






python的Requests(http://docs.python-requests.org/en/latest/)库在处理http/https请求时还是比较方便的,应用也比较广泛。
但其在处理response时有一些地方需要特别注意,简单来说就是Response对象的content方法和text方法的区别,具体代码如下:
@propertydefcontent(self):"""Content of the response, in bytes."""
if self._content isFalse:#Read the contents.
try:ifself._content_consumed:raiseRuntimeError('The content for this response was already consumed')if self.status_code ==0:
self._content=Noneelse:
self._content= bytes().join(self.iter_content(CONTENT_CHUNK_SIZE)) orbytes()exceptAttributeError:
self._content=None
self._content_consumed=True#don't need to release the connection; that's been handled by urllib3
#since we exhausted the data.
returnself._content
@propertydeftext(self):"""Content of the response, in unicode.
if Response.encoding is None and chardet module is available, encoding
will be guessed."""
#Try charset from content-type
content =None
encoding=self.encodingif notself.content:return str('')#Fallback to auto-detected encoding.
if self.encoding isNone:
encoding=self.apparent_encoding#Decode unicode from given encoding.
try:
content= str(self.content, encoding, errors='replace')except(LookupError, TypeError):#A LookupError is raised if the encoding was not found which could
#indicate a misspelling or similar mistake.
# #A TypeError can be raised if encoding is None
# #So we try blindly encoding.
content = str(self.content, errors='replace')return content
@property
def apparent_encoding(self):
"""The apparent encoding, provided by the lovely Charade library
(Thanks, Ian!)."""
return chardet.detect(self.content)['encoding']
可以看出text方法中对原始数据做了编码操作
其中response的encoding属性是在adapters.py中的HTTPAdapter中的build_response中进行赋值,具体代码如下:
defbuild_response(self, req, resp):"""Builds a :class:`Response ` object from a urllib3
response. This should not be called from user code, and is only exposed
for use when subclassing the
:class:`HTTPAdapter `
:param req: The :class:`PreparedRequest ` used to generate the response.
:param resp: The urllib3 response object."""response=Response()#Fallback to None if there's no status_code, for whatever reason.
response.status_code = getattr(resp, 'status', None)#Make headers case-insensitive.
response.headers = CaseInsensitiveDict(getattr(resp, 'headers', {}))#Set encoding.
response.encoding =get_encoding_from_headers(response.headers)
response.raw=resp
response.reason=response.raw.reasonifisinstance(req.url, bytes):
response.url= req.url.decode('utf-8')else:
response.url=req.url#Add new cookies from the server.
extract_cookies_to_jar(response.cookies, req, resp)#Give the Response some context.
response.request =req
response.connection=selfreturn response
从上述代码(response.encoding =get_encoding_from_headers(response.headers))中可以看出,具体的encoding是通过解析headers得到的,
defget_encoding_from_headers(headers):"""Returns encodings from given HTTP Header Dict.
:param headers: dictionary to extract encoding from."""content_type= headers.get('content-type')if notcontent_type:returnNone
content_type, params=cgi.parse_header(content_type)if 'charset' inparams:return params['charset'].strip("'\"")if 'text' incontent_type:return 'ISO-8859-1'
为避免Requests采用chardet去猜测response的编码,请慎用text属性,直接使用content属性即可,再根据实际需要进行编码。
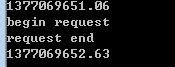
对于服务端没有显式指明charset的response来说,采用text和content的差别如下所示:
代码:
printtime.time()print 'begin request'r= requests.get(r'http://www.sina.com.cn')#erase response encoding
r.encoding =None
r.text#r.content
print 'request end'
print time.time()
采用text时的耗时:

采用content时的耗时:















 1969
1969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









