





In a world of targeted ads and constant recommendations, it sometimes feels like I consume media and buy products passively. It is easy to float through the day without noticing who is recommending what you watch, buy, and listen to. As much as I love getting an amazing suggestion on Spotify, I try to be an active seeker of music rather than a receptacle for my own listening habits. Each week I make a “To Listen To” playlist of albums I’ve found from online publications, friends, social media, Shazaming at the grocery store, etc. This blog post explains how you can use Python to automate the first option, gathering from online publications, with web scraping and put all of the information into an easily digested format. I walk through the process using Pitchfork’s “Best New Music” page as my example and you can check out the finished notebook here.
在有针对性的广告和不断推荐的世界中,有时感觉就像我在被动地消费媒体并购买产品。 在一天之内漂浮很容易,而不会注意到谁在推荐您观看,购买和收听的内容。 尽管我喜欢在Spotify上收到令人惊讶的建议,但我还是努力成为音乐的积极追求者,而不是自己的听音习惯。 每周,我都会从在线出版物,朋友,社交媒体,杂货店中的Shazaming等处找到专辑的“要收听”播放列表。这篇博客文章介绍了如何使用Python自动执行第一个选项,收集从在线出版物中进行抓取,然后将所有信息转换为易于消化的格式。 我以Pitchfork的“最佳新音乐”页面为例,介绍了整个过程,您可以在此处查看完成的笔记本。
Web scraping allows you to download the contents of a webpage and sift through the results. There are many useful ways to apply this but I’ve found it to be most useful when I am looking to consolidate information that would otherwise take a long time to manually retrieve. For example, when I wanted to create a visual from past Indy 500 race data, I realized gathering all the historical stats dating back to 1911 would be time consuming. Using web scraping, I was able to visit dozens of pages, gather relevant data points, and organize it into a neat table within seconds.
Web抓取使您可以下载网页的内容并筛选结果。 有许多有用的方法可以应用此信息,但是当我希望合并信息时,如果发现该信息将花费很长时间才能手动检索,则它是最有用的。 例如,当我想根据过去的Indy 500比赛数据创建视觉效果时 ,我意识到收集所有可追溯至1911年的历史统计数据将非常耗时。 使用Web抓取,我能够访问数十个页面,收集相关数据点,并在几秒钟内将其整理成整洁的表格。
When I set out to scrape a page, I usually follow the workflow below:
当我着手刮一页时,通常遵循以下工作流程:
- Check for API and site limitations 检查API和网站限制
- Decide what content to retrieve 确定要检索的内容
- Retrieve information and figure out HTML elements 检索信息并找出HTML元素
- Store in the desired format 以所需格式存储
I’ll go into each step in more detail below.
我将在下面更详细地介绍每个步骤。
1.检查API和网站限制 (1. Check for API and site limitations)
Before you start scraping, you will want to see if there’s an API and if the site has any limitations. An API (Application Programming Interface), is a more formal way you can retrieve the data. This would be a better alternative to use because the information is organized and companies will often have documentation with instructions for utilizing their API.
在开始抓取之前,您需要查看是否有API,以及网站是否有任何限制。 API(应用程序编程接口)是检索数据的一种更正式的方法。 这将是更好的替代选择,因为信息是有条理的,公司通常会在文档中包含使用API的说明。
I think of it like this: an API is like a meal kit with all the pre-measured ingredients set out and instructions to follow. APIs have specific endpoints that tell you exactly what information is stored there. Some even provide examples for what the data will look like when you retrieve it. But this is not to say it will be easy with no bumps along the way (I have messed up many meal kits in my time!). Web scraping is like making a recipe from scratch. It is more open ended and requires more preparation. You need to buy the ingredients, clean, measure, and cut it all. When you run into issues, it will likely require more creative troubleshooting to get to the solution. Simply Googling “website name API” should bring it up if one exists. But this post is about web scraping, so of course when I checked, there was no official API for Pitchfork.
我是这样想的:API就像一个饭盒,上面列出了所有预先计量的成分以及要遵循的说明。 API具有特定的终结点,可以确切告诉您那里存储了哪些信息。 有些甚至提供示例,说明检索数据时的数据。 但这并不是说这很容易,而且一路走来也没有颠簸(我当时弄乱了很多饭盒!)。 Web抓取就像从头开始制作食谱。 它是开放式的,需要更多的准备。 您需要购买原料,进行清洁,测量和切割。 当您遇到问题时,可能需要进行更多创造性的故障排除才能找到解决方案。 如果存在,只需使用Google搜索“网站名称API”即可。 但是这篇文章是关于网页抓取的,所以当我检查时,当然没有针对Pitchfork的官方API。
Before scraping, we need to see if the website has any limitations. You can find this out by adding /robots.txt to the base URL.
在抓取之前,我们需要查看网站是否有任何限制。 您可以通过在基本URL中添加/robots.txt来找到/robots.txt 。

Here, you will see a list of users and the permissions the website allows for each. In the case of Pitchfork, you and I fall under the user agent “*” (asterisk means all). According to this, anything in the root directory “/” and not specifically called out is fair game.
在这里,您将看到用户列表以及网站允许每个用户的权限。 对于干草叉,您和我属于用户代理“ *”(星号表示全部)。 据此,根目录“ /”中没有特别指出的任何东西都是公平的游戏。
Some sites also include limitations on how many requests can be sent. If you exceed this limit, it may raise flags on their end and result in you being blocked. You can use the time module in Python to help work around this (i.e. time.sleep() can delay and space out your requests). Additionally, many include sitemaps. This is especially helpful if you are trying to scrape every page they have.
一些站点还限制了可以发送多少个请求。 如果超过此限制,则可能会在其末端引发标志并导致您被阻止。 您可以使用Python中的time模块来解决此问题(例如, time.sleep()可以延迟并间隔您的请求)。 此外,许多都包含站点地图。 如果您要抓取每个页面,这将特别有用。
Some sites do not have a “robots” page. I don’t know what the official response is to that but I try to stay away unless I am confident it is allowed.
某些网站没有“机器人”页面。 我不知道官方对此有何React,但除非我确信这是允许的,否则我会尽量远离。
2.确定要检索的内容 (2. Decide what content to retrieve)
My purpose for creating this scraper is to grab all the “Best New Music” recommendations from Pitchfork and put it into a table. In my final table, each row would be an album or track with the corresponding details filling out each column. After brainstorming what information I would want for each entry, here is my wishlist of data to grab:
我创建刮板的目的是从干草叉中获取所有“最佳新音乐”建议,并将其放入桌子中。 在我的决赛桌中,每一行都是专辑或曲目,每一列都有相应的详细信息。 经过头脑风暴,我希望为每个条目提供哪些信息,以下是我希望获取的数据清单:
- Artist 艺术家
- Title of work 作品名称
- Link to Pitchfork’s full review 链接到干草叉的完整评论
- Preview of review 预览预览
- Pitchfork Author 干草叉作者
- Pitchfork Rating 干草叉等级
- Distinguish if it is an album or a song 区分是专辑还是歌曲
- Genre 类型
- Artwork 艺术品
I would also love to add a link to Spotify so I can go to listen directly from the table but since this isn’t included on the Pitchfork site, this will require adding an additional source like the Spotify API. I won’t cover that in this post but the finished repo has a separate notebook where I do just that.
我也想添加一个指向Spotify的链接,这样我就可以直接从表中进行侦听,但是由于Pitchfork网站上未包含此链接,因此这将需要添加其他资源,例如Spotify API。 我不会在这篇文章中讨论这个问题,但是完成的回购有一个单独的笔记本,我只是在那做。
3.检索信息并找出HTML元素 (3. Retrieve information and figure out HTML elements)
Now that we have a wishlist of data to grab, we’ll want to see where exactly this information lives on the page. First, let’s discuss how the requests and beautifulsoup4 packages work. You can start by installing (if you haven’t already) and importing them. We’ll also import pandas so the scraped data can be organized into a table.
现在我们有了要获取的数据的愿望清单,我们将要查看该信息在页面上的确切位置。 首先,让我们讨论requests和beautifulsoup4程序包如何工作。 您可以先安装(如果尚未安装)并导入它们。 我们还将导入pandas以便可以将抓取的数据组织到一个表中。
#Imports
import pandas as pd
import requests
from bs4 import BeautifulSoupThe requests module allows you to gather the underlying code from a page. The .get() method sends a request to a website’s server which then sends back information. All you need to do is add the URL as a string in the parentheses. As mentioned before, be cautious of any rate limits as sending too many requests in a short amount of time could look suspicious to them and result in your IP address being blocked.
requests模块使您可以从页面收集基础代码。 .get()方法将请求发送到网站的服务器,然后该服务器发送回信息。 您需要做的就是将URL作为字符串添加在括号中。 如前所述,请谨慎对待任何速率限制,因为在短时间内发送太多请求可能会对他们造成可疑,并导致您的IP地址被阻止。
Checking the status code will let you know if this request was successful or not.
检查状态码将使您知道此请求是否成功。
#Create a Request object by gathering information from the URL below
res = requests.get('https://pitchfork.com/best/')
#Check that the request worked (status code should be 200)
res.status_codeWe know our request went through but to see the actual contents of what was returned, add .text to the object. In the screenshot below you can see the text we received from the Pitchfork page. Just looking at the first thousand characters, it is a bit overwhelming and not very digestible.
我们知道我们的请求已经完成,但是要查看返回的实际内容,请在对象中添加.text 。 在下面的屏幕截图中,您可以看到我们从干草叉页面收到的文本。 仅查看前几千个字符,就有点让人难以理解,也不易消化。

This is where BeautifulSoup comes in! Converting this request object into a BeautifulSoup object allows us to search the text for specific HTML elements.
这就是BeautifulSoup进来的地方! 将此request对象转换为BeautifulSoup对象,使我们可以在文本中搜索特定HTML元素。
#Convert the raw text into a BS object. This is much easier to sort through!
best = BeautifulSoup(res.text, 'lxml')If you are unfamiliar with HTML, I would suggest checking out this overview. For the purposes of web scraping, we just need to know that most of the content lives within some sort of HTML element. Most elements have an opening and closing tag with the displayed text in between (i.e. <p>My paragraph </p> is a paragraph element with the text “My paragraph”).
如果您不熟悉HTML,建议您查看此概述 。 为了进行网络抓取,我们只需要知道大多数内容都存在于某种HTML元素中。 大多数元素都有一个开始和结束标签,中间显示的文字(即<p>My paragraph </p>是带有文本“我的段落”的段落元素)。
So if we know the information we want is stored in an h3 tag, we can use the .find() (returns the first h3 ) or .find_all() (returns list of all the h3's) methods to easily retrieve this. Adding .text to a single object returns just the text of that tag.
因此,如果我们知道所需信息存储在h3标签中,则可以使用.find() (返回第一个h3 )或.find_all() (返回所有h3的列表)方法来轻松地检索此信息。 将.text添加到单个对象仅返回该标签的文本。
#Returns first 'h3' tag
best.find('h3')
#Returns text of first 'h3' tag
best.find('h3').text
#Returns list of all 'h3' tags
best.find_all('h3')
#Use a for loop to see all of the text in this list
for tag in best.find_all('h3'):
print(tag.text)Pinpointing which HTML elements to gather is crucial for getting the relevant information from all the text you scraped. Keep in mind the text contains everything visible on the page like headlines, paragraph, tables, but also elements that are not displayed like links to images and other parts of the site. There are a couple ways to identify where the information you want is stored on the page. One method to try is using the “Inspect” feature on your web browser.
精确确定要收集HTML元素对于从您抓取的所有文本中获取相关信息至关重要。 请记住,文本包含页面上可见的所有内容,例如标题,段落,表格,还包含未显示的元素,例如指向图像和网站其他部分的链接。 有两种方法可以识别所需信息在页面上的存储位置。 一种尝试的方法是使用Web浏览器上的“检查”功能。

This will bring up the underlying code of the page so we can see what HTML tags are used for a specific piece of information.
这将显示页面的基础代码,因此我们可以看到哪些HTML标签用于特定信息。
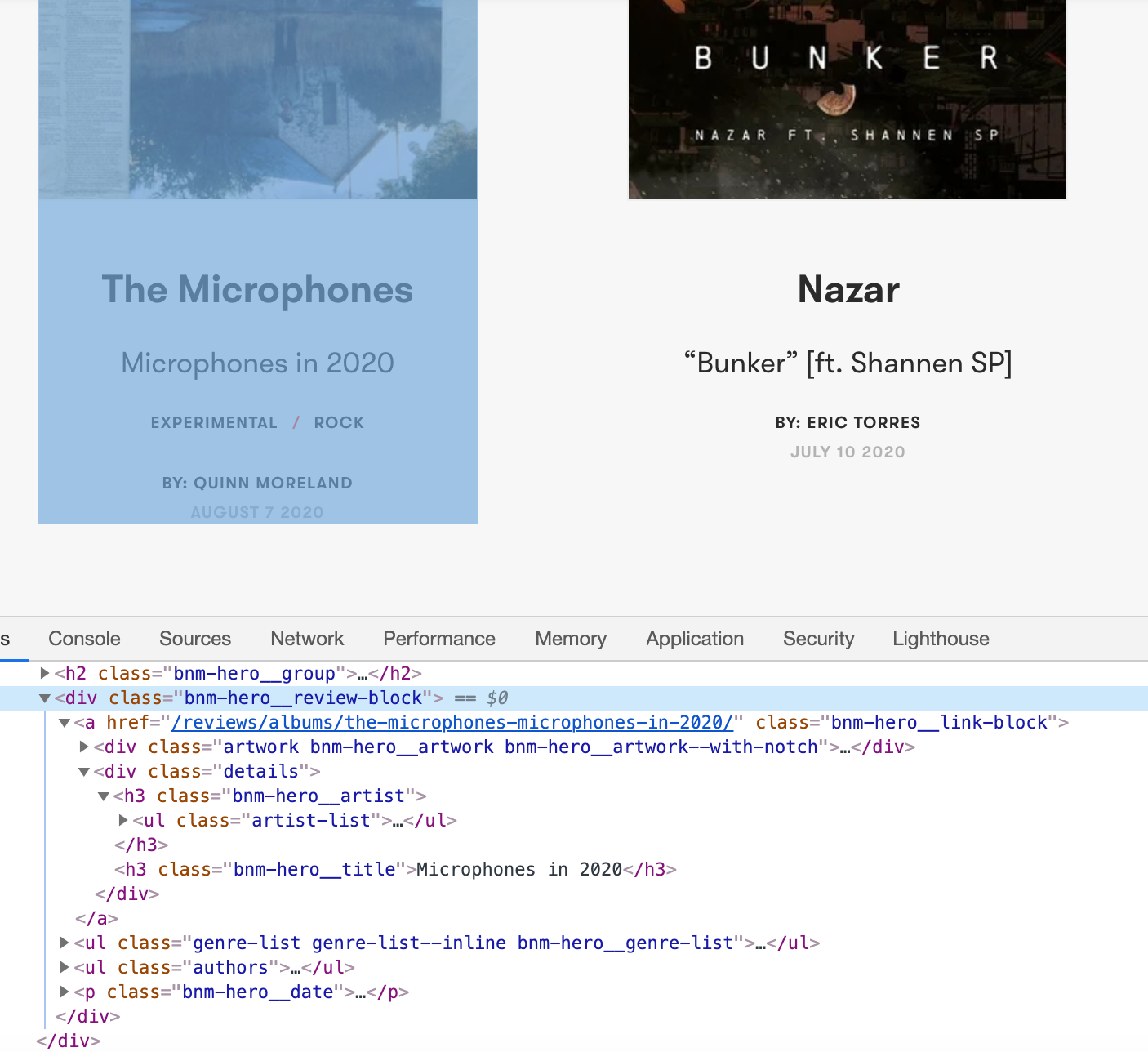
Another method is to search through your BeautifulSoup object to see where the text is. I usually employ both of these options simultaneously and mix trial and error with patience until I successfully identify which tags contain the data I want.
另一种方法是搜索BeautifulSoup对象以查看文本在哪里。 我通常同时使用这两个选项,并且将尝试和错误耐心地混合在一起,直到成功识别出包含所需数据的标签为止。
In pages that have hundreds or thousands of tags, it may be difficult to extract certain key pieces while weeding out the others. There may be dozens of h3 tags but only one that is important to you. Targeting specific attributes helps you filter. Attributes come in the opening HTML tag and help group or identify certain elements (i.e. <p class=my_class> My paragraph </p> contains the class attribute my_class). Class attributes can be applied to multiple elements while ID attributes are only for one. The code below shows how you can search for a tag and specify the class.
在具有成百上千个标签的页面中,可能难以提取某些关键片段,同时淘汰其他关键片段。 h3标签可能有很多,但只有一个对您很重要。 定位特定属性可帮助您进行过滤。 属性位于开头HTML标记和帮助组中,或标识某些元素(即<p class=my_class> My paragraph </p>包含类属性my_class )。 类属性可以应用于多个元素,而ID属性仅适用于一个元素。 下面的代码显示了如何搜索标签并指定类别。
#Returns list of all h3 tags with the class of "bnm-small album-small"
best.find_all('h3', {'class' : 'bnm-small album-small'}On the other end of the spectrum, you can broaden your search and include different tags by passing them in as a list. This also applies if you want to look for multiple attributes.
在频谱的另一端,您可以通过将它们作为列表传递来扩大搜索范围并包括不同的标签。 如果要查找多个属性,这也适用。
#Selects all 'h3' and 'h4' tags
best.find_all(['h3', 'h4'])Similar to how .text shows the text, you can isolate the different attributes of an element by adding .attrs and specifying which attribute in square brackets. This is especially helpful when you want to grab the link from an anchor tag like in the code below.
与.text显示文本的方式类似,您可以通过添加.attrs并在方括号中指定哪个属性来隔离元素的不同属性。 当您想要从锚标记中获取链接时,如下面的代码中所示,这特别有用。
#This returns the href attribute (aka the link) from the first 'a' tag
best.find('a').attrs['href']For the Pitchfork page, I found that each entry of an album or track was contained in a div tag, and all of the important information was included. Using .find_all() and specifying certain classes, I created a list called “reviews” where each item was a div section that would need to be parsed through further.
在Pitchfork页面上,我发现专辑或曲目的每个条目都包含在div标签中,并且所有重要信息都包括在内。 使用.find_all()并指定某些类,我创建了一个名为“ reviews”的列表,其中每个项目都是一个div节,需要进一步解析。
#All the albums or tracks have the following class tags
class_tags = ['bnm-hero__review-block', 'bnm-small album-small', 'bnm-small track-small']
#This is a list of all the entries, looping through this should gather all of the information
reviews = best.find_all('div', {'class' : class_tags})From there, I was able to break down the div sections further to see where details like “artist” and “title” were stored. Here are a few examples:
从那里,我能够进一步细分div部分,以了解存储“艺术家”和“标题”等详细信息的位置。 这里有一些例子:
#Artist
reviews[0].find_all(['h3'])[0].text
#Title of Album or Track
reviews[0].find_all(['h3'])[1].text
#Link to Pitchfork's review
reviews[0].find('a').attrs['href']
#Album or track? This can be found in the URL
reviews[0].find('a').attrs['href'].split('/')[2][:-1].title()The complete breakdown is available on my GitHub. I also realized that the first three entires were different from the rest so the repo includes those slight differences.
完整的细分可在我的GitHub上找到 。 我还意识到前三个整体与其余的有所不同,因此回购包含了那些细微的差异。
Some of the information is not on the main “Best New Music” page but rather on the actual review which is a separate link. This means I did one big scrape on the main page, then additional requests for each review page.
有些信息不在“最佳新音乐”主页上,而是在实际的评论上,这是一个单独的链接。 这意味着我在主页上进行了一次大的刮擦,然后对每个评论页面进行了其他请求。
My last step is to bundle all of this into a function that loops through to gather information for each entry, then cleans and exports the data.
我的最后一步是将所有这些捆绑到一个函数中,该函数循环访问以收集每个条目的信息,然后清除并导出数据。
4.以所需格式存储 (4. Store in the desired format)
Once I found where each piece of information lived on the page, I combined all the steps and made them flexible enough to work in a loop. Here’s an example of how I changed some of the code from above:
找到页面上每条信息的位置后,我将所有步骤组合在一起,并使它们足够灵活,可以循环工作。 这是我如何从上面更改一些代码的示例:
#This finds the artist for the first list item in "reviews"
reviews[0].find_all(['h3'])[0].text
#This is the same code changed to work in a for loop
for review in reviews:
review.find_all(['h3'])[0].textAs each album or track is scraped, the information is stored in a dictionary.
在抓取每个专辑或曲目时,信息将存储在词典中。
#Each album or track becomes a dictionary
entry = {
#Artist
'artist' : review.find_all(['h3'])[0].text,
#Title of Album or Track
'title' : review.find_all(['h3'])[1].text,
#Link to Pitchfork's review
'review_link' : URL + review.find('a').attrs['href'],
#Album or track? This can be found in the URL
'album_track' : review.find('a').attrs['href'].split('/')[2][:-1].title(),
#Genre
'genre' : [genre.text for genre in review.find_all('li', {'class' : 'genre-list__item'})],
#Artwork
'artwork' : review.find('img').attrs['src'],
}When the dictionary is complete, it is added to a list. The final product is a list of dictionaries where each list item is a different album or track from the Pitchfork website. A list of dictionaries is also the perfect format to convert into a DataFrame.
词典完成后,它将添加到列表中。 最终产品是词典列表,其中每个列表项都是Pitchfork网站上不同的专辑或曲目。 词典列表也是转换为DataFrame的理想格式。
#List to hold all the dictionaries
all_dict = []
#Add the entry to the list
all_dict.append(entry)
#Once all the dictionaries are added, turn the list into a dataframe
pd.DataFrame(all_dict)Just like that I have my listening list for the week and it took less than 6 seconds to gather.
就像这样,我有了本周的聆听清单,花了不到6秒的时间。

Here are some other ideas for how to expand this project further:
以下是有关如何进一步扩展该项目的其他一些想法:
- Add additional sources, like NPR, Complex, Stereogum, to get more recommendations 添加其他资源,例如NPR,Complex,Stereogum,以获得更多建议
- Integrate with Google sheets to have a living document that is expanded each week 与Google表格集成在一起,以提供一个实时文档,该文档每周都会扩展
- Utilize the Spotify API to build yourself a playlist 利用Spotify API构建自己的播放列表
I hope you enjoyed reading this and learned something new. If you have any suggestions, questions, or ideas for other sites to scrape, I would love to hear them!
我希望您喜欢阅读本文并学到新知识。 如果您有任何其他站点需要刮擦的建议,问题或想法,我很想听听他们的意见!
翻译自: https://medium.com/@stephaniecaress/scraping-pitchforks-best-new-music-be563d18ea4f















 6766
6766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









