下,VMAF得分如何变化。
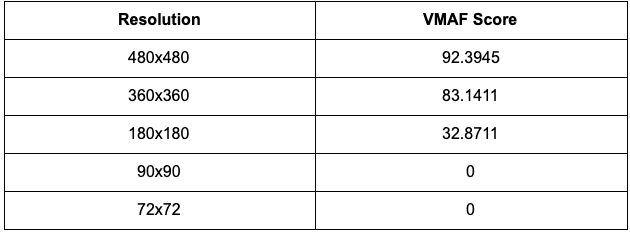
We can see that for both resolution and bitrate constraints, the VMAF score starts dropping significantly under more severe constraints. Both constraints seem to follow a logarithmic relationship between the VMAF score, although the VMAF score seems to drop more quickly for resolution constraints. This is the opposite of the number of unreadable data matrices given these constraints, as decoding data matrices are more resistant to resolution changes than bitrate changes.
我们可以看到,对于分辨率和比特率限制,在更严格的限制下,VMAF分数开始显着下降。 尽管VMAF分数对于分辨率约束而言下降得更快,但两个约束似乎都遵循VMAF分数之间的对数关系。 在给定这些约束的情况下,这与无法读取的数据矩阵的数量相反,因为解码数据矩阵比比特率变化更能抵抗分辨率的变化。
For resolution constraints, the VMAF score drops to 0 when the distorted resolution is approximately 1% of the original size. In these scenarios, some data matrices are unable to be decoded as well. Therefore, it is safe to conclude that whenever data matrices are unreadable due to resolution constraints, the VMAF score would have been 0, or an extremely low value anyway.
对于分辨率限制,当失真的分辨率约为原始大小的1%时,VMAF得分将降至0。 在这些情况下,某些数据矩阵也无法解码。 因此,可以得出结论,只要由于分辨率限制而无法读取数据矩阵,VMAF分数将一直为0,或者无论如何都是极低的值。
On the contrary, for bitrate constraints, the VMAF score does not drop as low for severe conditions, but more data matrices become unreadable. When a few data matrices are unreadable due to bitrate constraints, it is still entirely possible to get a valid VMAF score (see 200kbps example). However, when a significant number of data matrices are unable to be decoded due to bitrate constraints, the VMAF score would likely have been a very low number (see 100kbps example).
相反,对于比特率约束,对于严重条件,VMAF分数不会下降得那么低,但是更多的数据矩阵变得不可读。 当由于比特率限制而无法读取一些数据矩阵时,仍然完全有可能获得有效的VMAF分数(请参见200kbps示例)。 但是,当由于比特率限制而无法解码大量数据矩阵时,VMAF分数可能会非常低(请参见100kbps示例)。
To simulate a more realistic re-encoding of a video file, I used my phone to take a 720x1280 video of myself and simultaneously restricted the bitrate and resolution. The reference video and distorted video were then run through Clovis. Below is the table that shows the results of this test.
为了模拟更逼真的视频文件重新编码,我用手机拍摄了自己的720x1280视频,同时限制了比特率和分辨率。 然后,参考视频和失真视频通过Clovis运行。 下表显示了此测试的结果。
The results in this table very accurately reflect the trends found in the independent tests.
该表中的结果非常准确地反映了独立测试中发现的趋势。
结论 (Conclusion)
Finally, we’ve made the dream of end-to-end objective video quality analysis at Airtime a reality! Now that we’re able to analyze the video quality that users experience under different network constraints, what else needs to be done?
最终,我们实现了Airtime端到端客观视频质量分析的梦想! 现在我们已经能够分析用户在不同网络限制下体验的视频质量,还需要做些什么?
Clovis still needs to be integrated into Airtime’s testing environments. Being able to determine a score for videos under different constraints will allow Airtime’s testers and developers to further optimize the media server’s encoder, improving the app experience for all users of Airtime!
Clovis仍需要集成到Airtime的测试环境中。 能够确定在不同约束条件下的视频得分,将使Airtime的测试人员和开发人员能够进一步优化媒体服务器的编码器,从而改善Airtime所有用户的应用体验!
翻译自: https://blog.airtime.com/end-to-end-objective-video-quality-analysis-at-airtime-9fd1431553cb
端到端循环视频对象分割

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









