






什么是黑塞矩阵?
① 它是一个由多变量实值函数的所有二阶偏导数组成的方块矩阵。
注:德语:Hesse-Matrix;英语:Hessian matrix或Hessian),又译作海森矩阵、海塞矩阵或海瑟矩阵等。
② 假设有一实值函数

注:或者使用下标记号表示为:
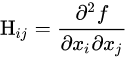
Python基础积累(pandas)
分类、表格名称重命名
import pandas as pd
df = pd.DataFrame({"id":[1,2,3,4,5,6], "raw_grade":['a', 'b', 'b', 'a', 'e', 'e']})
df运行结果:

注:.DataFrame建立表格。
df["grade"] = df["raw_grade"].astype("category")
df["grade"]运行结果:
0 a
1 b
2 b
3 a
4 e
5 e
Name: grade, dtype: category
Categories (3, object): [a, b, e]
注:把raw_grade类型转换为分类类型,这里分为了三类,分别为[a, b, e]。
df["grade"].cat.categories = ["very good", "good", "very bad"]注:重命名类别名为更有意义的名称。
注:将a、b、e重命名为["very good", "good", "very bad"]。
df["grade"] = df["grade"].cat.set_categories(["very bad", "bad", "medium", "good", "very good"])
df["grade"]运行结果:
0 very good
1 good
2 good
3 very good
4 very bad
5 very bad
Name: grade, dtype: category
Categories (5, object): [very bad, bad, medium, good, very good]
注:df["grade"].cat.set_categories(["very bad", "bad", "medium", "good", "very good"])使得grade中a—e对应这五个重命名的值。
注:重命名类别名为更有意义的名称。
注:df["grade"]再打印重命名后的grade值。
df
df.sort_values(by="grade")运行结果:
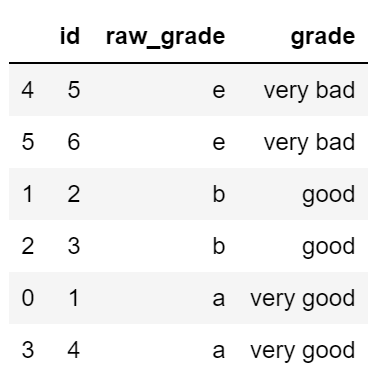
注:.sort_values这里是按照grade顺序来排,也就是按从大到小,从e到a的顺序来排。
df.groupby("grade").size()运行结果:
grade
very bad 2
bad 0
medium 0
good 2
very good 2
dtype: int64
注:按分类分组时,也会显示空的分类。
注:取得按照grade分类后情况,具有相同值得个数。
参考文献:
- 知乎/致Great/雅可比矩阵、黑森矩阵、泰勒展开式















 5708
5708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









